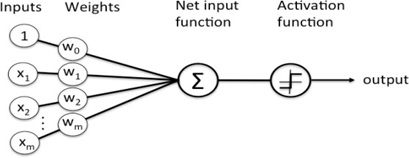
Рисунок 1 - Нейронный узел
Авторы: Dr. Priya Guptaa, Nidhi Saxenaa, Meetika Sharmaa, Jagriti Tripathia
Автор перевода:А. А. Суханов
Источник:
International Journal of Engineering and Manufacturing. – 2018. – Vol. 8, No. 1. – P. 63 - 71.
Распознавание лиц, процесс идентификации людей по изображениям лиц, имеет множество практических применений в области биометрии, информационной безопасности, контроля доступа, охраны правопорядка, смарт-карт и систем видеонаблюдения. Конволюционные нейронные сети (CovNets), один из видов глубоких сетей, доказали свою эффективность для FR. Для систем реального времени перед использованием CovNets необходимо выполнить некоторые шаги предварительной обработки, например, выборку. Но и в этом случае на вход CovNets передаются полные изображения (все значения пикселей), и все этапы (выбор признаков, извлечение признаков, обучение) выполняются сетью. Именно по этой причине реализация CovNet иногда бывает сложной и трудоемкой. CovNets находятся на стадии становления, а полученные точности очень высоки, поэтому им предстоит пройти долгий путь развития. В статье предлагается новый способ использования глубоких нейронных сетей (еще один тип глубоких сетей) для распознавания лиц. В этом подходе вместо исходных значений пикселей на вход подаются только извлеченные черты лица. Это снижает сложность и при этом обеспечивает точность 97,05 % на наборе данных лиц Йеля.
Ключевые слова: Распознавание лиц, каскад Хаара, глубокие нейронные сети, конволюционные нейронные сети, softmax.
Система распознавания лиц идентифицирует лицо, сопоставляя его с базой данных лиц. В последние годы она достигла большого прогресса благодаря улучшению дизайна и обучения признаков и моделей распознавания лиц [1]. Поскольку люди обладают исключительной способностью распознавать людей независимо от их возраста, условий освещения и различных выражений лица. Цель исследователей - разработать систему FR, которая могла бы соответствовать или даже превосходить человеческий уровень распознавания, который составляет почти 97,5 %.
Методы, используемые в лучших системах распознавания лиц, могут зависеть от области применения системы. Системы распознавания лиц можно разделить на две большие категории:
Традиционный процесс распознавания лиц состоит из четырех этапов: обнаружение лица, выравнивание лица, представление лица (или извлечение признаков) и классификация [2]. Предлагаемый метод извлекает черты лица из входных изображений и подает их в глубокие нейронные сети для обучения и классификации (используется слой softmax). Архитектура сети очень гибкая, и слои могут быть добавлены или удалены для достижения наилучших результатов. В последнее время существует множество библиотек, функций и платформ для создания и модификации сетей.
CovNets - это специализированный вид нейронных сетей для обработки данных, имеющих известную топологию, похожую на сетку. Эти сети добились огромного успеха в практических приложениях, включающих данные временных рядов, которые можно представить как одномерную сетку, берущую образцы через регулярные временные интервалы, и данные изображений, которые можно представить как двумерную сетку пикселей. Конволюционные сети - это просто нейронные сети, которые используют свертку вместо общего умножения матриц по крайней мере в одном из своих слоев. Название "сверточная нейронная сеть" указывает на то, что в ней используется математическая операция, называемая сверткой. Свертка - это специализированный вид линейной операции [3].
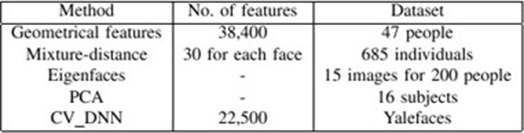
Недавно множественные CovNets или глубокие CovNets показали хорошие результаты для верификации лиц. Согласно Yi Sun et.al [1], существующие методы обычно решают проблему FR в два этапа: извлечение признаков (разработка или изучение признаков из каждого изображения лица отдельно для получения лучшего представления) и распознавание (вычисление балла сходства между двумя сравниваемыми лицами с использованием представления признаков каждого лица [1]. Для распознавания лиц (FR) ранее было реализовано множество подходов, таких как использование нейронных сетей [3,4,6], геометрических признаков, собственных лиц, сопоставление шаблонов и сопоставление графов. Нейросети CovNets показали многообещающие результаты для FR [2,4,5,7,8,9]. Метод автоматического извлечения признаков с использованием коэффициентов расстояний, представленный Канаде [7], использовал геометрические признаки и показал скорость распознавания в пределах 45-75% при использовании базы данных из 20 человек.
Для уменьшения размерности можно использовать такие подходы, как самоорганизующиеся карты (SOM) и преобразование Кархунена-Лоэва (KL), из которых SOM оказался эффективным алгоритмом [3]. Для этой же цели успешно применяется анализ главных компонент (PCA) [3, 4]. Хотя CovNets показали многообещающие результаты для FR, разработка хорошей архитектуры CovNet для конкретной задачи классификации остается неоднозначной из-за отсутствия теоретических рекомендаций [3]. Согласно [6], CovNet-Restricted Boltzmann Machine (RBM) показала точность 97,08% для сопоставления двух изображений одного и того же человека в условиях отсутствия ограничений.
Брунелли и Поджио [8] вычислили набор геометрических признаков, таких как ширина и длина носа, положение рта и форма подбородка. Они сообщили о скорости распознавания в 90 % на базе данных из 47 человек. Однако они показали, что простая схема сопоставления шаблонов показывает 100 %-ное распознавание для той же базы данных. Кокс и другие [9] представили метод смешанного расстояния, который позволил достичь скорости распознавания 95 %, используя базу данных запросов из 95 изображений, где каждое лицо было представлено 30 вручную извлеченными признаками.
Пентланд и другие [5,12] показали хорошие результаты на большой базе данных (95 % распознавания 200 человек из 3000). Трудно делать широкие выводы, поскольку многие изображения одних и тех же людей выглядели очень похожими [10]. В работе [10] Ладес и др. представили архитектуру динамических связей для распознавания объектов с инвариантом искажений, которая использует эластичное сопоставление графов для поиска ближайшего хранимого графа. Это разреженные графы, вершины которых помечены мультиразрешающим описанием в терминах локального спектра мощности, а ребра - геометрическими расстояниями. Они представили хорошие результаты, используя базу данных из 87 человек и тестовые изображения, состоящие из различных выражений и лиц, повернутых на 15°. Процесс сопоставления требует больших вычислительных затрат: при использовании параллельной машины с 23 транспьютерами на сопоставление с 87 сохраненными объектами уходит примерно 25 с. Таким образом, Eigen faces - это быстрый, простой и практичный алгоритм. Однако его возможности могут быть ограничены, поскольку для оптимальной работы требуется высокая степень корреляции между интенсивностями пикселей обучающего и тестового изображений [3]. Другим подходом к распознаванию лиц является сопоставление графов.
Викотт и другие [12] использовали обновленную версию методики и сравнили 300 лиц с 300 различными лицами тех же людей, взятых из базы данных Face Recognition Technology (FERET). По их данным, процент распознавания составил 97,3 %.
В условиях ограниченного окружения созданные вручную признаки, такие как локальные бинарные паттерны (LBP) [16] и локальное фазовое квантование (LPQ) [15,17], получили достойную оценку в FR. Однако их эффективность резко снижается, когда они применяются к изображениям, полученным в неограниченных условиях, например, при изменении положения лица, его выражения и освещенности.
Высокоуровневое распознавание обычно моделируется со многими этапами обработки, как в парадигме Марра: от изображений к поверхностям, от трехмерных (3D) моделей к сопоставленным моделям [10]. Однако Терк и Пентланд [18] утверждают, что существует также процесс распознавания, основанный на обработке двумерных (2D) изображений. Они представили схему распознавания лиц, в которой изображения лиц проецируются на главные компоненты исходного набора обучающих изображений. Полученные собственные лица классифицируются путем сравнения с известными лицами [3].
Ни один из предыдущих методов не использовал идею подачи только извлеченных признаков в глубокие нейронные сети для решения задачи FR. В статье предлагается использовать каскад Хаара (фронтальное лицо) для предварительной обработки изображений, которые затем подаются на вход глубоких нейронных сетей для распознавания лиц, вместо того чтобы напрямую передавать значения пикселей в CovNets.
Нейронная сеть - это алгоритм, созданный на основе человеческого мозга и предназначенный для распознавания закономерностей в числовых массивах данных. Для использования нейронных сетей данные реального мира, например, изображения, текст, аудио, видео и т. д., необходимо преобразовать в числовые векторы. Нейронная сеть состоит из различных слоев, а слой состоит из нескольких узлов. В зависимости от типа шаблона, который пытается выучить нейронная сеть, каждому входному сигналу, поступающему в узел, присваивается определенный вес. Эти веса определяют важность входных данных для получения конечного результата. Взвешенная сумма входных данных вычисляется и в зависимости от некоторых пороговых смещений определяется выход для узла. Сопоставление входных данных с выходными осуществляется некоторой функцией активации.
Цель нейронной сети - аппроксимировать некоторую функцию f. Задача простого классификатора y = f(x) - сопоставить входные данные x классу y, а нейронная сеть определяет параметр β, который приводит к наилучшей аппроксимации функции y = f(x,β).
Рисунок 1 - Нейронный узел
Простая нейронная сеть - это сеть таких функций, которые можно определить как f(x) = f3(f2(f1(x))). В этой цепочке f1 называется первым слоем, аналогично f2 - вторым и так далее. Длина этой цепочки определяет глубину нейронной сети. Последний слой называется выходным. Схематическое изображение нейронной сети показано на рис. 2. Во время обучения желаемый выход каждого слоя не виден, поэтому средние слои называются скрытыми. Глубокая нейронная сеть (ГНС) - это искусственная нейронная сеть (ИНС) с прямым управлением, с несколькими скрытыми слоями и более высоким уровнем абстракции.
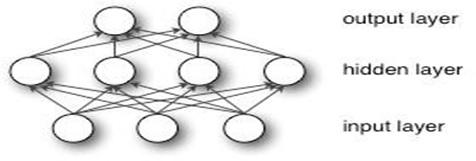
Рисунок 2 - Небольшая нейронная сеть
Ширина DNN определяется размерностью скрытого слоя. Значения скрытого слоя вычисляются с помощью функции активации. Обучение в глубоких нейронных сетях требует минимизации функции стоимости, например, в случае классификации функция стоимости - это разница между фактической и предсказанной меткой. Обычно для этого используется градиентный спуск. В современных нейронных сетях в качестве функции активации рекомендуется использовать прямолинейный блок или relu. Активация одной скрытой единицы h(i) дается следующим образом
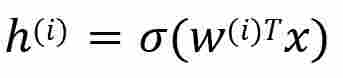
Где σ() - это функция tanh w(i), вектор весов для каждого скрытого блока, а x - вход. Она дает нелинейное преобразование, но при этом остается очень близкой к линейности, что позволяет легко оптимизировать линейные модели методом градиентного спуска [13,20].
Как правило, ограниченные данные приводят к проблеме избыточной подгонки в DNN. Чтобы избежать этого, используется метод dropout [6].
Он случайным образом удаляет некоторые узлы из слоев, основываясь на их вероятности. Выпадение
означает временное удаление узлов вместе
с их входящими и исходящими ребрами. это показано на рисунке 3.
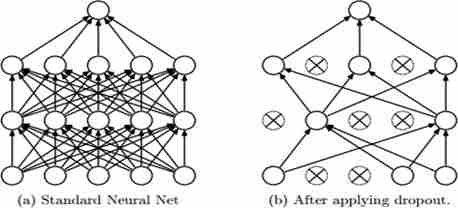
Рисунок 3 - Нейросетевая модель отсева
В следующих подразделах рассматриваются компоненты новой системы. Подход предлагает использовать фронтальное лицо в каскаде Хаара (определенном в opencv) для предварительной обработки входных изображений и подачи только лицевых признаков в сеть для обучения и классификации. Для FR на наборе данных yalefaces выполняются следующие шаги.
Выбор признаков - это процесс отбора полезных признаков и оставления лишних. Извлечение признаков - это процесс объединения нескольких признаков в один признак. В предлагаемом подходе для выбора и извлечения признаков используется фронтальное лицо, которое принимает изображение в качестве входных данных и возвращает только значения ключевых признаков лица, присутствующих на изображении. Сначала он обнаруживает лицо на изображении (выбор признаков, представляющих лицо на полном изображении), а затем извлекает признаки лица (например, составляет набор признаков, обозначающих глаза, нос, губы на изображении), как показано на рисунке 4.
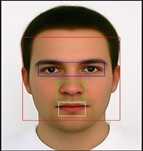
Рисунок 4 - Особенности лица на изображении
Многослойная глубокая нейронная сеть с обратной связью предназначена для обучения упрощенным признакам, полученным на предыдущем этапе. Для повышения эффективности обучения добавляется несколько наборов активационных, плотных (полностью связанных) и отсеивающих слоев. После каждого набора количество признаков уменьшается, что позволяет использовать только важные признаки для классификации в последнем слое. Архитектура сети показана на рисунке 5. Эта сеть обучена на 50 эпохах, точность обучения и тестирования показана на рисунке 6, а потери - на рисунке 7. Как видно, точность увеличивается с ростом числа итераций. Дальнейшее увеличение числа итераций или количества эпох до 75 или 100 приводит к той же конечной точности, поэтому 50 является наиболее эффективным значением.
Последний слой сети - softmax - используется для классификации. Это связано с тем, что извлеченные черты лица просто хранятся для обучающих изображений. У каждого авторизованного лица будет свой класс, и входное изображение должно принадлежать к одному из классов. Если оно совпадает с любым из изображений, имеющихся в базе данных, система разрешит человеку войти в охраняемое помещение или получить доступ к частной информации.

Рисунок 5 - Используемая архитектура DNN
Метод предлагаемой системы FR определяется следующим образом. Используется набор данных Yalefaces A
Предложенный метод был протестирован на базе данных Yaleface, состоящей из черно-белых изображений 15 образцов, каждый из которых содержит 11 изображений в различных выражениях, что в общей сложности составляет 165 изображений. Один из образцов показан на рисунке 7. Изображения для одного субъекта с различным выражением лица или конфигурацией: освещенное по центру, в очках, счастливое, освещенное слева, без очков, нормальное, освещенное справа, грустное, сонное, удивленное и подмигивающее. Категории определяются как субъекты вместе с метками, поэтому всего классов 15. Весь набор данных разделен на две части: 148 изображений для обучения и 17 для тестирования. Итоговая средняя точность вычисляется на слое softmax путем проверки количества тестовых образцов, которые идентифицированы правильно. Идея реализована на системе Python 3.5.3 (64 бит). Для предварительной обработки используется пакет Opencv с использованием фронтального признака лица каскада Хаара. Создание и обучение нейронной сети осуществляется с помощью пакетов keras, theano и tensorflow (доступных в python). Итоговая средняя точность, достигнутая в предложенной системе, составляет 97,05 %, что близко к точности распознавания человеческого лица, составляющей почти 97,5 %. Сравнительный анализ с некоторыми из предыдущих систем FR представлен в таблицах.
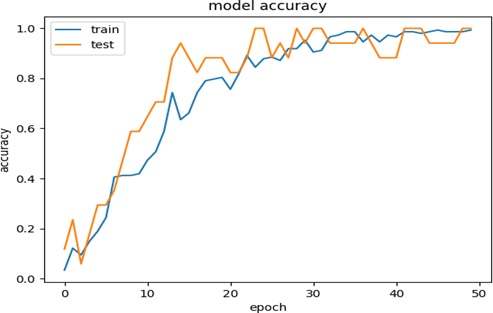
Рисунок 6 - График, показывающий точность тестирования и обучения
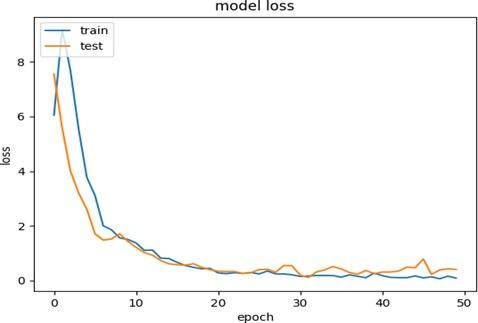
Рисунок 7 - Потери

Рисунок 8 - Набор данных Yalefaces
Таблица 1. Точность системы FR

Таблица 2. Детали вышеуказанной системы FR
Использование каскада Хаара для извлечения признаков лица и подачи их вместо необработанных значений пикселей помогает снизить сложность системы распознавания на основе нейронных сетей, так как уменьшается количество избыточных входных признаков. Кроме того, использование DNN вместо CovNets делает процесс более легким и быстрым. Кроме того, точность распознавания в предложенном методе не страдает, так как средняя точность составляет 97,05 %. Несмотря на то, что добавляется еще один шаг извлечения черт лица из каждого изображения, процесс все же лучше для небольших наборов данных.