Аннотация
Мы представляем снимок процесса обучения с 15 миллиардами параметров сети глубокого обучения на архитектурах HPC, применяемой к крупнейшему общедоступному набору данных естественных изображений и видео, выпущенному на сегодняшний день. Последние достижения в области неконтролируемых глубоких нейронных сетей предполагают, что масштабирование таких сетей как по размеру модельных, так и обучающих наборов данных может дать значительные улучшения в обучении концепций на самых высоких уровнях. Мы обучаем нашу трехслойную глубокую нейронную сеть на наборе данных Yahoo! Flickr Creative Commons 100M. Набор данных содержит приблизительно 99,2 миллиона изображений и 800 000 созданных пользователями видеороликов с платформы обмена изображениями и видео Flickr Yahoo. Обучение нашей сети занимает восемь дней на 98 узлах GPU в Центре высокопроизводительных вычислений в Ливерморской национальной лаборатории им. Лоуренса. Представлены и обсуждены обнадеживающие предварительные результаты и направления будущих исследований.
Введение
Область глубокого обучения с использованием стековых нейронных сетей возобновила интерес в последнее десятилетие [1,2,3]. Нейронные сети показано, что они хорошо справляются с широким спектром задач, включая анализ текста [4], распознавание речи [5,6,7], различные задачи классификации [8,9] и, в частности, неконтролируемое и контролируемое обучение признакам на естественных изображениях [1,2,3].
Глубокие нейронные сети, применяемые к естественным изображениям, продемонстрировали передовую производительность в контролируемых задачах распознавания объектов [10], а также неконтролируемых нейронных сетях [2,3].
Классический подход к обучению нейронных сетей для компьютерного зрения использует большой набор размеченных данных. Однако достаточно большие и точно размеченные данные сложно и дорого получить. Мотивированные этим, [3] исследовали применение глубоких нейронных сетей в неконтролируемом глубоком обучении и обнаружили, что достаточно большие глубокие сети способны изучать очень сложные признаки уровня концепций на верхнем уровне без меток.
Вдохновленные этим достижением, [2] приступили к построению очень больших сетей с параметрами порядка 109 – 1010. Ключевым достижением стала высокоэффективная архитектура с несколькими графическими процессорами их модели. [2] использовали высокую степень параллелизма модели и смогли обработать 10 миллионов миниатюр YouTube за несколько дней обработки на кластере среднего размера. Заметным результатом стало неконтролируемое обучение различных лиц, включая лица людей и кошек.
В конечном счете, улучшенное обучение признаков в больших масштабах может улучшить нижние возможности, такие как классификация сцен или объектов, дополнительное неконтролируемое обучение (т. е. с помощью тематического моделирования [11] или алгоритмов обработки естественного языка [12]). В сотрудничестве с авторами [2] мы масштабировали аналогичную модель и архитектуру до более чем 15 миллиардов параметров на системе Edge High Performance Computing (HPC) Lawrence Livermore National Laboratory (LLNL). Наша долгосрочная цель двухсторонняя: (1) исследовать предельную производительность массивных сетей (> 10 миллиардов параметров) и (2) обучать и анализировать наборы данных порядка 100 миллионов изображений.
По мере роста числа сетевых параметров наборы данных необходимо масштабировать соответствующим образом, чтобы избежать переобучения моделей. Мы используем совершенно новый набор данных, выпущенный совместно Yahoo!, LLNL и Международным институтом компьютерных наук (ICSI), который называется Yahoo! Flickr Creative Commons 100M (YFCC100M) dataset10.Насколько известно авторам, этот набор данных является крупнейшим отдельно взятым общедоступным набором данных изображений и видео, когда-либо опубликованным. В дополнение к необработанным изображениям и видео, YFCC100M также содержит метаданные для каждой записи, включая местоположения, типы камер, ключевые слова, заголовки и т. д. Хотя это выходит за рамки данной статьи, эти богатые связанные метаданные потенциально предлагают исследователям дополнительные возможности семантического мультимодальности обучения для изучения.
Работа с крупномасштабными наборами данных, моделями и вычислительными архитектурами, рассматриваемыми в данной статье, представляет собой несколько сложных инженерных задач. Например, значительно большее количество графических процессоров и вычислительных узлов, используемых в нашей системе по сравнению с [2], создает проблемы со связью в MPI. Кроме того, типичная модель занимает более 40 ГБ памяти, что делает простые задачи автономного анализа, такие как визуализация, сложными. Были протестированы различные сетевые архитектуры, балансирующие производительность и вычислительные ограничения, прежде чем мы пришли к нашей текущей модели. Наконец, как и в [2], пропускная способность данных является узким местом для обучения модели. Мы представляем новый подход к конвейеру для решения этой проблемы.
Остальная часть данной статьи организована следующим образом. В разделе ниже мы даем краткий обзор набора данных YFCC100M.
Обзор набора данных YFCC100M
В конце июня 2014 года Yahoo! выпустила набор данных Yahoo! Flickr Creative Commons (YFCC100M). Этот набор данных состоит из 100 миллионов изображений и видео, загруженных пользователями Flickr (99 206 564 изображений и 793 436 видео), а также соответствующих метаданных, включая название, описание, тип камеры, теги и геотеги, если они доступны. Все данные находятся под лицензией Creative Commons и бесплатно предоставляются *ученым для продвижения мультимедийных исследований 1. В дополнение к необработанным изображениям, видео и метаданным Yahoo! в сотрудничестве с ICSI и LLNL будет вычислять и предоставлять стандартные функции компьютерного зрения и звука, используя суперкомпьютерные ресурсы LLNL.
Ванг и др. [13]использовали данные YFCC100M для создания систем, которые связывают изображения с более естественными аннотациями, такими как те, которые встречаются в пользовательских подписях. Другие заинтересованы в использовании изображений и аудио YFCC100M для геолокации места, где была сделана фотография или видео [14]. Фактически, MediaEval Placing Task 2014 года использует YFCC100M в качестве источника контрольных данных [15].
Мы заинтересованы в использовании YFCC100M в качестве нашего набора данных для изучения характеристик изображений с использованием массивных неконтролируемых нейронных сетей, повторяя эксперимент [3] на порядке большего количества данных и параметров нейронной сети. В частности, мы хотим увидеть, какие другие «бабушкины нейроны» [3] наша сеть будет автоматически изучать из YFCC100M.
99 206 564 изображений были созданы и опубликованы 578 268 различными пользователями Flickr. 76%, 20% и 4% изображений имеют заголовки, автозаголовки или не имеют заголовков соответственно. Среднее количество слов в заголовке составляет 3,08. 32% изображений имеют описания, в среднем 22,52 слова в описании. Наконец, 69% изображений имеют в среднем 7,07 тегов на изображение.
Анализ с помощью масштабных нейронных сетей
Архитектура сети
Для большого набора данных изображений мы использовали трехслойную крупномасштабную глубокую нейронную сеть с функцией стоимости анализа независимых компонентов реконструкции (RICA),
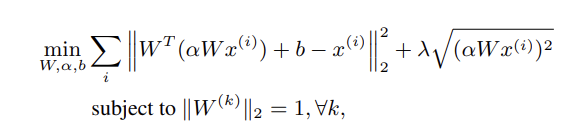
Рисунок 1 – функция стоимости анализа независимых компонентов реконструкции (RICA)
где, как и в [2], W - весовая матрица, ? - масштабное значение, а x(i) - точки данных в начале каждого слоя. Кроме того, мы вводим смещение, b, для повышения гибкости модели. Параметр ? контролирует относительную разреженность и устанавливается равным 0,1 на первых двух слоях и 0,01 на последнем слое. В отличие от [2], мы в настоящее время не включаем слой объединения, поскольку считаем, что масштаб сети и обучающих данных позволяет автоматически изучить аналогичную трансляционную инвариантность.
Особое преимущество, предоставляемое конструкцией RICA, заключается в том, что член разреженности ? p(?W x(i))2 может быть вычислен на месте с остальными параметрами модели. Это отличается от обычного разреженная конструкция автокодировщика, которая требует второго прохода по данным для вычисления градиентного вклада, специфичного для разреженности. Три слоя состоят из двух несвязанных сверточных слоев и третьего полностью связанного слоя. Первый сверточный слой использует 5184 фильтра 2 входного размера 16 * 16 * 3 с шагом 4 и выходным размером 4 * 4 * 24.
Второй слой берет 16 пространственно смежных 3 4 ? 4 ? 24 выходов первого слоя и полностью соединяет их с выходом 4 * 4 * 24.
Длина шага второго слоя составляет 4. Третий слой плотный, и полностью соединяет 62 * 62 * 24 выходов второго слоя с 4096 нейронами верхнего уровня. Общее количество обученных параметров составляет 15 миллиардов. После каждого слоя применяется локальная контрастная нормализация (LCN) перед переходом на следующий слой. Хотя объединение не применяется, размеры окна на следующем слое достаточно велики, чтобы включить пространственную информацию из соседних блоков.
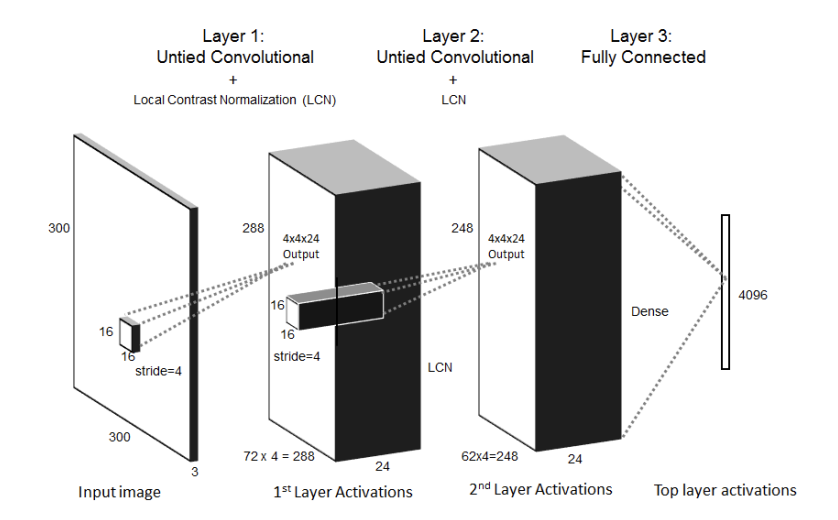
Рисунок 2 – Топология сети большого масштаба, обученная сеть. Около 15 миллиардов параметров
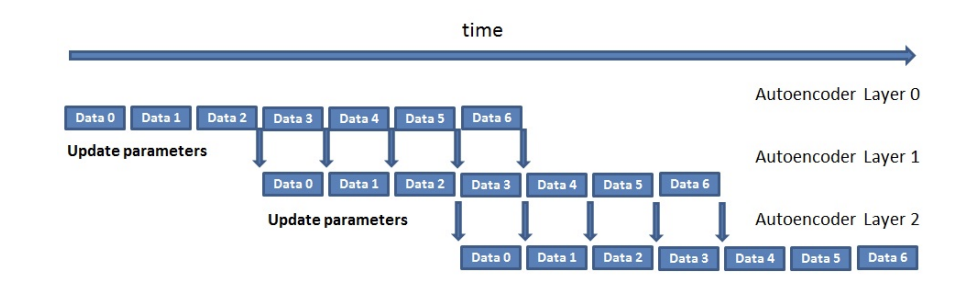
Рисунок 3 – Конвейер для полупараллельного обучения разреженных автоэнкодеров из одного источника данных
Данные обучения организованы в 99 207 блоков данных по 960 изображений. Каждый блок данных состоит из 5 мини-пакетов, где каждый мини-пакет содержит 192 изображения. Из-за масштаба данных предлагаемый алгоритм сокращает время обучения, используя конвейерную технику, где следующий слой начинает обучение до того, как предыдущий слой завершит обучение. Аналогично примеру, показанному на рис. 3, после того, как слой L обучил начальный набор блоков данных (в нашем случае 1000), следующий слой, L + 1, начинает обучение. Для этого одновременно запускаются два экземпляра слоя L: один, который продолжает обучение, и другой, который использует актуальные параметры для пересылки данных распространения из блока 0 в слой L + 1. Параметры экземпляра слоя прямого распространения L периодически синхронизируются с экземпляром слоя L, который продолжил обучение.
Мы заметили, что наша модель не чувствительна к выбору частоты синхронизации. Как правило, мы ждем, чтобы обучить слой L+1, пока цель слоя L не стабилизируется, что обычно происходит примерно после одного миллиона изображений.
Архитектура HPC
Для обучения нейронной сети в масштабе мы использовали 98 узлов кластера Edge HPC в Национальной лаборатории Лоуренса в Ливерморе. Кластер Edge состоит из 206 узлов с 12 ядрами Intel Xeon EP X5660 работающих на частоте 2,8 ГГц. Каждый узел имеет 96 ГБ DRAM и графический процессор Tesla M2050 (Fermi) NVIDIA с 3 ГБ GDDR5. Алгоритм обучения параллелен модели, как описано в [3], с узлами и GPU, обрабатывающими каждый мини-пакет по всей системе и распределяющими модель по GPU. Связь обеспечивалась MPI через карты Mellanox QDR Infiniband. Ускорители GPU использовались с CUDA 5.5 и MPI-direct связью, а операционная система была производной от ядра RHEL 6 версии 2.6.32. Набор данных хранился в файловой системе Lustre с пиковой пропускной способностью 10 ГБ/с. Каждый мини-пакет копировался из Lustre в память, а затем передавался в память графического процессора. Каждый графический процессор отвечает за вычисление своей части параметров модели для текущего мини-пакета. Связь внутри алгоритма происходит, когда входное (или выходное) поле слоя охватывает несколько графических процессоров. Связь обрабатывается распределенной структурой данных массива (с использованием MPI) в алгоритме обучения. Глобальная связь минимизируется за счет использования несвязанных локальных рецептивных полей и позволяет рецептивным полям обучаться независимо.
Предварительные результаты

Рисунок 4 – Визуализация выбора типичных весов первого слоя. Правый рисунок — это увеличенный фрагмент левого.
Мы обучили сеть, используя все изображения из набора данных YFCC100M. Изображения были предварительно обработаны, как в [2], и впоследствии изменены до 300 x 300 пикселей путем первого центрирования, затем масштабирования наименьшего размера до 300 пикселей и, наконец, обрезки. После обучения всех трех слоев мы переслали 2 миллиона изображений через сеть, чтобы получить значения активации для визуализации. Обратите внимание, что в этой статье тестовый набор значительно более шумный, чем эталонные наборы данных Labeled Faces In the Wild [16] и ImageNet [17], рассмотренные в предыдущих работах, таких как [3]. На рис мы показываем 5 основных стимулов для некоторых примеров нейронов.
Мы видим, что наша сеть способна изучать значительную структуру, идентифицируя здания, самолеты, текст, городские пейзажи и здания, похожие на башни, среди прочего. Сеть, по-видимому, реагирует на характерные текстуры, такие как края текста, стороны зданий и острые края самолетов на фоне плавной градации неба. Более того, сеть, по-видимому, активируется на крупномасштабных структурах на изображении, а не на локальных особенностях. Мы считаем, что существенный вклад в производительность наших сетей вносит ее большой размер, способный захватывать сложные концепции.
Хотя наши результаты обнадеживают, мы считаем, что значительного улучшения в обучении можно достичь за счет улучшения сетевой архитектуры и увеличения глубины. Как было показано в [2], сетевая архитектура оказывает значительное влияние на производительность глубоких сетей. В то время как сети, описанные в [3], смогли изучить сложные функции всего в трех слоях, наши результаты показывают, что чрезвычайно большие наборы данных, такие как YFCC100M, могут поддерживать (и, возможно, извлекать выгоду) из более глубоких сетей с улучшенным высокоуровневым обучением концепциям.
Резюме и будущая работа
Результаты, обсуждаемые в этой статье, представляют собой краткий обзор работы, ведущейся в Национальной лаборатории Лоуренса в Ливерморе по масштабированию глубоких нейронных сетей. Такие сети открывают огромный потенциал исследователям как в контролируемых, так и в неконтролируемых задачах компьютерного зрения, от распознавания и классификации объектов до неконтролируемого извлечения признаков. На сегодняшний день мы видим весьма обнадеживающие результаты обучения нашей большой трехслойной нейронной сети с 15 миллиардами параметров на наборе данных YFCC100M в неконтролируемом режиме.
Результаты показывают, что сеть способна изучать очень сложные концепции, такие как городские пейзажи, самолеты, здания и текст, все без меток или других указаний. То, что эта структура видна при осмотре, становится еще более примечательным из-за шумности нашего тестового набора (взятого случайным образом из самого набора данных YFCC100M).
Дальнейшая работа над нашими сетями будет сосредоточена на двух основных направлениях: (1) улучшение обучения концепции высокого уровня путем увеличения глубины нашей сети и (2) масштабирование ширины нашей сети в средних слоях. В первом направлении мы стремимся к улучшению обобщения высокого уровня и понимания сцены. Проблемы на этом фронте включают тщательную настройку параметров для борьбы с проблемой «исчезающего градиента» и проектирование структуры связей слоев более высокого уровня для максимизации обучения. Во втором направлении наши проблемы в основном сосредоточены на инженерии. Ограничения памяти и передачи сообщений становятся серьезной проблемой, даже в больших системах HPC, используемых LLNL. По мере того, как мы выходим за рамки нашей текущей большой нейронной сети, мы планируем изучить использование иерархий памяти для подготовки промежуточных/входных данных, чтобы минимизировать объем коммуникации между узлами, что позволяет эффективно обучать и анализировать даже более крупные сети.
Список использованной литературы
- A. Krizhevsky, I. Sutskever, and G. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012
- A. Coates, B. Huval, T. Wang, D. J. Wu, A. Y. Ng, and B. Catanzaro., “Deep learning with cots hpc,” in International Conference on Machine Learning, 2013.
- Q. V. Le, M. Ranzato, R. Monga, M. Devin, K. Chen, G. S. Corrado, J. Dean, and A. Y. Ng, “Building high-level features using large scale unsupervised learning,” in International Conference on Machine Learning, 2012.
- T. Mikolov, K. Chen, G. Corrado, and J. Dean., “Efficient estimation of word representations in vector space,” in Proceedings of Workshop at ICLR, 2013.
- O. Abdel-Hamid, L. Deng, and D. Yu, “Exploring convolutional neural network structures and optimization techniques for speech recognition,” in Interspeech 2013, 2013.
- G. Hinton, L. Deng, D. Yu, A.-R. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. Sainath, G. Dahl, and B. Kingsbury, “Deep neural networks for acoustic modeling in speech recognition,” IEEE Signal Processing Magazine, vol.
- H. Bourlard and N. Morgan, Connectionist Speech Recognition: A Hybrid Approach, Kluwer Academic Publishers, 1993.
- D. Claudiu Ciresan, U. Meier, L. M. Gambardella, and J. Schmidhuber, “Convolutional neural network committees for handwritten character classification,” in International Conference on Document Analysis and Recognition, 2011.
- D. Reby, S. Lek, I. Dimopoulos, J. Joachim, J. Lauga, and S. Aulagnier, “Artificial neural networks as a classification method in the behavioural sciences,” Behavioural Processes, vol. 40, pp. 3543, 1997.
- R Uetz and S. Behnke, “Large-scale object recognition with cuda-accelerated hierarchical neural networks,” in IEEE International Conference on Intelligent Computing and Intelligent Systems, 2009.
- L. Cao and L. Fei-Fei, “Spatially coherent latent topic model for concurrent object segmentation and classification,” in Proceedings of International Conference on Computer vision, 2007.
- R. Socher and M. Ganjoo and C. D. Manning and A. Y. Ng, “Zero Shot Learning Through Cross-Modal Transfer,” in Advances in Neural Information Processing Systems 26. 2013.
- J. K. Wang, F. Yan, A. Aker, and R. Gaizauskas, “A poodle or a dog? Evaluating automatic image annotation using human descriptions at different levels of granularity,” in Proceedings of the Workshop on Vision and Language, 2014.
- James Hays and Alexei A. Efros, “im2gps: estimating geographic information from a single image,” in Proceedings of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2008.
- J. Choi, B. Thomee, G. Friedland, L. Cao, K. Ni, D. Borth, B. Elizalde, L. Gottlieb, C. Carrano, R. Pearce, D. Poland, “ The Placing Task: A Large Scale Geo-Estimation Challenge for Social-Media Videos and Images,” 3rd ACM Multimedia Workshop On GeoTagging and Its Applications in Multimedia.
- G. B. Huang, M. Ramesh, T. Berg, and E. Learned-Miller, “Labeled faces in the wild: A database for studying face recognition in unconstrained environments,” .
- J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-fei, “Imagenet: A large-scale hierarchical image database,” in In CVPR, 2009.