Англо-русский
статистический глоссарий:
Основные понятия
© П.Н.Дубнер, 2000
infoscope@writeme.com
A
B
C
D
E
F
G
H
I
J
K
L
M
N
O
P
Q
R
S
T
U
V
W
X
Y
Z
additive
аддитивность
Ситуация, в
которой модель для зависимой переменной получается простым сложением
соответствующим образом вычисленных эффектов каждого из факторов (независимых
переменных). Аддитивность означает отсутствие взаимодействий.
alternative
hypothesis
альтернативная гипотеза
См. нулевая
гипотеза .
ANOVA
ДА
См. дисперсионный
анализ.
analysis of variance
дисперсионный
анализ
Совокупность моделей и методов, применяемых для анализа
зависимости непрерывного отклика от дискретных факторов.
ARIMA
АРПСС
Модели
авто-регрессии проинтегрированного скользящего
среднего (auto-regressive integrated moving average) широко используются
при анализе временных рядов. Хотя, на мой взгляд, их ценность для задач
прогнозирования сильно преувеличена, они неоценимы во многих задачах, например,
как: (а) средство получения сглаженных оценок спектра; (б) источник
параметрического пространства при распознавании образов, когда исходными данными
являются временные ряды; (в) основа способов, позволяющих находить моменты
изменения характера поведения временных рядов.
arithmetic mean
среднее
арифметическое
Сумма значений, деленная на их число: 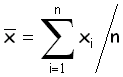 .
.
Среднее арифметическое простой
случайной выборки является несмещеннрй
оценкой среднего генеральной
совокупности. Следует иметь в виду, что среднее арифметическое – не
единственная и не всегда лучшая характеристика центральной
тенденции распределения. Используются также и другие показатели, такие как
геометрическое
или гармоническое среднее, медиана
или мода .
average
среднее
Термин “среднее” обычно
используется, когда говорят о параметре генеральной
совокупности, когда же имеют в виду статистику,
т.е. результат вычислений по выборочным данным, добавляют соответствующий
эпитет, например, среднее
арифметическое.
arithmetic weighted mean;
weighted average
взвешенное среднее
Сумма
произведений каждого значения на его вес, деленная на сумму весов, где веса –
неотрицательные коэффициенты, связанные с каждым значением. Вот как вычисляется
среднее переменной x, когда весовой переменной объявлена переменная
w: 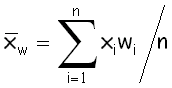 .
.
См. тж. взвешенные
данные.
autocorrelation
автокорреляция
Автокорреляция – это корреляция (взаимосвязь) между наблюдениями временного
ряда и значениями того же ряда, отстоящими на фиксированный интервал времени.
При работе с дискретизированными временными рядами проще всего считать, что
вычисляется корреляция между двумя множествами наблюдений, одно из которых –
исходный ряд, другое – он же, сдвинутый на нужное число точек.
bar chart
столбиковая диаграмма
Столбиковая диаграмма позволяет подытожить множество дискретных данных. Она
часто применяется в разведочном анализе данных для иллюстрации основных
характеристик распределений, которые на ней представлены рядом прямоугольников
одинаковой ширина, каждый из которых соответствует одной из категорий. Длина (и,
следовательно, площадь) каждого прямоугольника пропорциональна числу наблюдений
в представляемой им категории.
Столбиковые диаграммы используются для
иллюстрации номинальных или порядковых данных.
Столбиковые диаграммы можно
выводить горизонтально или вертикально, между столбиками (прямоугольниками)
обычно оставляют свободное пространство, в то время как на гистограмме
столбики вплотную прижаты друг к другу.
Bernoulli
distribution
распределение Бернулли
То же, что и биномиальное
распределение.
beta-distribution
бета-распределение
Распределение
вероятностей непрерывной случайной величины, принимающей значения на отрезке
[0, 1], плотность которого задается формулой 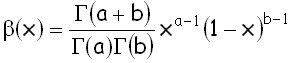 , где 0
, где 0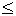 x1,
a,b>0 и Г – гамма-функция.
x1,
a,b>0 и Г – гамма-функция.
Примечание. Его частными
случаями являются многие широко используемые распределения. Скажем, при
a=b=1 получаем равномерное распределение.
Подробнее.
between factor
внутрисубъектный
фактор;
внутриобъектный фактор;
группируемый фактор
См. группирующий
фактор.
bias (of estimator)
смещение;
систематическая
ошибка (оценки)
Разница между ожидаемым
значением статистики и истинным значением параметра генеральной
совокупности, который эта статистика
оценивает.
biased estimator
смещенная оценка
Статистика, ожидаемое
значение которой не равно значению оцениваемого этой статистикой параметра
генеральной совокупности.
binary variable
бинарная переменная
Дихотомическая
переменная, значения которой кодируются числами 1 и 0. Как правило, 0
обозначает неудачу или отсутствие, а 1 – успех, наличие. Стандартный пример –
бросание монеты, где почему-то выпадение орла всегда обозначают кодом 1.
binomial distribution
биномиальное
распределение
Предположим, что мы проводим N испытаний, в
каждом из которых возможны лишь “успех” или “неудача”, причем вероятность
“успеха” в каждом испытании постоянна. Принято вероятность “успеха” обозначать
буквой p, а вероятность “неудачи” – буквой q.
Распределение числа успехов в такой схеме называется биномиальным; сама схема –
схемой Бернулли. Нужно ли подчеркивать, что распределение однозначно
определяется параметрами N и p?
Стандартный пример –
бросание монеты. Монета называется правильной, если выпадение орла равняется
выпадению решки; бросание правильной монеты 22 раза описывается
биномиальным распределением с параметрами N=22 и p=1/2.
Другой стандартный пример – бросание кости, которая называется правильной, если
вероятности выпадения любой грани равны друг другу, так что распределение числа
выпадения шестерок при 66 бросаниях описывается биномиальным
распределением с параметрами N=66 и p=1/6.
Биномиальное распределение
вероятностей дискретной случайной величины 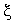 задается формулой
задается формулой 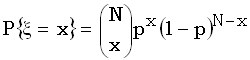 , где x=0,1,2,…,N, N=1,2,… и
0<p<1, причем
, где x=0,1,2,…,N, N=1,2,… и
0<p<1, причем 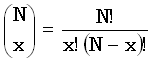 .
.
Подробнее.
bivariate distribution
function
двумерная функция распределения
Функция, дающая для любой
пары значений x, y вероятность того, что случайная
величина Х будет меньше или равна x, а случайная величина
Y меньше или равна y:
F(x,y) = Pr[Xx; Yy].
Примечание. Это понятие можно легко обобщить на большее число случайных
величин.
bivariate Laplace-Gauss
distribution
двумерное распределение Лапласа-Гаусса
См. двумерное
нормальное распределение.
Обратите внимание: не
двухмерное.
bivariate normal distribution
двумерное нормальное распределение
Распределение
вероятностей двух непрерывных величин X и Y, плотность
вероятности которого равна: 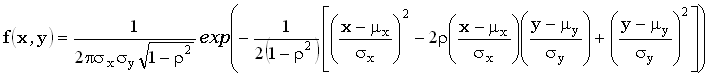 ,
,
где -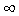 <x< + и - <y< +,
<x< + и - <y< +, 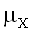 и
и 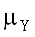 – математические ожидания,
– математические ожидания, 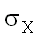 и
и 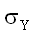 – стандартные отклонения
маргинальных (нормальных) распределений X и Y,
– стандартные отклонения
маргинальных (нормальных) распределений X и Y, 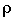 – коэффициент
корреляции случайных величин X и Y.
– коэффициент
корреляции случайных величин X и Y.
Если такое
распределение нарисовать в трехмерном пространстве, откладывая по вертикальной
оси его плотность, то мы увидим колокол, если две дисперсии равны друг другу,
или сплющенный “колпак”, если дисперсии не равны.
Важность этого
распределения обычно аргументируется тем, что если переменные распределены
совместно нормально, то всевозможные маргинальные распределения также нормальны.
Кроме того, в таких случаях некоррелированность (равенство нулю коэффициента
корреляции) эквивалентна независимости.
bivariate normality
двумерная
нормальность
Так характеризуют ситуацию, когда наши случайные величины
X и Y подчиняются двумерному
нормальному распределению, которое имеет специфическую колоколообразную
форму (не всякое колоколообразное распределение нормально!), однако, если
распределение не слишком «испорчено», говорят о приближенной нормальности.
Bonferroni adjustment
корректировка
Бонферрони
Рассмотрим ситуацию, когда нам нужно проверять несколько
статистических гипотез. Проверяя каждую из них по отдельности, мы знаем, что
вероятность ошибки
первого рода не превосходит уровня
значимости 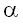 . Что мы можем
сказать при этом о вероятности того, что проверяя N гипотез, мы ни
разу не допустим ошибку 1-го рода? Идея Бонферрони состоит в следующем: если мы
хотим, чтобы уровень
значимости составной гипотезы равнялся
. Что мы можем
сказать при этом о вероятности того, что проверяя N гипотез, мы ни
разу не допустим ошибку 1-го рода? Идея Бонферрони состоит в следующем: если мы
хотим, чтобы уровень
значимости составной гипотезы равнялся 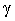 , то каждую из N отдельных гипотез
следует проверять с уровнем значимости =/N.
, то каждую из N отдельных гипотез
следует проверять с уровнем значимости =/N.
Так, если мы хотим, чтобы при проверке
4 независимых гипотез вероятность допустить (хотя бы одну) ошибку не
превосходила 0.05, то каждую отдельную гипотезу следует проверять с
уровнем значимости 0.0125.
Корректировку Бонферрони обычно
используют при сравнительно малом числе проверяемых гипотез, поскольку она
приводит к консервативным
критериям.
box plot
ящичковая диаграмма
Представление выборки в виде одного или нескольких ящиков
с усами. Используется для визуального сравнения распределений значений
нескольких переменных и/или подгрупп значений одной переменной.
В
современных статистических пакетах имеются разнообразные способы комбинирования
ящиков с усами в ящичковую диаграмму.
box-and-whisker
plot
ящик-с-усами
Способ визуализации множества данных, измеренных в
интервальной
шкале. Часто применяется в разведочном анализе данных. Выглядит как
прямоугольник, на котором представлены максимальное и минимальное значения
выборки, ее нижний и верхний квартили,
а также медиана
.
См. тж. пятичисловая
сводка .
case
наблюдение
Наблюдение состоит из
значений переменных, измеренных у одной и той же экспериментальной
единицы. Скажем, возраст, температура и давление
пациента составляют наблюдение. Значение одной переменной называют
измерением.
Синоним: observation.
capitalization on chance
подгонка к особенностям выборки
Так
говорят про модель, которая слишком хорошо отражает особенности выборки, по
которой ее строили. Подобная модель будет почти наверняка работать плохо за
пределами этой выборки. М.М.Бонгард предложил в подобных ситуациях говорить о
возникновении предрассудков.
categorical variable
дискретная
переменная
Переменная, измеренная в номинальной
или ранговой
шкале. Значения такой переменной часто называют градациями.
Множество объектов (статистических единиц), соответствующих одной и той же
градации, называют категорией объектов.
causal model
причинная модель
Модель, в которой учтены представления экспериментатора о причинных связях
между наблюдаемыми переменными. Имеются методы построения и оценки параметров
подобных моделей – пока, правда, лишь линейных.
cell
клетка; ячейка
В результате кросс-табуляции
появляется совокупность подвыборок, каждая из которых задается уникальной
комбинацией градаций факторов. Когда кросс-табуляцию представляют в виде
(многомерной) матрицы, уникальную комбинацию градаций факторов называют клеткой
или ячейкой. Например, два фактора, пол со значениями мужской
и женский и риск, со значениями низкий,
средний и высокий, образуют шесть ячеек: мужчины с низким
риском, мужчины со средним риском, мужчины с высоким риском, женщины с низким
риском, женщины со средним риском и женщины с высоким риском.
censoring
цензурирование
Когда за
субъектом наблюдают до наступления некоторого события (пример: наблюдение за
состоянием пациента до момента его смерти), его не всегда можно проследить в
точности до этого момента. Пациент может уехать и стать недоступным, выбыть по
какой-либо другой причине, или просто время сбора данных может закончиться до
того, как наступило представляющее интерес событие. В этом случае единственное,
что мы можем сказать, это то, что время до наступления события не меньше времени
до последнего наблюдения. Время наступления события, таким образом, оказывается
цензурированным.
Обратите внимание: наблюдения в выборке могут быть
цензурированными справа (наблюдение прекратилось до наступления события) или
слева (наблюдение начинается лишь после наступления события).
Для анализа
цензурированных наблюдений применяются, естественно, специализированные методы.
Один из примеров – методы анализа выживаемости.
centered random
variable
центрированная случайная величина
Случайная величина,
математическое ожидание которой равно нулю. Очень часто случайные величины
центрируют, вычитая из них математическое ожидание или его несмещенную оценку.
Примечание. Если математическое ожидание случайной величины Х
равно 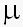 , то
соответствующая центрированная величина есть Х-.
, то
соответствующая центрированная величина есть Х-.
См. тж. нормированная
случайная величина .
central moment of order
q
центральный момент порядка q
В теории вероятностей и
математической статистике – математическое ожидание одномерной центрированной
случайной величины: E[(X-x)q].
В прикладной
статистике – характеристика распределения переменной, равная среднему
арифметическому разностей между наблюдаемыми значениями xi
и их средним  , возведенных в q-ю
степень:
, возведенных в q-ю
степень: 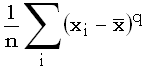 , где n – число
наблюдений.
, где n – число
наблюдений.
Пример. Центральный момент второго порядка – дисперсия
случайной величины X и оценка дисперсии, когда он вычисляется на
основе выборки значений переменной.
central tendency
центральная
тенденция
Область, в которой группируется выборка, естественно называть
ее “центром”. Про индикаторы и статистики, позволяющие судить о положении такого
центра, говорят, что они измеряют центральную тенденцию. К типичным мерам
центральной тенденции относятся среднее,
медиана,
мода,
усеченное среднее. Для симметричных распределений значения этих мер совпадают.
Различие становится существенным для асимметричных
распределений.
Приведенный список, конечно, не исчерпывает разнообразия
применяемых мер. Нечасто применяемой мерой является геометрическое
среднее, предназначенное для распределений, скошенных вправо.
centroid
центроид;
центр множества точек
Центроидом, или центром, многомерного множества данных называется точка,
координатами которой являются средние значений по каждой из размерностей; в
физике ему соответствует центр тяжести, если считать, что у каждой точки масса
единичная.
Пример. Для двумерных данных (с переменными X и
Y) центроидом будет точка  , т.е. (среднее X-значений, среднее
Y-значений). Линия простой линейной регрессии всегда проходит через
центроид данных X-Y.
, т.е. (среднее X-значений, среднее
Y-значений). Линия простой линейной регрессии всегда проходит через
центроид данных X-Y.
characteristic
характеристика, показатель,
признак
Некоторое свойство, которое используется для описания объектов
из данной популяции (совокупности). Вполне синонимичным является термин
признак.
Примечание. Признаки бывают количественными и качественными (дискретными) в зависимости от шкалы, в которой они измерены.
chi-square test for
goodness of fit
критерий согласия хи-квадрат
Критерий согласия
хи-квадрат используется для проверки гипотезы о совпадении эмпирического и
теоретического (постулируемого) распределений дискретных случайных величин.
Критерий основывается на сравнении наблюденных и ожидаемых (теоретических) встречаемостей.
Статистика
критерия равна сумме квадратов разностей между наблюденными и ожидаемыми
встречаемостями, деленных на ожидаемые встречаемости 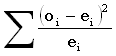 , где
oi – наблюденная встречаемость i-й градации, а
ei – ее ожидаемая встречаемость. Обратите внимание:
значение статистики зависит от объема выборки.
, где
oi – наблюденная встречаемость i-й градации, а
ei – ее ожидаемая встречаемость. Обратите внимание:
значение статистики зависит от объема выборки.
chi-square test for
independence (Pearson's)
критерий независимости хи-квадрат (Пирсона)
Критерий независимости хи-квадрат Пирсона предназначен для проверки гипотезы
о независимости двух признаков, задающих строки и столбцы таблицы сопряженности.
Статистика этого критерия 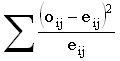 , где сумма берется по всем клеткам таблицы сопряженности. Она
совпадает с статистикой критерия
согласия хи-квадрат, специфика состоит лишь в способе вычисления ожидаемых
встречаемостей: eij=ricj/N, где
ri – сумма встречаемостей в i-й строке,
cj – сумма встречаемостей в j-м столбце.
, где сумма берется по всем клеткам таблицы сопряженности. Она
совпадает с статистикой критерия
согласия хи-квадрат, специфика состоит лишь в способе вычисления ожидаемых
встречаемостей: eij=ricj/N, где
ri – сумма встречаемостей в i-й строке,
cj – сумма встречаемостей в j-м столбце.
chi-squared
distribution
распределение хи-квадрат
Распределение
вероятностей непрерывной случайной величины с значениями от 0 до
+, плотность которого задается
формулой 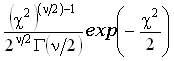 ,
,
где x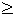 0, f=1,2,...; Г–
гамма-функция.
0, f=1,2,...; Г–
гамма-функция.
Примеры.
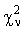 с параметром f; число f
называют еще количеством ее степеней
свободы.
/2 подчиняется гамма-распределению
с параметром f/2.
с параметром f; число f
называют еще количеством ее степеней
свободы.
/2 подчиняется гамма-распределению
с параметром f/2. chi-squared test
критерий хи-квадрат
Критерий, статистика которого подчиняется распределению 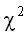 .
.
Стандартные применения:
chi-squared test of
homogeneity
критерий однородности хи-квадрат
Предположим, что наша
генеральная совокупность разбита на подсовокупности значениями признака
А, а каждая из них, в свою очередь, – на под-подсовокупности
значениями признака В. Если распределения под-подсовокупностей не
зависят от объемлющей подсовокупности, то говорят о независимости признаков
A и B, а также о гипотезе однородности.
Пример. Предположим, что мы даем школьникам контрольную по математике. Одна
из гипотез однородности состоит в предположении об одинаковых результатах
мальчиков и девочек.
Конечно, фактически имеется в виду проверка гипотезы о
независимости признаков, стандартным критерием для которой является критерий
хи-квадрат Пирсона .
coefficient of variation
коэффициент вариации (случайной величины или
распределения вероятностей)
Отношение стандартного отклонения к
математическому ожиданию (или его абсолютной величине) случайной величины, 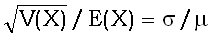 , а также
отношение s/m оценок этих параметров. Коэффициент вариации является
одной из мер разброса
данных.
, а также
отношение s/m оценок этих параметров. Коэффициент вариации является
одной из мер разброса
данных.
Примечания:
composite hypothesis
сложная
гипотеза; составная гипотеза
Гипотеза, которая включает более одной (в
частности, бесконечное число) простых
гипотез.
Примечание. Эта терминология естественна для ситуации, когда
совокупность гипотез удается параметризовать просто устроенным множеством
(скажем, одномерным континуумом). При этом простая гипотеза соответствует точке
в пространстве параметров.
Пример. Рассмотрим семейство нормальных
распределений. Гипотеза = 0 является простой, если стандартное
отклонение совокупности известно, и сложной, если оно неизвестно.
concordant
согласованные
Пара
наблюдений с двумя (по меньшей мере) порядковыми переменными, значения которых
на первом наблюдении оба меньше или оба больше, чем на втором. Вот пример
согласованной пары:
X1 X2
10 100
20 150
Антоним: рассогласованные
conditional expectation
условное
математическое ожидание
Математическое ожидание условного
распределения случайной величины
conditional frequency
distribution
условное распределение частот
Распределение (частот)
k (1kK) показателей из многомерного распределения
(частот), когда остальные K-k показателей фиксированы.
Примечание. Когда K=2, условные распределения частот считываются
непосредственно из строк и столбцов таблицы частот с двумя входами. Условное
распределение относительных частот получается делением чисел в каждой строке
(столбце) на общее число в соответствующей строке (столбце).
Пример
Имея
распределение частот двух показателей X и Y, мы можем
построить:
conditional probability
distribution
условное распределение вероятностей
Многомерное
распределение случайных величин, которое получается, когда значения одной или
нескольких из них фиксированы.
confidence coefficient
коэффициент
доверия
См. доверительный
уровень.
Примечание. Иногда доверительным уровнем называют (достаточно
малое) число , а
коэффициентом доверия – число (1-), однако, этот вариант не рекомендуется; см.
доверительная
вероятность.
confidence interval
доверительный
интервал
Доверительный интервал для скалярного параметра генеральной
совокупности – это отрезок, с большой вероятностью содержащий этот параметр. Эта
фраза без дальнейших уточнений бессмысленна. Поскольку границы доверительного
интервала оцениваются по выборке, естественна его частотная интерпретация: если
много раз брать из генеральной совокупности независимые выборки и по каждой из
них оценивать доверительный интервал, то определенная доля этих интервалов
“накроет” значение параметра. Доверительный интервал строят так, чтобы доля
накрывающих интервалов равнялась доверительному
уровню; не путать с уровнем
значимости критерия – вещи близкие, но не тождественные. Стандартные
значения доверительных уровней: 95%, 90%, 99% и, реже, 99.9%.
Ширина
доверительного интервала характеризует степень нашего незнания: слишком широкий
доверительный интервал может служить указанием на то, что следует собрать больше
данных.
Доверительные интервалы дают больше информации о параметре, чем
простая точечная оценка
, поскольку отграничивают сразу целую совокупность допустимых значений.
См.
тж. доверительные
границы.
confidence level
доверительный
уровень
Вероятность того, что неизвестное значение параметра будет
накрыто доверительным
интервалом. Как правило, задается величиной 1-, где в качестве берут один из стандартных уровней
значимости 0.1, 0.05 или 0.01. Например,
для =0.05
доверительный уровень равен 1-0.05=0.95. Часто выражается в
процентах, так что последнее значение – это 95% доверительный
уровень.
confidence limits
доверительные
границы
Доверительные границы – нижняя и верхняя границы доверительного
интервала. Для одностороннего интервала вида (-, T] или [T, +), говорят о (обратите внимание –
единственное число) доверительной границе T.
Пример. Верхняя и
нижняя границы 95% доверительного
интервала – это 95% доверительные границы.
confidence
probability
доверительная вероятность
Вероятность 1-, где , как правило, принимает одно из
стандартных значений 0.1, 0.05 или 0.01,
характеризующая доверительный
интервал, или, реже, статистически
накрывающий интервал.
Примечание. Величину 1- часто выражают в процентах.
conservative test
консервативный
критерий
Критерий называют консервативным, если его фактический уровень
значимости меньше декларируемого. Примером может служить критерий
Колмогорова-Смирнова, применяемый для проверки гипотезы о совпадении
распределений, который становится консервативным, когда параметры распределения
оцениваются по данным, а не задаются заранее. Консервативный критерий реже, чем
нужно отвергает нулевую гипотезу, когда она неверна, то есть является менее
мощным, чем его неконсервативный собрат.
Противоположностью консервативному
критерию является либеральный, для которого фактический уровень
значимости больше декларируемого.
consistent test
состоятельный
критерий
Критерий состоятелен для заданной альтернативной
гипотезы, если с ростом объема
выборки его мощность
стремится к 1.
contaminated
distribution
смешанное распределение
Рассмотрим несколько
генеральных совокупностей, подчиняющихся каждая своему распределению, и
следующую двухэтапную схему: Сначала мы выбираем совокупность, которой будет
принадлежать очередное наблюдение, затем производим наблюдение. Если “потерять”
информацию из первого этапа – "забыть" совокупность, к которой принадлежит
каждое наблюдение, распределение полученной выборки окажется смесью
распределений.
Распределение
вероятностей совокупностей, а также параметры каждого отдельного
распределения вместе называются параметрами смеси.
Например, артериальное
давление, измеренное в группе мужчин, может быть нормальным, в группе женщин –
также нормальным, однако, если параметры (средние и дисперсии) этих
распределений различны, то совместное распределение не будет нормальным.
Смесь двух нормальных распределений с одинаковым средним, но разными
дисперсиями, когда только меньшая часть значений берется из распределения с
большей дисперсией, часто называют загрязненным нормальным распределением. Хвост
такого распределения тяжелее, чем у нормального. Если доля значений из
распределения с большей дисперсией достаточно мала, загрязненное нормальное
распределение будет выглядеть как нормальное распределение с выбросами. В
подобной ситуации полезно бывает выделить выбросы в отдельную подвыборку.
См. смесь
распределений.
contingency
coefficient
коэффициент сопряженности
Термин относится к анализу таблиц
сопряженности. Является мерой
связи между переменными строк и столбцов. Изменяется между 0 и 1, значение
основывается на статистике
хи-квадрат. На некоторых таблицах не достигает значения 1.
contingency table
таблица
сопряженности
Таблица (ТС), каждая клетка
которой соответствует элементу кросс-табуляции.
В случае двух факторов клетки ТС располагают так, чтобы клетки одной строки
соответствовали одному и тому же значению одного фактора, а клетки одного
столбца – одному и тому же значению другого фактора; говорят, что уровни одного
фактора расположены по строкам, а другого – по столбцам. Размерность таких
таблиц часто обозначают r c, где r – количество уровней
фактора, соответствующего строкам, c – столбцам.
c, где r – количество уровней
фактора, соответствующего строкам, c – столбцам.
В случае трех
факторов удобно считать, что ТС состоит из совокупности ТС, каждая из которых
соответствует значению третьего фактора, являясь при этом (условной) ТС первых
двух факторов. Можно, конечно, построить ТС и для большего числа факторов.
В
каждой клетке ТС стоит количество элементов соответствующей клетки
кросс-табуляции.
Если велико количество уровней факторов, тем более, если
велико количество факторов, ТС – не слишком удобный способ представления данных
для их визуального анализа.
Для проверки гипотезы о независимости факторов,
по которым построена кросс-табуляция, используется критерий
независимости хи-квадрат Пирсона. Для таблиц 22 (два фактора, по два уровня у каждого)
используется также точный
критерий Фишера .
Общий метод анализа таблиц сопряженности –
лог-линейный анализ.
continuous scale
числовая шкала
Интервальная
шкала или шкала
отношений.
См. тж. шкала
измерений.
continuous variable
непрерывная
переменная
Переменная, измеренная в одной из числовых
шкал.
Примерами таких переменных являются: высота, вес, температура,
количество сахара в соке, время пробега в милях.
Антоним: дискретная
переменная.
correlation
корреляция
Когда говорят,
что две случайные переменные коррелированны, имеют в виду, как правило, что они
друг с другом как-то связаны.
Стандартной мерой связи переменных является коэффициент
корреляции. Следует, однако, помнить, что он измеряет лишь силу линейной
связи и лишь в случае, когда обе переменные числовые.
См. тж. мера
связи.
correlation
coefficient
коэффициент корреляции
Коэффициент корреляции – это
число, заключенное между -1 и 1, которое измеряет силу линейной связи двух
случайных переменных. Положительное значение коэффициента корреляции означает,
что с ростом одной из переменных другая также растет, с убыванием одной из них
убывает и другая. Отрицательное значение означает, что с ростом одной из
переменных другая убывает, с убыванием одной из них другая растет. Коэффициент
корреляции, равный нулю, означает, что между нашими переменными отсутствует
линейная связь.
Обратите внимание: даже если коэффициент корреляции равен 1
по абсолютной величине и, следовательно, наши переменные функционально связаны
(линейно), ничего нельзя сказать о причинно-следственной связи между ними.
В
статистической практике в ходу два коэффициента корреляции: для числовых
переменных используется коэффициент
корреляции Пирсона , для ранговых – коэффициент
корреляции Спирмена. Предложенный Кендаллом коэффициент ранговой корреляции
почему-то почти не употребляется.
count
встречаемость
Количество m
появлений случайного события в данной последовательности испытаний.
См. тж.
частота.
count table
таблица встречаемостей
См. таблица
частот.
covariance
ковариация
Недовычисленный
коэффициент
корреляции. В практической статистике практически не используется. Имеется,
правда, ковариационный анализ.
Приведу, все-таки, его определение для
любителей теории. Совместный центральный момент порядков 1 и 1: 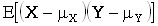 .
Выборочная несмещенная оценка вычисляется согласно формуле
.
Выборочная несмещенная оценка вычисляется согласно формуле 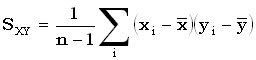 , где n –
число наблюдений,
, где n –
число наблюдений, 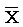 и
и 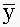 – средние
арифметические.
– средние
арифметические.
covariate
ковариата
В логистической
регрессии ковариатами принято называть независимые переменные, предикторы.
Гораздо более изощренную сущность это понятие обозначает в дисперсионном
анализе.
Ковариата – это переменная, которая может влиять на взаимосвязь
между изучаемыми переменными, однако сама по себе интереса не представляет. Как
и разбиение на блоки и стратификация, ковариата часто используется для контроля
изменчивости, не связанной с изучаемыми переменными. Ковариата может быть
дискретным фактором, как эффект блока, или непрерывной переменной, как
переменная X в ковариационном анализе. Например, анализируя, связь
демографических факторов (возраст, пол, образование и т.д.) с тарифом заработной
платы, месячные заработки сначала надо скорректировать, чтобы учесть (то есть
удалить соответствующие эффекты) количество отработанных часов, которое и будет
ковариатой в нашем примере
Заметим, что некоторые используют термин
ковариата, объединяя все переменные, которые могут повлиять на переменную
отклика, включая как основные переменные (предикторы), так и вторичные, которые
мы называем ковариатами.
Следует признать, что всем этим не исчерпываются
возможные значения термина.
Cramer's V
V Крамера
Еще одна мера
связи между переменными строки и столбца таблицы
сопряженности. Изменяется между 0 и 1, основана на статистике
хи-квадрат. В отличие от коэффициента
сопряженности всегда способна принять значение 1.
critical region
критическая область
При построении критерия мы разбиваем совокупность возможных значений статистики
критерия на две части так, что если наблюденное значение статистики попало в
одну из них, которая и называется критической областью, мы отвергаем нулевую
гипотезу и принимаем альтернативную,
в противном же случае мы говорим, что у нас нет оснований отвергнуть ее.
Таким образом, критическая область – это совокупность значений статистики
критерия, которые “говорят”, что нулевую гипотезу следует отвергнуть.
Эта
область выбирается так, чтобы было выполнено следующее условие: если нулевая
гипотеза верна, вероятность того, что значение статистики попадет в
критическое множество, меньше выбранного уровня
значимости.
Пример. При проверке нулевой гипотезы
H0(![]()
![]()
![]() 0) о среднем нормального
распределения с известным стандартным отклонением
0) о среднем нормального
распределения с известным стандартным отклонением 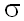 при альтернативе
H1(
при альтернативе
H1(![]() <
< ![]() 0) используют, как
правило, выборочное
среднее – статистику .
0) используют, как
правило, выборочное
среднее – статистику .
Критическая область критерия – это множество значений статистики, меньших
 , где n – объем выборки;
, где n – объем выборки; 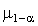 – (1-)-квантиль
нормированной нормальной случайной величины. Если рассчитанное значение меньше A, гипотеза
H0 отвергается, в противоположном случае не отвергается
(статистики избегают говорить "принимается").
– (1-)-квантиль
нормированной нормальной случайной величины. Если рассчитанное значение меньше A, гипотеза
H0 отвергается, в противоположном случае не отвергается
(статистики избегают говорить "принимается").
См. статистический
критерий, критическое
значение.
critical value
критическое значение
Как правило статистика
критерия одномерна, а критическая
область простирается либо от - до -x, либо от x до
+, либо
является объединением двух этих лучей, т.е. является дополнением отрезка
[-x, x]. В подобных случаях x называют критическим
значением.
Критическое значение зависит от выбранного уровня
значимости и от того, является ли критерий одно- или двусторонним.
См.
критическая
область, p-значение,
наблюденная
значимость.
cross-tabulation
кросс-табуляция
Разбиение выборки на группы в соответствии с значениями двух или более
дискретных переменных. К одной группе относятся наблюдения с одинаковыми
значениями переменных, которые в подобных случаях часто называют факторами.
Примечание. Расположим значения одной переменной вертикально, другой –
горизонтально. В полученной матрице первую переменную часто называют переменной
строки (ее значения задают строки матрицы), вторую – переменной столбца. Если
элементами матрицы являются объемы выборок соответствующей кросс-табуляции,
матрица называется таблицей
сопряженности. Похожая матрица фигурирует в двухфакторном дисперсионном
анализе.
cumulative count
накопленная
(кумулятивная) встречаемость
Количество членов множества наблюдений,
имеющих значения, которые не превосходят (меньше или равны) заданного значения.
См. тж. накопленная
частота.
cumulative frequency
polygon
полигон накопленных частот
Ломаная линия, получаемая при
соединении точек, лежащих по оси абсцисс на верхних границах каждого класса, а
по оси ординат - либо накопленных
встречаемостей, либо накопленных
частот.
Обратите внимание: в обоих случаях принято говорить о полигоне
частот.
cumulative relative
frequency
накопленная (кумулятивная) частота
Накопленная
встречаемость, деленная на общее число наблюдений. Иногда ее выражают в
процентах.
cyclical component
циклическая
компонента
Чтобы лучше понять поведение временного ряда, мы выделяем
его основные характеристики. Одной из таких характеристик является циклическая
компонента. Описательные методы можно распространить на прогноз (предсказание)
будущих значений.
В недельных или месячных данных циклическая компонента
описывает любые регулярные колебания.
Это не сезонная компонента, изменения
которой подчиняются некоторому "естественному" циклу.
См. тж. временные
ряды, тренд,
сезонность,
нерегулярная
компонента .
degrees of freedom
степени свободы;
число степеней свободы
Параметр 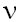 распределения хи-квадрат, а также
распределения хи-квадрат, а также 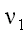 ,
, 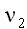 – параметры F-распределения принято
называть их степенями свободы.
– параметры F-распределения принято
называть их степенями свободы.
Примечание. Название связано с числом
оцененных по этой выборке параметров. В общем, количество степеней свободы равно
объему
выборки минус число параметров.
dependent variable
зависимая
переменная
Переменная, изменчивость которой мы стремимся объяснить
влиянием одной или нескольких независимых переменных. Различие между зависимой и
независимыми переменными обычно покоится на содержательных соображениях.
Синонимы: критериальная переменная, отклик.
design matrix
матрица плана
Спецификация, выраженная в виде матрицы, определенных эффектов и комбинаций
эффектов, исследуемых анализом.
Термин из дисперсионного
анализа и планирования
экспериментов.
dichotomous variable
дихотомическая
переменная
Переменная, имеющая только две категории. Например, пол
(мужской, женский).
См. тж бинарная
переменная.
difference
дискретная производная;
разностная операция
Популярный и эффективный метод удаления тренда
временного
ряда . Позволяет лучше видеть закономерности, лежащие в основе поведения
временного ряда.
Примечание. Эпитет "дискретная" часто опускают и говорят просто о производной временного ряда.
discordant
рассогласованные
Пара
наблюдений с двумя (по меньшей мере) порядковыми переменными, значения которых
на первом наблюдении одно меньше, а другое больше, чем на втором. Вот пример
рассогласованной пары:
X1 X2
10 100
20 50
Антоним: согласованные.
discrete scale
дискретная шкала
Одна из шкал
измерений: номинальная
или ранговая.
discrete variable
дискретная
переменная
Переменная, значения которой измерены в одной из дискретных
шкал. Значения таких переменных принято называть
градациями.
Ср. непрерывная
переменная.
dispersion
рассеяние
То же, что и разброс.
distribution function
функция распределения
Функция, задающая
для любого значения х вероятность того, что случайная величина
Х меньше или равна х; то же в виде формулы: F(x) =
Pr{X x}.
Пример. Функция
распределения переменной вес дает для каждого возможного значения веса
вероятность того, что он не превосходит этого значения.
distribution-free test
свободный от
распределения критерий
Критерий, распределение статистики которого не
зависит от того, как распределены наблюдения. Ясно, что подобные критерии не
существуют, и приведенную фразу нельзя считать определением – ее следует считать
лишь метафорой, пожеланием. На практике часто ограничиваются слабой зависимостью
распределений статистики критерия и наблюдений, причем смысл эпитета "слабая"
сильно зависит от контекста.
Пример. Критерий Колмогорова-Смирнова,
проверяющий гипотезу о том, что наблюдения из двух заданных рядов распределены
по одному и тому же неизвестному распределению.
dot plot
точечная диаграмма
То же, что и
диаграмма типа «стебель-с-листьями»
(«опора-и-консоль»).
dummy variables
индикаторные
переменные
Бинарные переменные, которые применяются для представления
дискретных
переменных, когда их нужно использовать в регрессионных моделях. Дискретная
переменная с k градациями кодируется (k-1)-й индикаторной
переменной.
Существуют две стандартных схемы кодирования значений дискретных
переменных:
entity
объект
Статистическая
единица .
См. тж. item.
Примеры объектов:
error of the first kind
ошибка
первого рода
Ошибка, состоящая в том, что мы отвергаем нулевую гипотезу
(поскольку статистика
принимает значение, принадлежащее критической
области), в то время как нулевая гипотеза верна.
Примечание. Ее часто
называют ошибкой I-го типа, а иногда – ошибкой типа "пропуск
цели".
error of the second kind
ошибка
второго рода
Ошибка, состоящая в том, мы не отвергаем (принимаем)
нулевую гипотезу (поскольку статистика принимает значение, не принадлежащее к
критической области), в то время как она неверна.
Примечание. Ее часто
называют также ошибкой II-го типа, а иногда – ошибкой типа
"ложная тревога".
estimate
оценка
Этим термином обозначают
несколько близких, но неодинаковых, понятий, каждому из которых соответствует
свой английский термин.
Прежде всего, оценка (estimator) – это функция,
алгоритм, словом, способ получить по выборке число (estimate), которое мы
объявляем значением неизвестного параметра. Сам процесс перехода от выборочных
данных к оценке называется оцениванием (estimation), или снова оценкой.
Оценки параметров совокупности иногда обозначают специальным символом,
«шапкой», чтобы отличить их от истинного значения. Например, так: – истинное значение
параметра, 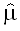 –
его оценка по выборке. Впрочем, столь же часто для истинных значений параметров
используют греческие буквы, а для оценок – их латинские соответствия.
–
его оценка по выборке. Впрочем, столь же часто для истинных значений параметров
используют греческие буквы, а для оценок – их латинские соответствия.
Пример
Обычной оценкой (estimator) среднего является
(X1+X2+...+Xn)/n, где n –
объем выборки, а X1,X2,...,Xn –
выборка. Если результатом вычислений на некоторой выборке окажется значение 5,
то 5 будет оценкой (estimate) среднего.
estimator
оцениватель
См. оценка.
estimation
оценивание
См. оценка
.
expectation
математическое ожидание
Для дискретной случайной величины Х, принимающей значения
xi с вероятностями pi,
математическое ожидание, если оно существует, задается формулой 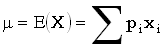 , где суммирование ведется по всем
значениям xi, которые может принимать случайная величина
Х.
, где суммирование ведется по всем
значениям xi, которые может принимать случайная величина
Х.
Для непрерывной случайной величины Х, имеющей
плотность f(x), математическое ожидание, если оно существует,
определяется формулой 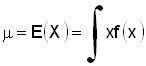 ,
где интеграл берется по всему интервалу (интервалам) изменения Х.
,
где интеграл берется по всему интервалу (интервалам) изменения Х.
expected frequency
ожидаемая
встречаемость
Встречаемости, предсказываемые («ожидаемые») используемой
моделью.
Пример. В задачах анализа
таблиц сопряженности стандартной является гипотеза о независимости, согласно
которой ожидаемая частота в клетке (i, j) равна произведению 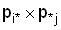 , где
, где 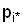 и
и  – маргинальные частоты по i-й строке и
j-му столбцу.
– маргинальные частоты по i-й строке и
j-му столбцу.
expected value
ожидаемое значение
То же, что и математическое
ожидание статистики. Предполагается, что если объем выборки стремится к
бесконечности, то среднее
значение статистики стремится к ее математическому ожиданию.
experiment design
планирование
экспериментов
Целая наука, цель которой – получить наиболее надежные
выводы наиболее дешевым (во всех смыслах этого слова) способом.
experimental unit
статистическая
единица
Статистическая единица – элемент подлежащей изучению
генеральной совокупности.
См. тж. наблюдение.
Полный синоним: sampling
unit.
exponential
distribution
экспоненциальное распределение
Распределение
вероятностей непрерывной случайной величины X, которая может
принимать любое значение от 0 до +, функция плотности которой равна 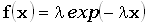 при x0 и параметре
при x0 и параметре 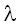 >0.
>0.
Примечание. Рассматривают также
чуть более общее распределение вероятностей, задаваемое формулой 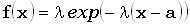 , где xa.
, где xa.
exponential
smoothing
экспоненциальное сглаживание
Метод построения нового
временного ряда, менее иррегулярного; про все подобные методы говорят, что они
сглаживают.
Он позволяет получить более ясное представление о закономерностях, лежащих в
основе этого ряда. Используется также для прогнозирования значений ряда; в этом
качестве применим для краткосрочных (на 1-2 шага) прогнозов..
extrapolation
экстраполяция
Предсказание значения переменной за пределами интервала анализа. Термин
применяется, как правило, при анализе временных рядов для коротких промежутков
времени. Количественное предсказание далекого будущего, как правило, менее
полезно; более полезны качественные прогнозы, они применяются для указания на
необходимое изменение характера процесса.
Пример. Предположим, что в 1 января 1975 года рост молодого человека был равен 1.20 м, а 1 января 1976 года – 1.40 м. Оценим его рост на 1 января 1997 года. Легко посчитать, что за год он вырастет еще на 0.20 м и на 1 января 1977 года его рост будет равен 1.60 м. Наше рассуждение, однако, предполагает, что он продолжит расти с той же скоростью. В конце концов это предположение необходимо нарушится – ведь иначе к 1980 году он станет гигантом.
factor
фактор
Фактор – это подлежащий
исследованию группирующий признак. Например, при испытании лекарств на крысах,
факторами могут служить пол крысы и/или вид принимаемого
лекарства. Термин употребляется, как правило, в областях, связанных с дисперсионным
анализом. Однофакторный дисперсионный анализ рассматривает отдельный
классифицирующий фактор (например, принимаемое лекарство), многофакторный –
сразу несколько факторов (например, и пол, и лекарство).
false negative
ложно отрицательный
Ложно отрицательное заключение при проверке гипотезы состоит в том, что мы
объявляем интересующую нас гипотезу ложной, когда на самом деле она истинна.
Другими словами, когда мы допускаем ошибку
первого рода.
false positive
ложно положительный
Ложно положительное заключение при проверке гипотезы состоит в том, что мы
объявляем интересующую нас гипотезу истинной, когда на самом деле она ложна.
Другими словами, когда мы допускаем ошибку
второго рода.
F-distribution
F-распределение
Распределение
вероятностей непрерывной случайной величины, принимающей значения между
0 и +, плотность которой равна 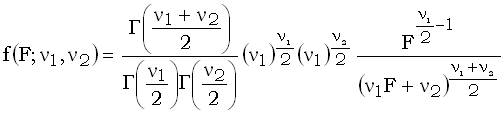 ,
,
где F0, , =1,2... – параметры; Г –
гамма-функция.
Примечания.
, в
котором делимое и делитель поделены на свои числа степеней свободы. Число степеней
свободы числителя равно , а
знаменателя . В таком порядке и
записываются числа степеней свободы случайной величины с распределением
F.
Fisher's exact test
точный критерий
Фишера
Точный критерий Фишера для таблицы
сопряженности 22 используется при проверке гипотезы о
независимости переменной строки и переменной столбца. В отличие от критерия
хи-квадрат, в котором уровень
значимости рассчитывается на основе асимптотического распределения, в точном
критерии используется для этой цели точное, в данном случае – гипергеометрическое,
распределение вероятностей.
five-number summary
пяти-числовая
сводка
Один из способов краткого представления выборки, предложенный
Дж.Тьюки. Состоит (не ожидали?) из 5 чисел: двух крайних значений (максимального
и минимального), нижнего и верхнего квартилей и медианы.
5-числовую сводку
можно представить на диаграмме, известной как ящик
с усами.
См. тж. ящичковая
диаграмма .
fractile
фрактиль
См. квантиль.
frequency
частота
Частота появления
случайного события – это отношение m/n числа m появлений
этого события в данной последовательности испытаний (его встречаемость)
к общему числу n испытаний.
Термин частота
используется также в значении встречаемость. В старинной книжке
Дунина-Барковского и Смирнова была сделана попытка развести эти два значения, и
для отношения они предложили термин частость. К сожалению, они
использовали термин частота в значении
встречаемость. В общем, их предложение не прижилось.
frequency
distribution
распределение частот; частотное распределение
Выборочная оценка плотности распределения. Связь между значениями признака и
встречаемостями или частотами его значений, которую, видимо, удобнее всего
представлять в виде таблицы
встречаемостей..
Примечание. Эту оценку часто представляют графически в
виде гистограммы,
столбиковой
диаграммы или как диаграмму
“стебель-с-листьями”.
frequency table
таблица частот
Таблица частот – способ обобщения множества данных. В ней для каждого
возможного значения указывается, сколько раз оно появляется в выборке, т.е.
фактически строят таблицу
встречаемостей. Таблицу часто превращают в истинную таблицу частот, добавляя
в нее проценты встречаемостей.
Таблица частот применяется для дискретных,
номинальных и ранговых данных. Конечно, ее можно использовать и для непрерывных
данных, если предварительно разбить их на группы.
F-test
F-критерий;
критерий Фишера
Критерий, статистика которого подчиняется F-распределению,
если нулевая гипотеза верна.
Примечание. Этот критерий применяется,
например, для (см. дисперсионный
анализ):
gamma
distribution
гамма-распределение
Распределение
вероятностей непрерывной случайной величины X, которая может
принимать любое значение между 0 и +, плотность которого задается формулой
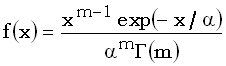
где
x0, а параметры
m и
оба больше 0.
Гамма-функция определяется соотношением  .
.
Примечания.
определяет
форму распределения. При m=1 гамма-распределение превращается в экспоненциальное
распределение.
. geometric mean
геометрическое среднее
Статистика вида  . Часто используется как мера центральной
тенденции для распределений с положительной асимметрией. Из средней школы
читатель, надеюсь, помнит: то же значение можно получить потенцированием среднего
арифметического логарифмов наблюденных значений.
. Часто используется как мера центральной
тенденции для распределений с положительной асимметрией. Из средней школы
читатель, надеюсь, помнит: то же значение можно получить потенцированием среднего
арифметического логарифмов наблюденных значений.
Примечание.
Произведение наблюдений является достаточной статистикой для гамма-распределения,
скошенного вправо.
goodness of fit of a
distribution
качество подгонки распределения
Мера соответствия между
наблюдаемым распределением и либо теоретическим распределением выбранным a
priori, либо подобранным по результатам наблюдений.
goodness of fit test
критерий
согласия
Критерии согласия проверяют гипотезу о совпадении наблюденной
эмпирической функции распределения с теоретической, постулируемой, функцией
распределения.
Примеры.
grouping
группировка
Переход к новой
(иногда виртуальной) переменной. Ее градации определяют категории, которые
являются объединениями категорий объектов, соответствующих градациям исходной
переменной.
grouping variable
группирующая
переменная
Номинальная переменная, используемая для разбиения
совокупности наблюдений на группы, подлежащие сравнению или более глубокому
изучению.
Ср. группировка
.
heteroscedasticity
гетероскедастичность
Неоднородность дисперсии.
Антоним: гомоскедастичность.
histogram
гистограмма
Гистограмма – это
способ графического представления распределения числовых (непрерывных) данных,
часто используемый в разведочном анализе данных для иллюстрации основных
характеристик распределения. Диапазон возможных значений переменной делится на
отрезки, задающие разбиение выборки на классы, или группы. Каждой группе на
гистограмме соответствует прямоугольник, длина которого равна диапазону значений
в заданной группе, а площадь пропорциональна числу наблюдений в этой группе.
Примечание. Гистограмма годится только для числовых переменных. Как правило,
она используется для больших множеств данных (>100 наблюдений), когда не
хотят строить диаграммы
ствол-лист. Гистограммы помогают выявить необычные наблюдения (выбросы) и
пропуски в множестве данных.
Сравните со столбиковой
диаграммой.
homogeneity of
variance
однородность дисперсии
Равенство дисперсий переменной,
подсчитанных в пределах разных групп. Является стандартным требованием в таких,
например, методах, как регрессионный
и дисперсионный
анализы.
Синоним: гомоскедастичность.
Антоним: гетероскедастичность.
homoscedasticity
гомоскедастичность
См. однородность
дисперсии.
hypergeometric
distribution
гипергеометрическое распределение
Дискретное
распределение вероятностей, задаваемое функцией  , где
x=max(0,M-N+n),...,max(0,M-N+n)+1,..., min(M,n), параметры
N=1,2,..., M=0,1,2,...,N, n=1,2,...,N и
, где
x=max(0,M-N+n),...,max(0,M-N+n)+1,..., min(M,n), параметры
N=1,2,..., M=0,1,2,...,N, n=1,2,...,N и 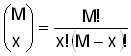 .
.
Примечание. Это распределение возникает как распределение
вероятностей числа успехов в выборке объема n, взятой без
возвращения из генеральной совокупности (популяции) объема N,
содержащий M успехов.
independence
независимость
Две
случайные величины X и Y независимы, тогда и только тогда,
когда для их функций распределения выполнено
F(x, y) = F(x,) F(, y) = G(x)H(y), где F(x,) = G(x) и
F(,
y) = H(y), – маргинальные функции распределения случайных величин
X и Y соответственно.
Примечания.
h(y), где g(x) и h(y)
– маргинальные функции плотностей X и Y соответственно.
Pr(Y = yi) для всех пар
(xi, yi).
independent variable
независимая
переменная
Переменная, используемая для предсказания значений,
объяснения, зависимой переменной.
Синонимы: предиктор,
объясняющая переменная.
См. тж. зависимая
переменная.
interaction
взаимодействие
Ситуация,
в которой направление и/или величина взаимосвязи между двумя переменными зависит
от значений одной или более других переменных, изменяется в соответствии с ними.
Например, в многофакторном дисперсионном анализе факторы A и
B взаимодействуют, если эффект фактора A зависит от уровня
фактора B. Например, при испытании таблеток на крысах, между
факторами пол и обработка существует взаимодействие, если
эффект обработки не одинаков для самцов и самок.
При наличии взаимодействия
простые аддитивные методы не годятся; следовательно, взаимодействие иногда можно
считать отсутствием аддитивности.
Синонимы: неаддитивность, эффект обусловливания, эффект сопряженности.
inter-quartile range
(IQR)
интерквартильная широта
Одна из мер разброса
, или рассеяния,
данных. Равняется разности между верхним и нижним квартилями.
IQR – это ширина интервала, содержащего средние 50% выборки, так что он тем
меньше, чем меньше рассеяние,
причем на него слабо влияют выбросы, т.е. он является робастной характеристикой.
Пример.
Пусть дана выборка (уже в виде вариационного ряда): 2 3 4 5 6 6
6 7 7 8 9. Ее верхний квартиль равен 7, ее нижний квартиль равен 4, наконец, IQR
равняется 7 - 4 = 3.
interval scale
шкала интервалов
Непрерывная числовая шкала с нефиксированным началом. Для такой шкалы
осмысленна операция вычитания, но не сложения. Пример интервальной шкалы -
время: разность двух дат вполне понятна, сумме двух дат трудно придумать
разумную интерпретацию.
Нелинейные преобразования шкалы влияют на результаты
аналитических методов для интервальной шкалы.
Синоним: интервальная шкала.
См. тж. шкала
измерений.
intervening variable
мешающая
переменная
Переменная, определяемая как предиктор одной или более
зависимых переменных, и одновременно предсказываемая одной или несколькими
независимыми переменными.
irregular component
иррегулярная
(стохастическая) компонента
Для лучшего понимания временного ряда мы
выделяем его основные характеристики. Одной из таких характеристик является
нерегулярная компонента (или «шум»).
Иррегулярная компонента – это то, что
остается после исключения всех остальных компонент ряда (тренда, сезонной и
циклической).
См. тж. временной
ряд, тренд,
циклическая
компонента , сезонная
компонента .
item
объект
То, что допускает индивидуальное
описание и рассмотрение, статистическая
единица .
Синоним: entity.
Примеры объектов:
Kendall's tau b
тау-b Кендалла
Мера связи, используемая при анализе таблиц
сопряженности (не менее чем ранговых) признаков. Меняется между -1 и +1,
основана на количествах согласованных
и несогласованных
пар наблюдений. Конечно, производится коррекция, если какие-то значения
оказываются совпадающими.
Kendall's tau
тау-c Кендалла
Еще
одна мера связи, используемая при анализе таблиц
сопряженности (не менее чем ранговых) признаков.
См. тж. тау-b.
kurtosis
эксцесс
Эксцесс указывает,
насколько плотность распределения более заострена, или наоборот, приплюснута по
сравнению с плотностью нормального распределения, он является мерой тяжести
хвостов распределения относительно нормального. У распределений с отрицательным
эксцессом хвосты легче, чем у нормального, и, соответственно, плотность
“острее”. У распределений с положительным эксцессом более тяжелые хвосты.
Примечание. Поскольку эксцесс является, фактически, моментом третьего
порядка, его оценка крайне неустойчива.
Laplace-Gauss
distribution
распределение Лапласа-Гаусса
Нормальное
распределение.
leverage
балансировка
Индикатор,
позволяющий судить о “важности” отдельных наблюдений для регрессионной задачи,
сравнивать относительное воздействие переменных на подогнанную модель.
levels within factor
уровни
фактора
Градации признака, используемого в качестве фактора.
Если факторов несколько, комбинации уровней образуют ячейки.
linear
линейный
Вид связи между
переменными, дающий на графике для двух переменных прямую линию. Взаимосвязь
линейна, если изменение зависимой переменной при изменение независимой
переменной одинаково при всех значениях зависимой переменной, короче, если ее
можно выразить линейной
функцией.
linear function
линейная функция
Линейная комбинация значений одной или более переменных: ![]() .
.
Иногда нелинейные зависимости можно
привести к линейному виду преобразованием предикторов 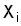 (например, уравнение
(например, уравнение  можно линеаризовать, заменив
можно линеаризовать, заменив 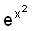 на u: мы получим линейную функцию
на u: мы получим линейную функцию 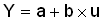 ), либо отклика Y (например, чтобы
линеаризовать
), либо отклика Y (например, чтобы
линеаризовать 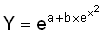 , нам нужно взять вместо
Y отклик
, нам нужно взять вместо
Y отклик  , после чего нам останется
линеаризовать только что рассмотренное уравнение
, после чего нам останется
линеаризовать только что рассмотренное уравнение 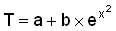 ).
).
linear predictor
линейный предиктор
Тот, который входит в модель линейно.
Рекомендую этот термин не использовать.
linear regression
линейная
регрессия
В линейной регрессии модельное (теоретическое, предсказанное)
значение отклика является линейной
функцией значений одного или более предикторов.
location
положение
См. центральная
тенденция.
logistic regression
логистическая регрессия
В ситуации, когда
отклик – дихотомическая переменная, логистическая регрессия позволяет оценить
зависимость вероятности 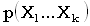 одной из градаций
отклика от совокупности предикторов X1,…,Xk.
Логистическая зависимость ищется в виде =
одной из градаций
отклика от совокупности предикторов X1,…,Xk.
Логистическая зависимость ищется в виде =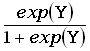 , где
Y=b0+b1X1+…bkXk.
То же самое можно выразить другими словами: ищется линейная регрессионная модель
для логит-преобразованиявероятности
.
, где
Y=b0+b1X1+…bkXk.
То же самое можно выразить другими словами: ищется линейная регрессионная модель
для логит-преобразованиявероятности
.
В последние
годы появилась логистическая регрессия и для номинальных откликов с числом
градаций, большим двух.
logit
transformation
логит-преобразование
Логарифм отношения вероятности
p того, что событие произойдет, к вероятности того, что оно не
произойдет:  .
.
log-normal
distribution
лог-нормальное (логарифмически нормальное) распределение
Случайная величина, логарифм которой подчиняется нормальному распределению.
marginal expectation
маргинальное
математическое ожидание
Математическое ожидание маргинального
распределения случайной величины
marginal frequency
distribution
маргинальное распределение частот
Выборочная оценка
плотности маргинального
распределения вероятностей. Распределение частот подмножества
k<K показателей из многомерного распределения частот K
показателей, когда остальные K-k переменных принимают любые из своих
областей значений.
Примечание. Для K=2 показателей маргинальное
распределение частот можно получить, добавляя к каждому значению или классу
значений рассматриваемого показателя соответствующие частоты (или относительные
частоты) остальных показателей.
Пример. В частотном распределении трех
показателей X, Y и Z имеются
marginal probability
distribution
маргинальное (частное) распределение вероятностей
Распределение
вероятностей подмножества k<K из множества K
случайных величин, причем остальные K-k случайные величины принимают
любые значения в соответствующих множествах возможных значений.
Пример. Для
распределения вероятностей трех случайных величин X, Y и
Z имеются
matched samples
спаренные выборки
См. парные
выборки.
mean
среднее
Одна из мер центральной
тенденции – математическое
ожидание.
Часто используется также, как синоним среднего
арифметического.
mean deviation
среднее отклонение
Мера разброса
: среднее абсолютных величин отклонений от некоторого фиксированного значения,
взятых по модулю.
Примечания.
mean root square
deviation
среднее квадратичное отклонение
То же, что и стандартное
отклонение.
Примечание. Говорят также "среднеквадратичное отклонение".
Кроме того, в том же смысле используют термины квадратичная
ошибка, средняя квадратичная ошибка.
measure of association
мера
связи
Индикатор, величина которого указывает силу связи между двумя
переменными. Для непрерывных переменных примером может служить коэффициент
корреляции Пирсона . Для дискретных данных меры связи основываются
исключительно на таблица сопряженности. Примеры: коэффициент
сопряженности, V
Крамера, тау-b
и тау-c
Кендалла, гамма и ро Спирмена.
В тех случаях, когда индикаторами являются
статистики обычных критериев (таких как хи-квадрат
Пирсона, F-критерий),
отличие заключается в использовании их значений.
median
медиана
Медиана выборки – это
точка, по обе стороны которой располагается одинаковое количество элементов
выборки. Если объем выборки нечетен и равен 2n+1, то медиана равна
элементу вариационного
ряда с номером 2n. Если объем выборки четен и равен
2n, то медиана лежит между элементами вариационного ряда с номерами
n и n+1; как правило, в таких случаях медианой считают
среднее арифметическое этих двух значений.
Медиана распределения – это точка
m, определяемая аналогичным условием: вероятность того, что случайная
величина примет значение, не превосходящее m, равна 1/2.
Другими словами, медиана – это квантиль уровня p=0.5.
Примечания:
method of least squares
метод
наименьших квадратов (МНК)
Распространенный метод оценивания
параметров. Ищутся оценки, минимизирующие сумму квадратов разностей между
модельными (предсказанными) и наблюденными значениями.
method of maximum
likelihood
метод максимума правдоподобия
Общий метод вычисления
оценок параметров. Ищутся оценки, которые максимизируют функцию правдоподобия
выборки, равную произведению значений функции распределения для каждого
наблюденного значения данных.
Метод максимального правдоподобия лучше
работает на больших выборках, где он, как правило, дает оценки с минимальной
дисперсией. На маленьких выборках оценки максимального правдоподобия часто
оказываются смещенными.
Метод максимального правдоподобия дает те же оценки
наклона
и свободного члена линейной регрессии, что и метод
наименьших квадратов, при условии, что отклик подчиняется нормальному
распределению. При этом оценки оказываются несмещенными с минимальной
дисперсией. В общем случае, однако, оценки максимального правдоподобия и метода
наименьших квадратов могут не совпадать.
mid-range
средина размаха
Среднее
арифметическое между наибольшим и наименьшим наблюденными значениями
количественного показателя.
Примечание. Как термин, так и статистика сейчас
практически не используются.
missing value
пропущенное значение
Если значение переменной по какой-либо причине неизвестно для данного
объекта, мы называем это значение пропущенным. Важно учитывать,
что значение может оказаться пропущенным по разным причинам: потеряно (из-за
ошибок кодировки), неприменимо (количество беременностей у мужчины), недоступно
(респондент отказался отвечать) и т.д. Часто необходимо различать эти ситуации и
тогда для них вводят специальные коды.
В современных статистических пакетах
имеется возможность объявить некоторое количество градаций переменной кодами
пропущенных значений. Имеется два основных способа исключения пропущенных
значений из анализа: исключение объекта целиком (exclude cases listwise), если
значение хотя бы одной переменной оказалось пропущенным, и попарное исключение
переменных (exclude cases pairwise), когда исключаются только те объекты, у
которых оказалось пропущенным значение хотя бы одной из переменных, участвующих
в текущем вычислении. Например, попарное исключение часто применяют при
вычислении матрицы ковариаций, хотя известно, что это может привести к
вырожденной матрице и, чтобы избежать этого, лучше пользоваться исключением
целиком.
Некоторые методы анализа требуют отсутствия пропущенных значений. В
подобных ситуациях применяют те или способы восстановления пропущенных значений:
например, заменяют их средними.
mixed model
смешанная модель
Факторы
в дисперсионном анализе могут быть как фиксированными, так и случайными. Если
все факторы фиксированы, это модель типа I, если же они случайны, это модель
Типа II. Модель со смешанными эффектами обычно называют моделью Типа III.
Многофакторные модели дисперсионного анализа, содержащие по крайней мере
один фиксированный и по крайней мере один случайный эффект, называют смешанными.
Рандомизированный блок также обычно является смешанной моделью, так как
представляющий интерес фактор обычно имеет хотя бы один фиксированный эффект.
Иногда термин смешанная модель применяется к моделям
дисперсионного анализа, в которых есть по крайней мере один фактор повторных
измерений (внутренний), и по крайней мере один группирующий фактор.
mixture distribution
смесь
распределений
Смесь распределений – это распределение, в котором каждое
наблюдение подчиняется одному из нескольких распределений. Например, когда мы
проводим измерения артериального давления в некоторой популяции, наблюдения для
мужчин могут представлять нормальное распределение, для женщин тоже нормальное,
но с другим средним и дисперсией, и вместе они не будут нормально распределены.
Синоним: смешанное
распределение.
mode
мода
Точка, где плотность вероятности
непрерывной случайной величины достигает максимума. Иногда используют для
характеристики дискретных распределений вероятностей.
Примечания.
moving average
smoothing
сглаживание скользящими средними
Один из способов сглаживания
временного ряда. При нечетной ширине окна соответствующая формула выглядит
особенно просто: 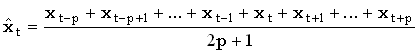
multicollinearity
мультиколлинеарность
Два предиктора коллинеарны, если сильна линейная связь между ними; в этом
случае их можно представить в виде линейной комбинации друг друга. Когда число
предикторов может быть больше двух, говорят о мультиколлинеарности. Она
делает проводимые в линейной регрессии вычисления неустойчивыми, а то и
невозможными, поскольку в этом случае матрицы плохо обусловлены. Кроме того, она
может вызвать неожиданно большие оцененные стандартные ошибки для коэффициентов
при предсказывающих переменных.
multinomial
distribution
мультиномиальное распределение
Распределение
вероятностей k дискретных случайных величин X1,
X2,...Xk, такое, что ![]()
где
x1,x2,…,xk – целые числа, такие, что
x1+x2+...+xk =n, а параметры
pi0
(i=1,2,…,k) удовлетворяют соотношению  .
.
Примечание.
При k=2
мультиномиальное распределение является обычным биномиальным
распределением.
multiple comparisons
множественные
сравнения
См. проблема
множественных сравнений.
multiple regression
множественная
регрессия
Множественная регрессия – это регрессионная модель, согласно
которой моделируемое значение переменной Y выражается как функция
одной или нескольких предсказывающих переменных (X). Чаще всего
встречается множественная линейная регрессия – линейная регрессионная модель с
более чем одной переменной.
multi-sample problem
проблема
множественных сравнений
Проверяя гипотезу, мы задаем уровень
значимости , ограничивающий вероятность ошибки
1-го рода . Что мы можем сказать в ситуации, когда нам придется проверять
гипотезу много раз подряд?
Скажем, что в составной процедуре, заключающейся
в проведении N проверок гипотезы, мы допускаем ошибку 1-го рода, если
мы допустили ее хотя бы в одной из N проверок. Проблема состоит в
том, что в этой ситуации вероятность ошибки 1-го рода не равна .
Чему же она равна? Что
можно сказать о вероятности ошибки 1-го рода составной процедуры? Только то, что
она заведомо больше , причем растет с ростом N. Придуманы
разнообразные способы корректировки уровня значимости отдельных проверок,
позволяющие гарантировать нужный уровень значимости составной процедуры. Один из
простейших методов – корректировка
Бонферрони.
multivariate normality
многомерная
нормальность
Вид распределения для двух и более переменных, при котором
распределение одной переменной нормально для каждой категории и всех комбинации
категорий других переменных.
См. тж. нормальное
распределение.
multivariate distribution
function
многомерная функция распределения
Функция, задающая
совместное распределение
вероятностей нескольких случайных величин Х, Y,…; для любого
набора значений x, y,… она равна вероятности того, что случайная
величина Х меньше или равна x и при этом случайная
величина Y меньше или равна y, и т.д. Вот формула:
F(x,y,...) = Pr[Xx; Yy;…].
negative binomial
distribution
отрицательное биномиальное распределение
Распределение
вероятностей дискретной случайной величины X такое, что 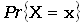 =
= 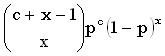 , где x=0,1,2,..., а
c>0 и 0<p<1 – параметры.
, где x=0,1,2,..., а
c>0 и 0<p<1 – параметры.
Здесь  =
= 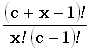 . Подробнее.
. Подробнее.
Примечания
nominal scale
номинальная шкала
Шкала
измерений, дающая коды или метки, которые позволяют говорить о
тождественности или нетождественности объектов, а, значит, и разбивать их
на классы одинаковых, но не подразумевающая никаких количественных взаимосвязей
и/или их упорядочивания. На выводы о переменных, измеренных в номинальной шкале,
не влияют взаимно однозначные преобразования кодов (“Как розу ты ни назови…”).
nominal variable
номинальная
переменная
Переменная, измеренная в номинальной
шкале.
Например, в некотором множестве данных мужчинам можно присвоить
код 0, а женщинам – код 1; семейное положение обозначить буквой Д для состоящих
в браке, и Н для одиноких.
nonlinear regression
нелинейная
регрессия
В нелинейной регрессии предполагается, что зависимость
отклика от предикторов не является линейной
функцией предикторов.
non-parametric
tests
непараметрические критерии
Большая часть статистической теории
построена для семейств распределений с пространствами параметров малой
размерности. Таковы экспоненциальное семейство и его частный случай – семейство
нормальных распределений, задаваемое своими средним и дисперсией (быть может,
многомерными).
Однако, придуманы критерии и для более сложно устроенных
семейств – скажем, семейства всех распределений с симметричной плотностью. Такие
критерии обычно и называют непараметрическими. Их применимость, конечно,
значительно шире, чем у их параметрических собратьев. Зато там, где
параметрические критерии применимы, их мощность
выше, чем у непараметрических.
Часто непараметрические критерии
отождествляют с критериями,
свободными от распределения.
normal distribution
нормальное
распределение
Распределение
вероятностей непрерывной случайной величины X с плотностью
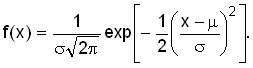
где - <x<+, – математическое
ожидание, а –
стандартное
отклонение.
Подробнее.
Примечания.
normal probability plot
график нормальной вероятности
График
с значениями выборки по оси X и довольно хитро вычисляемыми
квантилями нормального распределения по оси Y. Если данные
подчиняются нормальному распределению, точки графика ложатся близко к прямой
линии.
Синонимы: график на нормальной вероятностной бумаге, Q-Q
(квантиль-квантиль) график.
normality
нормальность
См. нормальное
распределение.
null hypothesis
нулевая гипотеза
Утверждение о распределении в целом или об одном или нескольких его
параметрах, которое предполагается подвергнуть статистической проверке.
Выбирается таким образом, чтобы можно было вычислить распределение статистики
критерия, что позволяет по заданному уровню
значимости построить критическую
область (критическое множество) критерия. Альтернативная
гипотеза – противоположное утверждение. Если наблюденное значение статистики
критерия попадает в критическую область, нулевая гипотеза (стандартное
обозначение H0) отвергается, отбрасывается, и,
соответственно, принимается альтернативная гипотеза (стандартные обозначения
H1 и 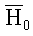 соответственно). В противном случае у нас нет
оснований отвергнуть нулевую гипотезу.
соответственно). В противном случае у нас нет
оснований отвергнуть нулевую гипотезу.
Примеры.
случайной величины X меньше заданного
значения 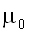 (не меньше этого значения). Стандартная запись – H0:
< и
H1: .
(не меньше этого значения). Стандартная запись – H0:
< и
H1: .
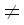 p2.
p2.
observation
наблюдение
Источник
имеющихся данных. Практически во всех статистических пакетах задается строкой
значений переменных.
Синоним: case.
См. тж. статистическая
единица .
observed frequencies
наблюденные
встречаемости
В задачах с таблицами
сопряженности наблюденные встречаемости
– те, которые оценены по нашей выборке. При вычислении критерия хи-квадрат
термин наблюденная встречаемость используется для описания фактических данных
таблицы сопряженности.
Наблюденные встречаемости сравнивают с ожидаемыми, и
их значимое различие говорит о том, что модель, выраженная ожидаемыми
встречаемости, не полностью объясняет данные.
observed significance
наблюденная
значимость
См. p-значение.
observed value
наблюденное значение
Значение данного показателя (признака), полученного в результате
эксперимента, измерения, вычисления и т.п.
one-sided confidence
interval
односторонний доверительный интервал
Пусть T –
функция от наблюдаемых значений (статистика),
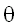 – параметр
генеральной совокупности. Если вероятность Pr{T } = 1-, то интервал от наименьшего возможного
значения до
T – это односторонний доверительный интервал для с доверительным
уровнем 1-. Аналогично, если Pr{T
– параметр
генеральной совокупности. Если вероятность Pr{T } = 1-, то интервал от наименьшего возможного
значения до
T – это односторонний доверительный интервал для с доверительным
уровнем 1-. Аналогично, если Pr{T![]() } = 1-, то интервал от T до наибольшего
возможного значения – это также односторонний доверительный интервал
для с
доверительным уровнем 1-.
} = 1-, то интервал от T до наибольшего
возможного значения – это также односторонний доверительный интервал
для с
доверительным уровнем 1-.
Примечание. Граница T доверительного интервала – это статистика и потому, вообще говоря, принимает разные значения от выборки к выборке.
one-sided test
односторонний критерий
Критерий, в котором используемая статистика одномерна, а критическая область
включает множество значений, меньших критического значения (или множество
значений, больших критического значения).
Примечание. Как правило, мощность
одностороннего критерия выше, чем двустороннего.
order statistics
порядковая
статистика
Когда наблюдения в выборке располагаются в порядке
возрастания их величин (говорят также представлены в виде вариационного
ряда ), каждое из упорядоченных значений – это значение случайной величины,
называемой порядковой статистикой; k-е значение называется
статистикой k-го порядка. Более общо, всякая статистика, основанная
на порядковых статистиках в этом узком смысле, также называется порядковой.
Пример.
Для выборки объема N примерами порядковых статистик
являются крайние значения: минимальное (статистика 1-го порядка) и
максимальное (статистика N-го порядка). Квантили также вычисляются по
порядковым статистикам.
ordered sample;
set of order
statistics
вариационный ряд
Выборка, упорядоченная по возрастанию
значений.
ordinal scale
шкала порядка
Шкала
измерений, дающая коды или метки, которые позволяют располагать объекты в
некотором порядке, но не допускающая никаких арифметических операций над кодами.
На выводы о переменных, измеренных в порядковой, или ранговой, шкале, не влияют
монотонные преобразования кодов.
Поскольку количество допустимых операций
над кодами здесь шире, чем для номинальной шкалы, говорят, что у ранговой шкалы
более высокий шкальный тип.
Синоним: ранговая
шкала
ordinal variable
порядковая
переменная
Переменная, измеренная в шкале
порядка . Очень известным примером является шкала Рихтера для силы
землетрясений. Отметки в школе – еще один пример порядковых данных. Обратите
внимание: в одних странах высшей оценкой является 5, в других – 1.
Синоним:ранговая переменная
outlier
выброс
См. выскакивающее
наблюдение.
outlying case
выскакивающее наблюдение
Наблюдение, далеко отстоящее от центра распределения.
Выброс может быть
результатом ошибки измерения, в этом случае он искажает данные, влияя на
итожащие статистики, скажем, на среднее.
В противном случае выброс чрезвычайно важен, так как указывает на необычное
поведение изучаемого процесса. Поэтому перед проведением анализа следует
внимательно изучить все выбросы. Их нельзя просто выбросить без предварительного
рассмотрения.
paired samples
парные выборки
Две
выборки набираются таким образом, что с каждым наблюдением одной выборки
сопоставлено наблюдение другой выборки; сопоставление основывается, как правило,
на совпадении значений одной или более заданных характеристик (признаков).
Примерами парных выборок являются повторные измерения одного и того же объекта,
и наблюдения за мужчинами и женщинами, составляющими семейные пары. Парные
выборки отличаются от независимых, в которых подобное соответствие оказывается
скорее мешающим.
parameter
параметр
Параметр – это
величина, обычно неизвестная и, следовательно, подлежащая оценке, которая
представляет определенную характеристику генеральной совокупности. Например, математическое
ожидание распределения – это параметр, характеризующий центральную
тенденцию.
Параметр совокупности имеет фиксированное значение. По
имеющейся у нас выборке мы можем посчитать значение статистики, используемой для
оценки параметра. Например, среднее выборки дает информацию о среднем
генеральной совокупности, из которой была сделана эта выборка. Поскольку выборка
случайна, это значение также случайно.
Параметры часто обозначают греческими
буквами (например, ), а
соответствующие статистики – латинскими (например, s).
Pearson correlation
coefficient
коэффициент корреляции Пирсона
Показатель связи двух
случайных величин, равный отношению их ковариации к произведению их стандартных
отклонений:  . Выборочная оценка
этого параметра, конечно, вычисляется так:
. Выборочная оценка
этого параметра, конечно, вычисляется так:  , где Sxy – ковариация
X и Y; Sx и Sy
- стандартные отклонения X и Y соответственно.
, где Sxy – ковариация
X и Y; Sx и Sy
- стандартные отклонения X и Y соответственно.
Примечания
percentile
процентиль
Процентили – это
величины, делящие выборку данных на сто групп, содержащих (по возможности)
равное количество наблюдений. Например, 30% данных имеют значение, меньшее 30-го
процентиля.
См. тж. квантиль.
pie chart
круговая диаграмма
Круговая
диаграмма – это один из способов визуализации дискретных
данных. Представляет собой круг, разделенный на сегменты, каждый из которых
соответствует определенной категории. Площадь каждого сегмента пропорциональна
числу наблюдений в этой категории.
Является аналогом гистограммы.
Poisson distribution
распределение
Пуассона
Распределение
вероятностей дискретной случайной величины X, принимающей
значения x=0,1,2,…, задаваемое формулой 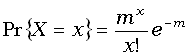 , где параметр m>0.
, где параметр m>0.
Подробнее.
Примечания.
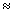 m.
m. pooled estimate of the
variance
объединенная оценка дисперсии
Объединенная оценка дисперсии
– это взвешенное среднее оценок дисперсий каждой из выборок. Если все выборки
взяты из одной генеральной совокупности, объединенная оценка дисперсии точнее
отдельных оценок.
Используется при проверке гипотез о различии выборок.
population
генеральная совокупность
Генеральная совокупность – это (как правило, лишь воображаемое) полное
собрание объектов (людей, животных, растений или вещей), являющееся источником
данных. Она представляет все множество статистических единиц (группу
интересующих нас предметов).
Приведенный пассаж нельзя, конечно, считать
сколько-нибудь полноценным определением.
Информацию о генеральной
совокупности мы получаем, изучая выборки из нее; из каждой совокупности можно
сделать много разных выборок. По выборке мы получаем информацию об интересующих
нас параметрах совокупности. Например, выборочное
среднее дает информацию о среднем всей совокупности.
Важно, чтобы перед
формированием выборки исследователь тщательно и полно определил генеральную
совокупность, а также способ извлечения выборки. Здесь всегда произносят
заклинание: выборка должна быть репрезентативной.
Примечание. Для случайной
величины распределение
вероятностей рассматривается как определение генеральной совокупности этой
случайной величины.
power function of a test
функция
мощности критерия
Зависимость мощности критерия от скалярного параметра
при фиксированном уровне значимости критерия.
Синоним: оперативная
характеристика критерия.
power of test
мощность критерия
Мощность критерия – это вероятность правильно отвергнуть нулевую
гипотезу, то есть отвергнуть ее, когда она неверна. Равна 1 минус
вероятность ошибки
второго рода . Иногда ее называют специфичностью.
Мощность зависит от уровня
значимости, используемой в критерии статистики,
и от альтернативной
гипотезы.
Как правило, мощность возрастает с ростом объема
выборки. К сожалению, она, как правило, убывает с убыванием уровня
значимости.
predictor
предиктор
Переменная,
выбранная в качестве объясняющей, независимой.
probability
вероятность
Действительное число в интервале от 0 до 1,
характеризующее случайное событие.
Примечания.
probability density
function
плотность вероятности
Производная (если она существует) от
функции распределения 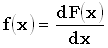 .
.
Примечание. Часто f(x)dx называют "элементом вероятности".
probability
distribution
распределение вероятностей случайной величины
Функция,
задающая вероятность того, что случайная величина, примет какое-либо заданное
значение или будет принадлежать заданному множеству значений.
Говорят, что
случайная величина X подчиняется дискретному распределению, если область ее
значений дискретна. Для такой случайной величины распределение вероятностей для
каждого значения хi задает вероятность pi
= Pr{X=xi} того, что случайная величина равна
хi.
Примечание. Обратите внимание: понятия случайная
величина и распределение вероятностей фактически тождественны.
probability mass
function
функция распределения масс
Распределение
вероятностей дискретной случайной величины.
p-value
p-значение
Если критическая
область одномерна и и простирается от x до +, т.е. задается критическим
значением, то перед проверкой гипотезы мы можем не искать x, а
использовать функцию распределения статистики критерия. Действительно, пусть
p – вероятность того, что значение статистики больше наблюденного
значения f, т.е. значения статистики, вычисленного по имеющейся
выборке, – уровень
значимости. Тогда из p< вытекает x<f, т.е. f
при этом условии попадает в критическую область и, значит, нулевую гипотезу
следует отвергнуть.
Это рассуждение легко приспособить и к случаю, когда
доверительная область простирается от - до -x, и к случаю, когда
доверительной областью является дополнение отрезка [-x,x].
Часто
вычислить функцию распределения гораздо проще, чем находить критические
значения.
Синоним: наблюденная
значимость.
qualitative
качественный
Измеренный в
дискретной – номинальной или ранговой – шкале.
qualitative variable
качественная
переменная
Дискретная (номинальная или ранговая) переменная.
quantile
квантиль
Число
xp, p [0,1], удовлетворяющее соотношению
Pr(X<xp)pPr(Xxp), называется p-квантилью
(или квантилем – мнения грамотеев расходятся).
[0,1], удовлетворяющее соотношению
Pr(X<xp)pPr(Xxp), называется p-квантилью
(или квантилем – мнения грамотеев расходятся).
Процентиль определяется
соответственно при значении p, выраженном в процентах.
Примечание. Если функция распределения F(x)равна p во
всем интервале между двумя последовательными значениями случайной величины, то
любое значение в этом интервале можно рассматривать как p-квантиль.
Если же у F(x) нет интервалов постоянства, то p-квантиль
xp – это корень уравнения F(x) = p.
Примерами квантилей являются квартили
и процентили.
quantitative
количественный
Антоним
к слову qualitative, которое здесь переведено как качественный
(не имеет отношения к каким бы то ни было потребительским свойствам).
quartile
квартиль
Квартили – это набор
квантилей
для p=0.25, 0.5, 0.75. Их оценками (квартилями эмпирического
распределения) являются величины, делящие выборку данных на четыре группы,
содержащие (по возможности) одинаковые количества наблюдений.
Когда говорят
о квартилях, обычно имеют в виду верхний q3 и нижний q1
квартили; второй квартиль q2 равен медиане.
Нижний квартиль q1 – это значение, ниже которого в упорядоченном
множестве данных находится четверть данных, а верхний квартиль q3 –
это значение, выше которого в упорядоченном множестве данных находится четверть
значений. Разность q3 - q1, интерквартильный
размах, является робастной мерой рассеяния.
quintile
квинтиль
Набор квантилей
для p = 0.2, 0.4, 0.6, 0.8. Квинтили делят выборку на 5 равных
частей.
random variable
случайная величина
Мы говорим о случайной величине X, когда у нас есть множество
 и функция, задающая
вероятности совокупности
и функция, задающая
вероятности совокупности  подмножество этого множества. Множество называется
множеством значений случайной величины X, элементы
–
событиями; вероятность события А обозначается
Pr(A) или P(A). Случайная величина, которая может
принимать только отдельные значения, называется дискретной.
Случайная величина, которая может принимать любые значения из конечного или
бесконечного интервала, называется непрерывной.
подмножество этого множества. Множество называется
множеством значений случайной величины X, элементы
–
событиями; вероятность события А обозначается
Pr(A) или P(A). Случайная величина, которая может
принимать только отдельные значения, называется дискретной.
Случайная величина, которая может принимать любые значения из конечного или
бесконечного интервала, называется непрерывной.
Термин
случайная величина используют чаще, когда речь идет о теоретических аспектах
статистики. Когда же говорят об анализе реальных данных, прикладной статистике,
чаще пользуются термином переменная,
добавляя при необходимости эпитет "случайная".
randomization
рандомизация
Процесс
перемешивания, в результате которого множество объектов
располагается в случайном порядке. Термин употребляется, как правило, в связи с
планированием экспериментов.
range
размах
Разность между наибольшим и
наименьшим наблюденным значением количественного показателя.
rank
ранг
Номер наблюдения в вариационном
ряде. Обратите внимание: когда вместо исходных величин мы переходим к их
рангам, мы, тем не менее, пользуемся интервальной, а не ранговой шкалой.
Пример. В выборке 11, 23, 32, 39, 55 наблюдению 11 соответствует ранг 1,
наблюдению 23 - ранг 2 и т.д.
Ранги оказываются полезными для построения
непараметрических ранговых критериев.
Ранговая корреляция
Спирмена или Кендалла – другие полезные применения рангов.
rank scale
ранговая шкала
См. шкала
порядка .
rank test
ранговый критерий
Критерии, в
которых вместо исходных данных используются их ранги.
ratio scale
шкала отношений
Шкала
измерений, для значений которой осмысленна операция вычитания и у которой
имеется естественное «начало». Пример – измерения веса: суммы весов не поддаются
интерпретации, естественным началом служит ноль. Для такой шкалы вполне
осмысленно говорить, что одно значение в полтора раза больше другого.
rectangular
distribution
прямоугольное распределение
Равномерное
распределение.
regression analysis
регрессионный
анализ
Совокупность идей и методов, используемых при построении
уравнений, связывающих непрерывный отклик с одним или несколькими непрерывными
предикторами. Наиболее разработанными являются, конечно, методы построения
линейных уравнений. «Вариантами» являются методы, предназначенные для
множественных откликов и/или дискретных предикторов.
regression coefficient
коэффициент
регрессии
Коэффициент при независимой переменной в уравнении регрессии.
regression curve
кривая регрессии
Для двух случайных величин регрессия X на Y (часто
говорят также Y по X) – это функция y =
f(x), дающая для каждого возможного значения x случайной
величины X условное математическое ожидание Y. Графическое
представление этой функции и называется кривой регрессии.
Если функция
f линейна, f(x) = a*x+b, то кривая регрессии Y
по X представляет собой прямую, а регрессию называют простой
линейной. В этом случае, коэффициент линейной регрессии Y по
X – это коэффициент a перед x (угловой
коэффициент, наклон)
в уравнении линии регрессии.
Примечание. Для оценки коэффициентов линейной
регрессии по выборке, состоящей из n пар наблюдений показателей
X и Y, используют, как правило, метод
наименьших квадратов.
regression surface
поверхность
регрессии
Для трех случайных величин X, Y и
Z регрессией X и Y на Z называют
функцию z = f(x,y), которая для каждой пары значений переменных
x и y дает математическое ожидание Z при
X=x и Y=y. Часто то же самое называют
регрессией Z по X
и Y. Графическое изображение этой функции называют
поверхностью регрессии.
Если функция fлинейна,
f(x,y)=a*x+b*y+c, то поверхность регрессии представляет собой
плоскость, а регрессия называется линейной. В этом случае
коэффициент линейной регрессии Z по X – это коэффициент
a перед x в уравнении плоскости регрессии.
Ясно, как
обобщить приведенное определение на случай более трех случайных величин.
relative frequency
частота
Встречаемость,
деленная на общее число событий или наблюдений. Иногда говорят,
относительная частота.
repetition
повторение
Термин,
обозначающий выполнение статистического исследования несколько раз одним и тем
же методом на одной и той же совокупности при одинаковых условиях.
Примечание. Термин употребляется, в основном, в дисперсионном
анализе и планировании
экспериментов.
residual
остаток, невязка
Разность между
наблюденным значением отклика и значением, вычисленным (предсказанным) в
соответствии с рассматриваемой моделью. Например, в t-критерии для
двух непарных выборок, предсказанным значением измерения будет среднее выборки,
из которой оно взято, так что остаток будет равен наблюденному значению минус выборочное
среднее.
Анализ остатков – песня, без которой не обходится ни одно
исследование.
resistant
резистентный;
устойчивый
Статистика называется резистентной, если ее значение
не изменяется существенным образом при сколь угодно большом, однако относящемся
к малой части данных, произвольном изменении. Например, медиана
является резистентной мерой положения, а среднее не является, так как среднее
можно существенно изменить, сделав очень большим отдельное значение данных, а
медиану нет.
См. тж. робастный.
response
отклик
То же, что и зависимая
переменная.
robust
робастный
Робастность
статистического метода – его свойство сохранять работоспособность за пределами
предположений, при которых он выведен.
Так, статистический критерий может
быть робастным относительно уровня
значимости, т.е. выдаваемые им наблюденные значимости будут близки к
истинным даже при (не слишком сильных) отклонениях от исходных допущений. Он
может быть робастным относительно мощности,
в том смысле, что он сохраняет мощность при подобных отклонениях.
Примечание. Еще совсем недавно робастность считалась панацеей от всех
статистических трудностей. В настоящее время она превратилась в одну из метафор,
характеризующих статистические методы.
run
серия
В рядах наблюдений качественного
показателя – повторение одного и того же значения признака называется “серией”.
В рядах наблюдений количественного показателя - последовательный набор
значений, которые монотонно возрастают или монотонно убывают, называют
“растущей” или “падающей” серией, соответственно. Конечно, рассматривают и серии
равных.
Примечание. Еще раз – это понятие применимо лишь к выборкам,
расположенным в каком либо интерпретируемом порядке. Пример подобной выборки –
временной
ряд.
running medians
smoothing
медианное сглаживание
Метод сглаживания, аналогичный
сглаживанию скользящими средними. У этого метода та же цель – выявить тренд.
sample
выборка
Выборка – это группа
статистических единиц, отобранная из большей группы, генеральной
совокупности. Изучая выборку, мы надеемся сделать разумные заключения о
генеральной совокупности.
sample mean
выборочное среднее
Арифметическое среднее наблюдений, составляющих выборку, т.е. сумма всех
наблюдений, деленная на их количество:
(x1+x2+…+xn)/n. Является одной из
наиболее частых оценок среднего совокупности. Это мера положения, часто
обозначается 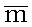 .
.
Величина среднего зависит от всех значений данных, поэтому среднее может
оказаться плохой мерой положения для асимметрично распределенных данных или при
наличии выбросов..
См. тж. ожидаемое
значение.
sample size
объем выборки
Количество
элементов в выборке.
sample variance
выборочная дисперсия
Выборочная дисперсия является мерой разброса, или рассеяния, множества
данных.
Сумма квадратов отклонений от среднего, деленная на число, на
единицу меньшее количества наблюдений. Например, для n наблюдений
x1,x2,…,xn с выборочным средним выборочная дисперсия
равна: 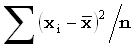 .
.
sampling distribution
выборочное
распределение
Оценка функции распределения по имеющейся выборке. Для
каждого t находим число nt членов вариационного
ряда выборки, располагающихся слева от t. Значение выборочного
распределения в точке t равно nt/n, где
n – объем выборки.
sampling error
ошибка выборки, выборочная
ошибка
Часть ошибки оценивания, обусловленная только тем фактом, что
объем выборки меньше, чем объем генеральной совокупности.
sampling unit
статистическая единица
То же, что и experimental
unit.
scale of measurement
шкала
измерений
Здесь шкала измерений указывает на природу предположений,
сделанных о свойствах переменной. На практике используются номинальная,
порядковая
и числовые
шкалы. Более тонкое разграничение числовых шкал практически не встречается
(скажем, шкалы отношений
или интервалов
упоминают, в основном, лишь в учебниках).
scatter plot
диаграмма рассеяния
Полезный способ визуализации множества двух- или трехмерных данных
(совместного распределения двух или трех переменных). На ней каждому наблюдению
соответствует одна точка, по осям откладываются значения переменных, точки на
диаграмме не соединены между собой.
Диаграмма рассеяния обычно выводится
перед вычислением коэффициента линейной корреляции или подгонкой регрессионной
линии.
Примеры.
Чем сильнее точки группируются вдоль прямой линии, тем
сильнее линейная взаимосвязь между двумя переменными (тем выше корреляция).
Если линия, вдоль которой группируются точки, идет от левого нижнего угла к
правому верхнему, взаимосвязь между двумя переменными положительная (прямая).
Если линия, вокруг которой группируются точки, идет от верхнего левого угла
к нижнему правому, взаимосвязь между двумя переменными отрицательная (обратная).
Если точки разбросаны по диаграмме случайным образом, между двумя
переменными нет взаимосвязи (очень низкая или нулевая корреляция).
Очень
низкая или нулевая корреляция может быть результатом нелинейной связи между
переменными. Если существующая взаимосвязь действительно нелинейна (точки
группируются вокруг некоторой, не прямой, линии), коэффициент корреляции не
является хорошей мерой силы этой взаимосвязи.
Диаграмма рассеяния показывает
также нелинейную взаимосвязь между переменными и наличие или отсутствие
выбросов.
Если мы имеем дело с большим количеством переменных, все возможные
диаграммы рассеяния можно представить одновременно в матрице диаграмм рассеяния.
seasonal component
сезонная
компонента
Один из способ описания временного ряда – разложение его на
компоненты: тренд,
периодическую, иррегулярную. Когда временная ось связана с датами, а период – с
месяцами или кварталами, периодическую компоненту называют сезонной. Часто ее
продолжают называть сезонной и при других периодах.
sensitivity of test
чувствительность
критерия
Единица минус уровень
значимости критерия.
sequence plot
график последовательности
Как правило, при статистическом анализе не учитывается порядок поступления
объектов в выборку. На графике последовательности по оси Y
откладывается значение переменной, а по оси X – порядковый номер
соответствующего наблюдения. График последовательности может помочь выявить
коррелированность последовательных наблюдений.
shape
форма
Говоря о форме распределения,
обычно имеют в виду форму его плотности (гистограммы). Рассуждения о форме часто
сопровождают оценками асимметрии
и эксцесса
рассматриваемого распределения, которые позволяют сравнивать его с нормальным.
significance level
уровень
значимости
Уровень значимости статистического критерия (его называют
также “альфа-уровень” и обозначают греческой буквой ) – это ограничение сверху на вероятность ошибки
первого рода (вероятность отвергнуть нулевую гипотезу, когда она на самом
деле верна). Типичные значения – 0.05, 0.01 и 0.001; часто эти значения выражают
в процентах.
significant result
значимый
результат
Как правило, некоторый статистический показатель называют
значимым, когда гипотеза о том, что он равен нулю, не принимается. Так, говорят
о значимом коэффициенте корреляции, значимом коэффициенте регрессии и т.п.
Когда гипотезу
о том, что значение коэффициента равно некоторому значению, не принимают, также
говорят о значимом отличии коэффициента от этого значения.
Пример.
При проверке нулевой гипотезы H0 ( ) о среднем нормального распределения при альтернативе
H1(
<),
используют, как правило, выборочное
среднее – статистику ![]() .
.
Если рассчитанное значение ![]() меньше
критического значения критерия, гипотеза H0 отвергается, в
противоположном случае не отвергается. Результаты проверки гипотезы иногда
выражают так: среднее выборки значимо выше/ниже на уровне 1-.
меньше
критического значения критерия, гипотеза H0 отвергается, в
противоположном случае не отвергается. Результаты проверки гипотезы иногда
выражают так: среднее выборки значимо выше/ниже на уровне 1-.
simple hypothesis
простая гипотеза
Гипотеза, которой соответствует единственное распределение совокупности.
skewness
асимметрия
Асимметрия – одна из
характеристик формы распределения. У скошенного вправо распределения значения
группируются слева от среднего и образуют длинный хвост справа от него.
Так
называемый коэффициент асимметрии положителен для скошенных вправо
распределений, равен нулю для симметричных, отрицателен для скошенных влево.
Распределения величин, ограниченных слева, как правило, скошены вправо
(таков, например, годовой доход).
Для выявления асимметрии полезно
использовать гистограммы, ящичковые диаграммы и графики на нормальной
вероятностной бумаге.
Чтобы симметризовать данные, их подвергают подходящему
преобразованию, например, данные с положительной асимметрией часто
логарифмируют.
slope
наклон
Для простой линейной регрессии
Y по X, выражаемой уравнением y = ax+b, –
коэффициент a.
smoothing
сглаживание; фильтрация
Сглаживание применяется для уменьшения иррегулярностей (случайных изменений)
временных рядов.
Распространенным методом сглаживания является сглаживание
скользящим средним, хотя не следует забывать и про другие. Способ сглаживания
определяется свойствами ряда и целями его обработки.
Somer's D
мера связи D Сомера
Мера
связи, применяемая при анализе таблиц
сопряженности. Меняется между -1 и 1, основана на числе согласованных
и несогласованных
пар наблюдений. Одна из переменных должна быть объявлена независимой, другая –
откликом. Обе переменные должны быть (по меньшей мере) порядковыми.
Конечно, производится коррекция, когда встречаются совпадения значений
переменных.
Spearman correlation
coefficient
коэффициент корреляции (Спирмена)
Непараметрическая мера
связи между двумя переменными, измеренными в порядковых
шкалах. Для всех наблюдений значения каждой из переменной ранжируются, после
чего вычисляется коэффициент
корреляции Пирсона между преобразованными переменными.
Примечания.
specificity of test
специфичность
критерия
Специфичность критерия – это единица минус его мощность,
т.е. его вероятность ошибки 2-го рода.
sphericity
сферичность
Представьте
себе эксперимент, в котором измерения проводятся для множества групп. Если
дисперсия разности между оцененными средними для любой из двух групп одинакова,
то говорят, что данные обладают свойством сферичности. Сферичность является
обычным требованием дисперсионного анализа при планах с повторными измерениями
или рандомизированных планах.
Более строгим условием является требование,
чтобы все корреляции между двумя различными группами имели одно и то же
значение. Это свойство называют составной симметрией. Из составной симметрии
следует сферичность, но не наоборот. Критерии сферичности обычно в
действительность основываются на проверке отсутствия составной симметрии.
spread
разброс
Обобщенное название
характеристик изменчивости распределения. Типичными мерами разброса являются дисперсия,
стандартное
отклонение, размах
и интерквартильная
широта.
standard deviation
стандартное
отклонение
Положительный квадратный корень из дисперсии 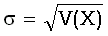 . Используется как мера разброса,
или рассеяния,
данных. Как правило, так же называется и выборочная оценка , которая обозначается буквой
s и вычисляется по формуле
. Используется как мера разброса,
или рассеяния,
данных. Как правило, так же называется и выборочная оценка , которая обозначается буквой
s и вычисляется по формуле  , где – среднее, n – объем выборки.
, где – среднее, n – объем выборки.
standard error
стандартная ошибка
Стандартное
отклонение статистики, в частности, выборочного распределения оценки. Как
правило, употребляется в выражениях типа "стандартная ошибка среднего" (которая
равна стандартному отклонению, деленному на корень квадратный из объема
выборки).
standardized
bivariate Laplace-Gauss distribution
нормированное двумерное распределение
Лапласа-Гаусса
То же, что и нормированное
двумерное нормальное распределение.
standardized
bivariate normal distribution
нормированное двумерное нормальное
распределение
Распределение
вероятностей пары нормированных нормальных случайных величин. Для пары
нормальных случайных величин (X, Y) с параметрами (, ) и (, ) соответствующие нормированные случайные
величины равны: 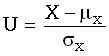 и
и 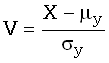 ,
,
а плотность вероятности равна:

где
- <u< + и - <v< +.
Параметр – коэффициент корреляции X и Y,
а также U и V.
Примечание. Ясно, как обобщить это
понятие на многомерное распределение более двух случайных величин, таких, что
маргинальное распределение любой их пары представимо в той же форме, что
приведена выше.
standardized
coefficient
нормированный коэффициент
В регрессионном анализе оценки
параметров (коэффициентов) регрессии называют нормированными, если процедура
применялась к нормированным переменным. Есть и более прямые способы получить
нормированные коэффициенты.
Такие коэффициенты часто больше “говорят” о
взаимодействии предикторов с откликом.
standardized
Laplace-Gauss distribution
стандартное распределение Лапласа-Гаусса
См. стандартное
нормальное распределение.
standardized normal
distribution
стандартное нормальное распределение
Распределение
вероятностей нормированной нормальной случайной величины U,
плотность распределения которой, равна 
при - <u<
+.
standardized variable
нормированная
переменная
Переход от переменной x к переменной 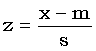 , где m –
среднее значений переменной x, а s – ее стандартное
отклонение, называется нормированием (часто – нормировкой) переменной
x, а результат, естественно, нормированной переменной z.
, где m –
среднее значений переменной x, а s – ее стандартное
отклонение, называется нормированием (часто – нормировкой) переменной
x, а результат, естественно, нормированной переменной z.
Примечание. Иногда говорят о "стандартизации", а также о
z-преобразовании и даже z-значениях переменной
x. Название восходит к стандартному
нормальному распределению N(0,1): ведь если x
подчиняется нормальному распределению, то для больших выборок ее нормировка
приводит к случайной величине z, подчиняющейся стандартному
нормальному распределению.
statistic
статистика
Статистика – это
функция элементов выборки. Дает информацию о неизвестных значениях параметров
генеральной совокупности. Например, среднее выборки является, как правило,
оценкой среднего совокупности, из которой была взята выборка.
Из генеральной
совокупности можно сделать много разных выборок, причем значение статистики в
общем случае будет меняться от выборки к выборке; другими словами, выборка
является случайной, а значит, случайной величиной является и статистика.
Например, выборочные средние для разных выборок из одной и той же совокупности
могут различаться между собой.
Статистики обычно обозначают латинскими
буквами (например, m и s), а оцениваемые ими параметры –
греческими, (например, и ).
Примечание. Статистика –
функция от случайных величин и потому тоже случайная величина. Это значит, что
ее значения различны от выборки к выборке. Значение статистики, получаемое при
использовании наблюдаемых значений, как их функция, может использоваться в
статистических проверках или как оценка параметра совокупности, такого как среднее
или стандартное
отклонение.
statistical coverage
interval
статистически накрывающий интервал
Интервал, для которого
можно утверждать с данным уровнем
доверия, что он содержит, по крайней мере, заданную долю определенной
совокупности.
Примечание. Если обе границы определены по статистическим
данным, то интервал – двусторонний. Если один из двух пределов представляет
собой бесконечность или ограничение по случайной величине, то интервал –
односторонний.
statistical coverage
limits
статистически покрывающие границы
Для двустороннего
статистически накрывающего интервала – нижняя и верхняя границы этого интервала.
Для одностороннего статистически накрывающего интервала – значение статистики,
ограничивающей этот интервал.
statistical
independence
статистическая независимость
Отсутствие связи между
переменными. Независимость двух непрерывных переменных часто ошибочно
отождествляют с равенством нулю их корреляции (ковариации), однако, это верно,
только если они подчиняются двумерному
нормальному распределению.
statistical inference
статистический
вывод
Искусство использовать информацию, содержащуюся в выборке, для
умозаключений (to draw conclusions) о свойствах генеральной совокупности, из
которой сделана эта выборка.
statistical measure
статистическая
мера, индикатор
Статистика
, значение которой мы интерпретируем как силу проявления интересующего нас
феномена. Примеры: сила взаимосвязи, вариабельность, уровень дохода. К
статистическим мерам относятся среднее, дисперсия, коэффициенты корреляции и
многие другие статистики. Статистические меры отличаются от статистических
критериев использованием, интерпретацией их значений.
statistical test
статистический
критерий
Статистический критерий состоит из следующих компонент: пара
гипотез – нулевая
и альтернативная,
статистика
критерия и уровень
значимости; по ним мы находим еще критическую
область.
Проверка гипотезы начинается с вычисления статистики критерия.
Если значение попадает в критическую область, мы отвергаем нулевую гипотезу и
считаем истинной ее альтернативу. В противном случае у нас нет оснований
отвергнуть нулевую гипотезу.
При проверке гипотезы мы можем допустить ошибку 1-го или 2-го рода .
statistics
статистика
Статистика –
научная дисциплина.
Статистические данные.
А также – функция
наблюдений.
stem-and-leaf plot
диаграмма
“стебель-с-листьями”, “ствол-лист”, "опора-и-консоль"
Придуманный
Дж.Тьюки способ представления выборки данных, измеренных в интервальной шкале.
Часто используется в разведочном анализе данных для иллюстрации основных
характеристик распределения данных в удобной и легкой для восприятия форме.
Диаграмма похожа на гистограмму, однако обычно более информативна для
относительно маленьких множеств данных (<100 точек). Помимо графика выдается
таблица, позволяющая с легкостью записать данные в порядке изменения их величин,
что бывает полезно для многих статистических процедур.
Мы можем сравнивать
разные множества данных посредством множественных диаграмм “стебель-с-листьями”.
Используя вплотную прилегающие диаграммы, мы можем сравнить значения одной и той
же характеристики в парных
выборках, например, частоту пульса после нагрузки у курящих и некурящих.
stratification
стратификация
То
же, что и группировка:
разбиение выборки на непересекающиеся группы. Отдельные группы при этом
называются стратами.
structural zeros
структурные нули
В таблице
сопряженности могут быть ячейки, в которые "теоретически" не может попасть
ни одно наблюдение. Нули в этих ячейках и называются структурными и это
обстоятельство нужно учитывать при построении модели.
Таблица сопряженности,
содержащая хотя бы один структурный нуль называется неполной таблицей. Критерий
независимости
хи-квадрат (Пирсона) и точный
критерий Фишера не предназначены для подобных таблиц.
Например, при
изучении заболеваемости раком в таблице сопряженности, образованной факторами
пол и тип рака, в ячейке для мужчин с раком яичников обязательно окажется 0
наблюдений, в то время как ожидаемое число мужчин с раком яичников не будет
равно 0, если среди наблюдений есть хотя бы один мужчина и хотя бы один случай
рака яичников.
Student`s test
критерий Стьюдента
Статистический критерий, в котором, в предположении нулевой гипотезы,
используемая статистика соответствует t-распределению (распределению
Стьюдента).
Примечание. Вот примеры применения этого критерия:
subpopulation
подсовокупность
Определенная часть (генеральной) совокупности
symmetry of
distribution
симметрия распределения
Плотность распределения
симметрична относительно среднего.
Многие стандартные статистические методы
годятся только для симметричных распределений. Поэтому асимметричные данные
часто стараются преобразовать так, чтобы привести к более или менее
симметричному виду.
t-distribution; Student`s
distribution
t-распределение; распределение Стьюдента
Распределение
вероятностей непрерывной случайной величины, плотность вероятности которого
задается формулой 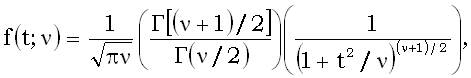
где - <t< + c параметром
=1,2,…; Г –
гамма функция.
Примечание. Распределение Стьюдента с степенями свободы – это дробь, в числителе которой –
нормированная нормальная случайная величина, а в знаменателе – положительное
значение квадратного корня из частного от деления случайной величины на ее число степеней свободы
. Числитель и знаменатель должны
быть независимы,
tail probability
“хвостовая”
вероятность
Как правило, является синонимом терминов p-значение,
наблюденная
значимость.
test of independence
критерий
независимости
Критерий независимости для таблиц сопряженности проверяет
гипотезу о том, что переменные строки и столбца независимы. К таким критериям
относится критерий
независимости хи-квадрат (Пирсона) и точный
критерий Фишера .
test statistics
статистика критерия
Статистика – функция, вычисляемая по наблюденной выборке. Соответственно,
статистика критерия – это статистика, используемая в статистическом критерии.
Если ее значение попадает в критическую
область, нулевая гипотеза отвергается.
Выбор статистики является важным
этапом в разработке критерия. Он определяется вероятностной моделью, описывающей
исследуемую ситуацию, и гипотезами – нулевой
и альтернативной.
tied
совпадающие
Так говорят о равных
значениях переменной. См. например, описание меры D
Соммера .
time series
временной ряд
Временной
ряд – это последовательность наблюдений, упорядоченных во времени (или
пространстве).
Если какое-нибудь явление наблюдают на протяжении некоторого
времени, имеет смысл представить данные в том порядке, в котором они возникали,
из-за того, в частности, что последовательные наблюдения могут быть зависимыми.
Временной ряд хорошо представлять на диаграмме рассеяния. Значения ряда
x откладывают по вертикальной оси, а время t по
горизонтальной, поскольку время – независимая переменная. Значение наблюдения в
момент t обозначают x(t) или xt.
Существует два типа временных рядов:
Примеры.
transformation
преобразование
Преобразование значений данных производится путем применения одной и той же
функции ко всем значениям переменной; важно то, что аргументами такой функции
могут являться только значения переменных текущего наблюдения.
Распространенными примерами таких операций являются: прибавление константы,
умножение на константу, взятие логарифма.
transformation to
normality
нормализующее преобразование
Преобразование, в результате
которого получается переменная, распределение которой более похоже на
нормальное, чем исходное.
Наиболее часто применяемыми преобразованиями
являются log(X),  , и 1/.
, и 1/.
trend component
тренд
Для лучшего
понимания временного ряда мы выделяем его основные характеристики. Одной из
таких характеристик является тренд.
Тренд это долговременное изменение
временного ряда. Это направление (тенденция к повышению или снижению) и скорость
изменения временного ряда, которые мы видим после исключения случайной ошибки и
циклических эффектов, когда наблюдаемые значения нанесены на график в порядке их
получения.
Бывает полезно моделировать тренд с помощью прямых линий,
полиномов и других кривых.
truncated distribution
усеченное
распределение
Говорят, что распределение усечено, когда оказывается,
что наблюдения не могут принимать все значения, допустимые для этого
распределения. Например, случайная величина, подчиняющаяся нормальному
распределению, может принимать любое значение между - и +. Если же ее значения ограничены
и, скажем, всегда больше 0, то говорят, что она подчиняется усеченному
нормальному распределению.
В современной речи этот термин почти не
встречается, поскольку его ценность ограничена – ведь необходимо еще указывать,
как “перераспределяются” вероятности. В итоге, усеченное, скажем, нормальное,
распределение оказывается очень не похожим на нормальное.
t-test
t-критерий
Критерий Стьюдента.
Примеряется для проверки гипотезы о равенстве двух средних нормально
распределенных выборок. Устойчив к умеренным отклонениям от нормальности, но
распределения должны оставаться симметричными.
two-sided confidence
interval
двусторонний доверительный интервал
См. доверительный
интервал.
two-sided test
двусторонний критерий
Критерий, в котором используемая статистика одномерна, а критическая область
состоит из множества значений, меньших первого критического значения, и
множества значений, больших второго критического значения.
Примечание. Выбор
между односторонним
и двусторонним критериями определяется альтернативной
гипотезой.
two-way table
таблица с двумя входами
Таблица, используемая для представления распределения двух дискретных
показателей. Ее строки и столбцы представляют, соответственно, значения или
классы первого и второго показателей. Если на пересечении строки и столбца
проставляется встречаемость,
соответствующая данной комбинации значений или классов, мы имеем дело с таблицей
сопряженности.
Примечание. Это понятие легко обобщить на случай более
двух показателей.
type I and type II error
ошибки
первого и второго рода
При проверке статистической гипотезы возможны
два вида ошибок.
Ошибка первого рода состоит в том, что мы объявляем нулевую
гипотезу ложной, когда на самом деле она верна. Выбирая уровень
значимости для статистического
критерия, мы ограничиваем значение вероятности ошибки первого рода. Уровень
значимости обычно обозначают греческой буквой (альфа); его типичные значения 0.05, 0.01 и 0.001.
Ошибка второго рода возникнет, если мы не отвергнем нулевую гипотезу, когда
она является ложной. Вероятность этой ошибки обычно обозначается греческой
буквой 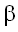 (бета), величина
1- называется мощностью
критерия. Греческие буквы используются в статистике и для других целей;
примеры: мера связи альфа Кронбаха и бета-распределение.
(бета), величина
1- называется мощностью
критерия. Греческие буквы используются в статистике и для других целей;
примеры: мера связи альфа Кронбаха и бета-распределение.
Вероятность ошибки первого рода зависит от компонент статистического
критерия. Обычно, при фиксированном уровне значимости, вероятность ошибки
второго рода снижается по мере того, как растет объем
выборки.
type I error
probability
вероятность ошибки I рода
Вероятность допустить ошибку
первого рода .
type II error
probability
вероятность ошибки II рода
Вероятность допустить ошибку
второго рода .
type III extreme value
distribution
распределение экстремальных значений типа III
См. распределение
Вейбулла .
unbiased estimate
несмещенная
оценка
Оценка параметра называется несмещенной, если ее ожидаемое
значение (математическое ожидание) равняется истинному значению параметра. В
противном случае оценка является смещенной.
unbiased estimator
несмещенная
оценка
Оценки со смещением,
равным нулю.
uniform
distribution
равномерное распределение
(1) Распределение
вероятностей непрерывной случайной величины, плотность вероятности которой
постоянна на конечном интервале [a,b] и равна нулю вне его.
(2)
Распределение вероятностей дискретной случайной величины X, такое что
Pr{X=xi}=1/n, где i=1,2,…,n.
Синоним: прямоугольное
распределение.
univariate frequency
distribution
одномерное распределение частот
Распределение частот
для единственного показателя (признака).
valid
комплектный
Про наблюдение, у
которого ни одно значение характеризующих его переменных не является пропущенным,
говорят, что оно комплектное.
Антоним: некомплектное
variance
дисперсия
Второй центрированный
момент сл.в. X, задаваемый формулой 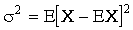 .
.
Несмещенная выборочная оценка дисперсии для выборки из n
наблюдений x1,x2,…,xn со средним
вычисляется
согласно формуле  .
.
См. тж. стандартное
отклонение.
variable
переменная
Характеристика
объекта исследования.
variate
случайная величина
Встречается
редко. Рекомендуется термин random
variable.
variation coefficient
коэффициент
вариации
Отношение стандартного
отклонения выборки к выборочному
среднему, s/m.
Коэффициент вариации измеряет разброс
множества данных как долю от их среднего. Часто выражается в процентах.
Конечно, не имеет смысла, когда среднее
распределения равно нулю.
violation of
assumptions
нарушение предположений
Все статистические методы
применимы лишь при некоторых предположениях о совокупности. Например, многие
критерии, требует, чтобы данные были выборкой из одного или нескольких
нормальных распределений; и/или чтобы дисперсии совокупностей были равны (гомоскедастичность).
Если предположения критерия нарушаются, результаты анализа могут оказаться
непригодными.
Weibull distribution
распределение
Вейбулла
Распределение
вероятностей непрерывной случайной величины X, функция
распределения которой задается формулой F(x) = 1 -
exp(-(x/b)c), где 0x < ![]() , b > 0;
c>0.
, b > 0;
c>0.
Подробнее.
Примечания.
weighted data
взвешенные данные
Переменная, значения которой являются сомножителями значений исследуемых
переменных. Другими словами, вместо значений xi
переменной, берутся произведения wixi, где
w – взвешивающая переменная.
Пример. Рассмотрим ситуацию, когда у
нас имеется много одинаковых наблюдений (в смысле, с одинаковыми значениями всех
рассматриваемых переменных). Вместо того, чтобы заводить, скажем, 100 одинаковых
наборов кодов, мы можем ввести лишь один и завести еще одну весовую, или
взвешивающую, переменную, значением которой для данного набора будет 100.
Веса применяют также, чтобы скомпенсировать разную “наполненность”
сравниваемых групп.
Говорят, что веса можно применять также для учета
относительной “важности” наблюдений.
within factor
межсубъектный фактор;
межобъектный фактор; группирующий фактор
В дисперсионном анализе с
повторными измерениями есть по крайней мере один фактор, измеряемый на каждом
уровне для каждого субъекта. Это внутренний (повторных измерений) фактор.
Например, в эксперименте, при котором каждый участник дважды выполняет одно и то
же задание, номер попытки представляет внутренним фактором. Кроме того, в модели
может быть фактор (факторы), такой, что каждому субъекту может соответствовать
только один его уровень. Факторы такого типа называют группирующими.
z-score
z-значение
Значение нормированной
переменной.
|
|
Дата последней модификации: 30 октября 2000 г.