Ассистент на базе генеративного ИИ для ускорения миграции в облако
A Generative AI Assistant to Accelerate Cloud Migration
Amal Vaidya, Mohan Krishna Vankayalapati, Jacky Chan, Senad Ibraimoski, Sean Moran
Автор перевода: А. Кобец
Источник: Conference’17, July 2017, Washington, DC, USA [ссылка]
Amal Vaidya, Mohan Krishna Vankayalapati, Jacky Chan, Senad Ibraimoski, Sean Moran Ассистент на базе генеративного ИИ для ускорения миграции в облако в данной работе был представлен инструмент, который использует генеративный искусственный интеллект для ускорения миграции локальных приложений в облако. The Cloud Migration LLM принимает входные данные от пользователя указывающего параметры своей миграции, и выводит стратегию миграции со схемой архитектуры. Исследование показывает, что migration LLM может помочь неопытным пользователям найти правильный профиль облачной миграции, избегая при этом сложностей ручного подхода.
Ключевые слова: LLM, Облачная миграция, галлюцинация, автоматизация
ВВЕДЕНИЕ
За последний год стали доступны сервисы, предоставляющие доступ к мощным большим языковым моделям (LLM) через API На момент написания статьи GPT4 считается самым современным, превосходящим результаты тестов по целому ряду задач языкового моделирования [3]. Для многих вариантов использования модели, такие как GPT4, и конкуренты, такие как Calude 2 [1], работают хорошо, часто требуя только создания соответствующей подсказки. Несмотря на то, что существует библиотека LLM с открытым исходным кодом и обширным инструментарием для тонкой настройки под конкретные задачи, часто их использование нецелесообразно с точки зрения затрат или времени, когда более мощные LLM доступны напрямую [2]. Доступ к этим моделям обусловил спрос на различные инструменты на базе LLM. Мотивация для перехода в общедоступное облако включает экономию затрат, масштабируемость и гибкость, глобальный охват и доступность. Публичное облако обеспечивает практически неограниченную масштабируемость и гибкость, позволяя владельцам приложений легко настраивать свои ресурсы в соответствии со своими потребностями.
Таблица 1: Значения основных критериев оцнки для различных стратегий запросов, Default
в данном случае значит - генерация полной JSON строки
| Стиль запроса | Тосность | Задержка (с) | Сгенерировано токенов |
|---|---|---|---|
| Structured | 0.87 | 55.51 | 305 |
| Default | 0.83 | 34.27 | 403 |
Модель публичного облака с оплатой по мере использования устраняет необходимость в первоначальных инвестициях и снижает эксплуатационные расходы. Кроме того, общедоступное облако позволяет осуществлять глобальную экспансию без необходимости использования физической инфраструктуры, обеспечивая при этом надежную инфраструктуру, надежное усиление безопасности и постоянное внедрение новых сервисов и функций. Это позволяет владельцам приложений внедрять новые технологии. Для владельца приложения, который не знаком с различными продуктами публичного облака, определение стратегии миграции может занять много времени. Это требует знания рассматриваемого приложения, общедоступных облачных продуктов и любых дополнительных ограничений, определяемых внутренними требованиями. Cloud migration LLM - это инструмент, который автоматически определяет стратегию облачной миграции для приложения. Инструмент использует данные приложения, извлеченные из внутренних API, и предоставляет стратегию миграции, а также схему архитектуры для этой стратегии и ссылки на внутреннюю документацию.
СХЕМА МЕТОДА
LLM способен выполнять разнообразные задачи, последовательно формируя текст на основе контекста, установленного промптом при вводе текста в модель через.Процесс промпт-инжиниринга представляет собой процесс создания набора письменных инструкций и соответствующего контекста. Для данного сценария использования критически важно было определить задачу языкового моделирования так, чтобы выходные данные были структурированы последовательно для последующего удобного использования. При облачной миграции LLM формирует профиль миграции, который легко проверить и применить в последующих задачах.
Определение профиля миграции
Для стандартизации задачи языкового моделирования была создана простая схема данных. Миграционный профиль определяется как набор определенных пар ключ-значение. Ключи отражают соответствующие опции предлагаемой стратегии миграции, такие как "вычисления" или "база данных", где обычно есть несколько приемлемых значений, таких как "ECS" или "Aurora Postgres". Некоторые просто имеют булевые значения. Этот профиль может быть представлен в виде текста в формате JSON.
Промпт-инжиниринг
Разработка подходящего запроса необходима для обеспечения того, чтобы LLM выполнял желаемую задачу точно и надежно. Запрос должен описывать задачу и предоставлять любой необходимый контекст. Длина запроса ограничена конечным размером контекстного окна LLM, который обычно составляет несколько тысяч токенов. Для устранения неполадок и повышения производительности была разработана библиотека методов оперативного проектирования. Было показано, что однократное и многократное приглашение, случаи, когда к приглашению добавляются явные примеры ввода и желаемого результата, помогают выполнять различные задачи [2]. В этом примере однократный запрос удобно вписывается в контекстное окно. Многочисленные примеры [4][5] демонстрируют, что запрос к LLM аргументировать свой ответ или решать проблему шаг за шагом также может повысить производительность модели. Запрос, используемый в этом примере, был разработан с использованием этого метода. Известно, что LLM ошибается, генерируя текст, который синтаксически корректен, но содержит фактические неточности [2, 6]. Было разработано множество стратегий предотвращения ошибок [2]. Некоторые из них сосредоточены на обеспечении соответствия выходного текста желаемой схеме. Можно запросить LLM сгенерировать профиль миграции в виде строки, доступной для чтения в формате JSON, однако небольшая ошибка в выходных данных модели может привести к ошибке синтаксического анализа. Альтернативный подход использует несколько вызовов API, когда LLM поручается сгенерировать одно значение для каждого связанного ключа профиля миграции. Обе стратегии были протестированы.
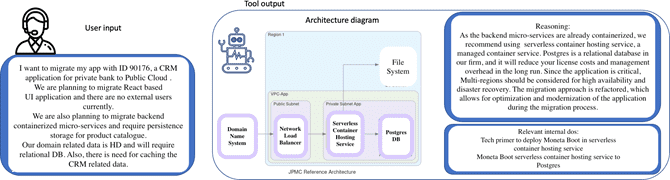
Архитектурные схемы и документация
Чтобы помочь пользователям проверить выходные данные модели, инструмент также генерирует ссылку на соответствующую внутреннюю инженерную документацию. Это делается путем использования ключевых слов из сгенерированного профиля миграции и использования эластичного поиска для извлечения соответствующих документов из внутреннего хранилища информации. Профиль миграции также используется для создания диаграммы архитектуры. На рисунке 1 показан пример
Валидация значения
Примеры входных данных с выводами, помеченными пользователем, были использованы для оценки точности восстановления двух разных стилей подсказок. Также была измерена средняя продолжительность выполнения каждого запроса, а также среднее количество токенов, сгенерированных в качестве показателя стоимости. Точность измеряется либо как соответствие строки без учета регистра, либо как логическое соответствие, в зависимости от ожидаемого значения. Исключение из этого правила относится к аргументации, которая не оценивается количественным способом. В таблице 1 показано значение этих показателей при сравнении двух разных стратегий запроса. Структурированная стратегия, при которой выполняется несколько вызовов API, каждый из которых генерирует другое значение, как правило, более точна за счет большей задержки и более высокой стоимости. Из-за требований к задержке был использован запроса по умолчанию. Отзывы пользователей в ходе исследований были положительными, в них говорилось, что инструмент особенно полезен в сложных случаях.
Развёртывание инфраструктуры
Реализованный облачный шаблон проектирования обеспечивает масштабируемость, надежность и экономичность. Отдельные сервисы упаковываются в виде образов и развертываются на бессерверном контейнерном хостинге в общедоступном облаке. Балансировка нагрузки используется для равномерного распределения трафика и обеспечения эффективного автомасштабирования. Принята 3-уровневая архитектура для достижения независимой масштабируемости и повышения безопасности базы данных. Для оптимизации производительности и снижения затрат реализовано кэширование на уровне запросов, а вводимые текстовые запросы, подсказки и выходные данные хранятся в бессерверной базе данных SQL для документов. Такой подход сводит к минимуму количество запросов, отправляемых в Open AI API, что приводит к значительной экономии средств. Кроме того, при разработке prompt используется тщательный многоступенчатый подход, позволяющий снизить риск получения неточных или нерелевантных ответов. Обратная связь по подсказке вывода используется для проверки аргументации и обеспечения того, чтобы представленные предложения были значимыми и ценными.
Выводы
Это исследование демонстрирует пример использования LLM для значительного сокращения ручной работы, необходимой для решения сложной задачи. Различные стратегии быстрого реагирования могут повлиять на точность инструмента, а также на стоимость и время ожидания. По-прежнему трудно постоянно гарантировать очень высокий уровень точности, и рекомендуется некоторая степень контроля со стороны человека.
Список использованных источников
- Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2023. A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109 (2023).
- Jean Kaddour, Joshua Harris, Maximilian Mozes, Herbie Bradley, Roberta Raileanu, and Robert McHardy. 2023. Challenges and Applications of Large Language Models. arXiv e-prints, Article arXiv:2307.10169 (July 2023), arXiv:2307.10169 pages. https://doi.org/10.48550/arXiv.2307.10169 arXiv:2307.10169 [cs.CL]
- OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems 35 (2022), 24824–24837.
- Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 (2022).
- Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi. 2023. Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models. arXiv:2309.01219 [cs.CL]