Аннотация
Коломойцева И. А., Гембицкий А. В. Исследование современных методов и технологий для парсинга веб-сайтов. В статье рассматриваются основные методы и инструменты для парсинга сайтов, включая использование CSS-селекторов, регулярных выражений, headless-браузеров, прокси-серверов и API-доступа к данным. Подробно анализируются возможности различных подходов и особенности их применения для структурированных и динамических веб-ресурсов. На основе анализа наиболее перспективным инструментом для парсинга выбрана библиотека Scrapy, которая сочетает высокую производительность с гибкостью и возможностью масштабирования.
Ключевые слова: веб, парсинг, метод, технология, данные, обработка.
Введение
Парсинг веб-данных включает методологии и инструменты для извлечения структурированной информации из неструктурированного или полуструктурированного потока данных, что играет важную роль в создании приложений, основанных на данных, особенно в области машинного обучения. С ростом объема информации в интернете способность преобразовывать большие массивы данных в значимую информацию приобретает всё большее значение, делая парсинг веб-данных актуальной областью в науке о данных и аналитике [1]. Этот процесс обычно включает извлечение данных, анализ их структуры и хранение в формате, пригодном для анализа, с использованием различных методов для эффективного извлечения информации. Среди основных методов, применяемых в парсинге, – парсинг HTML, парсинг DOM, использование headless браузеров и прямой доступ к API.
Несмотря на свои преимущества, парсинг веб-данных сталкивается с рядом проблем, таких как сложные HTML-структуры, динамические данные и неожиданные ответы серверов. Правовые и этические аспекты также усложняют ситуацию, поскольку несанкционированный парсинг может нарушать условия использования и привести к юридическим последствиям. Таким образом, для успешного парсинга данных необходимы не только технические навыки, но и понимание правовых и этических норм. С развитием технологий будущее парсинга веб-данных всё больше связано с машинным обучением и ИИ, что позволяет создавать более сложные инструменты для работы с динамическим контентом. Повышенное внимание к этическим нормам работы с данными и рост решений без программирования делают технологии парсинга более доступными для нетехнических пользователей.
Парсинг веб-данных необходим для преобразования сырой информации из интернета в формат, удобный для анализа и использования в различных приложениях, включая машинное обучение. Обычно он включает несколько ключевых этапов: извлечение данных, анализ их структуры и сохранение в пригодном для использования формате.
Парсинг HTML
Парсинг HTML – это процесс интерпретации HTML-кода веб-страницы для извлечения конкретных элементов данных. Инструменты, такие как BeautifulSoup и LXML на Python, упрощают этот процесс, позволяя пользователям ориентироваться в элементах документа и извлекать данные по тегам, атрибутам или CSS-селекторам. Вначале происходит загрузка HTML-кода страницы. После загрузки HTML-код анализируется для поиска нужной информации. Для этого применяются библиотеки, такие как BeautifulSoup, lxml или Selenium. Эти инструменты позволяют выделить конкретные теги, классы и атрибуты HTML для извлечения необходимых данных. Далее из HTML-кода извлекаются данные, представленные в текстовом или числовом виде, изображения, ссылки и другие элементы. Выборка осуществляется путем обращения к конкретным HTML-тегам и их свойствам, например, div, span, a, img, table и т.д. В конце извлечённые данные обычно преобразуются в структурированный формат, такой как JSON или CSV, что позволяет использовать их в аналитике, для построения моделей машинного обучения или для других целей. При работе с HTML-парсингом следует учитывать правовые и этические аспекты, такие как соблюдение условий использования веб-сайта и закона о защите персональных данных (GDPR). HTML-парсинг предоставляет множество возможностей для извлечения данных, структурирования информации и её дальнейшего анализа. Это важный инструмент для аналитиков, исследователей и специалистов в области машинного обучения, который позволяет эффективно обрабатывать неструктурированные данные из интернета.
Парсинг на основе CSS-селекторов
Это метод извлечения данных из HTML-документов с использованием CSS-селекторов, которые позволяют идентифицировать и выбирать элементы на веб-странице. CSS-селекторы широко используются в веб-разработке для стилизации элементов, и благодаря их удобству и гибкости они стали популярным инструментом в парсинге данных. CSS-селекторы — это синтаксис, позволяющий выбирать определённые элементы HTML-страницы. Селекторы могут быть основаны на имени тега, классе, идентификаторе, атрибутах, вложенности элементов и других характеристиках. Вначале загружается HTML-код страницы, который затем можно преобразовать в дерево DOM (см. рис. 1). С помощью различных библиотек, таких как BeautifulSoup (Python), jQuery (JavaScript), Cheerio (Node.js) и других, можно применять CSS-селекторы к DOM-дереву для доступа к элементам. После выбора элементов с помощью CSS-селекторов можно получить их текстовое содержимое, значения атрибутов, ссылки и другие данные, которые содержатся в HTML-коде. CSS-селекторы популярны среди новичков ввиду интуитивной понятности их работы и поддержки большинства парсинговых библиотек. Однако CSS-селекторы не работают с динамически загружаемыми данными (например, с AJAX). Для таких задач лучше подходят инструменты, работающие с DOM в браузере, такие как Selenium. Так же, если структура страницы изменится, CSS-селекторы могут перестать работать, что означет необходимость регулярного обновления селекторов для поддержания актуальности парсера.
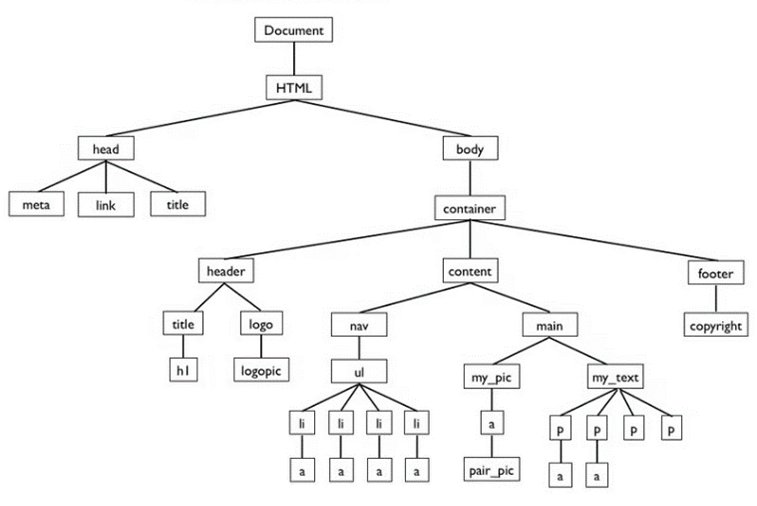
Рисунок 1 – Пример DOM дерева
Парсинг с помощью регулярных выражений
Это метод извлечения данных из текста HTML, XML или любого другого текста на основе шаблонов. Регулярные выражения (regex) представляют собой специальные шаблоны, которые позволяют находить строки, соответствующие заданным условиям. Этот метод подходит для задач, где структура данных предсказуема, но часто используется в ограниченных случаях. Работа с регулярными выражениями весьма проста. Вначале строиться регулярное выражение в соответствии с структурой необходимых данных, после чего при помощи функций языка или библиотек выполняется поиск всех соответствий шаблона в тексте. После извлечённые данные можно использовать для анализа, сохранения или дальнейшего преобразования. Отличительными особенностями регулярных выражений выделяют скорость работы, так как они требуют меньше ресурсов, чем другие методы парсинга в связи с отсутствием необходимости создания дерева DOM и гибкость настройки шаблонов для поиска практически любых текстовых паттернов. Однако регулярные выражения плохо справляются с динамическими и изменяющимися HTML-структурами, так как HTML имеет сложную, вложенную структуру, в которой теги могут содержать вложенные элементы, атрибуты и разные формы записи. Если структура HTML-кода изменится (например, изменится название классов или атрибутов), регулярные выражения также необходимо будет изменить.
Headless браузеры
Headless браузер — это браузер, работающий без графического интерфейса. Он полностью выполняет функции обычного браузера, например, загружает HTML и CSS, выполняет JavaScript, взаимодействует с DOM и поддерживает различные сетевые протоколы. Парсинг с использованием headless браузеров представляет собой метод извлечения данных с сайтов, где браузер запускается в фоновом режиме без графического интерфейса. Создаётся экземпляр браузера в headless-режиме после чего браузер переходит по заданному URL, загружая все необходимые ресурсы, включая динамически генерируемый JavaScript-контент. Таким образом появляется возможность выполнять собственные JavaScript-код для взаимодействия с сайтом, что может быть полезно для кликов по кнопкам, заполнения форм или скроллинга, чтобы подгрузить данные. После полной загрузки страницы и выполнения всех скриптов данные можно извлечь с помощью инструментов для работы с DOM, таких как CSS-селекторы или XPath. Отличительной чертой Headless браузеров считают возможность загружать всю страницу, включая JavaScript, CSS и мультимедийные файлы, что делает их идеальными для сайтов с динамической подгрузкой данных (AJAX или Infinite Scroll). Так же они способны эмулировать поведение пользователя и выполнять сложные сценарии, например, запрашивать данные после авторизации или выполнения многошаговых операций. Однако запуск headless браузера требует больше оперативной памяти и процессорного времени по сравнению с текстовыми парсерами, особенно при массовом парсинге. Кроме того некоторые сайты могут определять headless браузеры и блокировать их, поэтому для обхода таких защитных механизмов может потребоваться дополнительная настройка (подмена User-Agent или IP).
Доступ к API
Парсинг сайтов с помощью доступа к API — это метод получения данных, при котором вместо извлечения HTML-страниц используется программный интерфейс (API), предоставляемый самим сайтом или сервисом. Многие крупные платформы, такие как социальные сети, интернет-магазины и информационные ресурсы, предлагают API для легального и упрощённого доступа к своим данным. Данный подход обеспечивает более структурированный и эффективный способ получения информации, чем традиционный парсинг HTML-страниц. Многие API требуют регистрации и получения уникального API-ключа, который нужен для авторизации запросов. Этот ключ помогает сервисам отслеживать использование API и применять ограничения. При получении API-ключа можно отправлять запросы к API, используя методы HTTP, такие как GET (для получения данных) или POST (для отправки данных). API возвращает данные в структурированном формате, обычно в JSON или XML, что делает обработку данных более простой и надёжной. Работа с API требует меньше ресурсов и времени, чем парсинг HTML, так как API обычно предоставляет только необходимые данные без лишнего содержимого, такого как стили и скрипты. Так же доступ к API, как правило, гарантирует получение актуальных и качественных данных, которые обновляются в реальном времени. Однако большинство API имеют ограничения на количество запросов в единицу времени. Кроме того, API могут предоставлять доступ далеко не ко всей информации, либо требовать плату.
Парсинг через прокси и ротацию IP
Многие сайты ограничивают количество запросов, которые можно отправить с одного IP-адреса за определённый промежуток времени. Это может быть вызвано защитой от автоматического парсинга или от DDoS-атак. Данный метод, позволяет обходить ограничения, установленные сайтами для защиты от автоматических запросов. Прокси-серверы и ротация IP-адресов помогают распределять трафик и скрывать настоящие IP-адреса, что делает процесс парсинга более анонимным и снижает вероятность блокировок. Прокси-серверы выступают в роли посредника между парсером и сайтом. Когда парсер отправляет запрос через прокси, сайт видит IP-адрес прокси, а не реальный IP-адрес парсера. Различают: HTTP и HTTPS прокси, которые поддерживают запросы через HTTP и HTTPS соответственно и подходят для большинства веб-сайтов, SOCKS прокси, способные работать с различными протоколами, помимо HTTP и резидентные прокси (IP-адреса), привязанные к реальным устройствам, таким как компьютеры и мобильные телефоны, что делает их менее подозрительными для сайтов. Ротация IP — это смена прокси на регулярной основе, чтобы каждый запрос отправлялся с нового IP-адреса. Это может происходить по времени (каждые несколько секунд) или по количеству запросов (после 5–10 запросов). Ротация IP помогает избегать блокировок и позволяет посылать больше запросов без риска быть заблокированным. Однако резидентные и качественные прокси часто платные, кроме того, они замедляют скорость обработки запросов. Так же некоторые сайты умеют обнаруживать использование прокси и могут блокировать адреса прокси-серверов, что приводит к необходимости постоянного обновления списка IP-адресов.
Инструменты веб-скрапинга
Сфера инструментов для веб-скрапинга активно развивается и предлагает всё больше специализированных решений для автоматического извлечения данных. Современные инструменты становятся более универсальными и поддерживают работу с динамическими сайтами, сложными структурами и API-интерфейсами. Платформы с минимальным и полным отсутствием кода (low-code/no-code) делают скрапинг доступным для пользователей без навыков программирования, а интеграция с технологиями машинного обучения и ИИ повышает точность и эффективность.
ParseHub — это универсальный инструмент для веб-скрапинга, предлагающий интерфейс «наведи и кликни» для извлечения данных из комплексных веб-сайтов [2]. Он способен обрабатывать JavaScript и содержимое, загружаемое через AJAX, что делает его подходящим для широкого круга страниц. Пользователи могут планировать задачи парсинга для актуализации данных, а также использовать различные форматы экспорта, включая JSON, CSV, Google Sheets и Tableau. Кроме того, его модель машинного обучения анализирует структуру сайта и рекомендует подходящие данные для извлечения, что улучшает пользовательский опыт и повышает эффективность.
Scrapy — это фреймворк с открытым исходным кодом, разработанный для крупных проектов веб-скрапинга. Scrapy эффективно управляет процессом сбора данных и автоматизирует задачи, такие как обработка ошибок, повторные попытки запроса, а также создание и использование очередей запросов. Scrapy известен своей подробной документацией, что помогает в работе новичкам. Однако из-за обширных функций он имеет крутую кривую обучения и не поддерживает обработку JavaScript, что может ограничивать его использование на некоторых сайтах. Несмотря на эти ограничения, Scrapy популярен среди разработчиков благодаря своей мощности и возможностям для сложных задач парсинга [3].
Diffbot — это платформа для извлечения данных, использующая искусственный интеллект и автоматизирующая процесс преобразования веб-страниц в структурированные данные. Она отличается от традиционного веб-скрапинга тем, что предоставляет доступ к данным веб-страниц как к структурированной базе данных. Это позволяет пользователям получать информацию более систематично, повышая полезность данных для различных приложений.
Python является популярным языком для веб-скрапинга, особенно благодаря библиотекам, таким как Beautiful Soup и Requests [4]. Эти библиотеки упрощают процесс загрузки и парсинга веб-страниц, что делает извлечение данных более доступным. Beautiful Soup особенно хороша для навигации по HTML и XML-документам, а Requests облегчает выполнение HTTP-запросов. В совокупности они представляют собой мощный набор инструментов для веб-скрапинга, подходящий как для новичков, так и для опытных разработчиков.
MechanicalSoup — удобная и легковесная библиотека для Python, которая предназначена для веб-скрапинга и автоматизации взаимодействия с веб-страницами. Она разработана на основе библиотеки BeautifulSoup, которая позволяет легко разбирать HTML, и библиотеки Requests, которая обеспечивает поддержку HTTP-запросов. MechanicalSoup, в отличие от более сложных фреймворков, таких как Scrapy, ориентирован на легкий и быстрый парсинг с простыми задачами, особенно для сайтов с формами и авторизацией [5]. Однако, поскольку библиотека не предназначена для масштабного парсинга, она лучше всего подходит для проектов с небольшими объемами данных и простыми требованиями к сбору.
Вывод
В ходе анализа были рассмотрены различные аспекты и методы парсинга сайтов, включая использование CSS-селекторов, регулярных выражений, headless-браузеров, прокси-серверов, а также доступ к данным через API. Каждый метод имеет свои сильные стороны и области применения. Среди инструментов наибольший интерес представляет библиотека Scrapy. Она обладает широкими возможностями для парсинга, включая интеграцию с headless-браузерами и прокси, поддержку CSS-селекторов, XPath, а также встроенные функции для обработки и хранения данных. Scrapy выделяется гибкостью и расширяемостью, что делает её отличным выбором для автоматизации сбора данных и для крупных проектов, требующих высокой производительности и масштабируемости.
Список использованной литературы
1. Web Scraping for Research: Legal, Ethical, Institutional, and Scientific Considerations [Электронный ресурс] // Computer. – Электрон. дан. - 2024. – Режим доступа: https://arxiv.org/html/2410.23432v1 - Загл. с экрана.
2. 8 Best AI Web Scraping Tools I Tried in 2024 [Электронный ресурс] // Computer. – Электрон. дан. - 2024. – Режим доступа: https://blog.hubspot.com/website/ai-web-scraping - Загл. с экрана.
3. 9 Best Web Scraping Tools to Consider in 2024 [Электронный ресурс] // Computer. – Электрон. дан. - 2024. – Режим доступа: https://hevodata.com/learn/web-scraping-tools/ - Загл. с экрана.
4. Implementing Web Scraping in Python with BeautifulSoup [Электронный ресурс] // Computer. – Электрон. дан. - 2024. – Режим доступа: https://www.geeksforgeeks.org/implementing-web-scraping-python-beautiful-soup/ - Загл. с экрана.
5. A Practical Introduction to Web Scraping in Python [Электронный ресурс] // Computer. – Электрон. дан. - 2024. – Режим доступа: https://realpython.com/python-web-scraping-practical-introduction/#get-to-know-regular-expressions - Загл. с экрана.
Коломойцева И. А., Гембицкий А. В. Исследование современных методов и технологий для парсинга веб-сайтов. В статье рассматриваются основные методы и инструменты для парсинга сайтов, включая использование CSS-селекторов, регулярных выражений, headless-браузеров, прокси-серверов и API-доступа к данным. Подробно анализируются возможности различных подходов и особенности их применения для структурированных и динамических веб-ресурсов. На основе анализа наиболее перспективным инструментом для парсинга выбрана библиотека Scrapy, которая сочетает высокую производительность с гибкостью и возможностью масштабирования.
Ключевые слова: веб, парсинг, метод, технология, данные, обработка.
Kolomoiceva I. A., Gembickiy A. V. Research on Modern Methods and Technologies for Website Parsing. The article examines key methods and tools for website parsing, including the use of CSS selectors, regular expressions, headless browsers, proxy servers, and API-based data access. It provides a detailed analysis of various approaches and their application for structured and dynamic web resources. Based on this analysis, the Scrapy library was selected as the most promising tool for parsing, offering high performance along with flexibility and scalability.
Keywords: web, parsing, method, technology, data, processing.