
|
|
Автореферат
Решение систем ОДУ на системах SIMD машин
В современном мире больших скоростей и сверхбольших размеров создание любых сложных систем связано с большими
расчётами. Этих расчётов становится всё больше - размеры систем растут, а их количество, как и разнообразие,
всё увеличивается. Если ранее это были "строительства века", то теперь такие строительства возможны хоть и
раз в год - главное доказать их рациональность и перспективность.
Современные подходы к решению большинства расчётов - это описание системы любой сложности системой дифференциальных
уравнений, которые описывают все процессы в системе. Часто для западных специалистов такая система уже считается
решением - она отправляется в расчётные отделы или передается другим специалистам. У нас такая система называется
"моделью" или "задачей", и предполагается её решение как и всякой другой.
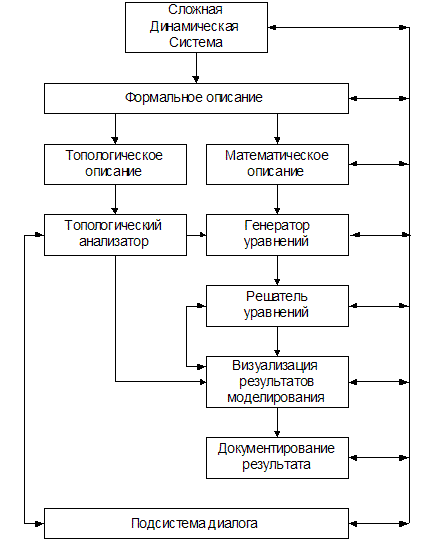 Конечно, современные, даже настольные, вычислительные системы позволяют решить большинство расчётных задач,
которые могут встретится на производстве. Но современная тенденция имитации очень больших систем (и излишняя,
с моей точки зрения), а также некоторые специфические расчёты - например, астрономические, требуют решения
систем с огромнейшим количеством неизвестных и уравнений, которые часто практически невозможно решить на
обычных машинах, и доставляет сложности даже на больших машинах. Основная возникающая проблема - оптимизация
расчётов таким образом, чтобы расчёты были проведены за достаточное время - некоторую часть времени жизни проекта.
Мощные компьютеры стимулировали быстрый рост нового вида научной деятельности. К двум обширным классическим
ветвям науки - теоретической и экспериментальной - добавилась вычислительная наука. Ученые-вычислители моделируют
на суперкомпьютерах явления, слишком сложные, чтобы быть достоверно предсказуемыми теоретически, и слишком
опасные или дорогостоящие при их воспроизведении в лаборатории. Успехи вычислительной науки резко повысили
требования к вычислительным ресурсам за последние десять лет.
За это время параллельные компьютеры прошли путь от экспериментальных лабораторных приборов до повседневных
вычислительных инструментов, для решения сложных задач, требующих предельных компьютерных ресурсов.
Несколько факторов стимулировали быстрое развитие параллельных архитектур. Это не только физические пределы
скорости отдельного компьютера, обусловленные конечностью скорости света и конечней эффективности рассеяния
тепла, затрудняющими создание высокопроизводительных однопроцессорных машин. Это также и тот факт, что стоимость
однопроцессорных компьютеров растет быстрее, чем их производительность. Во многих случаях, паралелльные
вычислительные ресурсы могут быть изысканы вместо закупки новых. Например, существующие сети рабочих станций,
первоначально закупленные для выполнения скромных вычислительных работ, могут быть использованы в качестве
параллельного компьютера (такие сети часто называют SCAN - Super Computer at Night - "ночной" суперкомпьютер,
т.к. рабочие станции используются для вычислений в основном в нерабочее время). Эта схема оказалась столь
успешной и ценовая эффективность индивидуальных рабочих станций возросла столь стремительно, что сети
рабочих станций стали закупаться с целью выполнения на них параллельных работ, обычно исполняемых на
более дорогих суперкомпьютерах.
MPI (Message Passing Interface) - стандарт, предложенный для организации взаимодействия процессов (процессоров) в
параллельной вычислительной среде. В качестве такой среды могут быть использованы параллельные компьютеры CRAY,
Paragon, … или кластер компьютерной сети, состоящий из однотипных компьютеров типа Sun, SGI, HP, PC (кластер может
состоять и из разнотипных машин - тогда говорят о гетерогенной сети).
MPI разрабатывается как предполагаемый стандарт для передачи сообщений и связанных с этим операций. Его принятие
пользователями и разработчиками обеспечит сообщество параллельных программистов мобильностью и средствами,
необходимыми для разработки прикладных программ и параллельных библиотек, которые использовали бы мощь современных
(и будущих) высокопроизводительных компьютеров.
Основное преимущество MPI - возможность пренебречь аппаратной организацией решателя. Фактически, можно даже пренебречь
количеством имеющихся машин - при запуске MPI-программы мы можем указать лишь необходимое количество запускаемых
процессов, остальное - распределение процессов среди имеющихся машин по нагрузке, передачу данных, даже имитацию
топологии - берёт на себя MPI.
MPI не единственный способ решения проблемы написания параллельных программ. Существуют решения, предоставляемые
разработчиками аппаратуры, есть параллельные языки. Первые максимально эффективны, но абсолютно немобильны -
реализация на одном компьютере не будет годится для другого. Вторые обеспечивают полную мобильность, но обычно
программистов не удовлетворяет их эффективность.
Кроме того, свою лепту вносит и проблема архитектуры - кластер дешевле, но менее эффективен, суперкомпьютеры с общей
памятью эффективнее, но более дороги. MPI же предлагает модель процессов с локальной памятью и передачей сообщений,
так называемый интерфейс.
Модель с передачей сообщений подразумевает множество процессов, имеющих только локальную память, но способных
связываться с другими процессами, посылая и принимая сообщения. Определяющим свойством модели для передачи сообщений
является тот факт, что передача данных из локальной памяти одного процесса в локальную память другого процесса
требует выполнения операций обоими процессами.
Модель с передачей сообщений является полезной и полной для выражения параллельных алгоритмов. Она приводит к
ограничению управляющей роли моделей, основанных на компиляторах и параллельности данных. Некоторые считают ее
антропоморфный характер полезным при формулировании параллельных алгоритмов. Она хорошо приспособлена для
реализации адаптивных, самопланирующихся алгоритмов и для программ, которые малочувствительны к несбалансированности
скоростей процессов, имеющей место в разделяемых сетях.
Важнейшей причиной того, что передача сообщений остается постоянной частью параллельных вычислений, является
производительность. По мере того, как CPU становятся все более быстрыми, управление их кэш и иерархией памяти
вообще становится ключом к достижению максимальной производительности. Передача сообщений дает программисту
возможность явно связывать специфические данные с процессом, что позволяет компилятору и схемам управления кэш
в полную силу работать. Действительно, одно из преимуществ, которое компьютеры с распределенной памятью имели
даже перед большими однопроцессорными машинами, состоит в том, что они обеспечивают большую основную память и кэш.
Конечно, современные, даже настольные, вычислительные системы позволяют решить большинство расчётных задач,
которые могут встретится на производстве. Но современная тенденция имитации очень больших систем (и излишняя,
с моей точки зрения), а также некоторые специфические расчёты - например, астрономические, требуют решения
систем с огромнейшим количеством неизвестных и уравнений, которые часто практически невозможно решить на
обычных машинах, и доставляет сложности даже на больших машинах. Основная возникающая проблема - оптимизация
расчётов таким образом, чтобы расчёты были проведены за достаточное время - некоторую часть времени жизни проекта.
Мощные компьютеры стимулировали быстрый рост нового вида научной деятельности. К двум обширным классическим
ветвям науки - теоретической и экспериментальной - добавилась вычислительная наука. Ученые-вычислители моделируют
на суперкомпьютерах явления, слишком сложные, чтобы быть достоверно предсказуемыми теоретически, и слишком
опасные или дорогостоящие при их воспроизведении в лаборатории. Успехи вычислительной науки резко повысили
требования к вычислительным ресурсам за последние десять лет.
За это время параллельные компьютеры прошли путь от экспериментальных лабораторных приборов до повседневных
вычислительных инструментов, для решения сложных задач, требующих предельных компьютерных ресурсов.
Несколько факторов стимулировали быстрое развитие параллельных архитектур. Это не только физические пределы
скорости отдельного компьютера, обусловленные конечностью скорости света и конечней эффективности рассеяния
тепла, затрудняющими создание высокопроизводительных однопроцессорных машин. Это также и тот факт, что стоимость
однопроцессорных компьютеров растет быстрее, чем их производительность. Во многих случаях, паралелльные
вычислительные ресурсы могут быть изысканы вместо закупки новых. Например, существующие сети рабочих станций,
первоначально закупленные для выполнения скромных вычислительных работ, могут быть использованы в качестве
параллельного компьютера (такие сети часто называют SCAN - Super Computer at Night - "ночной" суперкомпьютер,
т.к. рабочие станции используются для вычислений в основном в нерабочее время). Эта схема оказалась столь
успешной и ценовая эффективность индивидуальных рабочих станций возросла столь стремительно, что сети
рабочих станций стали закупаться с целью выполнения на них параллельных работ, обычно исполняемых на
более дорогих суперкомпьютерах.
MPI (Message Passing Interface) - стандарт, предложенный для организации взаимодействия процессов (процессоров) в
параллельной вычислительной среде. В качестве такой среды могут быть использованы параллельные компьютеры CRAY,
Paragon, … или кластер компьютерной сети, состоящий из однотипных компьютеров типа Sun, SGI, HP, PC (кластер может
состоять и из разнотипных машин - тогда говорят о гетерогенной сети).
MPI разрабатывается как предполагаемый стандарт для передачи сообщений и связанных с этим операций. Его принятие
пользователями и разработчиками обеспечит сообщество параллельных программистов мобильностью и средствами,
необходимыми для разработки прикладных программ и параллельных библиотек, которые использовали бы мощь современных
(и будущих) высокопроизводительных компьютеров.
Основное преимущество MPI - возможность пренебречь аппаратной организацией решателя. Фактически, можно даже пренебречь
количеством имеющихся машин - при запуске MPI-программы мы можем указать лишь необходимое количество запускаемых
процессов, остальное - распределение процессов среди имеющихся машин по нагрузке, передачу данных, даже имитацию
топологии - берёт на себя MPI.
MPI не единственный способ решения проблемы написания параллельных программ. Существуют решения, предоставляемые
разработчиками аппаратуры, есть параллельные языки. Первые максимально эффективны, но абсолютно немобильны -
реализация на одном компьютере не будет годится для другого. Вторые обеспечивают полную мобильность, но обычно
программистов не удовлетворяет их эффективность.
Кроме того, свою лепту вносит и проблема архитектуры - кластер дешевле, но менее эффективен, суперкомпьютеры с общей
памятью эффективнее, но более дороги. MPI же предлагает модель процессов с локальной памятью и передачей сообщений,
так называемый интерфейс.
Модель с передачей сообщений подразумевает множество процессов, имеющих только локальную память, но способных
связываться с другими процессами, посылая и принимая сообщения. Определяющим свойством модели для передачи сообщений
является тот факт, что передача данных из локальной памяти одного процесса в локальную память другого процесса
требует выполнения операций обоими процессами.
Модель с передачей сообщений является полезной и полной для выражения параллельных алгоритмов. Она приводит к
ограничению управляющей роли моделей, основанных на компиляторах и параллельности данных. Некоторые считают ее
антропоморфный характер полезным при формулировании параллельных алгоритмов. Она хорошо приспособлена для
реализации адаптивных, самопланирующихся алгоритмов и для программ, которые малочувствительны к несбалансированности
скоростей процессов, имеющей место в разделяемых сетях.
Важнейшей причиной того, что передача сообщений остается постоянной частью параллельных вычислений, является
производительность. По мере того, как CPU становятся все более быстрыми, управление их кэш и иерархией памяти
вообще становится ключом к достижению максимальной производительности. Передача сообщений дает программисту
возможность явно связывать специфические данные с процессом, что позволяет компилятору и схемам управления кэш
в полную силу работать. Действительно, одно из преимуществ, которое компьютеры с распределенной памятью имели
даже перед большими однопроцессорными машинами, состоит в том, что они обеспечивают большую основную память и кэш.
#include
#include
#include
#include
#define NUM_DIMS 2
#define P0 4
#define P1 4
#define M 64
#define N 64
#define K 64
PMATMAT_2(A, B, C, n, p, comm)
int n[];
float A[][], B[][], C[][];
int p[];
MPI_comm comm;
{
int nn[2];
float AA[][], BB[][], CC[][];
MPI_comm comm_2D, comm_1D[2], pcomm;
int coords[2];
int rank;
int dispc[], countc[];
int typeb, typec, types[2], blen[2], disp[2];
int i, j, k, sizeofreal;
int periods[2], remains[2];
MPI_Comm_dup(comm, pcomm);
MPI_Bcast(n, 3, MPI_INT, 0, pcomm);
MPI_Bcast(p, 2, MPI_INT, 0, pcomm);
periods[0] = 0;
periods[1] = 0;
MPI_Cart_create(pcomm, 2, p, periods, false, comm_2D);
MPI_Comm_rank(comm_2D, rank);
MPI_Cart_coords(comm_2D, rank, 2, coords);
for(i = 0; i < 2; i++){
for(j = 0; j < 2; j++)
remains[j] = (i = j);
MPI_Cart_sub(comm_2D, remains, comm_1D[i]);
}
nn[0] = n[0]/p[0];
nn[1] = n[2]/p[1];
AA = (float *)malloc(nn[0] * n[1] * sizeof(float));
BB = (float *)malloc( n[1] * nn[2] * sizeof(float));
CC = (float *)malloc(nn[0] * nn[2] * sizeof(float));
if(rank == 0){
MPI_Type_vector(n[1], nn[1], n[2], MPI_FLOAT, types[0]);
MPI_Type_extent(MPI_float, sizeoffloat);
blen[0] = 1;
blen[1] = 1;
disp[0] = 0;
disp[1] = sizeoffloat * nn[1];
types[1] = MPI_UB;
MPI_Type_struct(2, blen, disp, types, typeb);
MPI_Type_commit(typeb);
MPI_Type_vector(nn[0], nn[1], n[2], MPI_FLOAT, types[0]);
MPI_Type_struct(2, blen, disp, types, typec);
MPI_Type_commit(typec);
dispc = (int *)malloc(p[0] * p[1] * sizeof(int));
countc = (int *)malloc(p[0] * p[1] * sizeof(int));
for(j = 0; j < p[0]); j++){
for(i = 0, i < p[1]; i++){
dispc[j*p[1]+i] = (j*p[1] + i)*nn[1];
countc[j*p[1]+i] = 1;
}
}
}
if(coords[1] == 0){
MPI_Scatter(A, nn[0]*n[1], MPI_FLOAT, AA, nn[0]*n[1], MPI_FLOAT, 0,comm_1D[0]);
}
if(coords[0] == 0){
MPI_Scatter(B, 1, typeb, BB, n[1]*nn[1], MPI_FLOAT, 0, comm_1D[1]);
}
MPI_Bcast(AA,nn[0]*n[1], MPI_FLOAT, 0, comm_1D[1]);
MPI_Bcast(BB, n[1]*nn[1], MPI_FLOAT, 0, comm_1D[0]);
for(i = 0; i < nn[0]; i++){
for(j = 0; j < nn[1]; j++){
CC[i,j] = 0;
for(k = 0; k < n[1]; k++){
CC[i,j] = CC[i,j]+AA[i,k]*BB[k,j];
}
}
}
MPI_Gatherv(CC, nn[0]*nn[1], MPI_FLOAT, C, countc, dispc, typec, 0,comm_2D);
free(AA);
free(BB);
free(CC);
MPI_Comm_free(pcomm);
MPI_Comm_free(comm_2D);
for(i = 0; i < 2; i++){
MPI_Comm_Free(comm_1D[i]);
}
if(rank == 0){
free(countc);
free(dispc);
MPI_Type_free(typeb);
MPI_Type_free(typec);
MPI_Type_free(types[0]);
}
return 0;
}
int main(int argc, char **argv)
{
int size, rank, n[3], p[2], i, j, k;
int dims[NUM_DIMS], periods[NUM_DIMS];
int reorder = 0;
MPI_Comm comm;
MPI_Status st;
struct timeval tv1, tv2;
int dt1;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
for(i = 0; i < NUM_DIMS; i++) { dims[i] = 0; periods[i] = 0; }
MPI_Dims_create(size, NUM_DIMS, dims);
MPI_Cart_create(MPI_COMM_WORLD, NUM_DIMS, dims, periods, reorder, &comm);
n[0] = M;
n[1] = N;
n[2] = K;
p[0] = P0;
p[1] = P1;
if (rank == 0){
A = (float *)malloc(n[0] * n[1] * sizeof(float));
B = (float *)malloc(n[1] * n[2] * sizeof(float));
C = (float *)malloc(n[0] * n[2] * sizeof(float));
for(i = 0; i < M; i++)
for(j = 0; j < N; j++)
A[i][j] = 3.141528;
for(j = 0; j < N; j++)
for(k = 0; k < K; k++)
B[j][k] = 2.812;
for(i = 0; i < M; i++)
for(k = 0; k < K; k++)
C[i][k] = 0.0;
}
gettimeofday(&tv1, (struct timezone*)0);
PMATMAT_2(A, B, C, n, p, comm)
gettimeofday(&tv2, (struct timezone*)0);
dt1 = (tv2.tv_sec - tv1.tv_sec) * 1000000 + tv2.tv_usec - tv1.tv_usec;
printf("rank = %d Time = %d\n", rank, dt1);
if (rank == 0){
for(i = 0; i < 1; i++)
for(j = 0; j < 4; j++)
printf("C[i][j] = %f", C[i][j]);
}
MPI_Comm_free(&comm);
MPI_Finalize();
return(0);
}
|