Модель машинного обучения для анализа тональности отзывов к кинофильмам
Автор: А.Д. Балабан, О.И.Федяев
Источник: Программная инженерия: методы и технологии разработки информационно-вычислительных систем(ПИИВС-2022)
Аннотация
Балабан А.Д., Федяев О.И. Модель машинного обучения для анализа тональности отзывов к кинофильмам. Статья посвящена автоматизации определения тональности отзывов к кинофильмам. Для решения поставленной задачи предложен метод, основанный на использовании нейронной сети LSTM. В рамках статьи показаны все этапы конвейера NLP: подготовка, обработка данных, построение, обучение и применение модели.
Введение
Анализ тональности – это область компьютерной лингвистики, которая занимается изучением мнений и эмоций в текстовых документах. Цель анализа тональности состоит в том, чтобы автоматически распознавать и классифицировать мнения, выраженные в тексте, для определения общего настроения.
Анализ тональности является одним из методов обработки естественного языка. Обработка естественного языка(NLP) — это область исследований в компьютерных науках и искусственном интеллекте (ИИ), занимающаяся работой естественными языками. Обработка обычно включает в себя перевод естественного языка в данные (числа), с помощью которых компьютер может получить информацию об окружающем мире.
В статье демонстрируется анализ тональности рецензий к фильмам на сайте Кинопоиск с целью построения модели машинного обучения, которая затем сможет классифицировать отзывы как положительные или отрицательные. В рамках статьи показаны все этапы конвейера NLP(см.рис.1).

Рисунок 1 – Этапы конвейера NLP
Статья разбита на следующие разделы:
- Подготовка данных: парсинг сайта Кинопоиск для получения положительных и отрицательных отзывов к фильмам, составление корпуса с отзывами на русском языке.
- Обработка данных: токенизация, векторизация данных, разбиение данных на множества для обучения и проверки.
- Построение модели машинного обучения. В этом случае используется нейронная сеть LSTM, с целью классификации отзывов к фильмам.
- Проверка модели машинного обучения: использование различных метрик для того, чтобы убедиться, что модель хорошо обучена и может быть легко обобщена на другие наборы данных.
Подготовка данных
Для решения задачи определения тональности отзывов к кинофильмам был создан корпус с отзывами на русском языке, взятых с сайта Кинопоиск. Для того, чтобы автоматизировать этот процесс, на языке программирования Python с использованием библиотек BeautifulSoup и requests был написан веб парсер.
Функция get_response_texts очищает переданный ей список отзывов от html разметки (см.рис.2).

Рисунок 2 – Функция get_response_texts
Основная логика содержится в функции parse_kinopoisk (см.рис.3). Для каждого фильма из указанного списка составляется два списка – с хорошими и плохими отзывами. Затем эти списки сохраняются в файлах формата .json. Название файла – id фильма на сайте Кинопоиск.

Рисунок 3 – Функция parse_kinopoisk
Обработка данных
Для загрузки данных была написана функция load_dataset(см.рис.4), которая возвращает список текстов всех отзывов. Каждый отзыв получает метку 0 (отрицательная тональность) или 1 (положительная тональность).

Рисунок 4 – Функция load_dataset
Следующий этап – токенизация и векторизация данных.
Токенизация – это процесс разделения предложений на слова-компоненты(токены). Векторизация(эмбеддинг) – процесс преобразования языковой сущности(слова, предложения, параграфа или целого текста) в набор чисел – числовой вектор.
Для токенизации текста был использован токенизатор RegexpTokenizer из библиотеки nltk, для векторизации – модель fastText[1]. Функция токенизации и векторизации представлена на рисунке 5.

Рисунок 5 – Функция токенизации и векторизации
При помощи функции unique из библиотеки NumPy можно посмотреть количество отзывов каждого класса (см.рис.6).

Рисунок 6 – Количество положительных и отрицательных отзывов
Доли объектов разных классов существенно различаются – классы являются несбалансированными.
Далее подготовленные данные необходимо разбить на тренировочный и тестовый наборы в соотношении 80/20. Для этого можно воспользоваться функцией train_test_split из библиотеки sklearn. Так как присутствует несбалансированность классов, необходимо воспользоваться параметром stratify (см.рис.7).

Рисунок 7 – Разбиение данных на тренировочный и тестовый наборы
Затем задается большинство гиперпараметров сети. Переменная max_len содержит максимально возможную длину отзыва. Поскольку все входные сигналы нейронной сети должны быть одинаковой длины, необходимо усечь все примеры длиннее 550(немного больше, чем средняя длина отзыва) токенов и дополнить нулями более короткие до 550 токенов (см.рис.8).
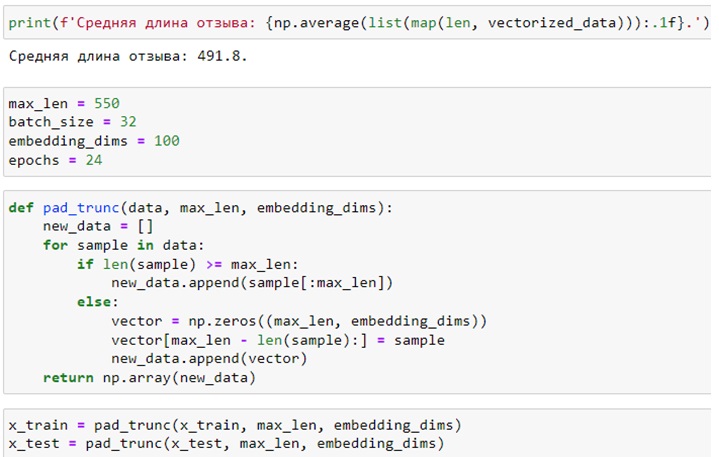
Рисунок 8 – Объявление гиперпараметров, усечение данных
На этом обработка данных завершена.
Построение модели
Создание многослойной нейронной сети в пакете Keras происходит при помощи класса Sequential.
В начале необходимо добавить несколько слоёв LSTM. Долгая краткосрочная память (Long short-term memory; LSTM) – особая разновидность архитектуры рекуррентных нейронных сетей, способная к обучению долговременным зависимостям[2, 3].
LSTM вводит понятие состояния для каждого из слоев рекуррентной сети. Состояние играет роль памяти. В LSTM правила, определяющие хранение информации в состоянии (памяти) (см.рис.9), – это сама обученная нейронная сеть. Ее можно обучить тому, что надо запоминать, в то время как остальная рекуррентная нейронная сеть учится предсказывать целевую метку. С появлением памяти и состояния можно выучивать зависимости, простирающиеся на весь пример данных, а не только на 1–2 токена. Благодаря таким «долгим» зависимостям можно выйти за рамки отдельных слов и больше узнать о языке.
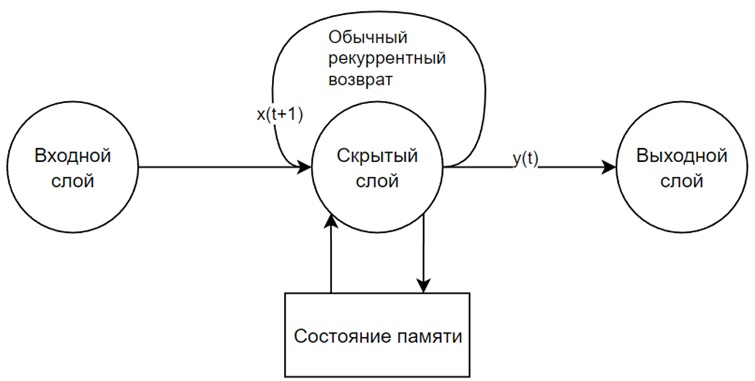
Рисунок 9 – Общая структура рекуррентной нейронной сети LSTM
В задачах, где доступны все временные шаги входной последовательности, можно использовать двунаправленные LSTM. Основная идея состоит в размещении двух LSTM рядом друг с другом и передаче одного и того же входного сигнала в одну обычным образом, а во вторую – в обратном порядке. Это может обеспечить дополнительный контекст для сети и привести к более быстрому и даже более полному изучению проблемы. В Keras есть слой-адаптер Bidirectional для автоматического поворота нужных входных и выходных сигналов в другую сторону и автоматического создания двунаправленной LSTM.
Для предотвращения переобучения необходимо добавить слои дропаута. Дропаут – это специальная методика предотвращения переобучения в нейронных сетях. Идея дропаута заключается в «выключении» определенной части передаваемого на следующий слой входного сигнала, выбираемой при каждом проходе случайным образом. В результате модель скорее усвоит не особенности именно тренировочного набора данных (и переобучится), а детальные представления закономерностей данных и, следовательно, окажется способна на обобщения и точные предсказания на основе совершенно новых для нее данных[4].
В конце необходимо добавить классификатор. В данном случае есть два класса: «Да – положительная тональность – 1» и «Нет – отрицательная тональность – 0». Поэтому необходимо добавить слой из одного нейрона (Dense(1)) и сигма-функцию активации. Cлой Dense требует в качестве входного сигнала вектор из n элементов. Однако на выходе LSTM данные представляют собой тензор второго ранга. Для преобразования тензора второго ранга в вектор необходимо воспользоваться вспомогательным слоем Flatten().
Модель полностью описана. Осталось её скомпилировать (см.рис.10).

Рисунок 10 – Компиляция модели
Параметр loss определяет, какую функцию сеть будет пытаться минимизировать. В данном случае используется функция потерь 'binary_crossentropy', так как есть только два класса.
Параметр optimizer может принимать значение, соответствующее любой из перечня стратегий оптимизации сети во время обучения, например RSMProp.
Параметр metrics позволяет отслеживать выбранные метрики во время обучения. Так как классы несбалансированны, была добавлена метрика ROC AUC.
Общую информацию о модели можно посмотреть при помощи метода summary()(см.рис.11).
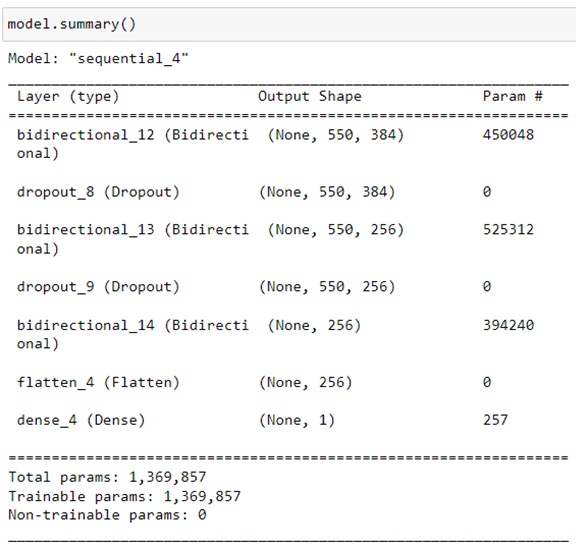
Рисунок 11 – Общая информация о модели
Обучение модели осуществляется при помощи метода fit(). В зависимости от аппаратного обеспечения и размеров модели и данных этот процесс может занимать от пары секунд до нескольких месяцев. В большинстве случаев использование GPU может сильно сократить время обучения. Изменение метрики ROC-AUC во время обучения представлено на рисунке 12.
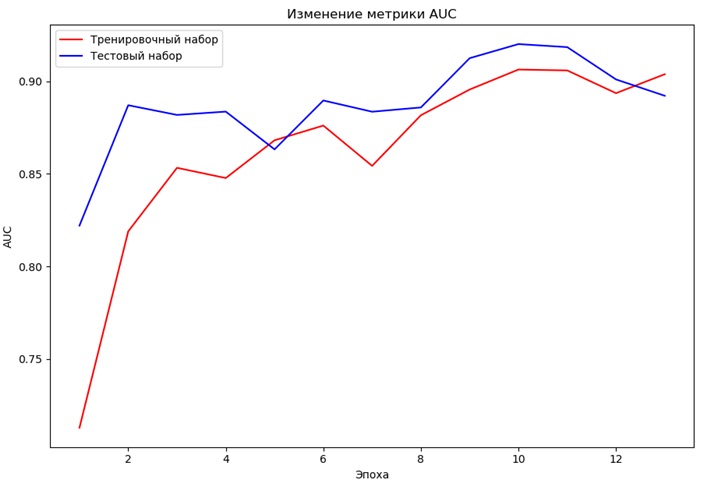
Рисунок 12 – Изменение метрики ROC AUC во время обучения
Последний шаг – сохранение модели. Чтобы каждый раз не обучать модель заново, её веса можно сохранить в файл с расширением .h5. Структуру модели можно сохранить в формате .json.
Проверка модели
При обучении модели после каждой эпохи выводятся значения метрик относительно тестовых данных. Наилучшие показатели – точность 87% и ROC-AUC 0.91.
После обучения модели можно передать ей новые отзывы для определения их тональности. Примеры прогнозов для отзывов с явно отрицательной и положительной тональностью приведены на рисунке 13. Прогноз модели: первый отзыв – отрицательный, второй – положительный.
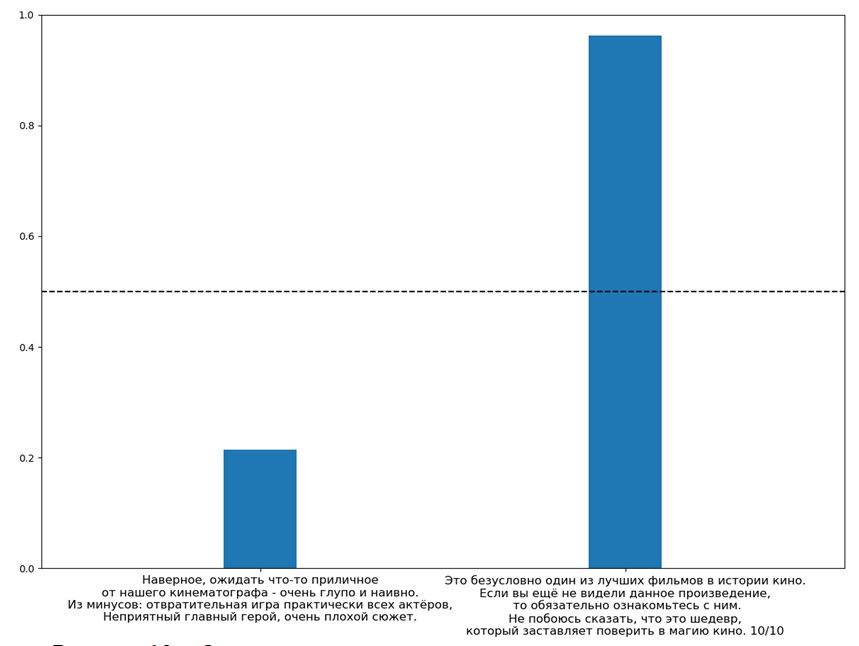
Рисунок 13 – Определение тональности отзывов при помощи модели
Заключение
В статье рассмотрена задача автоматической классификации текстов по тональности, которая относится к актуальным задачам анализа текстовых данных. Для решения поставленной задачи предложен метод, основанный на использовании нейронной сети LSTM. Следует отметить, что задача определения тональности является весьма сложной, кроме того, ее решение зависит от естественного языка, на котором написаны сообщения.
Литература
- fastText [Электронный ресурс]. – Режим доступа: https://fasttext.cc/
- Long Short-Term Memory [Электронный ресурс]. – Режим доступа: https://www.gwern.net/docs/ai/nn/rnn/1997-hochreiter.pdf
- Learning Precise Timing with LSTM Recurrent Networks [Электронный ресурс]. – Режим доступа: http://www.jmlr.org/papers/volume3/gers02a/gers02a.pdf
- Обработка естественного языка в действии / Хобсон Лейн, Ханнес Хапке, Коул Ховард - 1-е изд. – СПб.: Питер, 2020. – 576с.
- Long Short-Term Memory [Электронный ресурс]. – Режим доступа: https://www.gwern.net/docs/ai/nn/rnn/1997-hochreiter.pdf