Исследование потенциала ассоциативного подхода к организации данных и проектирования систем
рук.: Анохина И.Ю., исп. Кобец А.А.
ГОУ ВПО «Донецкий национальный технический университет» (г. Донецк)
Источник: Отчет о НИР (заключ.): Донец. нац. техн. ун-т
Анохина И.Ю., Кобец А.А. Исследование потенциала ассоциативного подхода к организации данных и проектирования систем В данной работе был исследован ассоциативный подход описания данных и проектирования приложений, а также определен его потенциал, в частности, в качестве модели памяти для систем искусственного интеллекта.
Ключевые слова:ассоциативность, модель, deep, структуры данных, паттерны проектирования, системы искусственного интеллекта
ВВЕДЕНИЕ
Проектирование модели данных является неотъемлемой частью разработки. Современные классические модели данных ограничивают проектировщика жёсткой структурой связей. Ограничивая себя множественными пространствами идентификации, разработчики неизбежно сталкиваются с тем, что в процессе развития проекта стоимость наращивания его функционала, выраженная в количестве сил, требуемых для внесения изменения в кодовую базу, возрастает пропорционально времени жизни проекта, ведь при необходимости добавления новых связей или применения старых связей в новом контексте, разработчикам приходится перестраивать не просто модель данных, изменения зачастую могут распространяться на всю инфраструктуру проекта, вызывая лавинообразное увеличение количества необходимых правок. В данной статье изучается модель представления данных и подход к проектированию, способный, в теории, решить данную проблему.
1. АССОЦИАТИВНАЯ МОДЕЛЬ САЙМОНА ВИЛЬЯМСА
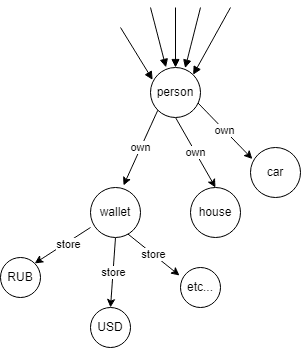
Современные подходы к хранению данных, такие как relational tables, document oriented databases, jsonb stores, предполагают сущностно единственный подход к формату хранения данных: представляя в качестве «минимальной единицы смысла» модель, такие подходы жёстко фиксируют структуру данных внутри себя (Рис. 1).
Современные подходы к хранению данных, такие как relational tables, document oriented databases, jsonb stores, предполагают сущностно единственный подход к формату хранения данных: представляя в качестве «минимальной единицы смысла» модель, такие подходы жёстко фиксируют структуру данных внутри себя (Рис. 1).
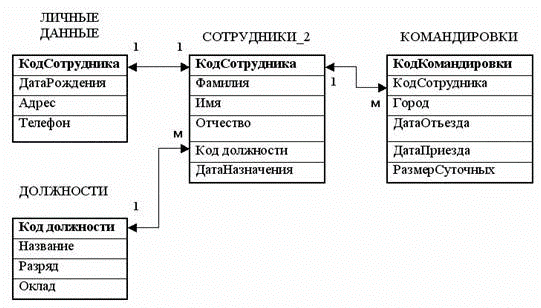
Такой подход имеет значительное число проблем [1], среди которых:
- Множество пространств адресации.
- Множество точек контроля структуры данных.
- Совместимость только на заложенном автором уровне.
- Неспособность полноценно описать что-то новое без создания еще одной таблицы/коллекции.
- Невозможность разделить предметы от отношений между ними.
Вышеописанные проблемы неизбежно будут приводить, к Legacy-коду, а значит и к необходимости проведения рефакторинга. Или, проще говоря к удорожанию проекта по мере его поддержки в долгосрочной перспективе. В оппозицию к данному подходу и была предложена ассоциативная модель данных.
Ассоциативная модель данных — это модель данных для систем баз данных. При таком подходе, данные имеющие дискретное независимое существование моделируются как объект, а отношения между ними моделируются как ассоциации.
В системе управления такими ассоциативными базами данных, сами данные и метаданные хранятся как два типа вещей: элемента, имеющего уникальный идентификатор и поле «name» и ссылки, каждая из которых имеет свой уникальный идентификатор и уникальные идентификаторы, представляющие источник, глагол и цель факта, который записан об источнике в базе данных. При этом ссылаться источник, глагол и цель может как на элемент, так и на ссылку. [2]
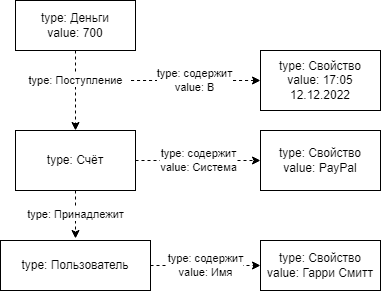
Рассмотрим, для примера, ситуацию, в которой в данной базе необходимо описать следующий факт: «На счёт PayPal принадлежащий Гарри Смиту поступили 700 у.е. в 17:05 12 декабря 2022 года». Всего 7 элементов. Четыре «существительных»: «700 у.е.», «Счёт PayPal», «Гарри Смитт», «17:05 12.12.2022» и 3 «глагола»: «поступили», «в», «принадлежащий». Графически это можно представить следующим образом:
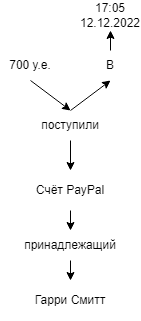
Для хранения данных необходимо 3 ссылки:
- Источник: «Счёт PayPal»; Глагол: «принадлежащий»; Цель: «Гарри Смитт»;
- Источник: «700 у.е.»; Глагол: «поступили»; Цель: «Счёт PayPal»;
- Источник: «Ссылка 2»; Глагол: «в»; Цель: «17:05 12.12.2022»;
Ассоциативная база данных может рассматривать как состоящую из двух таблиц: одну для элементов и одну для ссылок:
(Таблица 1)
| Items | |
|---|---|
| Identifier | Name |
| 0 | Счёт PayPal |
| 1 | Гарри Смитт |
| 2 | 700 у.е. |
| 3 | 17:05 12.12.2022 |
| 4 | принадлежащий |
| 5 | поступили |
| 6 | в |
(Таблица 2)
| Links | |||
|---|---|---|---|
| Identifier | Source | Verb | Target |
| 7 | 0 | 4 | 1 |
| 8 | 2 | 5 | 0 |
| 9 | 8 | 6 | 3 |
Используя реляционные БД, подобные отношения можно было бы представить примерно следующим образом:
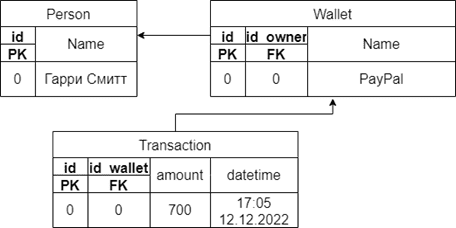
Сравнивая диаграммы на Рис. 2 и Рис. 3, можно легко убедиться, в том, что классические подходы к проектированию моделей данных вынуждают программистов описывать большое количество метаданных, мутация которых в сравнении с ассоциативным подходом значительно дороже [3]. Так, например, если заказчик при выходе на международный рынок, поставит задачу вместо универсального денежного эквивалента использовать различные валюты, вопрос изменения модели внутри ассоциативного хранилища будет лишь вопросом добавления новых сущностей при сохранении полной обратной совместимости, в то время как для традиционных баз данных это будет вопросом серии мутаций модели данных, способных вызвать неопределённое поведение на старых клиентских версиях платформы:
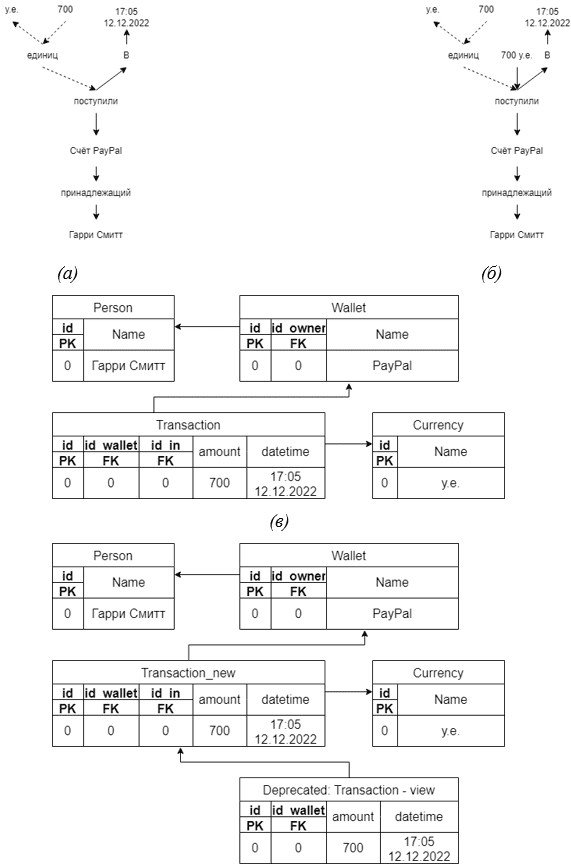
Как видно на рисунке 4 старые данные при мутации можно как продублировать (б), так и удалить, представив новым связям стандартное приведение (а). Нечто похожее можно реализовать с помощью представлений таблиц (View) в реляционных БД (г), однако, полностью описанную проблему это не решит.
Стоит так же отметить, что данный пример был синтетичен. На практике, если «существительное» ассоциативного подхода можно «разбить» на составные части, это значит, что при «квантовании» была допущена ошибка – «700 у.е.» на самом деле не дискретно и независимо. При правильном «квантовании», мутация описывалась бы лишь изменением путей связей, делая вариант (б) гораздо более дешёвым.
2. АССОЦИАТИВНАЯ МОДЕЛЬ DEEP
Развивая идею ассоциативной модели данных, можно обратиться к вопросу, «Что же есть на самом деле квант смысла?» [4]. В отличие от «кванта информации», способного не нести «полезной нагрузки» (например, бит вне контекста не значит ничего), к «минимальной единице смысла» в данном случае предъявляется более жёсткие требования. А именно наличие этого самого смысла.
В традиционных СУБД, в качестве данной единицы выступает сама модель, в ассоциативной модели данных Саймона Вильямса в качестве таких «квантов» могут выступать сущности двух типов: элементы и ссылки. Элементы в данном случае сами по себе несут некоторые конкретные значения, а ссылки описывают их взаимосвязь друг с другом.
В концепции, описанной в работе [4], идея «минимальной единицы смысла получила дальнейшее развитие. В этой парадигме «квантом» смысла является концепция Link – связь, а вся модель данных – описывается сетью связей – Links.
Идея Links очень похожа на граф, однако в отличие от деления на узлы и рёбра, ссылающиеся только на них, Links не разделяет эти пространства адресов. Это позволяет связям ссылаться на связи и нести любой смысл, который в них может заложить автор моделей данных.
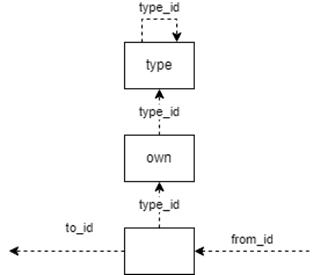
Структура единичной связи в памяти (Табл. 3), помимо её, непосредственно, значения (механика добавления которого основана на отдельных таблицах), состоит из двух обязательных полей: уникального идентификатора id связи и идентификатора типа type_id, а также необязательных полей, from_id и to_id, заполняемых одновременно и указывающих, соответственно, на начало и конец связи. from_id, to_id и type_id ссылаются на другие связи в рамках единого пространства идентификаторов, что позволяет описывать любые отношения (Рис. 6).
(Таблица 3)
| link | |||
|---|---|---|---|
| id | type_id | from_id? | to_id? |
Link, без установленного from_id и to_id играет роль узла, точки, описывающего категорию данных «Что». Если же from_id и to_id заполнены, связь играет роль отношения между узлами или связями. Она может ответить на вопрос как они связаны используя type_id.
При этом всё представленное на рисунке, является объектами Link, описываемыми в едином пространстве идентификаторов, что делает систему невероятно гибкой. А требование типизировать связь – чётко структурированной. Фактически подписи в данном примере описывают как раз типы, на которые ссылается Link в поле type_id:
Фактически в Deep, значения Link так же хранятся в виде отдельных таблиц (для number, string и object). Это необходимо для возможности указания их типизации и возможности создания дополнительных типов value.
(Таблица 4)
| string | |
|---|---|
| id_link | value |
Однако, в отличие от модели Саймона Вильямса, данный факт совершенно несущественен, так как на операционном уровне всегда происходит подстановка значений при попытке доступа. Поэтому в рамках данной работы, value описывается как необязательное поле Link:
(Таблица 5)
| link | ||||
|---|---|---|---|---|
| id | type_id | from_id ? | to_id ? | value ? |
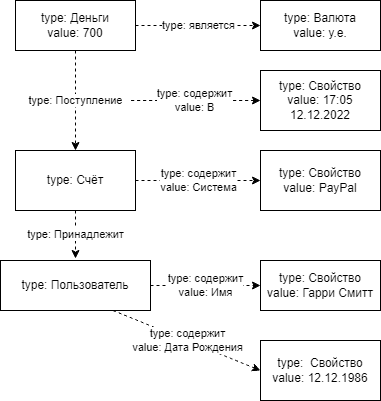
Таким образом, раннее представленный пример «На счёт PayPal принадлежащий Гарри Смиту поступили 700 у.е. в 17:05 12 декабря 2022 года» в графическом представлении будет выглядеть следующим образом:
В таком случае, база данных может рассматривать эту сеть следующим образом:
(Таблица 5)
| link | ||||
|---|---|---|---|---|
| id | type_id | from_id ? | to_id ? | value ? |
| 0 | 0 | type | ||
| 1 | 0 | содержит | ||
| 2 | 0 | Свойство | ||
| 3 | 0 | Счёт | ||
| 4 | 0 | Пользователь | ||
| 5 | 0 | Поступление | ||
| 6 | 0 | Принадлежит | ||
| 7 | 0 | Деньги | ||
| 8 | 7 | 700 | ||
| 9 | 2 | PayPal | ||
| 10 | 2 | Гарри Смитт | ||
| 11 | 2 | 17:05 12.12.2022 | ||
| 12 | 3 | |||
| 13 | 4 | |||
| 14 | 6 | 12 | 13 | |
| 15 | 5 | 8 | 12 | |
| 16 | 1 | 15 | 11 | В |
| 17 | 1 | 12 | 9 | Система |
| 18 | 1 | 13 | 10 | Имя |
И хоть табличное представление данных в таком случае получается весьма громоздким, такая структура получает одно очень значительное преимущество: она умеет накапливать опыт. Благодаря наличию единого адресного пространства, единожды созданные типы и сформированные Link можно использовать и переиспользовать с минимальными затратами на изменение при поддержке обратной совместимости:
Таким образом, можно сказать, что Deep – это концепция, некий метаязык, который сам по себе ничего не значит, но через который могут быть выражены все другие концепции. От языковых до программных [5].
3. ПОТЕНЦИАЛ АССОЦИАТИВНОСТИ
3.1. Deep как всеобъемлющее семантическое ядро
Развивая идею, авторы работы [5] представляют Deep как пространство, состоящее из связей как из минимальных единиц смысла, в котором существуют законы, позволяющие с помощью связей определять деревья, селекторы и правила для операций над связями. В связях может храниться код, который Deep самостоятельно запускает в изолированных средах в качестве реакции как на внутренние ассоциативные события, так и на внешние раздражители.
Благодаря этому и за счёт универсальности единицы смысла, внутри Deep фактически возможно создание любого продукта на любом языке программирования, использующего платформу как единую точку взаимодействия. Проект в этом случае может быть собран из различных библиотек (или, по-другому, пакетов), разрабатываемых на одном языке, расширен на других языках, путём добавления новых ассоциативных пакетов или подмены старых. При этом количество необходимых усилий при рефакторинге, как и случаев необходимости его применения становится в разы меньше. Все абстракции проекта, предприятия, науки, бизнес-плана, языка, юридической фикции, идеологической или философской формации описаны в одном месте, на одном языке и могут быть опубликованы и установлены как пакеты в пакетном менеджере.
Для достижения таких целей, предлагается преобразить подход к проектированию приложений. Если в классическом подходе программный код взаимодействует по API с программным кодом в этом или другом процессе, а данные служат лишь внутренним слоем хранения, то в Deep - все наоборот. Ассоциативные данные в центре всего. Код больше сам по себе не существует, кроме как в форме реакции на внешнюю среду или обработчика ассоциативных событий.
Ассоциативные данные доступны по единому API, в котором любые действия в системе выражены созданием/изменением/удалением связей от имени (jwt) той или иной связи.
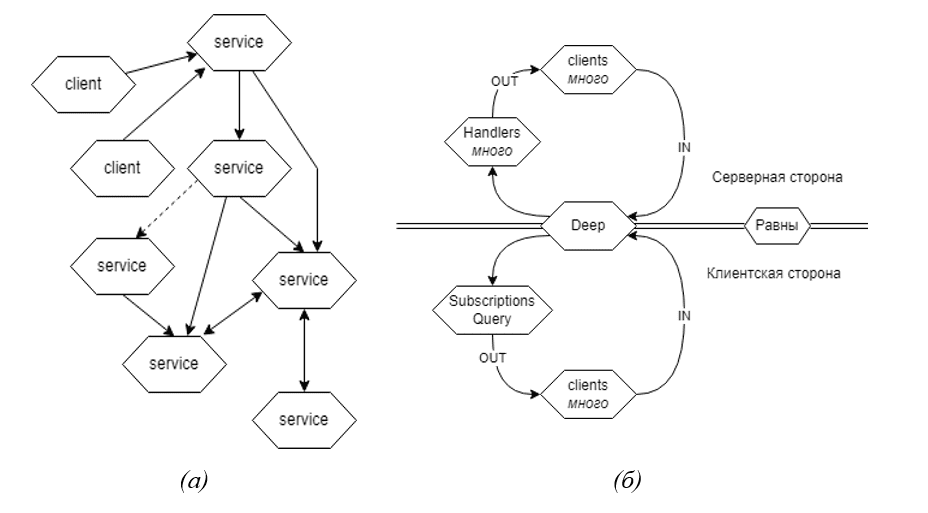
Deep предполагается, как стандарт работы с ассоциативностью. Мы обеспечим обратную совместимость стандарта, и мультиязыковую культуру доступа к разным реализациям ассоциативных хранилищ одновременно. Его структура позволяет отказаться от конкретной семантики и предоставить конструктор гибких вариантов семантики. Благодаря этому структура, фактически, говорит на языке хранимого ею смысла. Это значит, что даже если взаимодействие будет происходить на сотнях диалектов для работы с ассоциативностью в коде, внутри она останется целостной совместимой структурой.
3.2. Ассоциативность как универсальная память для систем искусственного интеллекта.
Отдельно стоит упомянуть ассоциативный подход к структуре данных в контексте систем искусственного интеллекта. Как можно было заметить из примеров выше, ассоциативные сети фактически представляют собой сети семантические. При этом ассоциативный подход к формированию структур данных имеет одно важное свойство: при таком подходе система способна накапливать опыт по мере увеличения количества смысловых единиц внутри неё.
Ассоциативный подход к хранению данных и универсальность единицы хранимого смысла в таком случае позволяет предположить, что ассоциативные хранилища могут служить хорошей кратковременной и долговременной памятью для систем искусственного интеллекта. Так, например, выступая в качестве основы для токенайзера [6] в нейросетевой модели «трансформер», и с помощью механизмов ассоциации, данный подход может помочь в формировании устойчивых и чётко прописанных правил поведения модели при её обучении, что может стать шагом на пути решения проблемы систем искусственного интеллекта как чёрного ящика.
К тому же, учитывая функционал, описанный в 3.1 данной работы, можно предположить, что ассоциативные хранилища могут стать платформой, позволяющей искусственному интеллекту по-новому взаимодействовать с ОС. Запуская систему ИИ внутри инстанции Deep, становится возможным конфигурация двусторонней связи модели с системой, т.к. сама модель находится в том же пространстве идентификаторов, что и программные модели. Т.е. сильно упрощая, можно сказать, что при использовании операционного пространства Deep в качестве платформы для модели машинного обучения, модель «начинает думать на одном с системой языке», что позволяет настраивать реакции модели на события происходящие внутри системы и наоборот – реакции системы на определённые процессы внутри модели, а так же даёт моделям машинного обучения возможность взаимодействия с элементами системы без разработки дополнительных протоколов, что несёт в себе как большое число возможностей в направлении развития ИИ, так и потенциальные опасности. Данная гипотеза требует дальнейших исследований.
ЗАКЛЮЧЕНИЕ
Ассоциативная модель – перспективный принцип организации данных внутри приложений и подход к их проектированию в целом, способный, перевернуть представление о методологии разработки приложений, позволяющий избавиться от различного рода проблем, возникающих при долгосрочной поддержке и развитии программных проектов и даже стать новой философией разработки ПО.
К тому же, данный подход к проектированию выглядит весьма перспективным с точки зрения его использования в системах искусственного интеллекта, открывая как множество возможностей для их развития, так и для потенциальных рисков для безопасности систем искусственного интеллекта, что порождает обширное поле для дальнейших исследований.
Список использованных источников
- Иван Глазунов. "Фактор рефакторинга" [Электронный ресурс]. – Режим доступа: URL: https://habr.com/ru/articles/576326/ (Дата обращения 25.05.2023).
- Williams S. The associative Model of Data / Williams Simon - Lazy Software Ltd, 2002 - 284 с.
- Joseph V. H., Paul J.K. A comparison of the relational database model and the associative database model / Joseph V. Homan, Paul J. Kovacs // Issues in Information Systems - 2009 - 6c.
- Иван Глазунов "Ассоциативные связи" [Электронный ресурс]. – Режим доступа: URL: https://habr.com/ru/articles/576398/ (Дата обращения 25.05.2023).
- Иван Глазунов "Стартап с другой планеты" [Электронный ресурс]. – Режим доступа: URL: https://habr.com/ru/articles/656879/ (Дата обращения 25.05.2023)
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin Attention Is All You Need [Электронный ресурс]. – Режим доступа: URL: https://arxiv.org/abs/1706.03762 (Дата обращения 25.05.2023)