Сравнительный анализ инструментов для развёртывания больших языковых моделей
Автор: И.В. Тарабаева, А.Д. Балабан
Источник: Программная инженерия: методы и технологии разработки информационно-вычислительных систем(ПИИВС-2024)
Аннотация
Тарабаева И.В., Балабан А.Д. Сравнительный анализ инструментов для развёртывания больших языковых моделей.В статье представлен сравнительный анализ трёх популярных инструментов для развёртывания больших языковых моделей: LM Studio, Text Generation Inference и vLLM. Рассмотрены основные характеристики, преимущества и недостатки каждого инструмента, включая производительность, поддержку многозадачности и потребление видеопамяти. Исследования показали, что vLLM демонстрирует наилучшую производительность в условиях высоких нагрузок, в то время как Text Generation Inference подходит для средних задач с низкой задержкой. LM Studio является хорошим решением для небольших проектов, требующих экономного использования ресурсов. Выбор инструмента зависит от специфики проекта и доступных вычислительных мощностей.
Введение
В последние годы большие языковые модели(large language model, LLM) стали важнейшим компонентом современных решений в области обработки естественного языка. Эти модели представляют собой мощные инструменты, способные решать широкий спектр задач, от генерации текста и ответов на вопросы до анализа настроений и автоматизированного перевода. Широкое применение LLM обусловлено их способностью обрабатывать тексты с высоким уровнем точности и создавать естественные, человекоподобные ответы, что делает их незаменимыми в таких областях, как поддержка клиентов, маркетинг, автоматизация деловых процессов и даже медицина.
Тем не менее, работа с большими языковыми моделями требует значительных вычислительных ресурсов, что создает серьёзные технические и инфраструктурные вызовы. Развёртывание LLM — процесс сложный, ресурсоёмкий и требует использования специализированных инструментов для оптимизации производительности. Появление специализированных решений для развёртывания LLM значительно упростило работу с такими моделями, предложив пользователям различные подходы к настройке и интеграции.
Цель данной работы – провести сравнительный анализ трёх популярных инструментов для развёртывания больших языковых моделей: LM Studio, Text Generation Inference и vLLM. Каждый из этих инструментов представляет собой уникальное решение, предоставляющее разработчикам и исследователям специфический набор возможностей и преимуществ.
Актуальность темы обусловлена тем, что для компаний и исследовательских команд выбор подходящего инструмента для развёртывания LLM является важным фактором, влияющим на конечную производительность и экономическую эффективность проекта. В условиях, когда модели становятся всё более сложными, а их задачи — всё более ресурсоёмкими, правильный выбор инструмента позволяет значительно снизить затраты и повысить скорость разработки.
Описание инструментов для развёртывания LLM
Рассмотрим основные характеристики популярных инструментов для развёртывания больших языковых моделей: LM Studio, Text Generation Inference и vLLM. Эти решения предлагают различные подходы к интеграции и управлению LLM, ориентированные на различные сценарии использования и потребности разработчиков.
LM Studio
LM Studio[1] представляет собой универсальную платформу для развёртывания, тестирования и управления большими языковыми моделями, разработанную с упором на простоту использования. Благодаря интуитивному интерфейсу пользователи могут развертывать модели и настраивать параметры без глубоких технических знаний.
Платформа поддерживает популярные открытые модели, что позволяет работать с различными архитектурами в зависимости от задачи. LM Studio также предлагает удобный графический интерфейс, позволяющий выбирать параметры моделей, настраивать вывод и конфигурацию, что делает платформу отличным выбором для быстрого тестирования LLM в приложениях.
Для интеграции с другими системами в LM Studio реализована поддержка REST API и OpenAI-совместимый API, что позволяет разработчикам легко подключать языковые модели к существующей инфраструктуре. Несмотря на оптимизацию для локального развертывания, платформа также поддерживает работу на GPU для повышения производительности, что особенно полезно при работе с большими моделями и значительными объёмами данных.
Text Generation Inference
Text Generation Inference[2, 3] – это мощное решение, разработанное компанией Hugging Face для развёртывания и использования языковых моделей. Этот инструмент взаимодействует с Hugging Face Hub, благодаря чему разработчики могут легко разворачивать модели из коллекции Hugging Face и работать с ними через оптимизированные API.
Одним из главных преимуществ Text Generation Inference является бесшовная интеграция с Hugging Face Hub, где доступно множество предобученных моделей, что значительно упрощает доступ к проверенным решениям и экономит время на начальных этапах разработки.
Кроме того, Text Generation Inference разработан с учётом высокой нагрузки и способен эффективно масштабироваться, оптимизируя использование ресурсов на серверах с GPU. Это даёт возможность командам эффективно распределять вычислительные мощности, улучшая общую производительность. Система также предоставляет гибкость в настройке параметров, позволяя адаптировать модель под конкретные задачи и обеспечивая возможность точной подстройки.
vLLM
vLLM[4, 5] – это специализированный фреймворк для развертывания и оптимизации вывода больших языковых моделей, разработанный для повышения производительности и эффективного использования вычислительных ресурсов. Архитектура vLLM позволяет максимально задействовать мощности CPU и GPU, что особенно важно для высоконагруженных приложений и систем с ограниченными ресурсами.
Фреймворк обеспечивает высокую производительность и минимизацию задержек за счёт оптимизированных алгоритмов, которые ускоряют время отклика и увеличивают скорость генерации текста. Это делает vLLM подходящим выбором для задач с высокой вычислительной нагрузкой. Также поддерживается распределение вычислений, что позволяет масштабировать задачи горизонтально и распределять нагрузку на несколько GPU, обеспечивая возможность обработки большего числа запросов одновременно. Это преимущество особенно ценно для крупных проектов, которым требуется стабильная производительность под высокой нагрузкой.
Методология и результаты сравнительного анализа
Проведен сравнительный анализ инструментов для развертывания больших языковых моделей. Тестирование проводилось на видеокарте NVIDIA RTX 3050 с 8 ГБ видеопамяти, при этом для всех инструментов использовалась модель Llama-3.2-1B-Instruct, подвергнутая квантованию до FP16.
В целях оценки производительности каждого инструмента были проведены тесты с использованием двух типов запросов (коротких и длинных) и разного количества запросов (от одного до ста), что позволило выявить, как каждый инструмент справляется с различной нагрузкой. Результаты тестов синхронной и асинхронной отправки запросов приведены в таблицах 1 и 2 и дополнительно проиллюстрированы на рисунках 1 и 2 соответственно.
Таблица 1 показывает время отклика при синхронной отправке запросов для каждого инструмента, отражая значительное увеличение времени отклика у LM Studio при больших объёмах запросов. На рисунке 1 эти данные представлены графически, что наглядно иллюстрирует сравнительную производительность.
| Короткие запросы | Длинные запросы | |||||
|---|---|---|---|---|---|---|
| 1 | 10 | 100 | 1 | 10 | 100 | |
| LM Studio | 2.42 с. | 8.11 с. | 75.65 с. | 12.41 с. | 112.35 с. | 1099.61 с. |
| vLLM | 1.93 с. | 6.13 с. | 56.86 с. | 8.49 с. | 83.04 с. | 756.20 с. |
| Text Generation Inference | 0.77 с. | 5.46 с. | 56.53 с. | 9.28 с. | 90.95 с. | 908.78 с. |
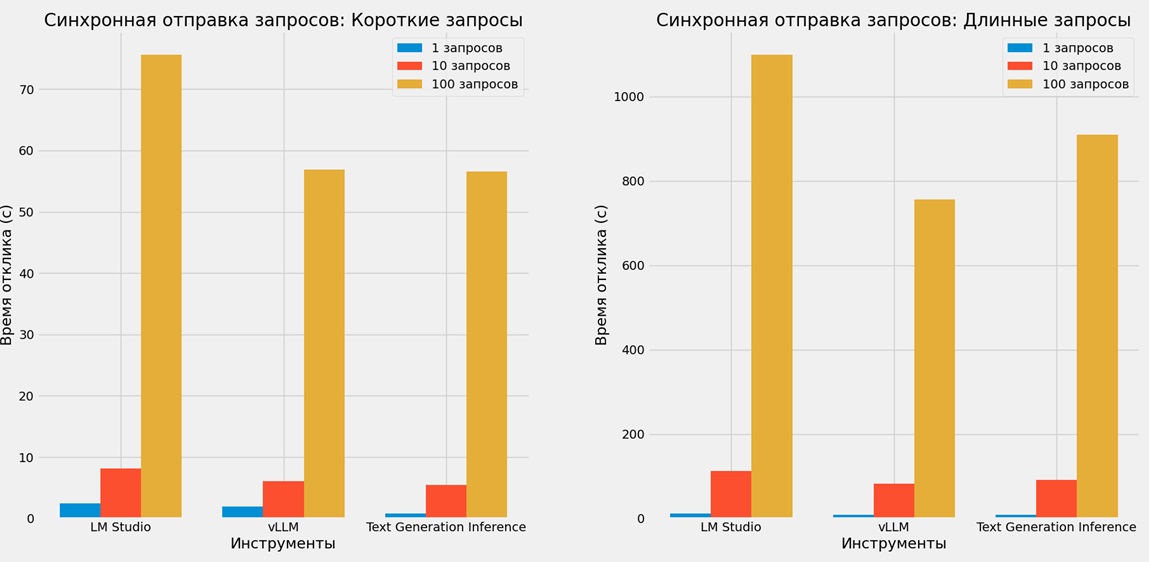
Рисунок 1 – Синхронная отправка запросов
Таблица 2 содержит данные времени отклика для асинхронной отправки запросов, демонстрируя, как каждый инструмент справляется с многозадачностью. График на рисунке 2 иллюстрирует эти результаты, показывая, что vLLM снова демонстрирует наилучшую производительность при высокой нагрузке.
| Модель | Короткие запросы | Длинные запросы | ||||
|---|---|---|---|---|---|---|
| 1 | 10 | 100 | 1 | 10 | 100 | |
| LM Studio | 1.23 с. | 6.88 с. | 75.82 с. | 11.31 с. | 111.03 с. | 1095.32 с. |
| vLLM | 0.84 с. | 1.01 с. | 4.64 с. | 8.81 с. | 11.14 с. | 42.91 с. |
| Text Generation Inference | 1.04 с. | 2.23 с. | 5.36 с. | 9.48 с. | 15.97 с. | 40.01 с. |
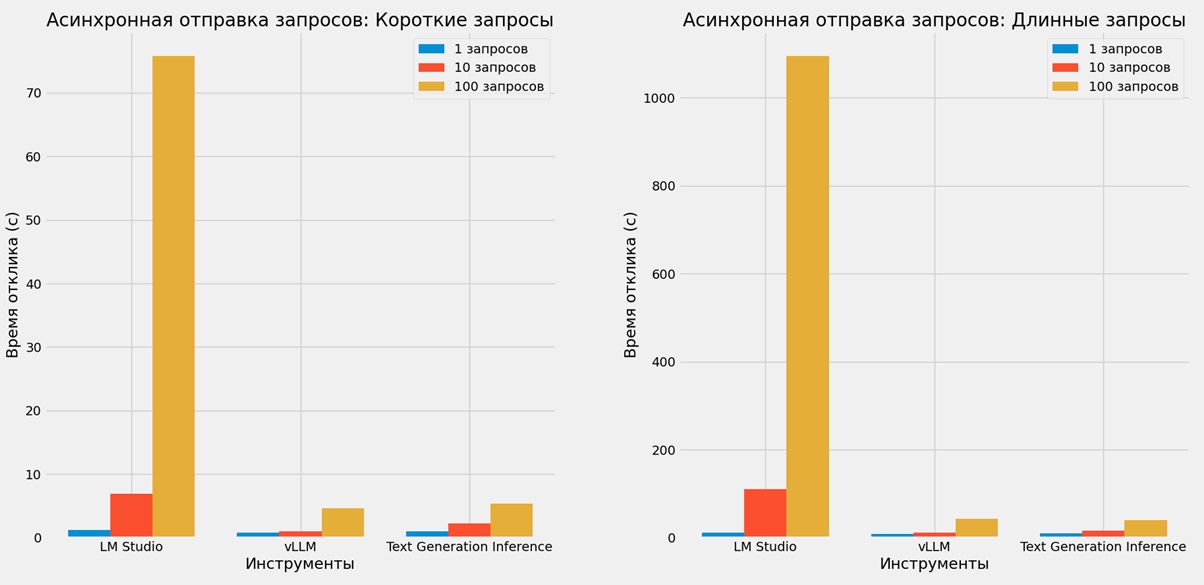
Рисунок 2 – Асинхронная отправка запросов
Также был проведен анализ потребления видеопамяти каждым из инструментов, результаты которого представлены в таблице 3 и визуализированы на рисунке 3. Этот анализ позволил оценить требования каждого инструмента к оборудованию и выявить их оптимальность для разных сценариев использования.
| Инструмент | Видеопамять, ГБ |
|---|---|
| LM Studio | 2.9 |
| vLLM | 6.3 |
| Text Generation Inference | 5.5 |
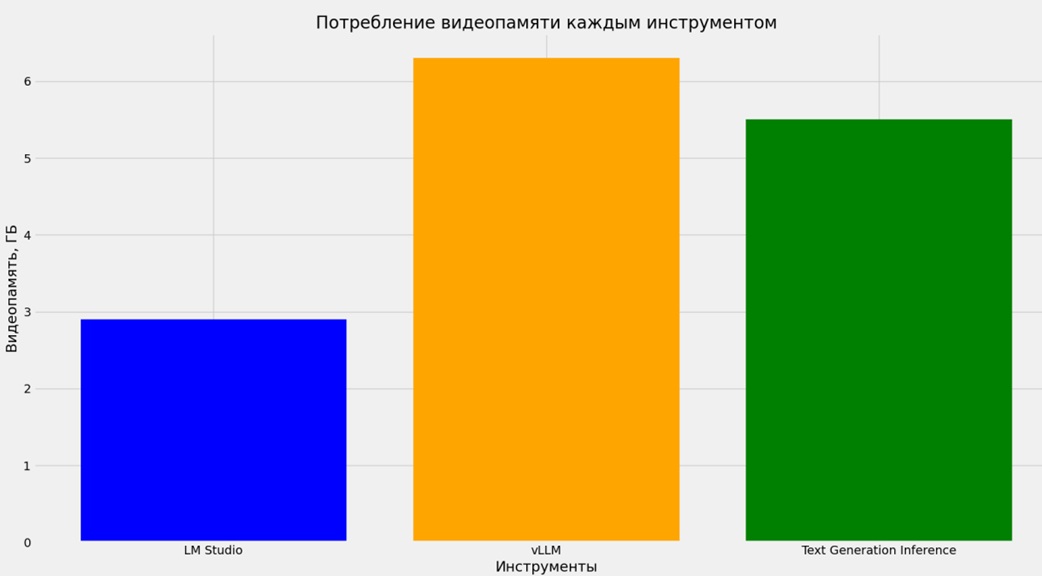
Рисунок 3 – Потребление видеопамяти
Проведённый анализ показал, что vLLM является оптимальным инструментом для высоконагруженных приложений, требующих высокой производительности и устойчивости при параллельной обработке запросов. Text Generation Inference также демонстрирует высокие результаты, особенно в задачах средней сложности и на умеренных объёмах нагрузки. LM Studio лучше всего подходит для небольших проектов и сценариев, не требующих интенсивной параллельной обработки запросов и высоких вычислительных ресурсов.
Заключение
В данной работе был проведён сравнительный анализ трёх современных инструментов для развёртывания больших языковых моделей: LM Studio, Text Generation Inference и vLLM. Эти инструменты позволяют использовать большие языковые модели в самых разных сценариях – от экспериментальных проектов и небольших приложений до высоконагруженных систем с распределённой архитектурой.
Анализ показал, что vLLM наилучшим образом справляется с интенсивной параллельной загрузкой, обеспечивая стабильную и высокую производительность для сложных запросов. Этот инструмент подходит для задач с высокой многозадачностью и значительной нагрузкой, где требуется высокая устойчивость и оптимизация под массовую обработку запросов. Text Generation Inference показал себя эффективным для приложений, требующих низкой задержки на короткие запросы при умеренной нагрузке, что делает его оптимальным для работы с небольшими и средними объёмами запросов. LM Studio продемонстрировал экономное потребление видеопамяти и подходит для решений с ограниченными ресурсами или небольшими объёмами данных, хотя уступает по производительности в условиях высокой нагрузки.
Выбор оптимального инструмента зависит от конкретных требований проекта: от желаемого уровня многозадачности до доступных вычислительных ресурсов. Проведённый анализ и рекомендации могут помочь разработчикам и инженерам принять взвешенное решение, адаптированное под нужды приложения, и более эффективно развернуть большие языковые модели в условиях различных сценариев эксплуатации.
Литература
- Discover LM Studio: An Easy Introduction to Running AI Models Locally [Электронный ресурс]. – Режим доступа: https://medium.com/@omkamal/discover-lm-studio-an-easy-introduction-to-running-ai-models-locally-674c58339f4b
- Understanding Text Generation Interface (TGI) [Электронный ресурс]. – Режим доступа: https://medium.com/@premsaig1605/deciphering-the-giants-a-comprehensive-comparison-of-text-generation-interface-tgi-and-vllm-26da3976d0e9
- Hugging Face AI Models in Natural Language Processing [Электронный ресурс]. – Режим доступа: https://medium.com/brainscriblr/hugging-face-ai-models-in-natural-language-processing-8f474fe531b3
- How to Use vllm: A Comprehensive Guide in 2024 [Электронный ресурс]. – Режим доступа: https://hyscaler.com/insights/vllm-virtual-large-language-model/
- VLLM List Models Explained: A Comprehensive Guide [Электронный ресурс]. – Режим доступа: https://blogs.novita.ai/unveiling-vllm-list-models-a-comprehensive-guide/
- Understanding Text Generation Interface (TGI) [Электронный ресурс]. – Режим доступа: https://medium.com/@premsaig1605/deciphering-the-giants-a-comprehensive-comparison-of-text-generation-interface-tgi-and-vllm-26da3976d0e9