Источник: Современные информационные технологии в образовании и научных исследованиях (СИТОНИ-2023) : сб. материалов VIII Всерос. науч.-техн. конф., г. Донецк, 29 нояб. 2023 г. / отв. ред. В. Н. Павлыш. – Донецк : ДонНТУ, 2023. - С. 116-123.
УДК 004.93
ОБНАРУЖЕНИЕ И КЛАССИФИКАЦИЯ ОБЪЕКТОВ НА ИЗОБРАЖЕНИИ С ПОМОЩЬЮ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ СЕМЕЙСТВА YOLO
А.Р. Муращенко, О.И. Федяев
ФГБОУ ВО «Донецкий национальный технический университет» (г. Донецк)
кафедра «Программная инженерия им. Л.П.Фельдмана»
e-mail: sasha.mur01@mail.ru, olegfedyayev@yahoo.com
Муращенко А.Р., Федяев О.И. Обнаружение и классификация объектов на изображении с помощью нейросетевых моделей семейства YOLO. В работе рассматриваются основные методы и способы обнаружения и классификации объектов на изображении. Анализ показал достоинства и недостатки разных версий модели при обработке статичных изображений и обработке изображений в режиме реального времени. В качестве сравнения были выбраны модель YOLOv3 и YOLOv8.
Ключевые слова: нейросеть, модель YOLO, обнаружение объектов на изображении, классификация объектов
Введение
Компьютерное зрение — это одно из направлений искусственного интеллекта, которое позволяет компьютерам идентифицировать или распознавать шаблоны или объекты в цифровых медиа, включая изображения и видео [1]. Модели компьютерного зрения могут анализировать изображение, чтобы распознавать или классифицировать объект на изображении, а также реагировать на эти объекты. Основная цель модели компьютерного зрения идёт дальше, чем просто обнаружение объекта на изображении, она также взаимодействует с объектами и реагирует на них.
Помимо компьютерного зрения, есть также машинное зрение. По сути, это то же компьютерное зрение, но применяется оно для решения конкретной прикладной задачи [2]. Например, на производстве ставят камеру, которая следит за качеством продукции на конвейере. Если такая камера увидит брак, то она предупредит об этом человека-оператора - и это единственная её задача. В этом случае компьютерное зрение можно назвать машинным зрением [2]. В настоящее время машинное и компьютерное зрение очень востребовано различными отраслями, динамика рынки систем распознавания постоянно растёт.
Для распознавания и классификации объектов в последнее время успешно используют различные нейросетевые модели и методы [1]. Каждая модель нейронной сети имеет свои достоинства и недостатки. Современные алгоритмы обработки изображений обычно используют модели глубокого обучения, которые при идентификации объектов учитывают сложные взаимосвязи на уровне пиксельного описания характерных признаков с последующим многоуровневым их обобщением. Качество распознавания во многом зависит от архитектуры используемой нейросети, стратегии обучения и обучающего множества. Для этого собирают и помечают набор изображений, например все изображения с человеком называют «человек». Затем эти данные передаются в нейронную сеть для обучения. Чаще всего для распознавания используют именно свёрточные нейронные сети (CNN), так как они гораздо лучше понимают особенности каждого объекта. После этого производится тестирование на изображении с объектами [1]. Модель будет использовать полученный набор данных для предсказания объекта на изображении и его распознавания.
Основной целью данной работы является выбор модели свёрточной нейронной сети из семейства YOLO для создания программных систем распознавания объектов на фото- и видео-изображениях в реальном времени.
Обзор работ по компьютерному зрению на основе моделей YOLO
На данный момент существует очень мало обзоров и сравнений версий нейронной сети YOLO.
В статье «Benchmarking YOLOv5 and YOLOv7 models with DeepSORT for droplet tracking applications», которая была написана в январе 2023 года, автор экспериментально сравнивает точность и скорость двух версий данной нейросети определённым методом[3]. Однако автор не рассказывает, как именно работают версии YOLO. Также в этой публикации указывается, что v7 является последней версией YOLO, однако на данный момент это не так.
В статье «Wearing face mask detection using deep learning through COVID-19 pandemic», которая была написана 28 апреля 2023 года, автор сравнивает модели для обнаружения масок на людях, а именно Single Shot Detection, YOLOv4-tiny, YOLOv4-tiny-3l[4]. Однако автор лишь упоминает о версиях YOLOv3, YOLOv3-tiny, YOLOv5. При этом модель SSD имеет слишком низкую скорость обнаружения объектов, хоть и является очень точной, поэтому она не подходит для обнаружения объектов в реальном времени.
Актуальность
Скорость и точность YOLO сделали его популярным выбором для многочисленных приложений для обнаружения объектов в реальном времени [5]. Вот несколько областей, в которых YOLO продемонстрировал свою эффективность:
- наблюдение и безопасность: обнаружение камеры YOLO в режиме реального времени можно использовать для наблюдения за общественными местами в режиме реального времени, выявления угроз безопасности и обеспечения общественной безопасности [5];
- робототехника и дроны: YOLO можно использовать в робототехнике и дронах, чтобы обеспечить возможности обнаружения и отслеживания объектов, что позволяет им эффективно перемещаться и взаимодействовать с окружающей средой;
- автономные транспортные средства: возможности YOLO в реальном времени делают его ценным компонентом автономных транспортных средств для обнаружения объектов, позволяя им воспринимать окружающую среду и реагировать на неё в режиме реального времени [5];
- обнаружение болезней на снимках: YOLO можно использовать для обнаружения дефектов на медицинских снимках, например на ЭКГ, это позволит существенно улучшить медицину во всём мире;
- розничная торговля и управление запасами: камеры наблюдения YOLO в режиме реального времени можно использовать в настройках розничной торговли для отслеживания запасов, отслеживания поведения покупателей и улучшения качества покупок [5].
Однако разные версии модели YOLO по разному работают с фото- и видеоизображениями. За последние годы вышло много версий данной модели. Однако, на данный момент авторы оригинальной YOLO сделали версии v1, v2, v3, v5, v8. В данной работе будет анализ и сравнение моделей YOLOv3 и YOLOv8.
Сравнение моделей YOLOv3 и YOLOv8
На вход модели YOLO поступает цифровое изображение – это двоичное представление визуальных данных. Оно содержит серию пикселей, расположенных в виде сетки, где каждая ячейка содержит визуальные данные: яркость и цвет.
CNN обычно имеет три уровня: свёрточный слой, слой объединения и полностью связанный слой, как показано на рисунке 1.
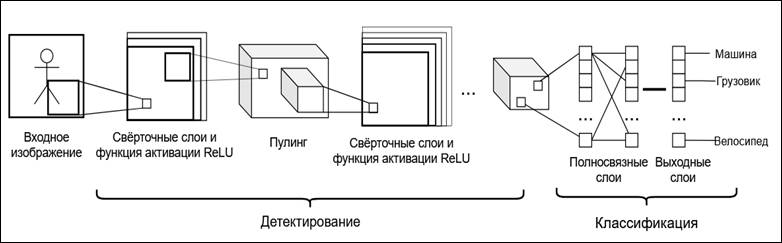
Рисунок 1 – Архитектура работы свёрточной нейронной сети
На рисунке показаны следующие главные элементы свёрточной нейронной сети:
- изображение в качестве входных данных.
- свёрточные слои: применяются фильтры (ядро свертки) к входному изображению для выявления признаков, таких как края, углы и другие текстурные элементы;
- функция активации ReLU: используется для добавления нелинейности, позволяющей сети обучаться более сложным паттернам;
- слой пулинга: уменьшает размерность пространственных данных, сохраняя при этом важные признаки, что уменьшает количество параметров и вычислительную сложность;
- полносвязные слои: после выделения признаков и снижения размерности данных, полносвязные слои комбинируют признаки для классификации и определения положения объектов;
- выходные данные: на последнем этапе, с помощью функции активации softmax, сеть предсказывает вероятности принадлежности выявленных объектов к определенным классам (например, автомобиль, пешеход) и их расположение на изображении.
В модели YOLOv3 реализован алгоритм обнаружения объектов в реальном времени, позволяющий идентифицировать конкретные объекты в видео, прямых трансляциях или изображениях. Для обнаружения объекта алгоритм машинного обучения YOLO использует характеристики, полученные глубокой свёрточной нейронной сетью. Версии 1-3 алгоритма YOLO были созданы Джозефом Редмоном и Али Фархади, а третья версия алгоритма машинного обучения YOLO является более точной версией оригинального алгоритма машинного обучения (ML).
Другие архитектуры нейросетей в основном использовали метод скользящего окна по всему изображению, и классификатор использовался для определенной области изображения (DPM). Также, R-CNN использовал метод предложения регионов (region proposal method). Описываемый метод сначала создаёт потенциальные якорные рамки. Затем, на области, ограниченные якорными рамками, запускается классификатор и следующее удаление повторяющихся распознаваний, и уточнение границ рамок.
По сравнению с алгоритмами распознавания алгоритм обнаружения предсказывает метки классов и определяет местоположение объектов. Таким образом, он не только классифицирует изображение по категории, но также может обнаруживать несколько объектов в изображении. Этот алгоритм применяет одну нейронную сеть к полному изображению. Это означает, что эта сеть делит изображение на области и предсказывает ограничивающие рамки и вероятности для каждой области. Прогнозируемые вероятности взвешивают эти ограничивающие рамки.
На следующем рисунке 2 представлена общая структура сети YOLOv3. На рисунке можно видеть: входное изображение размером (608 x 608) пикселей попадает в сеть Darknet-53 и получает 3 ветви. Эти ветви проходят серию свёрток, повышающей дискретизации, а после объединения и других операций в итоге получаются три карты характеристик разного размера, формы.
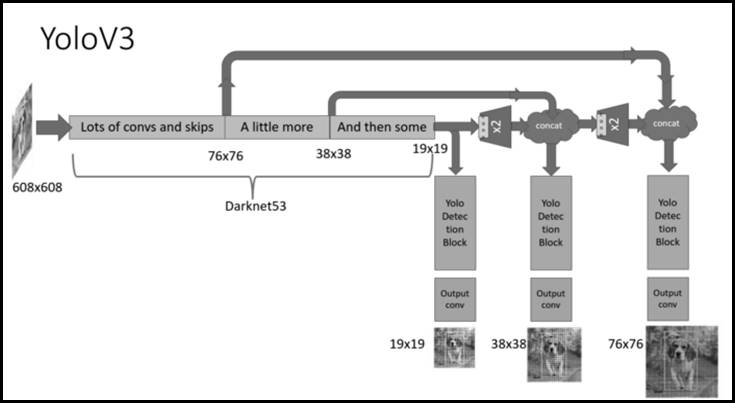
Рисунок 2 – Архитектура работы сверточной нейронной сети YOLOv3
В YOLOv3 используются якорные рамки для прогнозирования, которые существенно увеличивают точность обнаружения [6]. При распознавании используется сетка, в которой каждая ячейка предсказывает:
- для каждой якорной рамки: 4 координаты (tx , ty , tw , th), 1 ошибку объективности, которая является показателем уверенности в присутствии того или иного объекта;
- некоторое количество вероятностей классов.
Визуализация якорной рамки представлена на рисунке 3. Значения bx, by, bw, bh определяют координаты центра x, y, ширину и высоту текущего прогноза, а значения tx, ty, tw, th (xywh) — это то, что выводит сеть. Значения cx и cy определяют верхние левые координаты сетки, а pw и ph — размеры якорных рамок для блока.
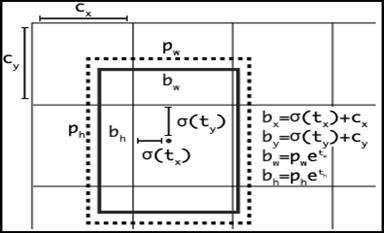
Рисунок 3 – Визуализация якорной рамки
Модель предсказывает ширину и высоту рамки в виде смещения от центров кластеров. Координаты центра поля относительно места применения фильтра предсказываются с помощью сигмоидальной функции. Если для объекта предварительно не указана граница, то он не несёт потерь в предсказании координат и классов, а только в объектности.
У всех моделей YOLO присутствует алгоритм «подавления не-максимумов», который делает модели данного семейства лидером в обнаружении объектов в реальном времени. Подавление не-максимумов это метод постобработки, используемый в алгоритмах обнаружения объектов для уменьшения количества перекрывающихся ограничивающих рамок и улучшения общего качества обнаружения. NMS отфильтровывает избыточные и нерелевантные ограничительные рамки, оставляя только самые точные. На рис. 4 показан алгоритм этого метода на псевдокоде. На рис. 5 показан результат работы этого алгоритма.

Рисунок 4 – Алгоритм «подавления не-максимумов» на псевдокоде

Рисунок 5 – Результат работы алгоритма «подавления не-максимумов»
Результат обнаружения объектов при помощи YOLOv3 представлен на рисунке 6. Созданная система компьютерного зрения обнаружила две машины, пометила их меткой car с процентом совпадений 90% и 100%, светофор меткой traffic light с процентом совпадений 100%. Обнаружение заняло 0.4 секунды при нагрузке на видеокарту и 2.2 секунды при нагрузке на процессор.

Рисунок 6 – Результат работы модели YOLOv3
Достоинства модели YOLOv3:
- высокая точность;
- гибкая настройка.
Недостатки модели YOLOv3:
- низкая скорость обработки видео;
- высокая нагрузка на систему.
Таким образом, модель YOLOv3 является хорошим вариантом для обработки статичных изображений, но плохо подходит для обработки видеоизображений в реальном времени.
YOLOv8 — новейшая современная модель YOLO, которая может быть использована для задач обнаружения объектов, классификации изображений и сегментации экземпляров.
YOLOv8 — это модель без якоря. Это означает, что она предсказывает непосредственно центр объекта, а не смещение от якорных рамок [4]. Обнаружение без привязки уменьшает количество прогнозов блоков, что ускоряет не-максимальное подавление (NMS) — сложный этап постобработки, который отсеивает обнаружения-кандидаты после вывода.
Компоненты архитектуры YOLOv8:
- backbone: извлекает признаки из входного изображения с помощью;
- neck: объединяет различные уровни признаков для улучшения точности;
- head: предсказывает координаты и классы объектов;
- upsample: увеличивает разрешение карты признаков;
- loss function: оценивает ошибку в предсказаниях и обновляет веса модели.
В YOLOv8 используется подход с распараллеливанием процессов, при котором задачи детектирования, классификации и регрессии обрабатываются независимо друг от друга в отдельных ветвях. Такая конструкция позволяет каждой ветви сосредоточиться на решении своей конкретной задачи, что способствует повышению общей точности обнаружения.
Для оценки объектности в выходном слое используется сигмоидальная функция активации, представляющая вероятность нахождения объекта в пределах ограничительного поля.
Еще одной важной особенностью YOLOv8 является способность выполнять многомасштабное обнаружение объектов. Модель использует сеть пирамид признаков для обнаружения объектов различных размеров и масштабов на изображении. Эта сеть пирамид состоит из нескольких слоев, которые обнаруживают объекты разного масштаба, что позволяет модели обнаруживать большие и маленькие объекты на изображении.
Семейство YOLOv8 имеет 5 стандартных обученных моделей. Сравнение этих моделей представлено в таблице 2 [7].
Таблица 2 – Сравнение обученных моделей YOLOv8
|
Model |
Точность по mAP, % |
Скорость обработки, ms |
|
YOLOv8n |
37.3 |
80.4 |
|
YOLOv8s |
44.9 |
128.4 |
|
YOLOv8m |
50.2 |
234.7 |
|
YOLOv8l |
52.9 |
375.2 |
|
YOLOv8x |
53.9 |
479.1 |
Для проверки работоспособности нейросетевой модели была выбрана YOLOv8n, т. к. она хорошо подходит для компьютеров любых мощностей, но при этом обладает неплохой точностью и скоростью. Функциональная схема созданной программной системы представлена на рисунке 7. Эта система позволяет распознавать объекты на статичных изображениях, а также распознавать объекты на веб-камере и в видеопотоке.

Рисунок 7 – Функциональная схема системы распознавания объектов на изображении
Результат обнаружения при помощи YOLOv8 представлен на рисунке 8. На фрагменте из видео нейронная сеть обозначила все найденные объекты и показала процент совпадения. В центре изображения модель нашла две машины, при этом одна из них закрывает другую, модель обозначила их меткой car с процентом совпадений 90% и 54%. Далее в самом конце дороги система показала машину с процентом совпадений 80%.
В правой части рисунка, машину в кустах, - с процентом 79%. Обнаружение четырёх объектов заняло 24 миллисекунды при нагрузке на видеокарту или 0.8 секунд при нагрузке на процессор.

Рисунок 8 – Результат обнаружения с помощью YOLOv8
Эксперименты показали, что среди других достоинств модели YOLOv8 можно также отметить высокую скорость, легкую обработку видео и легкую обучаемость.
Недостатками модели YOLOv8 являются: низкая точность по сравнению с другими моделями, возможны ошибки в работе самой модели.
Таким образом, модель YOLOv8 отлично подходит для всех задач обработки видеоизображений в реальном времени, однако данная модель гораздо хуже справляется со статичными изображениями.
Заключение
Выполнен обзор нейросетевых моделей семейства YOLO и анализ их технических и функциональных характеристик. Подробно рассмотрены архитектурные аспекты моделей YOLOv3 и YOLOv8. Для анализа эффективности этих моделей была создана программная система, на которой проводились эксперименты.
Проведены исследования этих моделей, которые ориентированы на реализацию систем компьютерного зрения, в частности, на примере автоматизации решения задач обнаружения и классификации различных объектов на изображении.
Данная система компьютерного зрения, построенная на этих моделях, позволяет распознавать объекты на любом источнике изображения, например на статичной фотографии или с веб-камеры.
Для обработки статичных изображений лучше использовать модель YOLO третьей версии, а для обработки изображений в реальном времени лучше использовать модель YOLO восьмой версии.
1. Что такое компьютерное зрение и где его применяют [Электронный ресурс]. Режим доступа: https://trends.rbc.ru/trends/industry/5f1f007e9a794756fafbfa83. – Загл. с экрана;
2. Компьютерное зрение OpenCV: где применяется и как работает в Python [Электронный ресурс]. Режим доступа: https://skillbox.ru/media/code/kompyuternoe-zrenie-opencv-gde-primenyaetsya-i-kak-rabotaet-v-python/?ysclid=los873c9yl859014313. – Загл. с экрана;
3. Mihir Durve, Sibilla Orsini, Adriano Tiribocchi. Benchmarking YOLOv5 and YOLOv7 models with DeepSORT for droplet tracking applications [Электронный ресурс]. Режим доступа: https://arxiv.org/pdf/2301.08189.pdf. – Загл. с экрана;
4. Javad Khoramdela, Soheila Hatamib, and Majid Sadedel. Wearing face mask detection using deep learning through COVID-19 pandemic [Электронный ресурс]. Режим доступа: https://arxiv.org/pdf/2301.08189.pdf. – Загл. с экрана;
5. YOLO v8: улучшенное обнаружение объектов (живая камера) с точностью в реальном времени [Электронный ресурс]. Режим доступа: https://skine.ru/articles/727546/. – Загл. с экрана;
6. Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement [Электронный ресурс]. Режим доступа: https://arxiv.org/pdf/1804.02767v1.pdf. – Загл. с экрана;
7. Документация Yolo V8 [Электронный ресурс]. Режим доступа: https://github.com/ultralytics/ultralytics?ref=blog.roboflow.com. – Загл. с экрана;