Источник: Информатика, управляющие системы, математическое и компьютерное моделирование» (ИУСМКМ-2024) : сб. материалов XV Междунар. науч.-техн. конф. в рамках X Междунар. Науч. форума ДНР; Т.2 / Ред. кол.: Аноприенко А. Я. (пред.); Васяева Т. А.; Карабчевский В. В. [и др.]; от. ред. Р. В. Мальчева. – Донецк : ДонНТУ, 2024. – С. 1110-1118.
УДК 004.93
ТРЕКИНГ ДВИЖУЩИХСЯ ОБЪЕКТОВ В РЕАЛЬНОМ ВРЕМЕНИ С ПОМОЩЬЮ НЕЙРОСЕТЕВОЙ МОДЕЛИ YOLOv9
А.Р. Муращенко, О.И. Федяев
ФГБОУ ВО «Донецкий национальный технический университет» (г. Донецк)
кафедра «Программная инженерия им. Л.П.Фельдмана»
e-mail: sasha.mur01@mail.ru, olegfedyayev@yahoo.com
Аннотация:
Муращенко А.Р., Федяев О.И. Трекинг движущихся объектов в реальном времени с помощью нейросетевой модели YOLOv9. В работе рассматривается распознавание и трекинг движущихся объектов с помощью нейросетевой модели YOLOv9. Проанализирована и описана архитектура нейросетевой модели YOLOv9. Показан способ обнаружения движения человека с помощью сегментации на примере видео со студентами в аудитории. Показана функция трекинга объектов на примере видео с движением автомобилей по дороге.
Annotation:
Murashchenko A.R., Fedyaev O.I. Real-time tracking of moving objects using YOLOv9 neural network model. The paper deals with the recognition and tracking of moving objects using the YOLOv9 neural network model. The architecture of the YOLOv9 neural network model is analysed and described. A method of human motion detection using segmentation is shown using video of students in a classroom as an example. The function of object tracking is shown on the example of video with cars moving on the road.
Ключевые слова: нейросеть, распознавание, модель YOLOv9, трекинг объектов в реальном времени, обучение.
Keywords: neural network, recognition, YOLOv9 model, real-time object tracking, training.
Введение
Компьютерное распознавание образов - это процесс выделения полезных данных из общей массы разнородных объектов и их классификация по характерным признакам. Уникальность компьютерного распознавания заключается в использовании алгоритмов и методов искусственного интеллекта для анализа и классификации изображений, текстов и других типов данных. Это позволяет компьютерам автоматически определять и классифицировать объекты, основываясь на их характеристики и признаки.
Эта мощная технология находит широкое применение практически во всех отраслях, включая медицинскую диагностику, автомобильную промышленность, робототехнику, безопасность и видеонаблюдение, интернет вещей, маркетинг и рекламу, промышленность и производство, развлечения и игры [1].
Сегодня существует множество моделей для распознавания объектов, среди которых можно выделить R-CNN, Fast R-CNN, Single Shot Detector, You Only Look Once, RetinaNet. У каждой модели есть свои преимущества и недостатки [2]. Для обнаружения на камере или видеофайле в реальном времени чаще всего используют модель You Only Look Once. Модель YOLO (You Only Look Once) - это архитектура нейронных сетей, предназначенная для детектирования объектов на изображении. Она отличается тем, что использует один проход для просмотра изображения и получения информации о присутствии объектов и их классах на картинке. Это позволяет существенно увеличить скорость обработки по сравнению с другими методами, которые требуют двойного просмотра изображения.
Основная задача данной работы заключается в оценке новой модели свёрточной нейронной сети YOLOv9, анализе её характеристик с целью построения на её основе системы для определения местоположения движущихся объектов во времени с помощью видеокамеры (на примере наблюдения за людьми в аудитории).
Обзор работ по компьютерному зрению на основе модели YOLOv9
Так как модель YOLOv9 появилась совсем недавно, существует мало научных статей о данной модели. Дадим краткую характеристику следующим новым публикациям.
В статье «SOAR: Advancements in Small Body Object Detection for Aerial Imagery Using State Space Models and Programmable Gradients», которая была написана 2 мая 2024 года, автор анализирует обнаружение мелких объектов на аэрофотоснимках с помощью моделей пространства состояний и программируемых градиентов [3]. Однако в данной статье не показывает особенности архитектуры моделей YOLO.
В статье «YOLOv9 for Fracture Detection in Pediatric Wrist Trauma X-ray Images», которая была написана 17 марта 2024 года, автор использует YOLOv9 для обнаружения объектов на медицинских снимках [4]. В данной статье автор не указывает особенности архитектуры, а при сравнении с другими версиями не указывает проблему, которая появилась в этих моделях.
Области применения модели YOLOv9
Модель YOLOv9 является очень эффективной для решения различных задач. Модель гораздо лучше подходит для обнаружения маленьких объектов или на кадрах с помехами. Особенно важно отметить то, что модель можно использовать даже для трекинга движения разных объектов. В частности, данная модель эффективно применялась для решения следующих важных задач:
- прогнозирование движения объектов (если объект двигается с постоянной скоростью, то можно заранее спрогнозировать путь его движения);
- обнаружение дефектов на медицинских снимках (улучшение точности для мелких объектов в новой модели позволит лучше справиться с данной задачей);
- управление автономными транспортными средствами (благодаря трекингу движения можно определить движение других автомобилей для предотвращения опасных ситуаций);
- улучшение функционирования робототехники (эффективное отслеживание объектов в динамике повысит безопасное их перемещение и взаимодействие с окружающей средой);
- контролирование поведения и безопасность (с помощью модели можно сделать систему распознавания некорректного поведения людей, например, студентов в аудитории).
Модель YOLOv9 постоянно и активно развивается. А разработчики своевременно устраняют проблемы, которые возникают в процессе её использования. Далее проведём анализ работы модели YOLOv9.
Описание и анализ модели YOLOv9
Модель YOLOv9 была опубликована 21 февраля 2024 года. Усовершенствования YOLOv9 глубоко укоренились в решении проблем, связанных с потерей информации, присущих глубоким нейронным сетям. Принцип информационного узкого места и инновационное использование обратимых функций занимают центральное место в её структуре, обеспечивая YOLOv9 высокую эффективность и точность [5].
Метод информационного узкого места предназначен для нахождения лучшего компромисса между сложностью и точностью. По мере прохождения данных через слои сети возрастает потеря информации, как показано на формуле 1:
![]() , (1)
, (1)
где I – взаимная информация; F, G – функции преобразования.
YOLOv9 повышает эффективность метода, вводя программируемую градиентную информацию (PGI). PGI может предоставить полную входную информацию о целевой задаче по вычислению целевой функции, так что можно получить надёжную информацию о градиенте для обновления весов сети. Это обеспечивает лучшую сходимость и производительность модели.
В модели YOLOv9 используется новая архитектура – обобщённая эффективная сеть агрегации слоёв (GELAN). Данная архитектура была получена путём объединения двух архитектур CSPNet и ELAN, которые разработаны на основе градиентного планирования пути. ELAN использовал только сложение вычислительных блоков, а CSPNet работал только с одним блоком.
GELAN позволяет быть модели более адаптируемой без ущерба к точности и скорости. Структура GELAN показана на рисунке 1.
Благодаря этому точность для небольших моделей и наборов данных возросла, по сравнению с YOLOv8, а количество параметров заметно сократилось.
Также модель использует функцию активации SiLU – сигмоидальную линейную единицу. Функция активации SiLU работает лучше, чем ReLU или ELU, но хуже чем функция активации GELU[6].
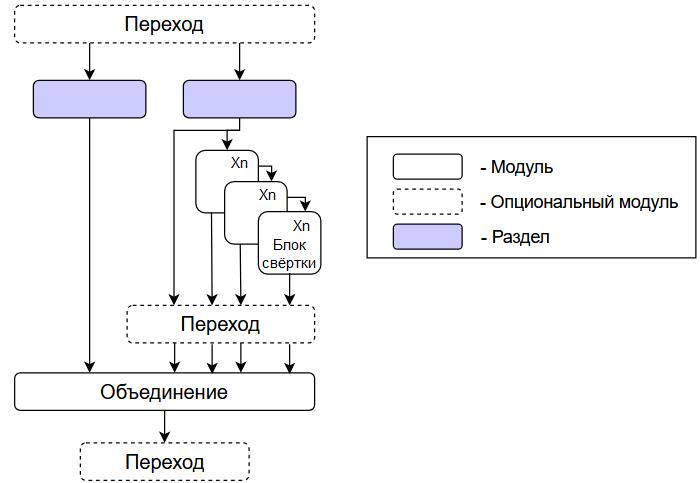
Рисунок 1 – Структура GELAN
На данный момент в источниках не описана архитектура YOLOv9.
Однако, есть возможно составить список и характеристику компонентов архитектуры YOLOv9:
- Convolution block. Блок свёртки. Состоит из слоя нормализации и функции активации. Параметрами являются значение ядра, количество шагов, значение заполнения.
- RepConvN block. Данные проходят через два свёрточных блока, объединяются и проходят через функцию активации SiLU.
- RepNBottleneck block представляет собой последовательность блоков RepConvN и Conv с коротким путём. Сравнение блока с аналогичным из YOLOv8 представлено на рисунке 2. Разница в том, что у прошлой версии три свёрточных блока и используется функция активации ReLU.
- RepNCSP block. Данные проходят через два свёрточных блока, в одном пути проходят по нужному количеству RepNBottleneck блоков. Затем данные из двух путей объединяются и проходят через третий свёрточный блок.
- RepNCSPELAN4. Блок, который содержит обобщённую эффективную сеть агрегации слоёв(GELAN).
- Adown block. Блок, который выполняет операцию понижения выборки или уменьшения разрешения на карте объектов. В данном блоке данные будут обработаны с помощью двухмерного пулинга и разделены на две части. Первая часть пойдёт в первый свёрточный блок, а вторая пойдёт в максимальный слой пулинга, за которым находится ещё один свёрточный блок. После этого две части объединяются.
- SPPELAN. Этот блок является модификацией пулинга пирамидой. Основная функция генерирует фиксированное представление объектов различных объектов в изображении разного размера. Разница с аналогичным блоков из YOLOv8 представлена на рисунке 3. Разница заключается в значении ядра и заполнения в блоке свёртки.
- Backbone. Архитектура глубокого обучения, которая работает как экстрактор признаков.
- Neck объединяет различные признаки, полученные из различных слоёв.
- Auxiliary повышает надёжность процессов обучения, предоставляя дополнительную информацию, которая связывает входные данные с конкретными выходными.
- Head прогнозирует классы и области ограничивающих рамок, что является конечным результатом.
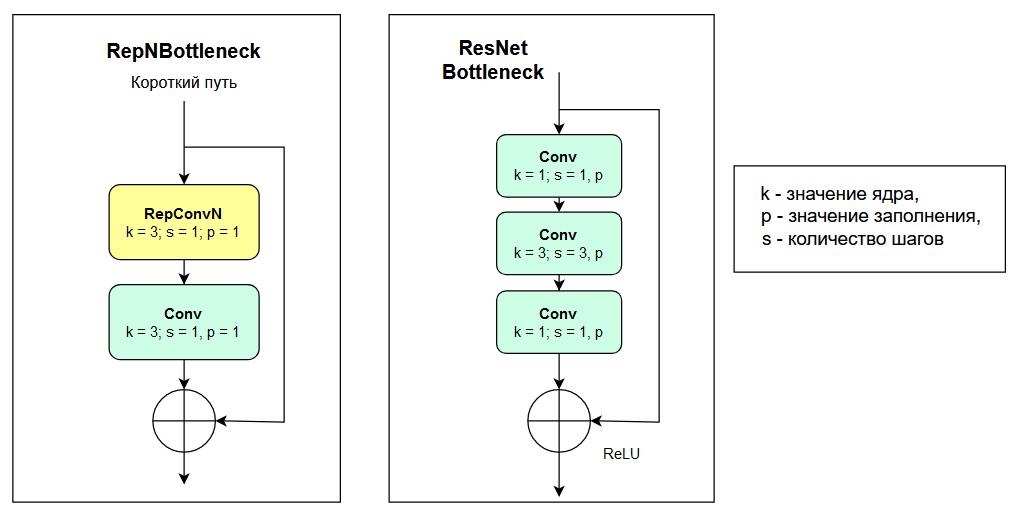
Рисунок 2 – Сравнение модуля Bottleneck между YOLOv9 и YOLOv8
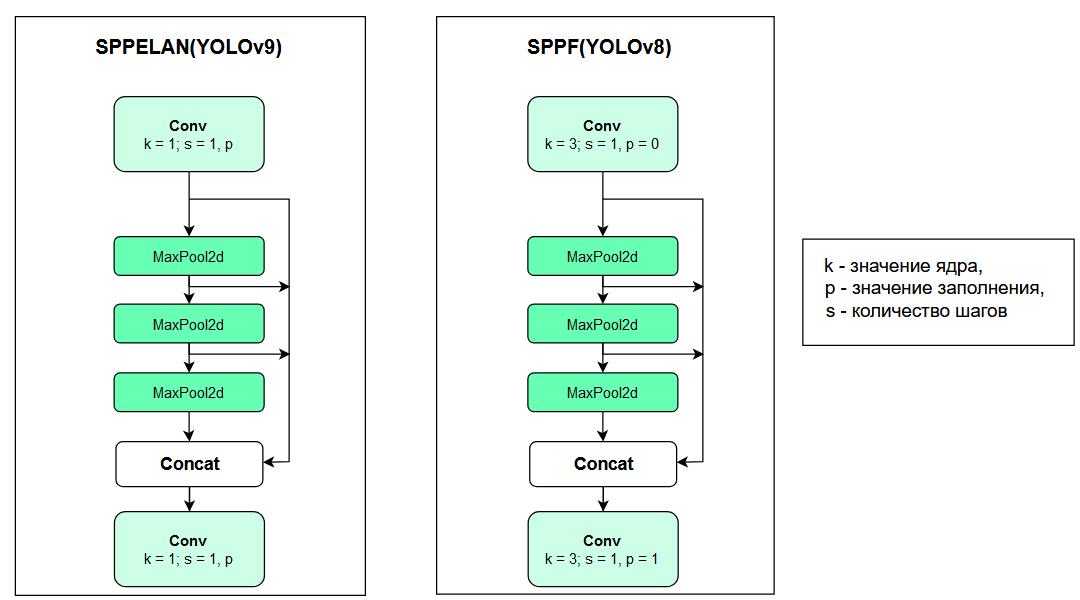
Рисунок 3 – Сравнение модуля SPP между YOLOv9 и YOLOv8
Новая архитектура глубокой нейронной сети GELAN заметно отличается от других архитектур. Сравнение работы архитектур PlainNet, ResNet, CSPNet, GELAN представлено на рисунке 4 [7]. Можно заметить, что при небольшом количестве слоёв GELAN работает гораздо эффективнее.

Рисунок 4 – Сравнение архитектур PlainNet, ResNet, CSPNet, GELAN
Анализ показателей качества модели YOLOv9
Сравнение показателей обнаружения объектов моделями YOLOv8 и YOLOv9 показаны в таблице 1. В таблице 2 показаны показатели сегментации моделей YOLOv8 и YOLOv9 [5,8].
Таблица 1 – Сравнение показателей обнаружения моделей YOLOv8 и YOLOv9
|
Модель |
Размер пикселей |
mAPval 50-95 |
params (M) |
FLOPs (B) |
|
YOLOv8s |
640 |
44.9 |
11.2 |
28.6 |
|
YOLOv8l |
640 |
52.9 |
43.7 |
165.2 |
|
YOLOv8x |
640 |
53.9 |
68.2 |
257.8 |
|
YOLOv9s |
640 |
46.8 |
7.2 |
26.7 |
|
YOLOv9c |
640 |
53 |
25.5 |
102.8 |
|
YOLOv9e |
640 |
55.6 |
58.1 |
192.5 |
Если сравнивать с другими моделями, модель YOLOv9 показывает улучшения не только в точности обнаружения (mAPval), но и в эффективности вычислительных потребностей (FLOPs). При меньшем количестве параметров модель YOLOv9 справляется с задачей лучше, чем YOLOv8. Также YOLOv9 гораздо лучше справляется при низких вычислительных нагрузках, чем предыдущие версии или аналоги.
Таблица 2 – Сравнение показателей сегментации моделей YOLOv8 и YOLOv9
|
Model |
Размер пикселей |
mAPval |
params |
FLOPs |
|
YOLOv8l-seg |
640 |
52.3 |
46.0 |
220.5 |
|
YOLOv8x-seg |
640 |
53.4 |
71.8 |
344.1 |
|
YOLOv9c-seg |
640 |
52.4 |
27.9 |
159.4 |
|
YOLOv9e-seg |
640 |
55.1 |
60.5 |
248.4 |
При сравнении моделей с сегментацией видно повышение эффективности в 1.3 раза, а количество используемых параметров меньше в 1.7 раза. При сравнении более натренированных моделей разница растёт многократно.
Для тестирования была создана тестовая программа для сегментации и распознавания объектов с помощью YOLOv9. Функциональная схема программы показана на рисунке 5. Модель обучена на стандартном датасете COCO, который имеет 80 классов [9].
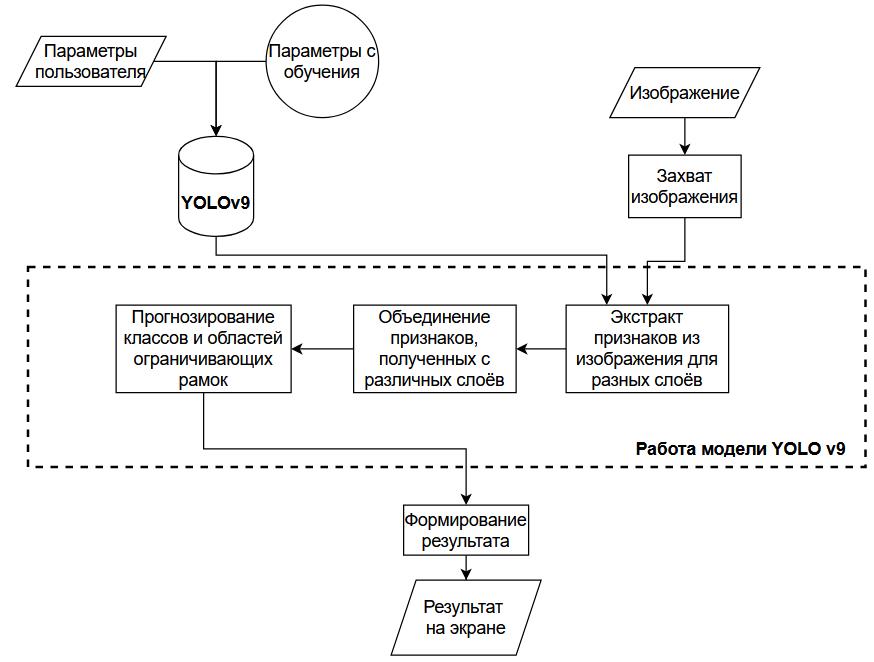
Рисунок 5 – Функциональная схема системы распознавания объектов на изображении
Тестирование проводилось на следующей технической конфигурации:
- процессор: intel i3-1005G1(8 потоков, 2 ядра);
- видеокарта: nVidia GeForce MX330(2 гб графической памяти);
- оперативная память: 8 ГБ;
- размер изображения: 967 х 386 пикселей.
Результаты распознавания и сегментации представлен на рисунке 6 и на рисунке 7. Распознавание заняло 70 миллисекунд с помощью видеокарты. Были обнаружены все 9 студентов, а также 6 свободных мест спереди камеры.
При сравнении сегментаций двух кадров можно посчитать, что количество пикселей у заднего студента на втором кадре сильно отличается от количества пикселей на первом кадре. Поэтому следует вывод, что студент вёл себя активнее, чем обычно. Это можно использовать для выявления необычного поведения студентов.
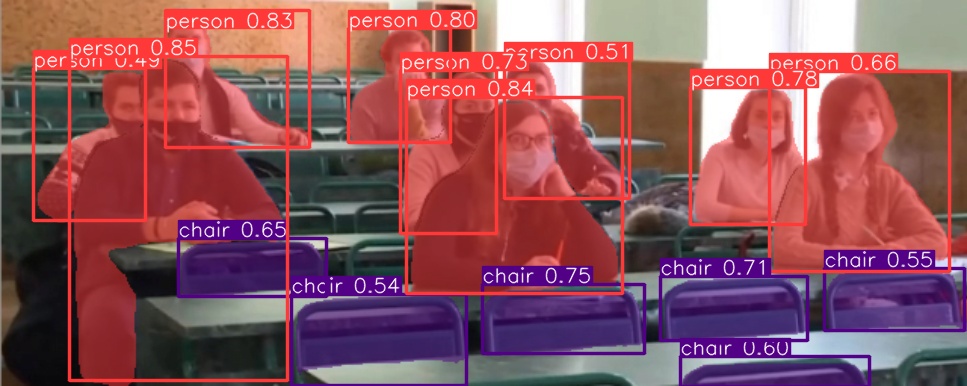
Рисунок 6 – Первый кадр распознавания студентов в аудитории
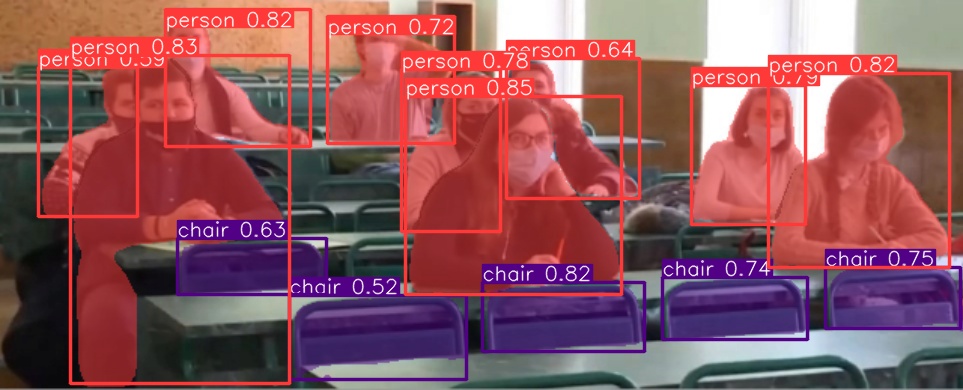
Рисунок 7 – Второй кадр распознавания студентов в аудитории
Также можно добавить функцию трекинга для запоминания объектов на кадре. Результат данной функции представлен на рисунках 8 и 9. Модель запоминает каждый объект класса отдельно и может определить его местоположение на двух разных кадрах. При желании можно нарисовать линию (траекторию), по которой двигался объект.

Рисунок 8 – Первый кадр движения автомобилей с трекингом

Рисунок 9 – Второй кадр движения автомобилей с трекингом
По результату видно, что модель запомнила объекты конкретного класса и поставила им номер на первом кадре видеопотока. Затем на втором кадре видеопотока модель показала все объекты, которые она запомнила.
Достоинства новой версии модели YOLOv9:
- низкая нагрузка на систему;
- повышенная точность обнаружения относительно прошлых версий;
- повышенная эффективность обучения;
- возможность трекинга объектов.
Недостатки модели YOLOv9:
- сниженная скорость обучения;
- низкая точность относительно других моделей статичного обнаружения
- сложность подключения.
Можно сделать вывод, что модель стала сильно лучше в плане количества параметров и нагрузки на систему, при этом, не потеряв в точности обнаружения. Данная модель подняла планку стандарта для будущих моделей нейронной сети для обнаружения объектов в реальном времени.
Заключение
В данной работе был выполнен анализ нейросетевой модели семейства YOLO, а именно YOLOv9. Для неё определены технические и функциональные характеристики, позволяющие сравнить её показатели с предшествующими моделями этого класса. Подробно рассмотрены архитектурные аспекты модели YOLOv9.
Для получения характеристик модели YOLOv9 и проведения тестирования была создана программная оболочка, позволяющая обнаруживать, классифицировать и сегментировать объекты. Система обнаружения, построенная на YOLOv9, позволяет распознавать объекты на любом источнике изображения, как на камере, так и на видеофайле. Исследование проводилось на видео со студентами в аудитории и на движении машин по трассе.
Модель лучше показывает себя в плане точности обнаружения и обучения, особенно при маленьких размерах объектов, а также имеет более низкую нагрузку на систему, в сравнении с предыдущими версиями. Однако процесс обучения модели занимает больше времени. Скорость обнаружения осталась такой же.
1. Методы распознавания образов: от простых до сложных [Электронный ресурс]. Режим доступа: https://www.simbirsoft.com/blog/metody-raspoznavaniya-obrazov-ot-prostykh-do-slozhnykh/?ysclid=lwb0mwsytm19505859. – Загл. с экрана.
2. The Ultimate Guide to Object Detection [Электронный ресурс]. Режим доступа: https://www.v7labs.com/blog/object-detection-guide. – Загл. с экрана.
3. SOAR: Advancements in Small Body Object Detection for Aerial Imagery Using State Space Models and Programmable Gradients [Электронный ресурс]. Режим доступа: https://arxiv.org/pdf/2405.01699. – Загл. с экрана.
4. YOLOv9 for Fracture Detection in Pediatric Wrist Trauma X-ray Images [Электронный ресурс]. Режим доступа: https://arxiv.org/pdf/2403.11249. – Загл. с экрана.
5. Документация Yolo V9 [Электронный ресурс]. Режим доступа: https://docs.ultralytics.com/ru/models/yolov9/#performance-on-ms-coco-dataset. – Загл. с экрана.
6. GAUSSIAN ERROR LINEAR UNITS (GELUS) [Электронный ресурс]. Режим доступа: https://arxiv.org/pdf/1606.08415. – Загл. с экрана.
7. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information [Электронный ресурс]. Режим доступа: https://arxiv.org/pdf/2402.13616. – Загл. с экрана.
8. Документация Yolo V8 [Электронный ресурс]. Режим доступа: https://github.com/ultralytics/ultralytics?ref=blog.roboflow.com. – Загл. с экрана.
9. COCO - Common Objects in Context [Электронный ресурс]. Режим доступа: https://cocodataset.org/#home. – Загл. с экрана.