
Abstract on the topic of graduate work
At the time of writing this abstract, the master's thesis is not yet complete. Final completion: June 2024. The full text of the work and materials on the topic can be obtained from the author or his supervisor after this date.
Table of Contents
- Introduction
- 1. Relevance of the topic
- 2. Purpose and objectives of the study
- 3. Overview of research and development
- 3.1 Review of international sources
- 3.2 Review of national sources
- 3.3 Overview of local sources
- 4. Pattern recognition using convolutional neural network
- 4.1 Architecture of a convolutional neural network
- 4.2 Training a convolutional neural network
- 4.3 VGGFace convolutional neural network architecture
- Conclusion
- List of Sources
Introduction
Despite the advances in computer vision implementation in recent years, there are still a number of unsolved problems in this area. The main challenges of computer face recognition that need to be overcome are to recognize a person from a facial image regardless of the changes in angle and lighting conditions when [1] taking a picture. In addition, with each passing year, computer vision technology is finding more and more applications in various industries and everyday life.
At present, great prospects in solving these problems are associated with the application of deep neural networks. application of deep neural networks. This class includes multilayer convolutional neural network [2,3].
Currently, the convolutional neural network and its modifications are considered the best in terms of accuracy and speed in recognizing objects in an image. accuracy and speed in recognizing objects in an image. Moreover, face recognition from a video stream from a camera shows that neural networks with this architecture are able to work in real time even on devices with the architecture is able to work in real time even on devices with limited resources. limited resources. An important factor in the proliferation of neural networks has been the ability to hardware acceleration of neurocomputing using such libraries as Nvidia CUDA and OpenCL.
1. Relevance of the topic
Facial recognition technology has been around for quite some time, but in recent years there has been a significant leap in the development and training of neural networks. a significant leap in the development and training of neural networks [4]. At present, great prospects in solving recognition problems are associated with the application of deep neural networks, which are successfully used, for example, in the well-known face recognition systems: the well-known face recognition systems: FaceNet [5], Face ID from iPhone, DeepFace from Facebook, Face++ from Chinese company Megvii [6] and others. Nevertheless, computer vision is still a long way off to the level of a living person, but at present it is reasonable to develop and use such systems for solving some problems. to be developed and used for solving some narrow point tasks.
Such a task, which can be successfully solved with the help of modern computer vision tools, is the task of automatic video registration of students' presence in the classroom with the help of neural network face recognition [7]. Of course, such systems can only be used with taking into account current legislation regarding privacy and confidentiality of personal data. If this system is used, the legal provisions related to the video recording of students will be Observed by written consent of the participants in the educational process.
2. Purpose and objectives of the study
The purpose of the research is to study convolutional neural networks, learning methods, and the study and research of the VGGFace convolutional neural network.
The objectives of the study are to:
3. Overview of research and development
This section will present research in the area of computational face recognition using convolutional neural networks, as well as related topics.
3.1 Review of international sources
Article by Mei Wang and Weihong Deng titled Deep Face Recognition: A Survey
[8], in the
this article provides a comprehensive overview of recent developments in the field of training
deep neural networks for face recognition, covering a wide range of algorithms,
databases, protocols, and applications.
A book by Michael Nielsen called Neural Networks and Deep Learning
[9].
It describes
the basic concepts of neural networks, including modern deep learning techniques,
and also provides a framework for writing your own recognition programs and systems.
образов.
Simon Hykin's book, Neural Networks. The Complete Course. Second edition
[10], which
which reviews the basic paradigms of artificial neural networks, and also
The role of neural networks in pattern recognition, control, and signal processing is analyzed.
signal processing.
3.2 Review of national sources
Article from Alexander Webere, Facial recognition technology: working principle and relevance
[4], which talks about the development of facial recognition technology, how facial recognition
recognition works, about practical implementations of the system in various industries, and also
the application of facial recognition technology in business.
The book Machine Learning Tutoria
l from the School of Data Analytics [11], which describes the
classical theory and the intricacies of implementing algorithms related to machine learning and
various neural networks.
3.3 Overview of local sources
Scientific article Fedyaeva O.I., Makhno Y.S., System of recognition of noisy and distorted graphical images based on neural network of neocognitron type
[1]
, in which the model of artificial neural network for recognizing noisy and distorted graphic images is presented and described.
and described a model of an artificial neural network for recognizing graphic images in the
presence of various kinds of distortions.
Scientific article Fedyaev O.I., Kolomoytseva I.A. Automatic registration of students'
presence at the training session using computer vision
[7].
Among the works of DonNTU master's students we would like to note a similar article by the topic by Kolbasov S.Yu,
Sorokin R.A., Solution of the problem of pattern recognition by means of convolutional neural networks
[12], which is devoted to the review of the solution of the problem of pattern recognition with the help of convolutional
neural networks.
4. Pattern recognition using convolutional neural networks
4.1 Architecture of convolutional neural network
A convolutional neural network is a class of artificial neural networks that utilize convolutional layers to filter input data to obtain useful information. The operation convolution involves combining the input data with a convolution kernel to form a a transformed feature map. The filters in convolution layers are modified based on the learned parameters to extract the most useful information for a particular task. The convolutional networks are automatically tuned to find the best feature depending on the task. This network filters object shape information in a general object recognition task objects, for example, it can extract the color of a bird when solving a bird recognition task. This based on the understanding that different classes of objects have different shapes, but different types of birds are are more likely to differ in color than in shape.
These neural networks are applied in various image processing systems, image recognition, image classification, video labeling, text-to-speech analysis, and speech analysis. image recognition, image classification, video labeling, text and speech analysis, speech recognition, natural language processing, text classification, as well as in modern systems for image processing, video labeling, text and speech analysis, text and speech, natural language processing, text classification, as well as in modern systems of artificial intelligence systems such as robots, virtual assistants, and self-driving automobiles.
It consists of several layers, each with a different function:
- Convolution Layer - convolves the input data with a filter to create feature maps. Filters can detect various image characteristics such as lines, angles and textures.
- Merge Layer - reduces the size of feature maps while retaining the most relevant characteristics.
- Activation Layer - introduces non-linearity into the model, making it more flexible and capable of handling complex data.
- Full-link layer - receives the feature map and compresses it into a one-dimensional array, which is passed to the subsequent layer.
- Output layer - computes the output of the model.
A convolutional neural network uses a combination of these layers to form a sort of stack of layers layers. Depending on the task at hand, these layers may vary in proportion and number. number. But in general, the combination and the sequence of layers is aimed at extracting features from the input data, from which the network can learn to classify the data.
Convolutional neural networks also improve the ability to detect unusually located objects by using pooled layers for limited invariance under translation and rotation. Layer pooling also allows more convolutional layers to be used, reducing the memory consumption. Normalization layers are used to normalize local input regions by normalizing all input data in the layer to a mean equal to zero and a variance, equal to one. Other regularization methods can also be used, such as batch normalization, where the activation for the entire batch is normalized, or dropout, where we ignore the randomly selected neurons during the training process. Fully connected layers have neurons which are functionally similar to convolutional layers, but differ in that they are connected to all the activations in the previous layer.
More modern convolutional neural networks utilize inference modules that use the 1×1 convolutional kernels to further reduce memory consumption and more efficiently computation, and hence learning. This makes this network suitable for a number of applications of machine learning.
Input modules in a convolutional neural network allow you to create deeper and larger layers of convolutions, while accelerating the computation at the same time. This is achieved by using convolutions 1×1 with a small feature map size, e.g. 192 feature maps of size 28×28 can be reduced to 64 feature maps of size 28×28 by using 64 1×1 convolutions. Due to the reduced size, these 1×1 convolutions can be supplemented by larger convolutions of sizes 3×3 and 5×5. In addition to the 1×1 convolution, maximum union can also be used to reduce the dimensionality. union. At the output of the initial module, all large convolutions are merged into a large feature map. which is then fed to the next layer (see Fig. 1) [13].
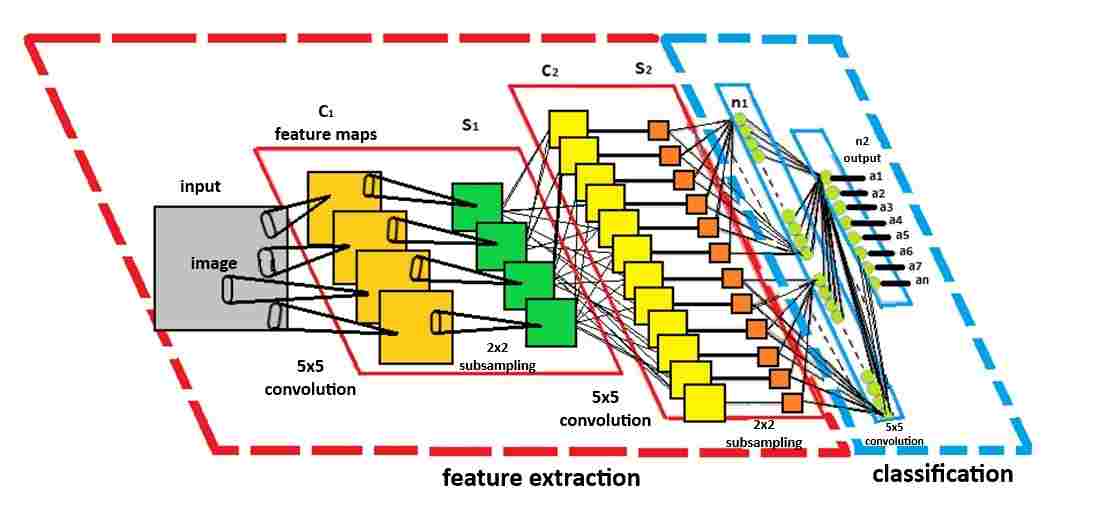
Figure 1 – Architecture of a convolutional neural network
The activation function in a neural network applies a nonlinear transformation to weighted input data. A popular activation function for a convolutional neural network is the ReLu or rectified linear function that zeroes out negative input data, see the formula below. The rectified linear function speeds up training without compromising accuracy.
Input modules in a neural network allow for deeper and larger convolution layers, while at the same time speeding up the computation. This is achieved by using 1×1 convolutions with a small feature map size. feature maps, e.g. 192 feature maps of size 28×28 can be reduced to 64 feature maps of size 28×28 using 64 1×1 convolutions. Due to the reduced size, these 1×1 convolutions can be augmented with with larger convolutions of sizes 3×3 and 5×5. In addition to the 1×1 convolution, maximum union can also be used to reduce the dimensionality. also use maximum pooling. At the output of the initial module, all large convolutions are merged into a large feature map, which is then fed to the next layer, or the initial module.
One of the advantages of a convolutional neural network is pooling. Pooling is a procedure that reduces the input data in a certain area to a single value. In convolutional neural networks, this concentration of information provides similar information for outgoing connections with less memory consumption. Pooling provides basic invariance to rotations and translations and improves the convolutional networks' ability to detect objects. For example, a face in an image segment that is not in the center of the image but is slightly displaced, can still be detected by convolutional filters because the information is brought to the right place by the merging operation. The larger the size of the pooling region, the more information is compressed, resulting in thin networks, which can more easily fit into GPU memory. However, if the merge region is too large, too much information is discarded and the prediction performance decreases [9].
4.2 Training a convolutional neural network
The procedure that is used for the learning process is called a learning algorithm. This procedure arranges the synaptic weights of the neural network in a certain order to provide the necessary neuronal connectivity structure.
Changing synaptic weights represents a traditional method for tuning neural networks. This approach is very close to the theory of linear adaptive filters, which has long been claimed and applied in various fields of human activity. various fields of human endeavor. However, neural networks can change their own topology. This is due to the fact that neurons in the human brain are constantly dying off, and new synaptic connections are constantly being made.
Like multilayer perceptrons and recurrent neural networks, convolutional neural networks can also be trained using gradient-based optimization techniques. To optimize the parameters of a neural network, stochastic, batch or mini-batch gradient descent algorithms can be used. Once the network is trained, it can accurately predict the output when presented with input data, this process is called inference of the neural network. To perform inference, the trained neural network can be deployed on a variety of platforms ranging from cloud computing, enterprise data centers data centers to edge devices with limited resources. The deployment platform and the type of application impose unique requirements on latency, throughput, and size of the application at runtime. For example, a neural network performing lane recognition in a car must have low latency and a small runtime application size. On the other hand, a data center, identifying objects in video streams must process thousands of video streams simultaneously, requiring high throughput and efficiency [14].
Various methods and formulas are used to train a convolutional neural network, but the most popular and the most popular and the simplest is the method of error back propagation. Thanks to this method it is possible to correct adjustment of weights of links between all layers, due to which the value of the error function is reduced and the network is trained. decreases and the network is trained. The magnitude of the error is determined by the following formula as the RMS error:
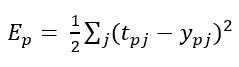
where, Ep is the magnitude of the error function for image p; tpj is the desired output of neuron j for image p; ypj is the activated output of neuron j for image p. The unactivated state of each neuron j for image p is written as a weighted sum according to the formula:
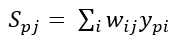
where, Spj is the weighted sum of the outputs of the connected neurons of the previous layer by the connection weight, otherwise still denoted as the unactivated state of neuron j for image p; wij - is the connection weight between i and j neurons; ypi is the activated state of neuron j of the previous layer of image p. The output of each neuron j is the value of the activation function fj, which puts the neuron into the activated state. As an activation function any continuously differentiable monotonic function can be used. The activated state of a neuron is calculated by the following formula:
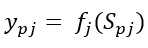
where, ypj is the activated state of neuron j for image p; fj is the activation function; Spj - is the non-activated state of neuron j for image p. As a method of error minimization the method of gradient descent is used, the essence of this method is reduced to the search for the minimum or the maximum of the function by moving along the gradient vector. To find the minimum, the movement should be carried out in the direction of the antigradient. The gradient of the loss function is a vector of partial derivatives, which is calculated by the formula:
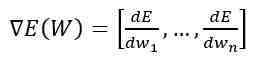
where, E(W)- gradient of the loss function from the weight matrix; dE/dw - partial derivative of the error function by neuron weight; n is the total number of weights of the network. And the derivative of the error function by a particular image can be written by the chain rule.
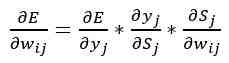
where, ∂E/∂wij is the value of the derivative of the error function by weight wij, between i and j neurons; ∂E/∂yj is the error of neuron j; ∂yj/∂Sj is the value of the derivative of the activation function by its argument for neuron j; ∂Sj/∂wij - output i of the neuron of the previous layer, with respect to neuron j. The essence of the algorithm of the inverse error propagation is the sequential calculation of the errors of the hidden layers using the error values of the output layer, the error values propagate through the network in the reverse direction from output to input. The error for the hidden layer is calculated by the formula:
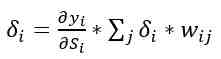
where, ∂yi)/∂Si is the value of the derivative of the activation function by its argument for neuron j; δi - error of neuron i of the hidden layer; δj - error of neuron j of the next layer; wij - weight of the connection between neuron i of the current hidden layer and neuron j of the output or exactly the same layer layers [15].
As an example of neural network training, we can take sign recognition as an example (see Fig. 2). The input image of a road sign is filtered by 4 convolutional kernels 5×5, which generate 4 feature maps, these feature maps are subsampled by maximum pooling. The next layer applies 10 convolution kernels 5×5 to these subsampled images and again merges the feature maps. The last layer is a fully connected layer where all the generated features are combined and used in the classifier, essentially a logistic regression.
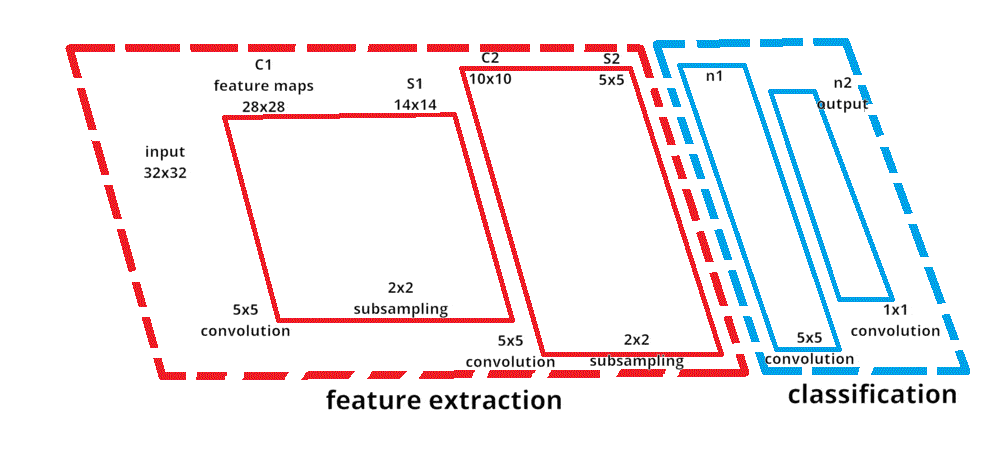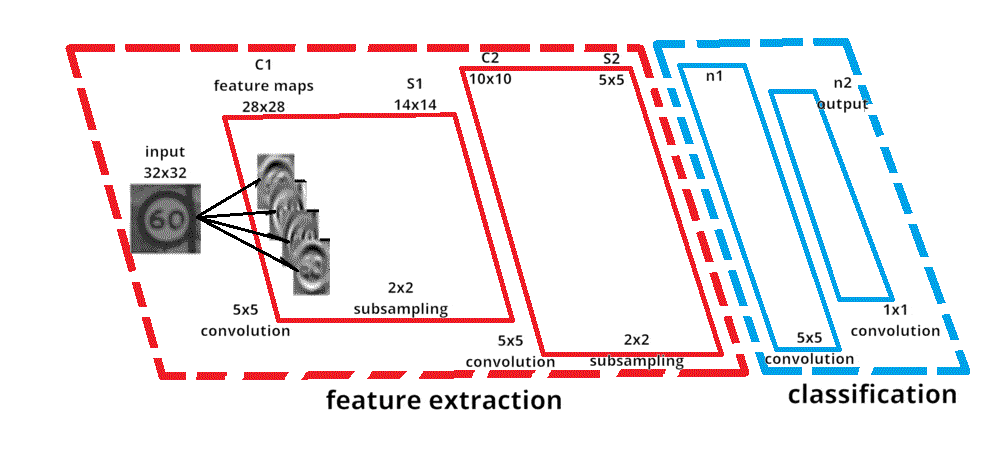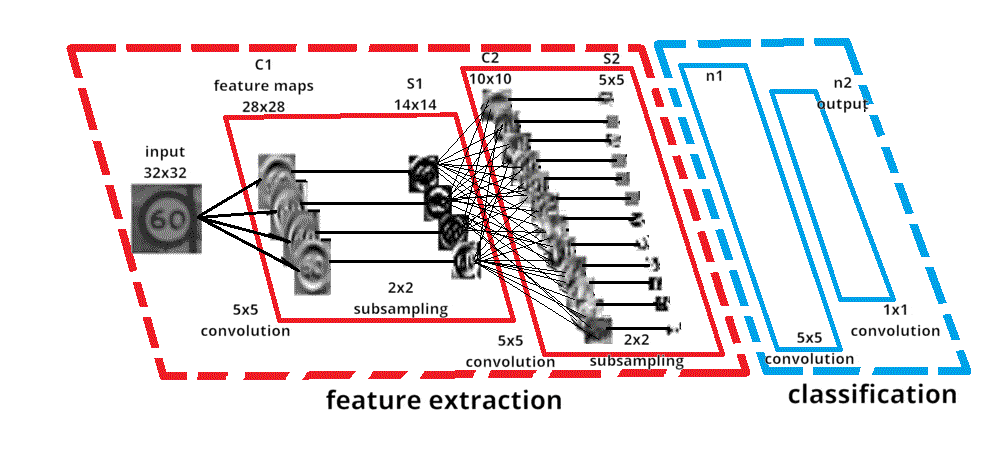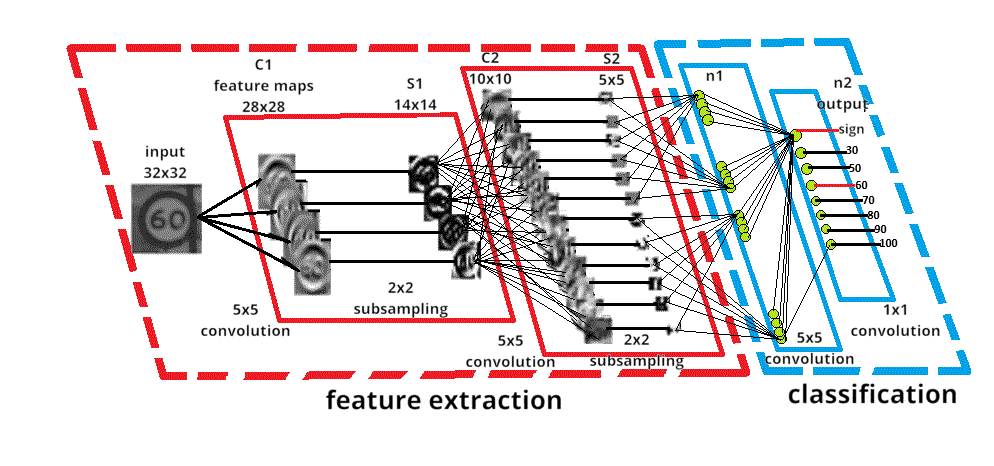
Figure 2 – Recognizing a road sign
The number of repetitions is 10 and the duration of one repetition is 90ms, size 100 kB
4.3 VGGFace convolutional neural network architecture
Face recognition in this system is performed using a multilayer convolutional neural network VGGFace, which is a modification of an earlier model VGG16, developed in 2013 by K. Simonyan and A. Zisserman from the University of Oxfordshire [16]. Since the VGGFace model is a a pre-trained neural network, the natural question is how well will it will recognize students whose faces were not included in its training.
The multilayer architecture of VGGFace consists of convolutional layers and subsampling layers layers, which alternate with each other (see Figure 3).
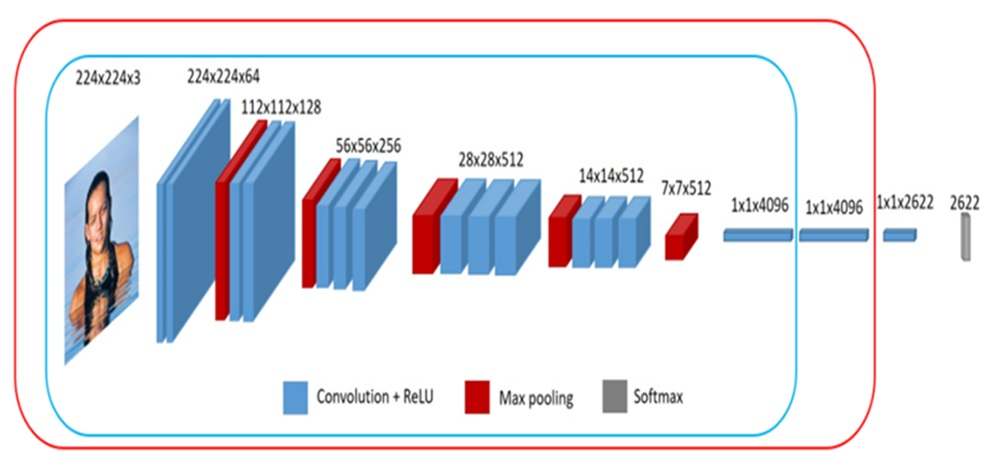
Figure 3 – Structure of VGGFace multilayer neural network
The sequential operation of the neural network layers is organized in such a way that the transition from specific features of the image to more abstract details, and then to even more abstract ones. The convolution operation plays a key role in this process:
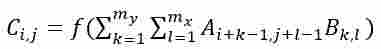
where A - matrix of size (nx × ny); B - matrix (convolution kernel) of size (mx × my); C - resulting matrix of size [(nx-mx+1)×(ny-my+1)]; i=1,2,..., nx-mx+1; j=1,2,..., ny-my+1, f() is the activation function. The subsample layer as well as the convolutional layer has maps, but their number is the same as the previous (convolutional) layer layer. Its task is to reduce the dimensionality of the maps of the previous layer.
For face feature extraction, the convolutional neural network has been pre-trained by its creators on examples of photos of 2622 people (1000 photos per person)[7, 16].. The network is tuned to classification of the recognized face using faces from the training set as classes. Therefore, the result of the network is a 2622-dimensional vector, each element of which is a represents the probability of similarity of the face to one of the training set. Two face images are said to be belong to the same person if they are equally similar to each face from the training set. For this purpose, the feature vectors of these images in the space of faces from the training set must form a sufficiently sharp angle between them.
Conclusion
Thus, neural network training is reduced to minimizing the error function by adjusting the weight coefficients of synaptic connections of neurons in the layers of the network. Due to the peculiarities of the architecture, training of a multilayer network allows by means of layer-by-layer analysis of images to identify characteristic features of recognized objects and classify them.
Since the convolutional neural network is well established in Google projects (for searching among user's user's photos), Amazon (for generating product recommendations), Pinterest (for personalizing user's user's homepage), it can be effectively used to build various systems of computer vision, including the system of visual control of students' presence in the classroom. based on a deep neural network.
List of Sources
- Федяев О.И., Махно Ю.С. Система распознавания зашумлённых и искажённых графических образов на основе нейронной сети типа неокогнитрон // Одиннадцатая национальная конференция по искусственному интеллекту с международным участием КИИ-2008: Труды конференции. Т. 3. – М.: ЛЕНАНД, 2008. – С. 75–83.
- Гудфеллоу Я., Бенджио И., Курвилль А. Глубокое обучение / пер. с анг. А.А.Слинкина. – 2-е изд., испр. – М.: ДМК Пресс, 2018. – 652 с.
- Le Cunn Y, Bengio Y. Convolutional neural networks for Images, Speech and Time Series, AT&T Laboratories, 1995. – Р. 1 – 14.
- Блог Faceter. Технология распознавания лиц: принцип работы и актуальность [Электронный ресурс] / Интернет-ресурс. Режим доступа: https://faceter.cam/ru/blog/.... – Загл. с экрана.
- FaceNet — пример простой системы распознавания лиц с открытым кодом Github [Электронный ресурс] / Интернет-ресурс. Режим доступа: https://neurohive.io/ru/tutorial/.... – Загл. с экрана.
- Training Data. Распознавание лиц для машинного обучения технологии, процесс обучения [Электронный ресурс] / Интернет-ресурс. Режим доступа: https://trainingdata.solutions/metodic/.... – Загл. с экрана.
- Федяев О.И., Коломойцева И.А. Автоматическая регистрация присутствия студентов на учебном занятии с помощью компьютерного зрения // XXI Национальная конференция по искусственному интеллекту с международным участием КИИ-2023 (Смоленск, 16-20 октября 2023 г.). Труды конференции. В 2-х томах. Т.1. – Смоленск: Принт-Экспресс, 2023. – С. 294-303.
- Mei Wang, Weihong Deng. Deep Face Recognition: A Survey, National Key R&D Program of China and BUPT Excellent Ph.D. Students Foundation, 2020. – P. 1 – 31.
- Nielsen, Michael “Deep Learning”. Neural Networks and Deep Learning, 2017. – P.1 – 224.
- Хайкин С. Нейронные сети. Полный курс. Второе издание [Текст] / Саймон Хайкин // Издательский дом «Вильямс», 2006. – С. 1104
- Учебник по машинному обучению. Школа анализа данных [Электронный ресурс] / Интернет-ресурс. Режим доступа: https://education.yandex.ru.... – Загл. с экрана.
- Решение проблемы распознавания образов при помощи свёрточных нейронных сетей // Материалы Х Международной научно-технической конференции Информатика, управляющие системы, математическое и компьютерное моделирование (ИУСМКМ - 2019) - Донецк: ДонНТУ, 2019. - с. 111-114.
- Сверточные нейронные сети. NVIDIA DEVELOPER [Электронный ресурс]. – Режим доступа: https://developer.nvidia.com/discover/.... – Загл. с экрана.
- Искусственная нейронная сеть. NVIDIA DEVELOPER [Электронный ресурс]. – Режим доступа: https://developer.nvidia.com/discover/.... – Загл. с экрана.
- Обратное распространение в сверточных нейронных сетях. DeepGrid [Электронный ресурс]. – Режим доступа: https://www.jefkine.com/general/.... – Загл. с экрана.
- Blog. Great Learning. Introduction to VGG16 | What is VGG16? [Электронный ресурс]. - Режим доступа: https://www.mygreatlearning.com/blog/.... – Загл. с экрана.