Аннотация
Ж. Гийо, С. Радуани, Ж. Фальке Поиск многоязыковой информации на основе онтологий. Для нашего первого участия в кампании по оценке CLEF, наша цель состоит в том, чтобы исследовать вариант перевода свободной техники для многоязычного поиска информации. Этот метод основан на онтологическом представлении документов и запросов. Мы используем многоязычную онтологию для представления документов/запросов. Для каждого языка мы используем многоязычную онтологию для отображения термина к соответствующей концепции. То же самое отображение применяется к каждому документу и каждому запросу. Затем мы используем классическую модель векторного пространства для индексации и выполнения запросов. Основные преимущества нашего подхода: не требуется фаза слияния, независимость от автоматических переводчиков между всеми парами существующих языков, и для добавления нового языка требуется только новый словарь отображения в многоязычной онтологии.
![Рисунок 1 — Пример определения понятия в UNL [UNL]](images/an.gif)
Рисунок 1. Пример определения понятия в UNL [UNL]
Введение
Существующие подходы используют либо перевод всех документов в общий язык, либо автоматический перевод запросов или же комбинацию переводов и запросов, и документов [Chen в соавт. 2003]. В этих случаях нам нужны автоматические переводчики между всеми парами языков. Если перевести запросы, то после получения списка результатов от каждой поисковой системы, мы должны использовать процедуру слияния, чтобы обеспечить уникальный ранжированный список результатов. К тому же добавление нового языка (для запроса или документа) требует столько переводчиков, как и существующие языки.
В нашем подходе мы пытались «развести» эти проблемы с помощью многоязычной онтологии. На основе этой онтологии, мы проводили различные эксперименты с многоязычным набором тестов. Мы получаем документы, написанные на голландском, английском, финском, французском, немецком, итальянском, испанском и шведском языках, независимо от языка запросов.
Во–первых, мы попытались доказать целесообразность нашего подхода с использованием английского языка при подаче запросов. Мы также пытались доказать, что наша система не зависит от языка запросов. Таким образом, мы использовали голландский, французский, испанский и при подаче запросов, В следующем разделе мы опишем наш подход и предоставим наши официальные работы.
1 Поиск многоязыковой информации на основе онтологий
1.1 Многоязычная онтология
Многоязычная онтология определяется одной онтологией и набором словарей (один словарь для каждого языка). Онтология является формальной, явной спецификацией общей концептуализации. [Gruber 1993]. Она содержит множество различных и определенных понятий С, связанных набором отношений R. В нашем подходе, нам нужно лишь использовать набор понятий. Здесь мы приведем два примера понятий, извлеченных из нашей онтологии:
- 8612: единица длины (в США и Великобритании), равная одной двенадцатой стопы;
- 28845: толстый короткий самый важный палец на передних конечностях.
Словарь DL представляет собой объединение понятий онтологии C с точки зрения установленных терминов TL, относящихся к языку L. Обозначим: DL: C –> TL. Действительно, понятие с обозначено набором терминов t1, t2, ..., tn в языке L. Обозначим DL (с) = {t1, t2, ..., tп}. Мы также определим взаимное отношение SL: TL –> C помощью SL (Т) = {c принадлежит C | t принадлежит DL (c)}. На самом деле, термин t обозначает понятия, c1, c2, ..., сm. Мы также будем обозначать SL(t) = {c1, c2, ..., сm}. Здесь мы приведем два примера ассоциаций между терминами и понятиями:
D.EN(28845)= {thumb}.
S.FR(pouce)= {8612, 28845 }.
![Рисунок 1 — Пример определения понятия в UNL [UNL]](images/article10_pic1.png)
Рисунок 1. Пример определения понятия в UNL [UNL]
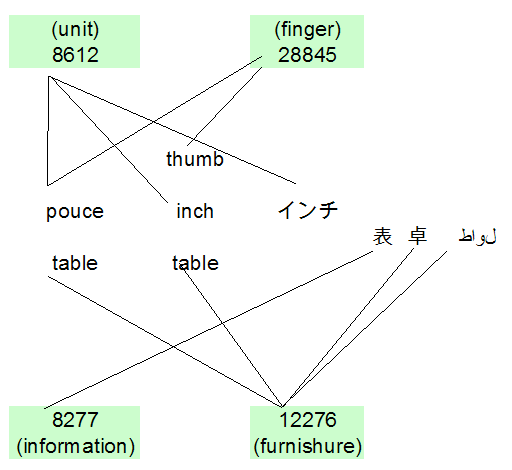
Рисунок 2. Пример термина–понятия ассоциации
Чтобы выполнить начальную загрузку и построить словари, мы использовали словари эсперанто, найденные в Интернете (в основном из Ergane [ERG 2005]). Мы также использовали функцию автоматического перевода, чтобы выполнить некоторые из них.
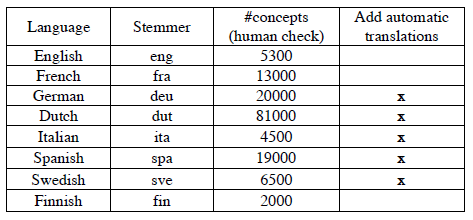
Таблица 1. Описание лингвистических используемых ресурсов.
1.2 Поиск многоязыковой информации на основе онтологий.
В нашем подходе для каждого документа во всем наборе, мы используем многоязычную онтологию для сопоставления каждого термина к соответствующей ему концепции. Мы применяем тот же самый процесс на запросы.
Документ dL =
Мы не делали ничего для двусмысленности терминов. На самом деле, если термин неоднозначен, мы заменяем его всеми его соответствующими понятиями.
Перед стадией отображения терминов, мы используем «стоп–список слов» для каждого языка и специализированной получающейся системы. Мы использовали Snowball, небольшой язык обработки строк, предназначенный для создания алгоритмов, вытекающих по информационному поиску [Snow 2005].
Мы не вводили какие–либо морфосинтаксические или обрабатывающие (например, н–граммы), чтобы разорвать сложные слова на голландском, немецком или финском.
Для индексации и выполнения запросов, мы используем модель векторного пространства [Солтон и др. 83].
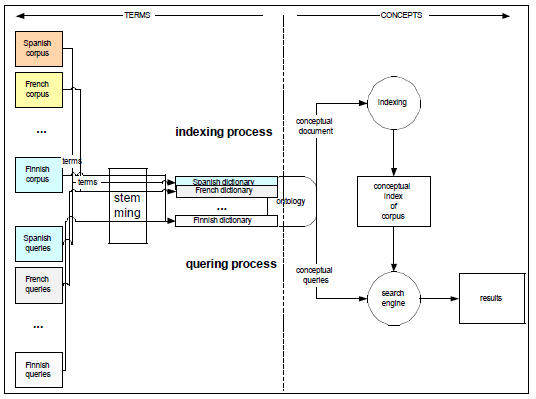
Рисунок 3. Индексация и процесс организации запросов.
1.3 Описание официальных пробегов.
В нашем подходе, каждый запрос Q состоит из двух полей: поле темы и области тела. Обозначим Q = (Topic, Body). Содержание каждого поля зависит от пробега. Каждое поле состоит из списка терминов, извлеченных из оригинального текста запроса.
Поскольку запросы являются точными, мы используем поле темы для запроса всей коллекции. В результате мы получаем набор документов, содержащих понятия темы. Затем мы используем поле тела чтобы классифицировать этот набор документов.
Здесь мы приведем пример запроса, составленного в тему поля (текст между тегами тему) и поле тела (текст между всеми другими тегами).

Рисунок 4. Примера запроса.
Теперь мы представляем наши официальные заходы. В следующих трех заходов, мы используем английский язык при подаче запросов:
- AUTOEN: поле темы состоит из условий названия исходного запроса (текст между тегами заголовков). Поле тела состоит из текста исходного запроса.
- ADJUSTEN: поле темы состоит из модифицированного заголовка путем добавления и/или удаления терминов. Добавляющиеся термины извлекаются из оригинального текста запроса. Поле тела состоит из текста исходного запроса.
- FEEDBCKEN: поле темы состоит из модифицированного заголовка, как в ADJUSTEN. Поле тела состоит из исходного текста запроса и первого соответствующего документа (если он существует) в первых 30 документах, найденных во время предыдущего запуска ADJUSTEN.
В таблице 1 показаны результаты каждого прогона. Конечно, это трудно иметь хороший результат для запуска AUTOEN в то время как тема содержит все понятия, соответствующие названию запроса терминов. Нам удалось улучшить результат в 63.11%, используя скорректированную тему. И, наконец, с помощью обратной связи актуальность, мы улучшили результат 24,74%.
Это улучшение обусловлено векторной моделью, которая дает лучшие результаты, когда векторы документов/запросов длинны.
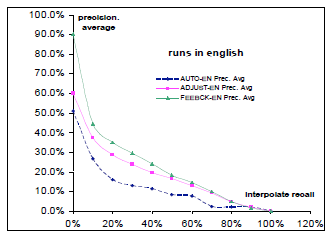
Рисунок 5. Сравнение результата системы с помощью трех стратегий.
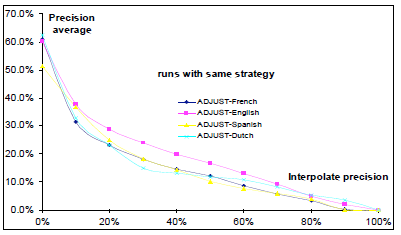
Рисунок 6. Сравнение результатов системы с использованием четырех языков.
Для того чтобы сравнить результаты системы с использованием различных языков при подаче запросов, мы провели еще три пробега: ADJUSTDU, ADJUSTFR и ADJUSTSP. Для каждого запуска, мы используем соответственно голландский, французский, испанский при подаче запросов. В этих опытах, поле темы составлено измененным названием, как в ADJUSTEN и поле тела состоит из исходного текста запроса.
Для всех четырех пробегов, мы получаем почти одинаковую среднюю точность: 13.90% для ADJUSTDU 13,47% для ADJUSTFR, 13.80% для ADJUSTSP и 16,85% для ADJSUTEN. Наша система не зависит от языка запросов. Это дает практически одинаковый результат при подаче запросов на четырех разных языках. Трудно объяснить разницу, потому что охват и качество онтологических словарей имеют важное значение.
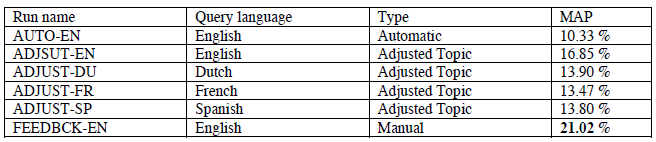
Таблица 2. Описание и Средняя точность (MAP) наших официальных многоязычных пробегов.
Вывод
В ходе этой кампании оценки CLEF, мы оценили многоязычную подход, основанный на онтологиях, для многоязычного поиска информации. Мы не использовали никакого перевода ни для документов, ни для запросов. Мы провели общее представление документов/запросов на основе многоязычной онтологии. Тогда мы использовали векторную модель для индексации и выполнения запросов. По сравнению с существующими подходами, наш подход имеет ряд преимуществ. В самом деле, не существует зависимости от автоматических переводчиков между всеми парами языков. Когда мы добавляем новый язык, мы только добавляем в онтологию новый словарь отображения. Кроме того, мы не нуждаемся в каком–либо методе слияния для ранжирования списка найденных документов.
В этой предварительной работе мы попытались доказать лишь целесообразность нашего подхода. Мы пытались также доказать, что наша система не зависит от языка запросов. У нас еще есть некоторые ограничения в нашей системе, потому что мы не ввели какой–либо морфосинтаксической обработки чтобы разорвать сложные слова на голландском, немецком или финском языках. Кроме того, наша онтология является неполной и грязной (мы импортировали много ошибок с автоматическим переводом).
Кроме того, мы использовали тот же подход в области выравнивания би–текста. Мы использовали другие языки, такие как китайский, арабский и русский. [Гайота 2005].
Выражение признательности
Мы хотели бы поблагодарить организаторов CLEF–2005 за их усилия. Мы также хотели бы поблагодарить Metaread за предоставленную нам возможность использовать информационно–поисковую систему «idxvli» (быстрый индексатор для больших корпусов).
Список использованной литературы
- [Chen at al. 2003] Chen, A. and Gey, F. Combining query translation and document translation in cross-language retrieval. In proceedings CLEF-2003, pp. 39.48. Trondheim.
- [ERG 2005] Ergane: http//download.travlang.com/, see also http://www.majstro.com/-
- [Guyot 2005] GUYOT, J. yaaa: yet another alignment algorithm - Alignement ontologique bi-texte pour un corpus multilingue. Cahier du CUI 2005.
- [Gruber 1993] Gruber, T. R. A translation Approach to Portable Ontology Specifications, Knowledge Acquisition, 5 : 199-220, 1993.
- [UNL] UNL: Universal Networking Language. http://cui.unige.ch/isi/unl/ & http://www.undl.org/.
- [Salton et al. 83] Salton, G. and Mcgill, M. J. Introduction to the modern Information Retrieval. McGraw-Hill (1983)
- [Snow 2005] SnowBall: http://snowball.tartarus.org/.