Аннотация
Черкасов А.Н. Туркин Е.А. Выбор оптимальной архитектуры искусственной нейронной сети для задачи классификации текстов. В связи с растущей потребностью изучения роли человеческого фактора в рамках информационной безопасности была предпринята попытка применить искусственные нейронные сети для решения социально значимых проблем, связанных с информационными рисками. Основная цель исследования заключается в выборе оптимальной архитектуры нейронной сети, которая способна наиболее эффективно определять тональность сообщений на Интернет-форумах. В статье проведен обзор ряда архитектур искусственных нейронных сетей, которые применяются для определения эмоциональной окраски текстов. Рассматриваемые модели были подвергнуты анализу на предмет качества определения тона текстов. Применение модели сверточной нейронной сети, совмещенной с элементами рекуррентной нейронной сети, позволило получить точность определения окраски текста, равную 87,77%. В дальнейшем отобранная модель станет базисом для комплексной аналитической платформы в виде программного обеспечения, которое нацелено на идентификацию особенностей лексических форм, входящих в основу вербальной модели потенциального злоумышленника в рамках информационной безопасности.
Введение
Развитие технологии искусственного интеллекта и машинного обучения началось с 40-х годов прошлого столетия [1]. Однако из-за высоких требований к вычислительным ресурсам для обучения и работы нейронных сетей они применялись достаточно редко.
Современный уровень скорости вычисления и появление многих архитектур нейронных сетей позволили значительно расширить область их применения. Отдельного внимания заслуживает область обработки и анализа текстов в целях оценки поведения пользователя. Например, такая информация позволяет адаптировать систему поддержки принятия решений для различных задач в рамках ситуационного центра [2].
Анализ тональности текста используется для выявления эмоционально окрашенной лексики [3]. Распознавание эмоциональной окраски сообщений пользователей позволяет определять их отношение к тем или иным объектам, темам и субъектам. Сегодня анализ тональности текстов актуален во многих сферах – экономика, политика, социология, маркетинг и менеджмент. В описанных выше областях использование NN (Neural Network) уже становится повсеместным явлением. Много реже NN используют в управленческих решениях, касающихся безопасности.
Искусственные нейронные сети могут быть использованы в качестве инструмента анализа текстов с целью определения лексических форм и общей семантики [4]. Впоследствии результаты анализа могут быть использованы экспертами для выявления склонности человека к определенным действиям, нарушениям в области информационной безопасности
Несмотря на большое количество проведенных исследований, в области применения нейронных сетей обработки текстов существует ряд пробелов:
-
Анализ тональности текстов применяется в области управления довольно часто, но применение его огранивается распределением данных на положительно окрашенные и отрицательно окрашенные;
-
Лексические аспекты и общее настроение сообщений по конкретной теме могут быть использованы для определения поведенческих особенностей человека и выявления склонности к злонамеренным действиям;
-
Проводится множество аналитических операций без практического применения результатов [5, 6], таких как сокращение преступлений в области информационной безопасности.
Методы и материалы исследования
В ходе выполнения данной работы были обучены несколько моделей нейронных сетей. Среди архитектур искусственных нейронных сетей, применяемых для обработки текстов, следует выделить сверточные нейронные сети – CNN (Convolutional Neural Network) [7] и рекуррентные нейронные сети – RNN (Recurrent Neural Network) [8], атакже различные их комбинации. Изначально сверточные нейронные сети были предложены для обработки изображений [1, 9], однако со временем эта модель стала применяться и для задач обработки текстов. Использование CNN позволяет ускорить процесс обучения, поскольку их архитектура подразумевает возможность параллельных вычислений большого количества данных.
Были выбраны следующие варианты архитектур моделей для обработки текстов с помощью искусственных нейронных сетей:
-
Рекуррентная нейронная сеть из одного слоя LSTM. Далее эта архитектура будет наименоваться LSTM;
-
Рекуррентная нейронная сеть из двух слоев LSTM. Этой архитектуре будет дано название LSTM-2;
-
Сверточная нейронная сеть и рекуррентная нейронная сеть из одного слоя LSTM. Данная архитектура будет наименоваться CNN-LSTM.
-
Размерность словаря. Были опробованы словари размерности 10000 и 15000 слов;
-
Размерность фрагмента текста 128, 196 символов;
-
Максимальная длина текста 250 символов.
-
Все спец. символы были удалены;
-
Из слов были выделены их стеммы (основы для заданных слов);
-
Буква
ё
была заменена на буквуе
.
Стоит отметить, что зачастую рекуррентная архитектура нейронной сети является более предпочтительной. Связано это с тем, что анализ каждого слова основан не только на значении его эмоциональной окраски, но и на значении предыдущих слов. Этот факт позволяет анализировать эмоциональную семантику отдельных слов, а также и эмоциональное значение цельного предложения.
Для выбранных архитектур моделей классификации были выделены следующие гиперпараметры:
Набор данных для обучения содержал равное количество фрагментов текстов, помеченных как «положительные» и «отрицательные». Для оценки качества обучения была выбрана метрика Accuracy (точность). При прекращении роста параметра точности на валидационной выборке процесс обучения приостанавливался, поскольку далее имеет место переобучение модели.
Обучение выбранных моделей происходило по схеме обучения с учителем. Процент валидационной выборки данных составлял 10% от общего количества данных для обучения.
Тексты прошли предварительную подготовку к обработке:
Для борьбы с переобучением моделей была применена Dropout регуляция [10].
Алгоритм анализа моделей нейронных сетей может быть представлен следующей схемой (рис. 1)
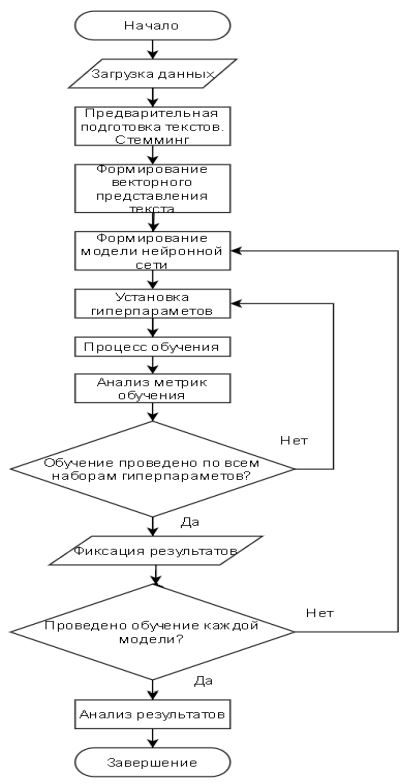
Рисунок 1 – Алгоритм проведения анализа нейронных сетей
На основании описанных ранее условий было проведено обучение моделей с заданными архитектурами и гиперпараметрами. Результаты обучения приведены в таблице 1.
Лучшее значение метрики Accuracy на валидационном наборе данных показала модель CNN-LSTM с размерностью словаря 15000, длиной текста 250 и размером фрагмента 128.
Стоит заметить, что на тестовом наборе данных значение метрики Accuracy составило 87,77%.
Данная модель может быть представлена следующей схемой (рис. 2).
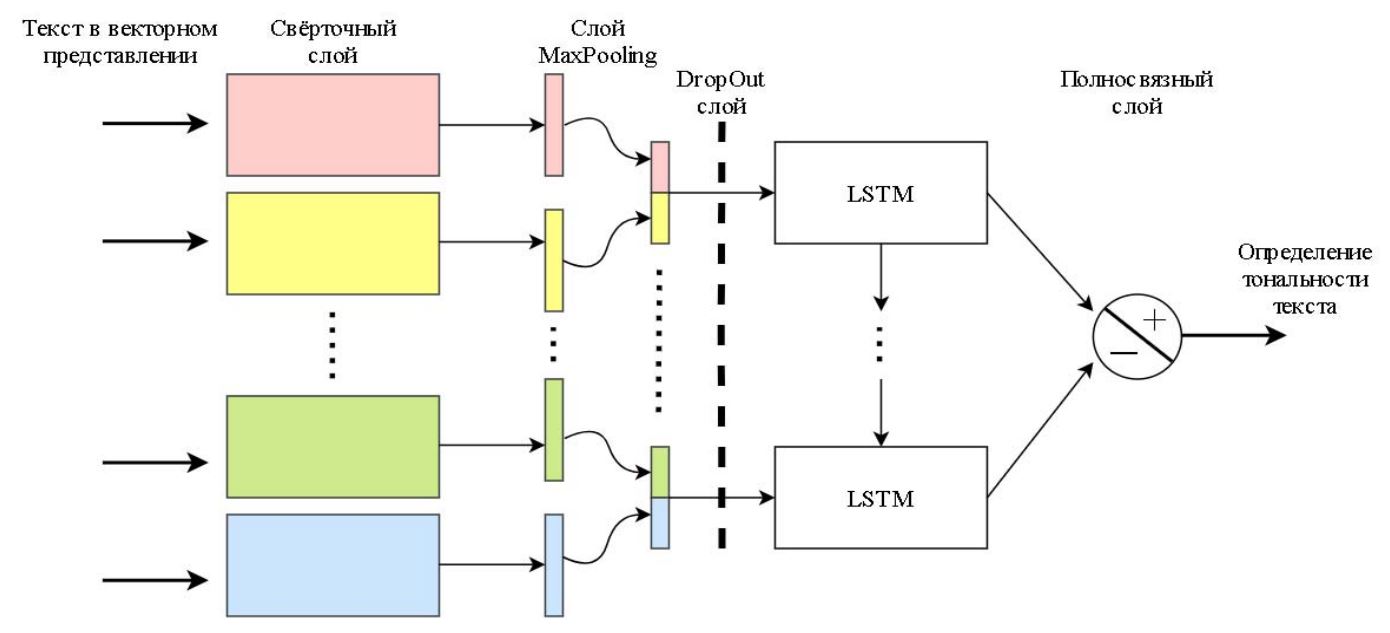
Рисунок 2 – Структура модели CNN-LSTM
Выбранная модель искусственной нейронной сети использована как одна из технологий автоматизации анализа текстов и определения лексики, наиболее характерной для субъектов, склонных к тем или иным действиям в определенной ситуации. В качестве эксперимента рассматривались лексика и смысловые фразы в области информационной безопасности. Результаты эксперимента показали, что выбранная модель позволяет с достаточной точностью анализировать текст, определять лексику и действия субъекта.
Заключение
Проведены реализация и обучение нескольким моделям искусственных сетей с различными комбинациями настраиваемых параметров. По итогам обучения и последующего тестирования была выбрана CNN-LSTM сеть, позволяющая составлять наиболее точные заключения об эмоционально-семантической окраске текста.
Данная модель может быть взята за основу в качестве многокритериального классификатора. Каждый текст будет подвергнут анализу, итогом которого будет заключение о склонности автора текста к определенным поведенческим паттернам.
Список использованной литературы
1. McCulloch Warren S., Walter Pitts. A logical calculus of the ideas immanent in nervous activity // Springer New York. 1943. P. 115–133.
2. Симанков В.С., Черкасов А.Н. Анализ и синтез системы поддержки принятия решений на основе интеллектуальных систем ситуационного центра // Глобальный научный потенциал. 2014. № 12 (45). С. 114–122.
3. Рубцова Ю. Автоматическое построение и анализ коротких текстов (постов микроблогов) для задачи разработки и тренировки тонового классификатора // Инженерия знаний и технологии семантического веба. СПб.: Университет ИТМО, 2012. Т. 1. С. 109–116.
4. Тарасов Е.С. Разработка лингвосемантических методов обработки экспертной информации для ситуационных центров органов государственной власти: дис. ... канд. техн. наук. Kраснодар: КубГТУ, 2011. 198 c.
5. Краснов Ф.В. Анализ тональности текста научно-практических статей по нефтегазовой тематике с помощью искусственных нейронных сетей // Вестник Евразийской науки. 2018. Т. 10, № 3. 10 с. URL: https://esj.today/PDF/43ITVN318.pdf (дата обращения: 07.02.2020).
6. Cмирнова О.С., Шишков В.В. Выбор топологии нейронных сетей и их применение для классификации коротких текстов // International Journal of Open Information Technologies. 2016. Т. 4, № 8. С. 50–54.
7. Kim Y. Convolutional neural networks for sentence classification // arXivpreprintarXiv: 1408.5882. 2014. P. 1746–1751.
8. Recurrent neural network based language model / T. Mikolov, M. Karafiat, L. Burget, J. Cernocky, S. Khudanpur // Eleventh Annual Conference of the International Speech Communication Association. 2010. P. 1045–1048.
9. Gradient-based learning applied to document recognition / Yoshua Bengio, Yann LeCun, Leon Bottou, Patrick Haner // IEEE. 1998. No. 86 (11). P. 2278–2324.
10. Воронцов К.В. Курс лекций по машинному обучению. 2015. URL: https://yar.ru/2020/05/07/vorontsov-kurs-mashinnoeobuchenie-2019-shkola-analiza-dannyh/