
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цели и задачи исследования
- 3. Современная система рекомендации
- 4. Применение методов рекомендательных систем
- 4.1 Применение методов коллаборативной фильтрации
- 4.2 Применение методов контентной фильтрации
- 4.3 Применение гибридных методов
- 5. Прототип контентная фильтрация в рекомендательной системе
- 5.1 Разработка моделей для контентной фильтрации
- 5.2 Результаты тестирования построенных моделей
- 5.3 Анализ результатов моделирования
- Выводы
- Список источников
Введение
В современном информационном обществе обмен идеями и вдохновением играет ключевую роль в развитии как отдельных индивидов, так и целых сообществ. С ростом популярности онлайн-платформ и социальных сетей появляется всё больше возможностей для взаимодействия пользователей, обмена знаниями и совместного творчества. Однако вместе с увеличением объёма информации возрастает и необходимость эффективных инструментов её организации и персонализации, чтобы обеспечить пользователям доступ к наиболее релевантному и вдохновляющему контенту.
В свете вышеизложенного актуальность разработки веб-ориентированных информационных систем, предназначенных для общественного обмена идеями и вдохновением, становится очевидной. Такие системы не только способствуют распространению инновационных мыслей и творческих концепций, но и стимулируют коллективное решение проблем, поддерживают креативность и способствуют развитию сетевого сообщества.
Особое значение в данной работе уделяется внедрению рекомендательных систем в структуру информационной платформы. Рекомендательные системы, основанные на современных алгоритмах машинного обучения и анализа данных, способны анализировать предпочтения пользователей, предсказывать их интересы и предлагать наиболее подходящий контент. Это не только улучшает пользовательский опыт, но и повышает вовлечённость аудитории, способствуя более активному участию в обмене идеями и вдохновением.
Целью данной магистерской работы является разработка веб-ориентированной информационной системы для общественной платформы обмена идеями и вдохновением с интегрированными рекомендательным механизмом.
1. Актуальность темы
В условиях стремительного развития информационных технологий и цифровой трансформации общества, веб-ориентированные платформы приобретают всё большую значимость как инструменты для обмена идеями и вдохновением. Такие платформы способствуют формированию и развитию онлайн-сообществ, где пользователи могут взаимодействовать, делиться знаниями и генерировать инновационные решения. В современных реалиях, характеризующихся глобализацией и быстрыми изменениями в различных сферах деятельности, способность эффективно обмениваться идеями становится ключевым фактором конкурентоспособности как отдельных индивидов, так и организаций.
Одной из основных проблем существующих платформ для обмена идеями является избыточность информации, что приводит к затруднениям в поиске релевантного контента и снижению эффективности взаимодействия между пользователями [1]. Пользователи сталкиваются с необходимостью фильтрации большого объёма данных, что требует значительных временных и когнитивных ресурсов. В таких условиях персонализация контента становится неотъемлемой частью успешной платформы, способной удовлетворять индивидуальные потребности и предпочтения пользователей.
Интеграция рекомендательной системы в веб-ориентированную информационную систему предоставляет эффективное решение данной проблемы [2]. Рекомендательные алгоритмы позволяют анализировать поведенческие данные пользователей, выявлять их интересы и предпочтения, а также предлагать наиболее релевантный контент. Это не только упрощает процесс поиска идей, но и повышает уровень вовлечённости пользователей, стимулируя их активное участие в жизни платформы.
2. Цели и задачи исследования
Цели исследований изучить роль веб-ориентированных платформ в обмене идеями и их значимость для развития онлайн-сообществ в условиях цифровой трансформации общества. Оценить проблемы, связанные с избыточностью информации на платформах для обмена идеями, и их влияние на эффективность взаимодействия пользователей. Разработать концепцию интеграции рекомендательной системы в веб-ориентированную платформу для повышения персонализации контента и улучшения взаимодействия пользователей. Исследовать возможности применения рекомендательных алгоритмов для повышения вовлеченности пользователей и улучшения качества обмена идеями на платформах. Создание прототипа рекомендательной системы, которая обеспечит персонализацию контента.
Задачи исследования:
- Проанализировать существующие веб-ориентированные платформы для обмена идеями, выявить их сильные и слабые стороны в контексте взаимодействия пользователей и персонализации контента.
- Изучить теоретические подходы и методологии, используемые в рекомендательных системах, а также их влияние на восприятие и поведение пользователей.
- Оценить проблемы избыточности информации на веб-платформах и исследовать возможные решения, в том числе с помощью рекомендательных алгоритмов.
- Разработать модели и методы персонализации контента на основе данных пользователей и предложить оптимальные пути их интеграции в веб-ориентированные платформы.
3. Современная система рекомендации
Современные системы рекомендаций играют ключевую роль в веб-ориентированных платформах, особенно когда речь идет об обмене идеями и контентом. С развитием информационных технологий и увеличением объемов доступной информации, системы рекомендаций помогают пользователям эффективно искать релевантный контент, уменьшая информационный перегруз и повышая вовлеченность. Рекомендательные системы используют различные алгоритмы, направленные на анализ поведения пользователей, их предпочтений и интересов, что позволяет предоставить наиболее подходящий контент и улучшить пользовательский опыт [3].
4. Применение методов рекомендательных систем
4.1 Применение методов коллаборативной фильтрации
Коллаборативная фильтрация — это один из самых распространенных методов создания персонализированных рекомендаций, который основывается на анализе взаимодействия пользователей с контентом. Существует два типа коллаборативной фильтрации: пользовательская и объектная.
Пользовательская коллаборативная фильтрация (User-based Collaborative Filtering) предполагает, что если два пользователя имеют схожие предпочтения по отношению к некоторому набору объектов, то они с высокой вероятностью будут оценивать схожим образом и другие объекты. Математически это выражается следующим образом:
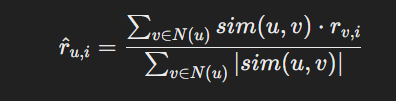
Рисунок 1 – Пользовательская коллаборативная фильтрация
Где r(u,i)— предсказанная оценка пользователя u для объекта i, N(u) - множество пользователей, схожих с пользователем u, sim(u,v) — мера сходства между пользователями u и v, r(v,i) - реальная оценка пользователя v для объекта i.
Коллаборативная фильтрация эффективна, но она сталкивается с проблемой "холодного старта", когда для новых пользователей или новых объектов контента нет достаточной информации для создания рекомендаций. Для решения этой проблемы могут применяться другие методы или гибридные подходы.
4.2 Применение методов контентной фильтрации
Контентная фильтрация основывается на характеристиках объектов контента, таких как ключевые слова, метки, категории и другие признаки. Она анализирует, какие характеристики контента пользователю интересны, и на основе этого предсказывает, какие объекты могут быть ему интересны. Для расчета сходства между объектами используется метрика косинусного сходства:
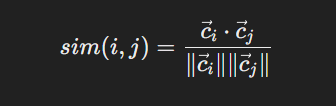
Рисунок 2 – Метрика косинусного сходства
Где Ci и Cj - векторы признаков объектов i и j, ||Ci|| и ||Cj|| - нормы (длины) этих векторов.
Рекомендация для пользователя делается на основе сходства характеристик объектов, которые он уже оценил или взаимодействовал с ними. Если пользователь положительно оценил объект i, то рекомендуется объект j, схожий с i.
4.3 Применение гибридных методов
Гибридные методы объединяют различные подходы (коллаборативную и контентную фильтрацию), чтобы улучшить качество рекомендаций и преодолеть ограничения каждого из методов. Например, можно комбинировать результаты двух методов, взвешивая их:
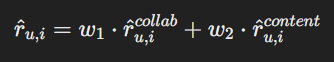
Рисунок 3 – Объединение коллаборативной и контентной фильтрации
Где w1 и w2 - веса, определяющие значимость каждого метода.
Гибридный подход позволяет минимизировать проблемы, такие как холодный старт, и повысить точность рекомендаций.
5. Прототип контентная фильтрация в рекомендательной системе
Контентная фильтрация (Content-Based Filtering) основывается на характеристиках самих элементов. Например, если пользователь часто смотрит фильмы определенного жанра или с определенными актерами, система будет рекомендовать ему похожие фильмы. Этот метод требует анализа и обработки данных о самих элементах, таких как жанры, актеры, режиссеры и т.д. Контентная фильтрация предполагает, что пользователи будут заинтересованы в элементах, схожих с теми, которые они уже оценили положительно. Она анализирует свойства объектов, такие как текстовые описания, метаданные и ключевые слова, чтобы выявить схожие элементы. Это позволяет системе рекомендовать пользователю материалы, аналогичные тем, которые он уже оценил положительно [4].
Основной задачей контентной фильтрации заключается в нахождении похожих элементов на основе анализа их содержимого.
Для реализации данной задачи были выбраны следующие инструменты:
Torch выбран в качестве основной библиотеки для разработки и обучения нейронных сетей.
Библиотека Transformers мощный инструмент с открытым исходным кодом, разработанный компанией Hugging Face, который предоставляет удобный интерфейс для работы с моделями трансформеров.
Torchvision библиотека, разработанная в рамках экосистемы PyTorch, обеспечивающая поддержку для работы с изображениями и компьютерным зрением. Она предлагает множество инструментов, включая наборы данных, предобученные модели.
PIL (Python Imaging Library) одна из самых известных и широко используемых библиотек для обработки изображений на языке Python.
Matplotlib — это одна из наиболее популярных библиотек для создания статической, анимационной и интерактивной визуализации данных в Python.
5.1 Разработка моделей для контентной фильтрации
Первым этапом была выполнена предварительная обработка данных – это процесс анализа данных, который включает преобразование необработанной информации в удобный для анализа формат и дальнейшего использования [5]. После предварительной обработки данных выполняется векторизация текстов, так как алгоритмы машинного обучения предназначены для работы с числовыми данными, и необходимо выполнить преобразование текста в числовой вектор признаков [6].
Для извлечения текстовых признаков из заголовков и описаний была использована предобученная модель BERT [7]:
(1)
где text — это исходный текст, Tokens — это список токенов, представленных в виде числовых идентификаторов.
После процесса токенизации токены поступали в модель BERT, которая преобразовала их в эмбеддинги:
(2)
где BERT(Tokens) — это выход модели BERT для заданных токенов, а [0] — это выбор эмбеддинга[CLS], который находится на первой позиции в выходном векторе.
После получения эмбеддингов, заголовки и их описания были объединены для формирования единого вектора признаков:(3)
где dn-вектор заголовка, dd-вектор описание.
Объединение выполняется конкатенацией:
(4)
где Embeddingtitle и Embendingdescriptions - эмбеддинги заголовка и описания, [;] обозначает операцию конкатенации векторов.
Для извлечения визуальных признаков использована предобученная модель ResNet-50 [8]. Для создания единого представления элемента, текстовые и визуальные признаки объединяются:
(5)
где dtext - текстовые признаки, dimage - визуальные признаки.
Объединение признаков текста и изображения происходит с помощью операции конкатенации:
(6)
где dim=1 указывает на то, что конкатенация выполняется по размерности признаков [9].
Для обучения модели на основе сходства были созданы пары элементов. Положительные пары сформированы из элементов, которые идентичны, то есть представляют собой один и тот же объект. Эти пары помечаются меткой 1. В данной работе выбран подход формирования пар на основе uid пользователя:
(7)
где UID(x)— уникальный идентификатор элемента x.
Отрицательные пары сформированы из элементов, которые различны, и помечаются меткой 0. Формирование отрицательных пар сделана случайным:
(8)
где UID(x)— рандомный уникальный идентификатор элемента x.
Процент положительных и отрицательных пар контролируется параметром positive_ratio:
(9)
где N – это общее количество пар.
Недостатком формирование случайным образом отрицательных пар является то, что многие из них будут слишком легко различимы моделью, что не способствует эффективному обучению.
Для предсказания схожести между парой признаков применена нейронная сеть, которая состоит из нескольких слоев, обеспечивающих обработку и анализ входных данных. Архитектура модели описывается следующими компонентами:
Входной слой принимает объединенные признаки двух элементов, что приводит к следующему количеству измерений:
(10)
где input_dim = 3584 - это количество признаков, извлеченных из одного элемента, total_input_dim = 2 * input_dim = 7168 - пара элементов, общее количество входных измерений увеличивается в два раза.
Модель включает в себя несколько скрытых слоев, которые выполняют функции обработки и обучения.
Первый полносвязный слой содержал 512 нейронов и для него функция активации ReLU (Rectified Linear Unit) определяется как:
(11)
Dropout слой применялся с вероятностью p=0.3 для предотвращения переобучения, что означает, что 30% нейронов будут случайным образом отключены во время тренировочного этапа.
Второй полносвязный слой имел 128 нейронов и такую же функцию активации ReLU, как и первый. Второй Dropout слой также применялся с вероятностью p=0.3.
Выходной слой состоял из одного нейрона, который использовал функцию активации Sigmoid для предсказания вероятности схожести между элементами. Функция Sigmoid определяется как:
(12)
Таким образом, выходной слой предсказывал вероятность схожести p в диапазоне от 0 до 1:
(13)
где W — это вес выходного слоя, h — выход предыдущего слоя, b — смещение.
Для задач бинарной классификации [10], где необходимо было предсказать, является ли пара элементов схожими (1) или не схожими (0), применялась функция потерь бинарной кросс-энтропии. Она измеряет расхождение между истинными метками y и предсказанными вероятностями p. Формально, функция потерь BCE определяется следующим образом:
(14)
где N— общее количество образцов в батче, yi — истинная метка (0 или 1) для i-го образца, p_i — предсказанная вероятность схожести для i-го образца.
5.2 Результаты тестирования построенных моделей
В ходе обучения модели было проведено 5 эпох. На рисунке 1 представлена динамика изменения значения функции потерь (Loss) во время обучения модели. Наблюдается устойчивое снижение значения Loss с 0.6244 на первой эпохе до 0.3934 на пятой эпохе.
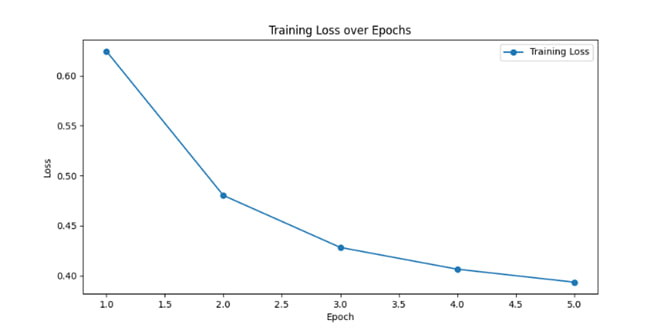
Рисунок 4 – График функции потерь на тренировке
На рисунке 2 отображены изменения метрик Precision (точность), Recall (полнота) и F1-Score модели на валидационной выборке в течение пяти эпох обучения.
Динамика метрик указывает на первоначальное повышение точности модели с последующим балансированием точности и полноты. Увеличение Recall и F1-Score свидетельствует о том, что модель становится способной выявлять все большее количество релевантных примеров, сохраняя при этом приемлемый уровень точности.
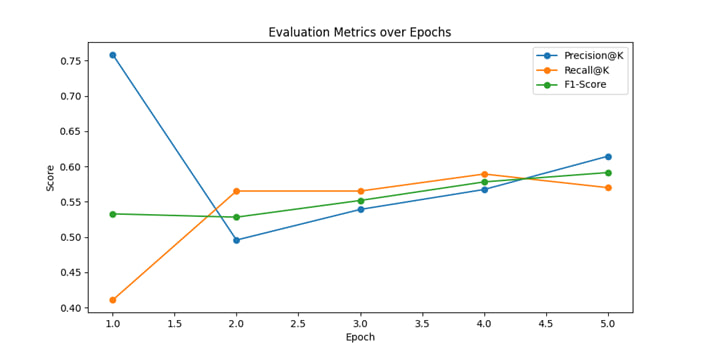
Рисунок 5 – Графики оценочных метрик при валидации
5.3 Анализ результатов моделирования
Показатели метрик качества для пяти эпох составили от 55% до 60%, что является средним результатом.
В дальнейших исследованиях, в первую очередь, следует увеличить количество эпох для достижения более приемлемого результата.
Для улучшения показателей качества построенной модели при генерации отрицательных пар для обучения следует использовать Hard Negative Mining вместо случайного формирования негативных пар.
Этот метод сосредоточен на отборе отрицательных пар, которые модель может легко классифицировать как положительные, что позволит улучшить её способность различать схожие, но разные элементы. Для этого будут использоваться такие метрики, такие как косинусное сходство и евклидово расстояние.
Необходимо выбрать негативные пары с высокими значениями сходства. Эти пары будут считаться «жесткими негативами» и представляют собой примеры, которые модель может легко перепутать с положительными. Отрицательная пара (xi,xj) считаются жестким негативом, если:
(15)
где f(xi,xj)— это функция сходства, а threshold— заранее установленный порог.
Выводы
Полученные результаты прототипной модели демонстрируют эффективное обучение модели, подтверждённое стабильным снижением функции потерь на тренировочных данных. Несмотря на первоначальное снижение метрики Precision, последующее восстановление и общий рост метрик Recall и F1-Score свидетельствуют о достижении баланса между точностью и полнотой предсказаний. Но для более приемлемого результата в дальнейшем стоит увеличить эпох, так же для улучшения показателей качества построенной модели при генерации отрицательных пар для обучения будет использоваться метод Hard Negative Mining.