Abstract. The article deals with the process of face recognition. Neural networks are studied and examined, examples of artificial intelligence and the use of face and image recognition systems are given. Keywords: deep neural networks, face recognition, perceptrons, augmentation, normalization.
Neural networks, also known as artificial neural networks or simulated neural networks, are a subset of machine learning and underlie deep learning algorithms. Their name and structure are inspired by the human brain, mimicking the way human brain neurons send signals to each other.
Neural networks consist of node layers containing an input layer, one or more hidden layers, and an output layer (Fig. 1). Each node, or artificial neuron, is connected to another and has a corresponding weight and threshold. If the output of any individual node exceeds a given threshold value, that node is activated node is activated, transmitting data to the next layer of the network. Otherwise, no data is transmitted to the next layer of the network[4].
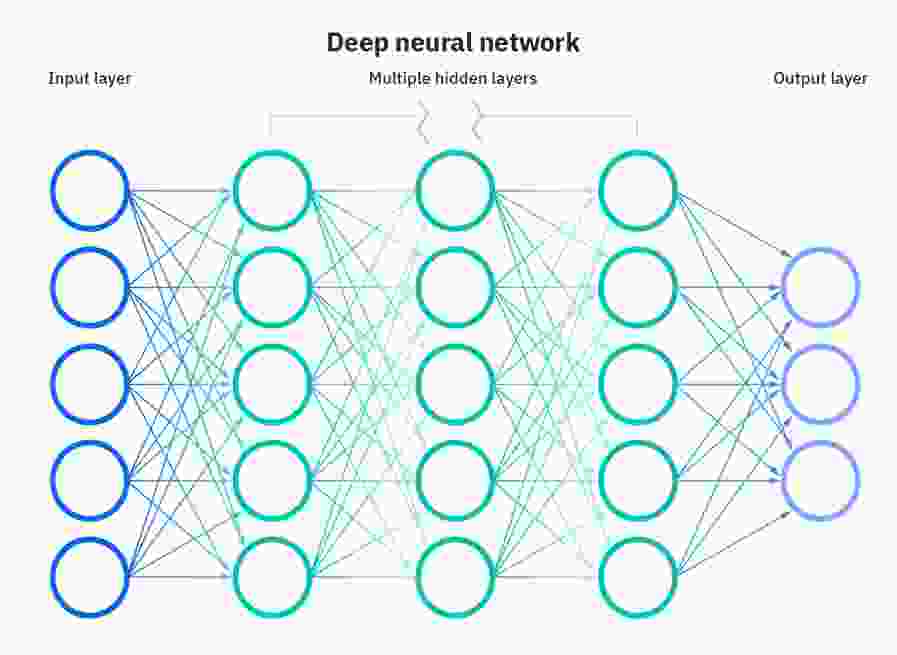
Figure 1 - Schematic diagram of a deep neural network
Neural networks rely heavily on the data with which they are trained and increase their accuracy over time. However, once these learning algorithms are tuned for accuracy, they become powerful tools in computer science and artificial intelligence, enabling them to classify and cluster data at high speed. Speech or image recognition tasks can take minutes compared to hours during manual identification by experts in a field. A couple of the best-known neural networks, Google's search algorithm and You Tube video recommendations, are examples.
To understand how the architecture of a neural network is arranged and how it works, an example is a network that does a pretty good job of classifying handwritten digits. Suppose we have a network (Fig. 2), the leftmost layer in this network is called the input layer, and neurons in this layer are called input neurons. The rightmost or output layer contains output neurons, or, in this case, one output neuron. The middle layer is called the hidden layer, because neurons in this layer are neither inputs nor outputs.
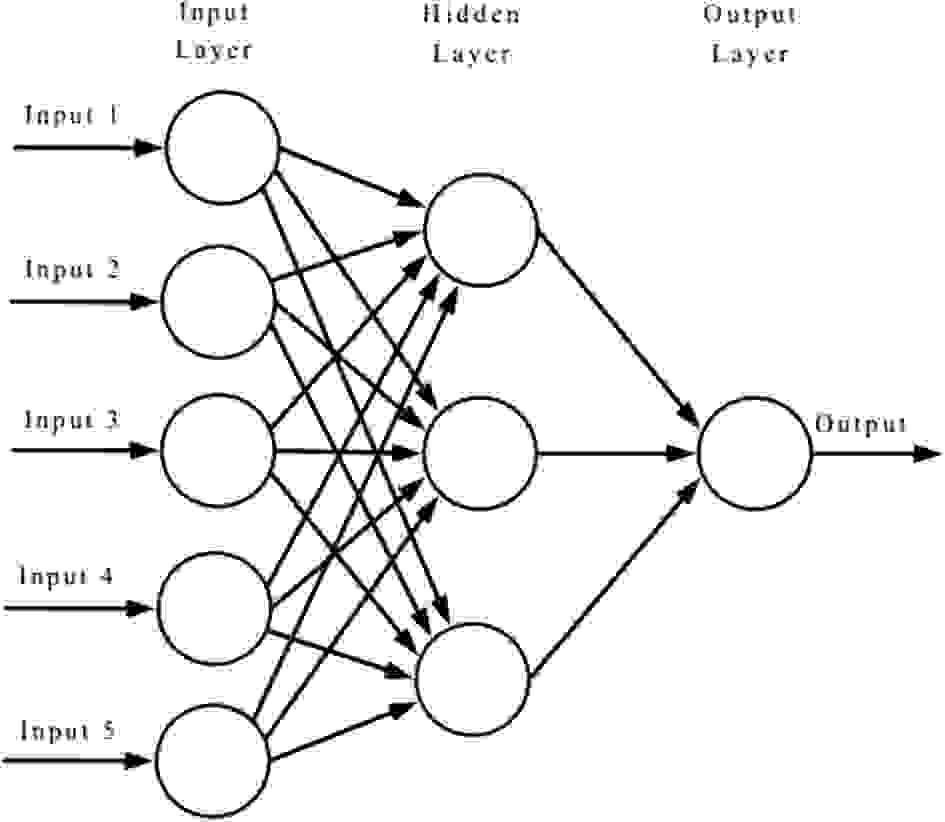
Figure 2 - Neural network
The term "hidden" sounds a bit cryptic - but it really means nothing more than "neither in nor out"[3]. The network above has only one hidden layer, but some networks have multiple hidden layers. For example, the following four-layer network has two hidden layers (Fig. 3).
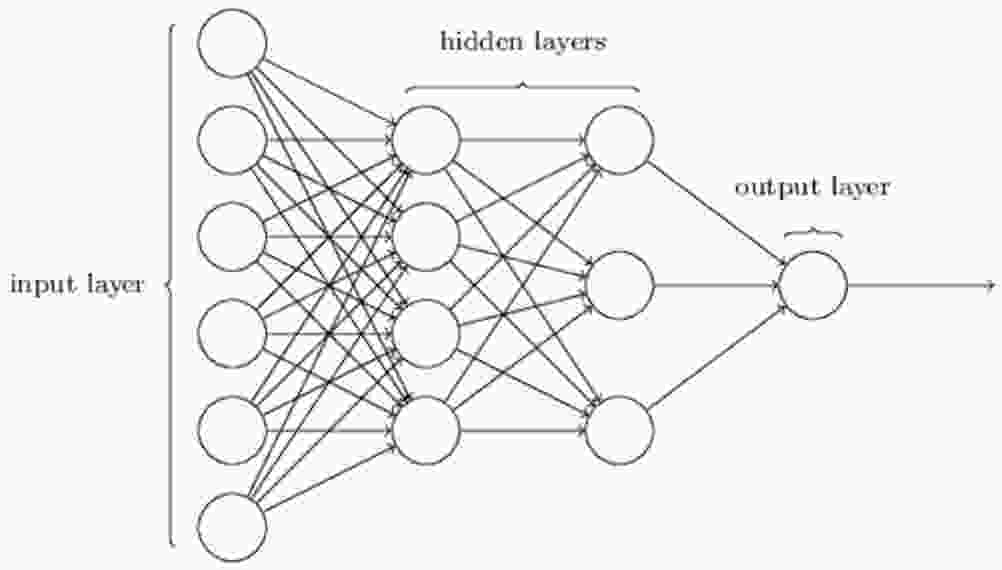
Figure 3 - Four-layer neural network
For historical reasons, multilayer networks are sometimes called multilayer perceptrons or MLPs, even though they consist of sigmoid neurons rather than perceptrons[1].
The design of the input and output layers in a network is often simple. For example, suppose we are trying to
determine whether a handwritten image depicts the number 9
or not. The natural way to design a network is
to encode the pixel intensity of the image into the input neurons. If the image is a grayscale picture of 64 by 64,
you will get 4, 096 = 64 × 64 input neurons, whose intensities will be scaled accordingly between 0 and 1.
The output layer will contain one neuron whose value is less than 0.5, which means that the input image is not 9
,
and values greater than 0.5 mean that "the input image is 9".
If the design of input and output layers of a neural network is simple, the design of hidden layers can be quite masterful. The design of the input and output layers of a neural network is often straightforward, but the design of the hidden layers is quite time consuming and complex. In a particular case, it is impossible to generalize the hidden layer design process to a few simple rules. For this reason, neural network researchers have developed many heuristics for designing hidden layers that help people achieve the desired behavior from their networks. As an example, such heuristics can be used to determine the relationship between the number of hidden layers and the time required to train the network.
Neural networks in which the output of one layer is used as input for the next layer are called direct transfer neural networks. This means that there are no loops in the network - information is always passed forward and never backward.
However, there are other models of artificial neural networks in which feedback loops are possible. These models are called recurrent neural networks. The idea behind these models is to have neurons that operate for some limited period of time, and then freeze. Because of this, this excitation can stimulate other neurons, which in turn can be excited a little later, but also work for a limited time. This causes even more neurons to be actuated, so that over time we get a cascade of working neurons. The loops in this one is not a problem in this model.
Recurrent neural networks are less powerful than direct transfer networks, partly because the learning algorithms for recurrent networks are, by far, less powerful. But recurrent networks are still extremely interesting. They are much closer in spirit to the way our brains work than direct-transmission networks. And it is quite possible that recurrent networks can solve problems that are very difficult to solve with direct-transmission networks.
Basically, three modules are needed for face detection. The first module, is the face detector, which is used to localize faces in images or videos. The second, facial landmark detector, created to align the face to the normalized canonical coordinates. The third face recognition module works already with the second module, namely the aligned face images.
Before the face image is transferred to the recognition module, the face antispoofing is applied, which recognizes whether the face is live or fake, this is done in order to avoid different types of attacks on the system. Then, after verification, the recognition itself can already be performed. The recognition module consists of face processing, deep feature extraction and face matching. It can be represented by a certain formula (Form. 1).
M[F(Pi(Ii)),F(Pj(Ij))]
From where Ii and Ij are the two face images. P - denotes facial processing for intrapersonal variations, before training and testing, such as posture, lighting, facial expression, and occlusions. F - denotes feature extraction, which encodes information about personality. The feature extractor is trained using lossy learning functions and is used to extract different facial features when they are tested. M is the face matching algorithm itself, used to compute feature similarity scores to determine the identity of a face. Unlike the classified objects, the tested faces usually do not match the training data. in the recognition module, which leads to the fact that the learned classifier cannot be used to recognize the tested faces. Therefore, the face matching algorithm is an important part of the overall system.
Although deep learning approaches are widely used, some experts have proven that various factors such as pose, lighting, facial expression and occlusion still affect the performance and accuracy of face recognition using deep neural networks. Accordingly, facial processing is usually introduced to solve this problem. Facial processing methods are divided into "augmentation from one to many" and "normalization from many to one.
- One-to-many augmentation. These methods generate many patches or images of pose variability from a single image to allow deep neural networks to learn representations of pose variability[2].
Many-to-many normalization. These methods reconstruct a canonical face image from one or many non-frontal images; and then the recognition algorithm itself can be performed already under controlled conditions. The various neural network architectures can be divided into backbone and assembled networks. Inspired by the outstanding success of the ImageNet problem, using typical neural network architectures were created, AlexNet, VGGNet, GoogleNet, ResNet and SENet. Which have been introduced and widely used as basic models in face recognition, either directly or with slight modifications, of course. In addition to the basic models, some assembled networks, such as multitasking networks and networks with multiple inputs, can be used in the system. Experts have shown that the accumulation of results collected by networks provides an increase in performance over a single network.
The loss function is typically used as an observation signal in object recognition, and it contributes to feature separability. However, loss functions are not efficient enough for face recognition because intraspecific differences can be larger than interspecific differences, and more discriminative features are required when recognizing different people. Many works are devoted to creating new loss functions to make the features not only more separable, but also more discriminative.
The face recognition algorithm can be divided into face verification and face identification. In either of these scenarios, a set of known subjects, the so-called gallery, is initially entered into the system, and a new subject, the probe, is presented during testing. After training deep neural networks on the massive data with control of the appropriate loss function, each of the test images is run through the networks to obtain a deep representation of the features. Using cosine distance or L2 distance, face verification computes a one-to-one similarity between the gallery and the probe to determine if the two images are the same subject, while face identification computes a one-to-one similarity to determine the specific face identity of the probe. In addition to this, there are other methods for downstream processing of deep features so that face matching is performed efficiently and accurately, such as metric learning, sparse representation-based classifier, etc.
From the above written we can summarize, in face recognition using deep neural networks, different face databases are built for training and testing the network itself, and different architectures and losses always follow the architecture and losses of deep feature classification and change according to the unique characteristics of the recognition algorithm. Moreover, in order to cope with unlimited facial changes, different techniques for processing the face itself, handling poses, expressions, and occlusion variations are being developed all the time. Thanks to these strategies, a deep neural network system for face recognition, greatly improves artificial intelligence capabilities and surpasses human performance in data analysis. Face recognition algorithms are becoming more and more mature and performant over time in general scenarios, thanks to which various solutions for more complex specific scenarios, such as face recognition with crossed poses, with crossed movements, and also face recognition with video, have recently emerged. This facial recognition algorithm is planned to be implemented in the university, to control the presence of students in the classroom.
References
- Аггарвал Ч. Нейронные сети и глубокое обучение: учебный курс / Ч. Аггарвал – 2020 – 29 с.
- Ванг М. Глубокое распознавание лиц: Обзор / М. Ванг, В. Дэнг – 2020 – 3 с.
- Гудфеллоу Я. Глубокое обучение / Я. Гудфеллоу, И. Бенджио, А. Курвилль – 2018. – 160 – 169 с.
- Нильсен М. Нейронные сети и глубокое обучение / М. Нильсен – 2019 – 10 с.
- Хайкин С. Нейронные сети: полный курс, 2-е издание / С. Хайкин – 2020 – 31 с.