Аннотация
Истягин А.О., Коломойцева И.А. Алгоритм построения Web-API средствами платформы .NET. В статье рассмотрена методика построения RESTFull API средствами платформы .NET и фреймворка EntityFramework. Рассмотрены паттерны MVC, принципы Dependency Injection и SOLID, приведены рекомендации по архитектуре API и именованию объектов в соответствии с руководством Clean Code.
Введение
Проектирование и разработка клиент-серверных приложений требуют больших затрат времени и человеческих ресурсов. Любое правильно спроектированное приложение гораздо легче реализовать в коде, чем начинать писать без четкой архитектуры.
Существует множество подходов в реализации клиент-серверных приложений: двухуровневые и трехуровневые системы и микросервисные приложения. Двухуровневые приложения имеют клиентскую и серверную часть, в которой совмещены процессы бизнес-логики и хранение данных. Трехуровневые системы разделяют серверную часть на слои бизнес-логики и данных, что облегчает разработку и сопровождение. Микросервисные системы не имеют привычных слоев, вся бизнес-логика заключена в распределенных микросервисах. Двухуровневые системы подходят предприятиям малого бизнеса, так как они компактнее и проще в разработке, но их трудно поддерживать и расширять. Микросервисные приложения следует применять в крупных информационных системах с большими потоками данных и операций. Трехуровневые системы можно применять в системах любого размера.
Промежуточный слой любого трехуровневого приложения называется API – application programming interface – программный интерфейс приложения. Этот слой обеспечивает связь между клиентским (одним или несколькими) приложением и базой данных (также одной или несколькими). Именно в этом слое обрабатывается вся бизнес-логика приложения, т.к. клиентские интерфейсы мы изначально считаем тонкими и не содержащими функций обработки данных. Как же реализовать правильный API?
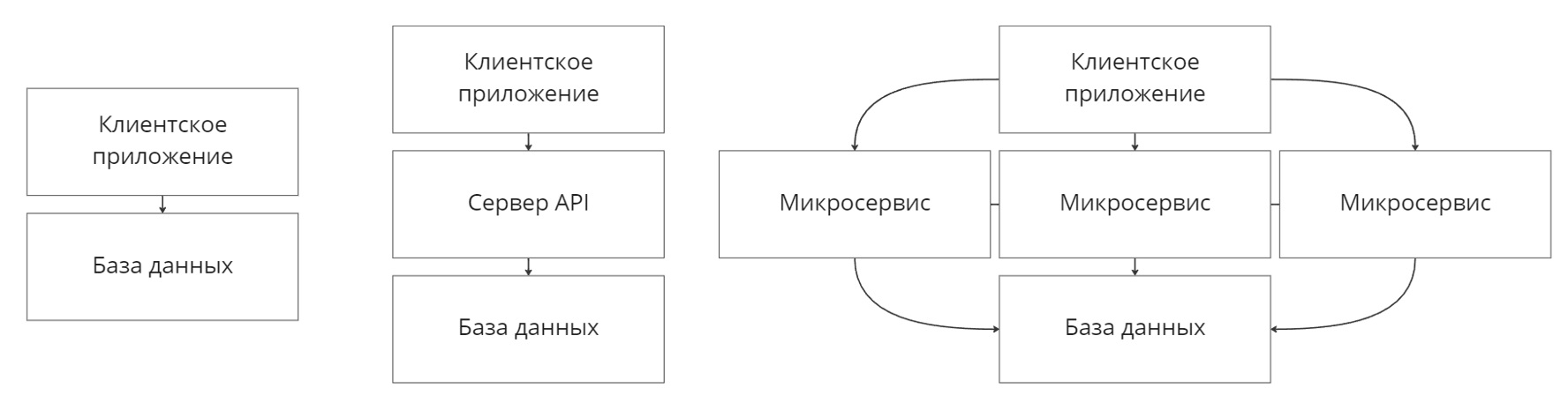
Рисунок 1 – Типы клиент-серверных архитектур.
Постановка задачи
Платформа разработки .NET от Microsoft очень быстро развивается. Новые версии .NET выходят каждую осень. На данный момент актуальная версия платформы – 7, однако уже через год она таковой не будет. Предыдущий релиз .NET 6 имеет долгосрочную поддержку и соответствующую приписку LTS – long term support. Выбранная платформа имеет широкий функционал для реализации API: начиная от одностраничных скриптов и заканчивая объемными системами обработки данных. Вариантов реализации API существует множество, каждая компания пишет по-своему, т.к. установленных стандартов нет.
Целью данной статьи является рассмотрение различных способов построения WebAPI и поиск наиболее оптимальной архитектуры промежуточного слоя.
Анализ существующих подходов
Как было сказано ранее, .NET предоставляет очень широкий спектр возможностей для разработки API, и нет никаких четких инструкций как необходимо писать код. Рассмотрим несколько способов.
Минимальный API [1] представляет собой одностраничный скрипт, который содержит все эндпоинты (конечные точки HTTP/S-запросов для связи с клиентами) и методы для их настройки. Данный метод пригоден только для очень маленьких систем, в которых мало запросов и бизнес-логики (см.рис.2.)

Рисунок 2 – Простейший пример минимального API.
Рассмотренный пример возвращает строку “Hello World!”, когда к API приходит HTTP/S-GET запрос по пути “/”. Нагромождение множества запросов в один файл ведет к множественному дублированию кода, отсутствию единого стиля написания и плохой читабельности. Такой код трудно сопровождать в будущем, так как запросы никак не структурированы и могут располагаться в хаотичном порядке.
Более правильным способом является разделение API на несколько слоев. Так, например, можно выделить слой контроллеров, слой бизнес-логики и слой связи с базой данных:
- контроллеры;
- слой бизнес-логики;
- контекст.
Контроллеры – классы, которые служат для связи системы с клиентскими приложениями. Они принимают HTTP/S-запросы и вызывают методы классов из слоя бизнес-логики, после чего возвращают полученное значение. Контроллеры реализуются средствами платформы ASP.NET и не обладают никакой внутренней логикой. Сервисы бизнес-логики - представляют собой множество классов, которые читают и формируют результат, удаляют, добавляют или удаляют данные, вызывая методы класса-контекста. Для чтения данных можно применять LINQ-выражения, Entity SQL или чистый SQL с внедрением параметров. Контекст – класс-драйвер, который имеет непосредственное подключение к базе данных и читает или записывает данные в нее.
Такое разделение существенно облегчает работу программиста и позволяет писать чистый код. Также можно разделить все классы по сущностям предметной области или по функционалу
Алгоритм реализации WebAPI
Рассмотрим наиболее оптимальный способ построения API. Применим фреймворк Entity Framework [2] (далее EF) для реализации промежуточного слоя информационной системы и разберемся, чем он хорош.
Для начала необходимо спроектировать базу данных. EF предполагает подход Code First – «сначала код» в отличие от привычного Base First, в котором сначала реализовывается база, а потом функции работы с ней. После проектирование схемы данных создадим набор классов-моделей, которые в будущем будут представлять собой таблицы базы данных. Для свойств моделей можно указать аннотации и ограничения, записав их в квадратных скобках, н.: [Key], [MinLength], [MaxLength], [ForeignKey] и другие. Если не указывать первичные ключи, фреймворк сам присвоит первичный ключ первому свойству с именем Id. Также для всех полей с именем Id создастся индекс по умолчанию. Здесь же можно предусмотреть какую-либо базовую модель, которая содержит id записи, даты создания, последнего редактирования, удаления записи из таблицы и прочую информацию, которая должна быть у всех таблиц в базе. Далее необходимо создать класс контекста, пусть он называется Context и наследует методы от DBContext. В нем должны находиться шаблоны списков для всех моделей системы – DBSet<Model>.
Создав все классы и контекст, можно приступить к миграции. Миграция в EF – конвертация классов-моделей в SQL-таблицы и автоматическая установка первичных и внешних ключей, типов данных и ограничений соответствующих полей. Производятся миграции командой Add-Migration “название”, после миграции необходимо синхронизировать данные командой Update-Database. Таким образом, имеем сгенерированную базу данных и набор моделей для нее; за обработку операций связи с базой отвечает созданный класс Context.
Далее необходимо реализовать репозитории – открытые классы, из которых можно читать и в которые можно записывать данные. Если контекст отвечает только за физический доступ к данным, то в репозитории можно добавить минимальную логику (не путать с бизнес-логикой). Классы репозиториев содержат списки моделей, которые ссылаются на списки из контекста. В репозиториях можно генерировать уникальные GUID, устанавливать даты создания и редактирования записей в таблицах, после чего передавать объекты в контекст для сохранения. Также в репозиториях можно обеспечить функции логгирования операций.
Базовый метод разработки предполагает создание одного репозитория для каждой модели базы данных. Если моделей много, следует применить паттерн UnitOfWork, чтобы не нагромождать множество одинаковых классов. В таком случае создается интерфейс базового шаблонного репозитория BaseRepository<Model>, а класс UnitOfWork хранит множество репозиториев. Это убережет проект от излишнего разрастания и обеспечит удобную работу с данными из одного места.
Когда репозитории готовы, можно приступать к слою бизнес-логики. Его также стоит разделить на различные сервисы. Самый простой пример – сервисы чтения ReadServices и сервисы записи WriteServices. Первые отвечают за чтение и формирование результатов, вторые – за добавление и изменение данных. Именно в них должна быть заключена вся бизнес-логика информационной системы.
Как было сказано ранее, существует множество способов прочитать данные из базы средствами EF. Интегрированные выражения LINQ и Entity SQL сначала транслируются в чистый SQL, и лишь затем выполняются. Лишние операции могут привести к задержкам в выполнении запросов. Из этого следует необходимость самим писать SQL-запросы для получения данных с базы. Для этого создадим набор классов Query, в которые поместим базовые запросы Get(id), GetAll(), специальные GetByX(X), где X – параметры чтения (условия отбора, порядок сортировки, группировки и т.п.) или любые другие запросы на чтение. Однако пользователю (клиентским приложениям) не нужны сухие таблицы из базы, ему необходимы свои наборы свойств сущностей предметной области. В этом поможет библиотека Dapper. Она позволяет преобразовать результат SQL-запроса в экземпляр какого-либо класса. Такие классы называются DTO-модели – data transfer objects – или WebEntity. DTO модели служат для обмена информацией между клиентскими и серверными приложениями и содержат только нужную для клиента информацию, а не все данные из таблиц. Для удобства пользования их следует разделять на модели, приходящие с клиентского приложения и уходящие в него, добавляя приписки Request и Response в конце имени класса, н.: GetXResponse и UpdateXRequest для получения и обновления сущности X соответственно.
Не менее важной частью являются сервисы записи. В них происходит вся бизнес-логика системы и обработка всех данных. С клиентского приложения через контроллеры (о них позже) также приходят разнородные DTO-модели, свойства которых не совпадают с полями таблиц в базе данных. Для этого необходимо преобразовать данные с клиента в модели базы данных. В этом поможет библиотека AutoMapper, с ее помощью можно автоматически преобразовывать объекты DTO в объекты моделей БД. Для корректной работы AutoMapper необходимо явным образом указать, преобразования каких объектов будет происходить. Это можно сделать в одном классе Profile или в разделенных XProfile, где X – имя сущности (правила преобразования объектов в библиотеке принято называть профилями). По умолчанию AutoMapper переносит значения полей с одинаковым названием, однако при необходимости можно тонко настроить алгоритм трансляции моделей друг в друга. При необходимости проводить сложные операции бизнес-логики сервис может обращаться к другим сервисам и репозиториям, однако пользователь не должен ожидать ответа. После всех операций объекты можно записывать в репозитории, после чего сохранять изменения в контексте.
Верхний уровень API – контроллеры, разрабатываемые средствами веб-платформы ASP.NET. Методы этих классов вызываются, когда на адрес приложения приходит HTTP/S запрос (с указанием конечного пути – эндпоинта – и передаваемых данных). Для контроллеров также указываются аннотации перед методами, такие как [HttpGet("{id}")], [HttpPost], [Route("api/[controller]")] и другие. Контроллеры также разделяют по ключевым сущностям предметной области, и каждый контроллер хранит в себе соответствующие сервисы. При вызове методов он передает данные в методы сервисов и возвращает ответ из них, оборачивая ответ в Ok(message) при успешном завершении и Conflict(message) в случае ошибки. Эти методы присвоят HTTP/S ответу соответствующие заголовки и статус ответа, после чего вернут ответ клиентской программе. В общем случае передаются объекты в JSON-нотации. Их удобно распознавать на стороне клиента, но они могут иметь избыточное описание при передачах массивов. Важно: в контроллерах не стоит описывать какую-либо логику приложения, это необходимо делать в других классах.
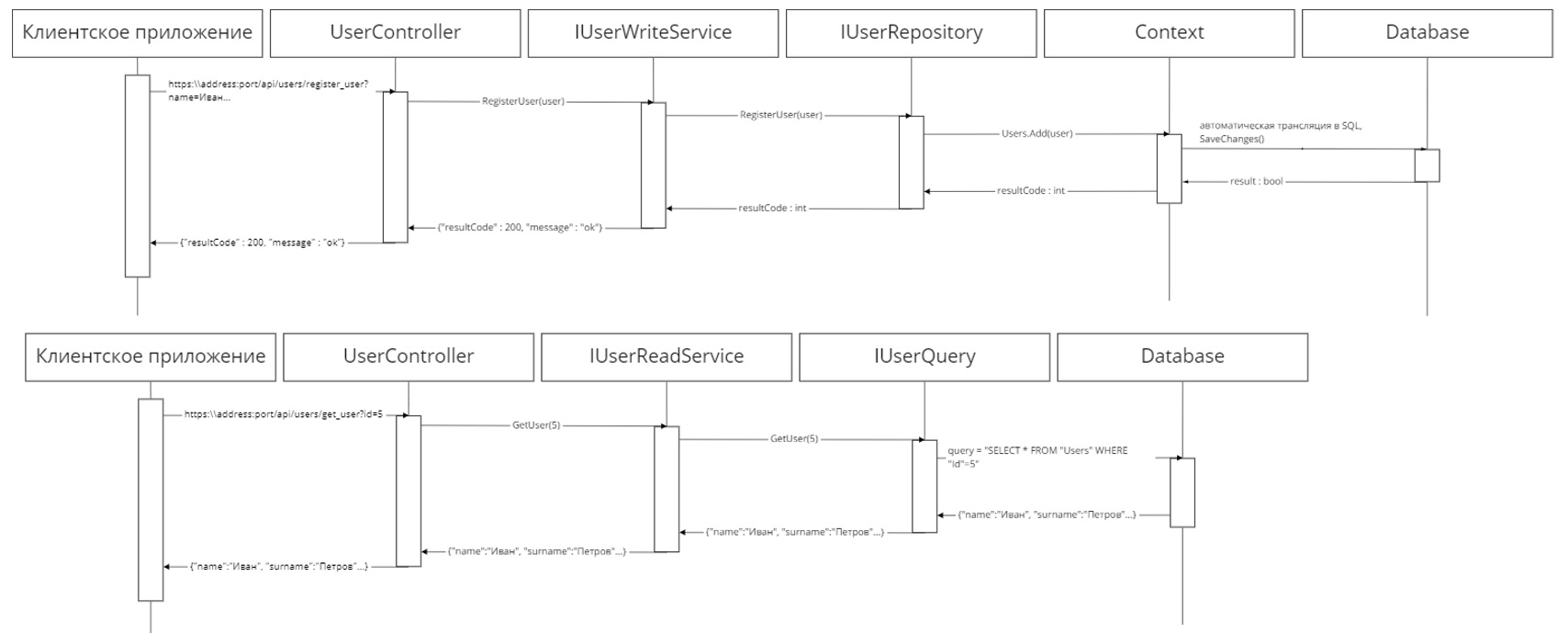
Рисунок 3 – Пример диаграммы последовательностей жизненного цикла запроса.
Для функционирования API разработать вышеназванные классы недостаточно. Применяя принцип DI [4] – Dependency Injection – внедрение зависимостей – все разработанные классы и их интерфейсы необходимо явно указать в скрипте настройки приложения. Чтобы понять, зачем это, разберем базовый жизненный цикл запроса API. HTTP/S-запрос приходит с клиента, обрабатывается API, проходя через различные сервисы, и возвращается результат обработки. Запросы и процессы их обработки никак не связаны между собой, все операции проходят независимо друг от друга. Существует три способа указать явное внедрение зависимостей. AddTransient подразумевает, что сервис создается каждый раз, когда его запрашивают. Этот жизненный цикл лучше всего подходит для легковесных, не фиксирующих состояние, сервисов. AddScoped - сервис создаются единожды для каждого запроса. AddSingleton - сервис создается при первом запросе (или при запуске приложения), а затем каждый последующий запрос будет использовать этот же объект сервиса.
Применяя AddScoped, для каждого отдельного запроса экземпляры соответствующих классов (контроллеров, сервисов, репозиториев, профилей) создаются заново. Экземпляры всех нижележащих классов необходимо передавать вышележащим экземплярам. Указанные в скрипте настройки классы будут автоматически подставляться в те конструкторы, которые их требуют. Например, в конструкторе контроллера должны быть сервисы, в сервисах – запросы или репозитории. Это существенно сократит время разработки и упростит понимание кода в будущем.
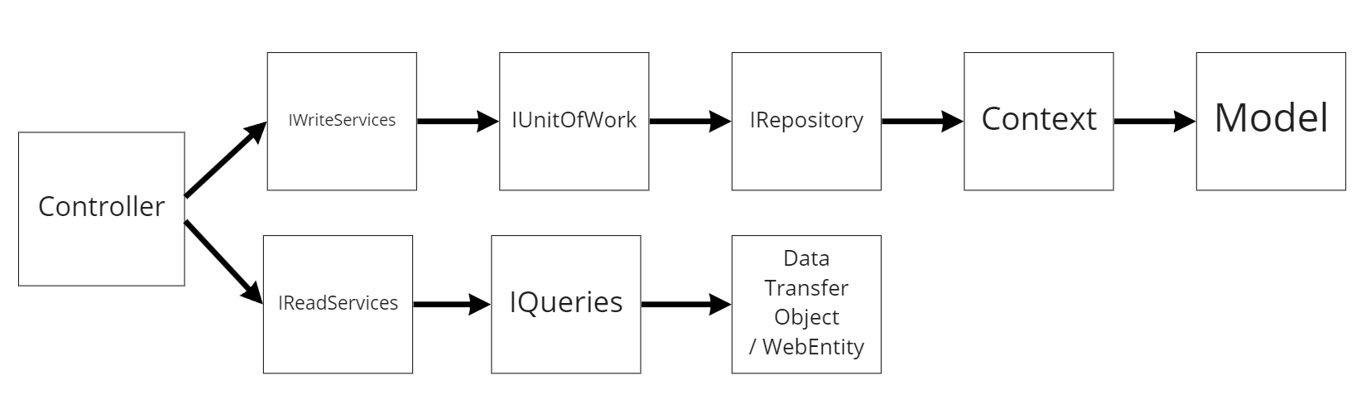
Рисунок 4 – Структура ASP.NET Web API.
Немаловажной частью любой системы является механизм безопасной регистрации и авторизации пользователей. Рассмотрим такой механизм, предложенный платформой ASP.NET, который называется ASP.NET Identity. Помимо непосредственной регистрации и авторизации в системе он также позволяет проводить интеграцию со многими сторонними сервисами. Для начала нужно указать контексту, что в базе будет храниться информация о пользователях и их ролях: унаследуем созданный контекст от ApplicationDbContext, также создадим модели пользователей и ролей, унаследованные от библиотечных IdentityUser и IdentityRole соответственно. В скрипте настройки API можно указать параметры регистрации пользователей: длина пароля, необходимость ввода цифр, букв верхнего регистра, блокировка после неуспешных попыток ввода и др. Теперь необходимо заново провести миграцию и обновить базу данных, чтобы таблицы с полями и пользователями были занесены в БД. Чтобы создать пользователя-администратора и базовые роли по умолчанию, создадим класс DBSeed, в котором инициализируем необходимые данные. Методы класса DBSeed должны вызываться в методе OnModelCreating() контекста. Далее необходимо реализовать функционал JWT – JSON web token. Токены JWT представляют собой зашифрованные строки, которые передаются пользователю и используются как идентификатор сессии. В классе JWTMiddleware (от middleware – промежуточный слой) реализуем функционал генерации и валидации токенов. Генерация происходит в методе Login() контроллера пользователей, валидация – при каждом обращении к какому-либо запросу. Осталось указать, какие роли могут выполнять те или иные запросы. Для этого укажем в аннотациях соответствующих методов список ролей, которые могут выполнять данные методы (или взаимодействовать со всеми методами контроллера сразу).
Понимание того, как работают механизмы и алгоритмы разрабатываемой системы критически важно для программиста. JWT – строковый ключ, основанный на формате JSON, что следует из названия. Он состоит из трех частей: заголовка, полезной нагрузки и цифровой подписи. В заголовке должен быть указан алгоритм ЭЦП (электронной цифровой подписи) и могут быть указаны тип токена и тип содержимого (чаще всего указываются значения “JWT” в обоих полях. В полезной нагрузке указывается идентификатор пользователя, идентификатор самого токена, время его создания и длительность его жизни. Устаревшие токены не проходят валидацию и считаются нерабочими. Подписанные токены также называют JWS – JSON Web Signature.
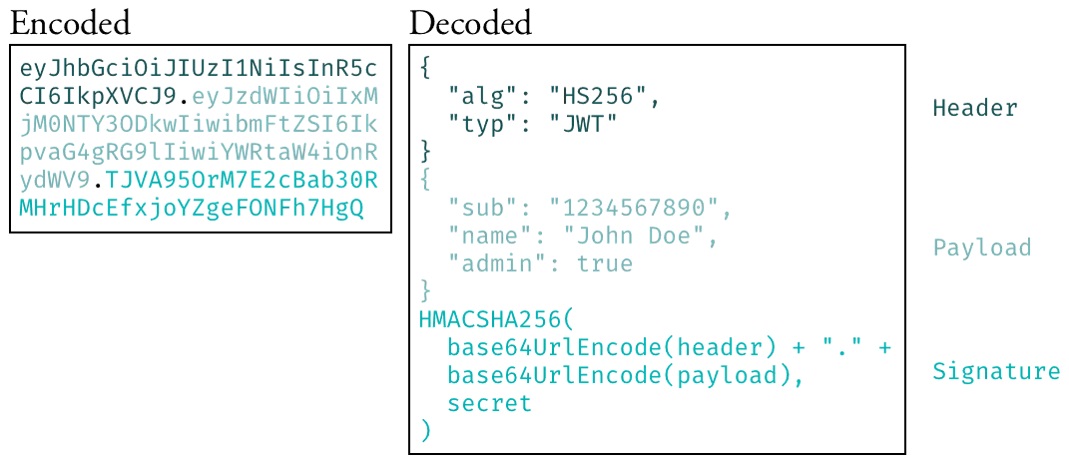
Рисунок 5 – Структура токена JWT
Для комфортного отображения, полученного API следует применить технологию Swagger [5]. Данное средство позволяет визуализировать все контроллеры и их методы, передаваемые и возвращаемые данные и сохранять токены авторизации. Сгенерированная Swagger-документация представляет собой JSON-файл, в котором отображена вся информация об эндпоинтах API. Такой файл можно передать разработчикам клиентского приложения, что благотворно повлияет на процесс разработки.
SOLID – акроним из пяти основных принципов объектно-ориентированного проектирования и программирования [7, 8]. Соблюдение этих принципов способствует созданию системы, которую легко сопровождать и поддерживать, в том числе расширять, в течение долгого времени. Рассмотрим их подробнее. SRP – Принцип единичной ответственности – «для каждого класса определено единственное назначение, все ресурсы которого инкапсулированы в самом классе». Каждый класс приложения выполняет только те функции, которые обозначены в его названии: сервисы обрабатывают логику, репозитории хранят данные, модели хранят форму данных, DTO передаются между клиентом и сервером и т.д. OCP – Принцип открытости-закрытости – «программные сущности (классы и модели) открыты для расширения и закрыты для модификации». Разделение логики приложения позволяет быстро и без изменений существующей системы добавить новый функционал. LSP – Принцип подстановки Лисков – «функции могут использовать подтипы базового типа, не зная об этом». Для простых сервисов чтения можно реализовать шаблонные функции чтения; шаблоны репозиториев работают без указания конкретных типов. ISP – Принцип разделения интерфейса – «много интерфейсов для клиентов лучше, чем единый интерфейс общего назначения». Группировка контроллеров и сервисов логики по ключевым сущностям предметной области. DIP – Принцип инверсии зависимостей – «зависимость на абстракциях, а не на конкретных объектах». Шаблонные репозитории и UnitOfWork; все операции происходят через интерфейсы соответствующих классов. Таким образом, разработанные по вышеописанному алгоритму WebAPI удовлетворяют всем принципам SOLID.
Выводы
Предложенный алгоритм построения API средствами платформы .NET является базовым и может быть модифицирован в соответствие со специфическими требованиями предметной области. Могут быть добавлены любые дополнительные механизмы: шифрование данных, функции логгирования и отслеживания проведенных транзакций на уровне middleware и т.п.
Рассмотренная архитектура API реализует различные паттерны и принципы высокоуровневого проектирования и программирования (DI, UnitOfWork, CodeFirst). В общем виде соблюден паттерн MVC [6], где Model – модели базы данных и слой контекста, View – контроллеры и Swagger-документация, а Controller – управляющие методы контроллеров и сервисы чтения и записи. Помимо MVC данный подход API удовлетворяет принципу SOLID. Схожие методы, с учетом специфики требований, используют многие крупные предприятия, в том числе Microsoft, IBM, Intel, Cisco, Siemens, Starbucks, StackOverflow и другие.
Список использованной литературы
1. Общие сведения о минимальных API [Электронный ресурс] / Режим доступа: https://learn.microsoft.com/ru-ru/aspnet/core/fundamentals/minimal-apis?view=aspnetcore-6.0&viewFallbackFrom=aspnetcore-2.0
2. Документация по Entity Framework [Электронный ресурс] / Режим доступа: https://learn.microsoft.com/ru-ru/ef/
3. Документация по AutoMapper [Электронный ресурс] / Режим доступа: https://docs.automapper.org/en/stable/
4. Симан, М. Внедрение зависимостей в .NET / М. Симан. — Санкт-Петербург: Питер, 2013. – 464 c.
5. API Development for Everyone [Электронный ресурс] / Режим доступа: https://swagger.io
6. Фримен, А. ASP.NET MVC 4 с примерами на C# 5.0 для профессионалов, 4-е издание /А. Фримен — М.: «Вильямс», 2013. — 688 с.
7. Мартин, Р.С. Быстрая разработка программ. Принципы, примеры, практика / Р. С. Мартин, Дж. В. Ньюкирк, Р. С. Косс. — Вильямс, 2004, ISBN 5-8459-0558-3, ISBN 0-13-597444-5
8. Мартин, Р.С. Чистый код: создание, анализ и рефакторинг. Библиотека программиста /Р.С. Мартин. — СПб.: Питер, 2013. — 464 с.: ил