
Рис. 1.Процесс ввода звуковой информации
Автор:Бершадская О.А., Семенова А.П.
Источник: Материалы VII Международной научно-технической конференции «Современные информационные технологии в образовании и научных исследованиях» (СИТОНИ-2021). – Донецк: ДонНТУ, 2021. – С.445-449.
УДК 004.93'4
ПРИМЕНЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ЗАДАЧИ РАСПОЗНОВАНИЯ РЕЧИ
Бершадская О.И., Семенова А.П.
ГОУ ВПО «Донецкий национальный технический университет» (г. Донецк)
e-mail: olga.bershadskaya20@yandex.ru, nastena-semenova19@rambler.ru,
Бершадская О.А., Семенова А.П. Применение нейронных сетей для задачи распознавания речи. В данной работе рассматриваются задача распознавания речи и способы ее решения с применением нейросетевых технологий. Проанализированы способы преобразования звукового сигнала для подачи его на вход нейронной сети. Рассмотрены различные виды нейронных сетей и особенности их применения при распознавании речи.
Ключевые слова: распознавание речи, спектр, акустика, нейросетевые технологии, звук
Введение
Речь человека очень эмоциональна по ряду причин: отличия дыхательной системы, голосовых связок и резонаторов [1]. Речь одного и того же произносящего, осуществляющего одни и те же акустические единицы, будет отличаться по спектральному составу и длительности произношения. Присутствие наложения артикуляции, характерной для последующего звука, на весь предшествующий звук, является следствием зависимости от контекста. Из приведенного следует, что высококачественное распознавание речи требует быстроты. Добиться необходимой скорости можно при помощи применения нейросетевых технологий.
Задача распознавания речи сейчас наиболее актуальна в сфере распознавания. Ее основная цель - поиск оптимального метода преобразования речевого сигнала в цифровой для последующего использования его на ЭВМ. Существующие системы распознавания речи характеризуется рядом недостатков: полны ошибок, маленький объем словарей, неразрешимость помех и т.д. Данные недостатки можно решить с помощью применения нейросетевых технологий.
Рассмотрим базовые понятия, лежащие в основе подходов к распознаванию речи. Речь является цепочкой звуков, звук – наложение звуковых волн различных частот. Волна характеризуется двумя атрибутами: амплитуда и частота. Чтобы сохранить звуковой сигнал на носителе его необходимо разбить на множество промежутков и взять среднее значение на каждом из этих промежутков. Так механические колебания превращаются в цифры, предназначенные для обработки на ЭВМ.
Этапы процесса распознавания
Процесс распознавания речи можно разбить на три этапа, рассмотрим каждый из них подробно.
На первом этапе речевой сигнал преобразуется в цепочку векторов признаков, получаемых через назначенные промежутки времени. Как показывает практика, эти векторы состоят из спектральных или кепстральных коэффициентов, которые отражают короткие отрезки речевого сигнала и максимально приближаются к реакции слуховой системы человека.
На втором этапе происходит сравнение полученных векторов признаков с эталонами, содержащимися в моделях слов, и соотношение речевых участков, выраженных несколькими векторами признаков.
На третьем этапе происходит временное выравнивание векторов признаков с эталонами и находятся величины соответствия для слов. Временное выравнивание необходимо для восполнения преобразований в скорости говорящего.
После выполнения всех этих операций распознаватель выбирает слово, для которого мера соответствия максимальна. При распознавании слитной речи локальные метрики, полученные на втором этапе вычислений, используются для временного выравнивания и определения величин соответствия для отдельных предложений или высказываний.
Подача звука на вход нейросети
Чтобы подать звук на вход нейросети, следует выполнить некоторую предобработку звука. Представление звука во временной форме бессмысленно. Гораздо более эффективно спектральное представление речи [2]. Для получения спектра необходимо сначала выполнить прерывное преобразование Фурье [1], а затем видоизменить спектр, к примеру, при помощи логарифмического изменения масштаба, который близок к субъективному масштабу восприятия звука человеком. Процесс ввода звуковой информации изображен на рисунке 1.
Рис. 1.Процесс ввода звуковой информации
Только после нормирования и сжатия, спектр можно подать на вход нейросети. На входном слое над звуком не происходит никаких преобразований. От выбора числа входов, зависит процент последующей потери информации и сложность распознавания. При большой разрешающей способности сети можно определить высоту голоса, при малой – формантную структуру.
Нейронные сети для решения задачи распознавания речи
Решить задачу распознавания речи можно при помощи нескольких типов нейросетей. Рассмотрим их архитектуру с конкретными случаями использования.
Однослойная нейронная сеть перцептрон может быть использована для
распознавания речи с прерывным мониторингом. В этом случае выполняется векторное разделение и каждому вектору признаков ставят в соответствие символ из кодовой книги, где находятся эталонные вектора-признаки, затем при помощи вероятностных наблюдений за символами для каждого эталонного вектора, происходит вычисление локальных метрик. Однослойный перцептрон представленный на рисунке 2, состоит из линейных узлов, число которых равно числу эталонов, число входов должно быть равным числу возможных символов.

Рис. 2.Нейронная сеть однослойная перцептрона
На рисунке 3 предоставлена сеть Кохонена, которая очень схожа с картой признаков и с помощью нее также может быть выполнено векторное разделение. Сеть является двумерным массивом, который содержит по одному узлу на каждый символ. Для каждого узла вычисляется евклидовое расстояние между входным вектором и непосредственно подходящим эталоном в виде веса узла. Далее берется узел с наименьшим расстоянием. Веса сети вычисляются с помощью алгоритма Кохонена, его модификаций [1] или с помощью любого другого традиционного алгоритма векторного разделения [3].

Рис. 3.Нейронная сеть Кохонена
На начальном этапе распознавания можно использовать многослойную сеть, представленную на рисунке 4, чтобы уменьшить объем векторов признаков. Для этого в многослойной сети устанавливается одинаковое количество входов и выходов, а также один или несколько скрытых слоев. Веса подбираются так, чтобы сеть могла на выходе давать любой входной вектор через небольшой слой скрытых узлов. Выходы этих узлов после обучения сети могут быть использованы в качестве входных векторов меньшей размерности для дальнейшей обработки и распознавания речи [4].
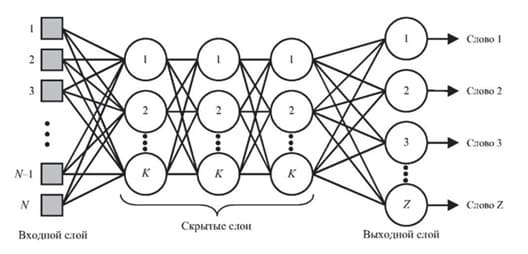
Рис. 4.Многослойная нейронная сеть
Выводы
В статье рассматривается задача распознавания речи и способ ее решения. Анализ использования нейросетевых технологий при распознавании речи показал их эффективность и быстроту распознавания. Правильный выбор типа нейросети и ее архитектуры позволяет не допускать потери данных. Также немало важен формат подачи звуковой информации на вход сети, так как необработанный звуковой сигнал не даст нужного результата.
В работе определен способ использования трех видов нейронных сетей для различных вариантов решения задачи распознавания речи. Однослойный перцептрон подходит для распознавания речи с прерывным мониторингом, многослойная сеть используется для уменьшения объема векторов признаков, а сеть Кохонена полезна для векторного разделения признаков. Такой вариант использования данных сетей позволит уменьшить ресурсные и временные затраты, а также увеличить скорость распознавания.
Литература
Бершадская О.А., Семенова А.П. Применение нейронных сетей для задачи распознавания речи. В данной работе рассматриваются задача распознавания речи и способы ее решения с применением нейросетевых технологий. Проанализированы способы преобразования звукового сигнала для подачи его на вход нейронной сети. Рассмотрены различные виды нейронных сетей и особенности их применения при распознавании речи.
Ключевые слова: распознавание речи, спектр, акустика, нейросетевые технологии, звук
Bershadskaya O.A., Semenova A.P. Application of neural networks for speech recognition tasks. In this paper, the problem of speech recognition and ways to solve it using neural network technologies are considered. The methods of converting an audio signal to feed it to the input of a neural network are analyzed. Various types of neural networks and features of their application in speech recognition are considered.
Keywords: speech recognition, spectroscopy, neural network technologies, sound