|
ВВЕДЕНИЕ :.:.
Одним из наиболее перспективных направлений в развитии информационных технологий являются системы поддержки принятия решений. Системы поддержки принятия решений базируются на следующих технологиях: оперативные базы данных, хранилища данных, системы оперативной аналитической обработки информации и интеллектуальный анализ данных. В тоже время классические методы поддержки принятия решений в большинстве своем хоть и разработаны довольно давно и получили широкое распространение не имеют под собой четкого математического обоснования. В области поддержки принятия решений работают следующие ученые Уильям Кейм, Стивен Кейм, Ди Янг, Дэнис Пайлон, Эдвард Кодд. Из отечественных ученых можно выделить Павла Горского и Дмитрия Суркова занимающихся разработкой математических методов поддержки принятия решений.
Актуальность данной работы состоит в том, что технологии лежащие в основе систем поддержки принятие решений хоть и проработаны достаточно глубоко, но все же новы и являются приоритетными направлениями исследований в области информационных технологий.
Целью работы является исследование текущих тенденций развития и практического применения СППР, выявление существующих недостатков, а также выбора направления для дальнейших исследований.
Исследуемые технологии не имеют четко очерченной области применения и могут быть использованы в любой отрасли социально-экономической деятельности где возникает необходимость в анализе большого количества данных и принятия сложных управленческих решений.
ПРЕДМЕТ ИССЛЕДОВАНИЯ, ЕГО СОСТАВЛЯЮЩИЕ, МЕТОДЫ ПРОЕКТИРОВАНИЯ И АНАЛИЗА :.:.
ОСНОВНЫЕ ПОНЯТИЯ :.:.
Система поддержки принятия решений - это диалоговая автоматизированная система, использующая правила принятия решений и соответствующие модели с базами данных, а также интерактивный компьютерный процесс моделирования.
Основу СППР составляет комплекс взаимосвязанных моделей с соответствующей информационной поддержкой исследования, экспертные и интеллектуальные системы, включающие опыт решения задач управления и обеспечивающие участие коллектива экспертов в процессе выработки рациональных решений [4,7,8].
Первоначально информация хранится в оперативных базах данных OLTP-систем. Но ее сложно использовать в процессе принятия решений по причинам, о которых будет сказано ниже. Агрегированная информация организуется в многомерное хранилище данных. Затем она используется в процедурах многомерного анализа (OLAP) и для интеллектуального анализа данных (ИАД).
Хранилища данных
Ясно, что принятие решений должно основываться на реальных данных об объекте управления. Такая информация обычно хранится в оперативных базах данных OLTP-систем. Но эти оперативные данные не подходят для целей анализа, так как для анализа и принятия стратегических решений в основном нужна агрегированная информация.
Решением данной проблемы является создание отдельного хранилища данных (ХД), содержащего агрегированную информацию в удобном виде. Целью построения хранилища данных является интеграция, актуализация и согласование оперативных данных из разнородных источников для формирования единого непротиворечивого взгляда на объект управления в целом.
На основе хранилища данных возможно составление отчетности для руководства, анализ данных с помощью OLAP-технологий и интеллектуальный анализ данных (Data Mining) [13,21,22].
По Кодду, многомерное концептуальное представление является наиболее естественным взглядом управляющего персонала на объект управления. Оно представляет собой множественную перспективу, состоящую из нескольких независимых измерений, вдоль которых могут быть проанализированы определенные совокупности данных. Одновременный анализ по нескольким измерениям данных определяется как многомерный анализ. Каждое измерение включает направления консолидации данных, состоящие из серии последовательных уровней обобщения, где каждый вышестоящий уровень соответствует большей степени агрегации данных по соответствующему измерению. Так, измерение Исполнитель может определяться направлением консолидации, состоящим из уровней обобщения "предприятие - подразделение - отдел - служащий". Измерение Время может даже включать два направления консолидации - "год - квартал - месяц - день" и "неделя - день", поскольку счет времени по месяцам и по неделям несовместим. В этом случае становится возможным произвольный выбор желаемого уровня детализации информации по каждому из измерений. Операция спуска соответствует движению от высших ступеней консолидации к низшим; напротив, операция подъема означает движение от низших уровней к высшим.
Хранилища данных содержат информацию, собранную из нескольких оперативных баз данных. Хранилища, как правило, на порядок больше оперативных баз, зачастую от сотен гигабайт до нескольких терабайт. Как правило, хранилище данных поддерживается независимо от оперативных баз данных организации, поскольку требования к функциональности и производительности аналитических приложений отличаются от требований к транзакционным системам. Хранилища данных создаются специально для приложений поддержки принятия решений и предоставляют накопленные за определенное время, сводные, консолидированные и преагрегированные данные, которые более приемлемы для анализа, чем детальные индивидуальные записи.
OLAP
Системы поддержки принятия решений обычно обладают средствами предоставле-ния пользователю агрегатных данных для различных выборок из исходного набора в удобном для восприятия и анализа виде. Как правило, такие агрегатные функции обра-зуют многомерный (и, следовательно, нереляционный) набор данных (нередко называе-мый гиперкубом или метакубом), оси которого содержат параметры, а ячейки - завися-щие от них агрегатные данные - причем храниться такие данные могут и в реляционных таблицах, но в данном случае мы говорим о логической организации данных, а не о фи-зической реализации их хранения). Вдоль каждой оси данные могут быть организованы в виде иерархии, представляющей различные уровни их детализации. Благодаря такой мо-дели данных пользователи могут формулировать сложные запросы, генерировать отчеты, получать подмножества данных.
Технология комплексного многомерного анализа данных получила название OLAP (On-Line Analytical Processing). OLAP - это ключевой компонент организации хранилищ данных.
1995 году на основе требований, изложенных Коддом, был сформулирован так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information - быстрый анализ разделяемой многомерной информации), включающий следующие требования к приложениям для многомерного анализа:
FAST(Быстрый) - означает, что система должна обеспечивать выдачу большинства ответов пользователям в пределах приблизительно пяти секунд.
ANALYSIS (Анализ) означает, что система может справляться с любым логическим и статистическим анализом, характерным для данного приложения, и обеспечивает его сохранение в виде, доступном для конечного пользователя.
SHARED (Разделяемой) означает, что система осуществляет все требования защиты конфиденциальности (возможно до уровня ячейки) и, если множественный доступ для записи необходим, обеспечивает блокировку модификаций на соответствующем уровне.
MULTIDIMENSIONAL (Многомерной) наше ключевое требование. Если бы мы должны были определить OLAP одним словом, то выбрали бы его. Система должна обеспечить многомерное концептуальное представление данных, включая полную поддержку для иерархий и множественных иерархий, поскольку это определенно наиболее логичный способ анализировать бизнес и организации.
INFORMATION (Информации) - это все. Необходимая информация должна быть получена там, где она необходима.
Техника реализации включает много различных патентованных идей, которыми так гордятся поставщики: разновидности архитектуры "клиент-сервер", анализ временных рядов, объектная ориентация, оптимизация хранения данных, параллельные процессы и т.д. Мы также имеем свое представление об этом, но мы не хотели бы, чтобы какие-то технологии стали частью определения OLAP. Поставщики, которые охвачены нашим отчетом, имели все возможности сообщить нам о своих технологиях, однако нас интересовала более всего их способность достигнуть целей OLAP в соответствующих прикладных областях, выбранных ими.
Традиционные реляционные серверы не обеспечивают эффективное выполнение сложных OLAP-запросов и поддержку многомерных представлений данных. Но, тем не менее, три типа реляционных серверов баз данных - реляционной, многомерной и гибридной оперативной аналитической обработки - позволяют выполнять OLAP-операции в хранилищах данных, построенных с использованием систем управления реляционными базами данных. Серверы ROLAP. Размещаются между основным реляционным сервером, где находится хранилище данных и клиентским инструментарием переднего плана. Серверы ROLAP поддерживают многомерные OLAP-запросы и, как правило, оптимизированы для конкретных реляционных серверов. Они указывают, какие представления должны быть материализованы, возможные запросы пользователей в терминах соответствующих материализованных представлений, и генерируют сложные SQL-серверы для основного сервера. Они также предусматривают дополнительные службы, такие как планирование запросов и распределение ресурсов. Серверы ROLAP наследуют возможности масштабирования и работы с транзакциями реляционных систем, однако существенные различия между запросами в стиле OLAP и SQL могут стать причиной низкой производительности. Нехватка производительности становится менее острой, благодаря ориентированным на задачи OLAP расширениям SQL, реализованным в серверах реляционных баз данных наподобие Oracle, IBM DB2 и Microsoft SQL Server. Такие функции, как median, mode, rank, percentile дополняют агрегатные функции. К другим дополнительным возможностям относятся агрегатные вычисления на перемещающихся окнах, текущие сводные значения и точки прерывания для улучшенной поддержки формирования отчетов.
Многомерные электронные таблицы требуют группировки по различным наборам атрибутов. Для того чтобы удовлетворить эти требования SQL был расширен двумя операторами - roll-up и cube. Свертка списка атрибутов, включающего продукт, год и город, помогает находить ответы на вопросы, в которых фигурируют:
1 - группировка по продуктам, годам и городам;
2 - группировка по продуктам и годам;
3 - группировка по продуктам.
Пусть дан список из k столбцов, оператор cube предлагает группировку по каждой из 2**k комбинаций столбцов. Многочисленные операции "group by" могут быть выполнены эффективно за счет распознавания общих частей вычислений [3]. Разумно подобранные предварительные вычисления могут увеличить производительность серверов OLAP [4].
MOLAP. Серверная архитектура, которая не опирается на функциональность основных реляционных систем, но напрямую поддерживает многомерные представления данных с помощью многомерного механизма хранения. MOLAP позволяет реализовывать многомерные запросы на уровне хранения путем установки прямого соответствия. Основное преимущество MOLAP заключается в превосходных свойствах индексации; ее недостаток - низкий коэффициент использования дискового пространства, особенно в случае разреженных данных. Многие серверы MOLAP при работе с разреженными множествами данных используют двухуровневую организацию памяти и сжатие. При двухуровневой организации пользователь либо непосредственно, либо с помощью специальных инструментов проектирования, идентифицирует набор подмассивов, которые, скорее всего, будут плотными и представляет их в виде массива. Индексировать эти массивы меньшего размера можно с помощью традиционных индексных структур. Многие из методик, разработанных для статистических баз данных, подходят и для MOLAP. Серверы MOLAP обладают хорошей производительностью и функциональностью, но не в состоянии должным образом масштабироваться в случае очень больших баз данных.
HOLAP. Гибридная архитектура, которая объединяет технологии ROLAP и MOLAP. В отличие от MOLAP, которая работает лучше, когда данные более менее плотные, серверы ROLAP лучше в тех случаях, когда данные довольно разрежены. Серверы HOLAP применяют подход ROLAP для разреженных областей многомерного пространства и подход MOLAP - для плотных областей. Серверы HOLAP разделяют запрос на несколько подзапросов, направляют их к соответствующим фрагментам данных, комбинируют результаты, а затем предоставляют результат пользователю.
Многомерная модель данных
Основными понятиями многомерной модели данных являются:
Показатель - это величина (обычно числового типа), которая является предметом анализа. Это, например, объём продаж некоторого товара, или выручка от продаж товара. Один OLAP-куб может обладать одним или несколькими показателями.
Измерение (dimension) - это множество объектов одного или нескольких типов, организованных в виде иерархической структуры и обеспечивающих информационный контекст числового показателя. Измерение принято визуализировать в виде ребра многомерного куба.
Объекты, совокупность которых образует измерение, называются членами измерений (members). Члены измерений визуализируют как точки или участки, откладываемые на осях гиперкуба. Например, временное измерение: Дни, Месяцы, Кварталы, Годы - наиболее часто используемые в анализе, могут содержать следующие члены: 8 мая 2002 года, май 2002 года, 2-ой квартал 2002 года и 2002 год.Объекты в измерениях могут быть различного типа, например "производители" - "марки автомобиля" или "годы" - "кварталы". Эти объекты должны быть организованы в иерархическую структуру так, чтобы объекты одного типа принадлежали только одному уровню иерархии.
Ячейка (cell) - мельчайшая структура куба, соответствующая конкретному значению некоторого показателя. Ячейки при визуализации располагаются внутри куба и здесь же принято отображать соответствующее значение показателя.
Измерения играют роль индексов, используемых для идентификации значений показателей, находящихся в ячейках гиперкуба. Комбинация членов различных измерений играют роль координат, которые определяют значение определенного показателя. Поскольку для куба может быть определено несколько показателей, то комбинация членов всех измерения будет определять несколько ячеек со значениями каждого из показателей. Для однозначной идентификации ячейки необходимо указать комбинацию членов всех измерений и показатель.
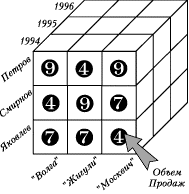
Рис. 1. OLAP-куб
В отличие от измерений, не все значения показателей должны иметь, и имеют реальные значения. Например, Менеджер Петров в 1994 г. мог еще не работать в фирме, и в этом случае все значения Показателя Объем продаж за этот год будут иметь неопределенные, "пустые" значения.
Интеллектуальный анализ данных
Наибольший интерес в СППР представляет интеллектуальный анализ данных, так как он позволяет провести наиболее полный и глубокий анализ проблемы, дает возможность обнаружить скрытые взаимосвязи, принять наиболее обоснованное решение.
Современный уровень развития аппаратных и программных средств с некоторых пор сделал возможным повсеместное ведение баз данных оперативной информации на разных уровнях управления. В процессе своей деятельности промышленные предприятия, корпорации, ведомственные структуры, органы государственной власти и местного самоуправления накопили большие объемы данных. Они хранят в себе большие потенциальные возможности по извлечению полезной аналитической информации, на основе которой можно выявлять скрытые тенденции, строить стратегию развития, находить новые решения.
Интеллектуальный анализ данных (Data Mining) - это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей (шаблонов информации). При этом накопленные сведения автоматически обобщаются до информации, которая может быть охарактеризована как знания.
| OLAP |
DataMining |
| Каковы средние показатели травматизма для курящих и некурящих? |
Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму? |
| Каковы средние размеры телефонных счетов существующих клиентов, в сравнении со счетами бывших клиентов отказавшихся от услуг телефонной компании)? |
Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании? |
| Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? |
Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными карточками? |
Таблица 1. Сравнительная таблица задач OLAP и DataMining.
Важное положение Data Mining - нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания.
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование.
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом.
Если существует цепочка связанных во времени событий, то говорят о последовательности.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
Классы систем Data Mining
Предметно-ориентированные аналитические системы
Эти методы часто используют несложный статистический аппарат, но максимально учитывают сложившуюся своей области специфику (профессиональный язык, системы различных индексов и пр.).
Статистические пакеты
Недостатком систем этого класса считают требование к специальной подготовке пользователя. Есть еще более серьезный принципиальный недостаток статистических пакетов, ограничивающий их применение в Data Mining. Большинство методов, входящих в состав пакетов опираются на статистическую парадигму, в которой главными фигурантами служат усредненные характеристики выборки. А эти характеристики при исследовании реальных сложных жизненных феноменов часто являются фиктивными величинами.
Нейронные сети
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается в том, что даже натренированная нейронная сеть представляет собой черный ящик. Знания, зафиксированные как веса нескольких сотен межнейронных связей, совершенно не поддаются анализу и интерпретации человеком (известные попытки дать интерпретацию структуре настроенной нейросети выглядят неубедительными - система "KINOsuite-PR").
Системы рассуждений на основе аналогичных случаев
Системы CBR показывают неплохие результаты в самых разнообразных задачах. Главным их минусом считают то, что они вообще не создают каких-либо моделей или правил, обобщающих предыдущий опыт, - в выборе решения они основываются на всем массиве доступных исторических данных, поэтому невозможно сказать, на основе каких конкретно факторов CBR системы строят свои ответы.
Другой минус заключается в произволе, который допускают системы CBR при выборе меры "близости". От этой меры самым решительным образом зависит объем множества прецедентов, которые нужно хранить в памяти для достижения удовлетворительной классификации или прогноза [7].
Деревья решений (decision trees)
Популярность деревьев решений связана как бы с наглядностью и понятностью. Но деревья решений принципиально не способны находить "лучшие" правила в данных. Они реализуют наивный принцип последовательного просмотра признаков и "цепляют" фактически осколки настоящих закономерностей, создавая лишь иллюзию логического вывода. Вместе с тем, большинство систем используют именно этот метод.
Генетические алгоритмы
Генетические алгоритмы удобны тем, что их легко распараллеливать. Например, можно разбить поколение на несколько групп и работать с каждой из них независимо, обмениваясь, время от времени несколькими хромосомами. Существуют также и другие методы распараллеливания генетических алгоритмов.
Генетические алгоритмы имеют ряд недостатков. Критерий отбора хромосом и используемые процедуры являются эвристическими и далеко не гарантируют нахождения "лучшего" решения. Как и в реальной жизни, эволюцию может "заклинить" на какой-либо непродуктивной ветви. И, наоборот, можно привести примеры, как два неперспективных родителя, которые будут исключены из эволюции генетическим алгоритмом, оказываются способными произвести высокоэффективного потомка. Это особенно становится заметно при решении высокоразмерных задач со сложными внутренними связями.
Системы для визуализации многомерных данных
В той или иной мере средства для графического отображения данных поддерживаются всеми системами Data Mining. Вместе с тем, весьма внушительную долю рынка занимают системы, специализирующиеся исключительно на этой функции. Примером здесь может служить программа DataMiner 3D словацкой фирмы Dimension5 (5-е измерение).
ВЫВОДЫ :.:.
В ходе поиска и анализа информации по следующим направлениям:
- математические методы поддержки принятия решений;
- применение СУБД и хранилищ данных в СППР;
- применение оперативного анализа данных в СППР;
- интеллектуальные и распределенные СППР.
Были выявлены следующие недостатки в существующих СППР:
- традиционные методы поддержки принятия решений не имеют четкого матема-тического обоснования;
- в хранилищах данных отсутствуют, или находятся в зачаточном состоянии мето-ды очистки "грязных данных";
- многие интеллектуальные методы анализа данных требуют большого количества данных для анализа;
- отсутствуют механизмы оптимизации распределенных хранилищ данных;
Практически все существующие на данный момент средства для создания СППР прекрасно справляются с задачами создания СППР на основе хранилищ данных. Однако данные средства не позволяют создавать единые системы поддержки принятия решений для предприятий, чьи подразделения значительно удалены друг от друга. Использование традиционных технологий хранилищ данных не представляется возможным. Сейчас для этих целей используются витрины данных, но они имеют существенные недостатки. Витрины данных, как правило, не связаны друг с другом и одни и те же данные хранятся многократно в различных витринах. Это приводит к дублированию данных и, как следст-вие, к увеличению расходов на хранение и проблемам, связанным с необходимостью поддержания непротиворечивости данных. Также к недостаткам витрин данных относят-ся очень сложный процесс наполнения витрин данных при большом количестве источни-ков данных и отсутствие консолидации данных на уровне предприятия, как следствие, отсутствие единой картины бизнеса
ПРЕДЛОЖЕНИЯ ПО ДАЛЬНЕЙШИМ ИССЛЕДОВАНИЯМ :.:.
В ходе дальшейших исследований я планирую изучить факторы влияющие на скорость выполнения запросов в распределенном хранилище данных и применить генетические алгоритмы для оптимизации времени выполнения запросов в распределенном хранилище данных.
Мною будет применен генетический алгоритм для распределения данных между узлами распределенного хранилища и оптимизации времени выполнения запросов, а также теория графов [8] для создания модели распределенного хранилища данных.
Для реализации данного подхода необходимо выполнить следующие шаги:
- Выяснить все запросы, которые будут выполнятся всеми программами, работающими с хранилищем данных, и выясняются все таблицы и поля, фигурирующие в этих запросах.
- Необходимо удалить из хранилища данных те поля, которые не используются ни в одном из запросов. В случае, если впоследствии появятся новые запросы использующие данные поля, необходимо будет ввести в хранилище эти данные и повторить процедуру оптимизации.
- Затем производится упорядочение таблиц и полей в источниках данных с учетом их релевантности потребностям приложений в данных.
- Создается модель хранилища данных в виде графа, вершины которого будут представлять собой узлы распределенного хранилища данных, а дуги - каналы связи между ними [6,7]. В вершинах данного графа будет хранится информация о скорости выборки столбцов, находящихся в данном узле хранилища, а вес дуги будет определятся скоростью передачи данных по данному каналу связи.
- Необходимо для каждого из запросов составить целевую функцию вида:
 где Q - скорость выполнения запроса;
где Q - скорость выполнения запроса;
R - релевантность данного запроса;
Хi, Ak- скопрость выборки для i-го столбца и к-го агрегатного значения;
vj - скорость передачи данных по j-му каналу связи;
n - количество выбираемых столбцов;
а- количество выбираемых агрегатных значений;
m - количество дуг графа, которое проходят данные из столбца.
- Решить систему целевых функций относительно Xi и Аі с помощью генетических алгоритмов.
Данная методика имеет ряд преимуществ:
1. Данная методика позволяет получить структуру распределенного хранилища данных с учетом её "распределенности".
2. С помощью генетических алгоритмов можно получить оптимизированную структуру хранилища данных гораздо быстрее, чем с помощью классических методов оптимизации.
3. Структура хранилища данных строится автоматически на основании расчетов, с учетом релевантности запросов, а не проектировщиками, полагающимися на собственный опыт.
ЛИТЕРАТУРА :.:.
1. Ларичев О.И. Объективные модели и субъективные решения. М., Наука. 1987.
2. Кун Т. Структура научных революций. М., Прогресс. 1977.
3. Slovic P., Fichhoff B., Lichtenstein S. Behaviorial decision theory. - Annu. Phychol. Rev. vol. 28, 1997.
4. Eom S.B. decosion support systems research: reference disciplines and a cumulative tradition. - The International Journal of Management Science, 23, 5, October 1995, p. 511-523.
5. Ларичев О.И., Мошкович Е.М. Качественные методы принятия решений. М., Наука. Физматлит. 1996.
6. Simonovic A., Slobodan P. Decision support for sustainable water resources development in water resources planning in a changing world. -Proceeding of International UNESCO symposium, Karlsruhe, Germany, p. III. 3-13, 1994.
7. Ginzberg M.J., Stohr E. A. A decision support: Issues and Perspectives. - Processes and Tools for Decision Support. Amsterdam, North - holland Publ. Co, 1983.
8. Simon H.A. The new science of management decision. Englewood Cliffs, N.J., Prentice - Hall Inc., 1975.
9. Саати Т. Принятие решений. Метод анализа иерархий. М., Радио и связь. 1993.
10. Трахтенгерц Э.А. Компьютерный анализ в динамике принятия решений. - Приборы и системы управления. # 1, 1997, с. 49-56.
11. Трахтенгерц Э.А. Построение распределенных систем группового проектирования. - АиТ, # 9, 1993, с. 154-174.
12. Трахтенгерц Э.А. Методы генерации, оценки и согласования решений в распределенных системах поддержки принятия решений. - АиТ, #4, 1995, с. 3-52.
13. H. Gupta. Selection of Views to Materialize in a Data Warehouse. In Proceedings of the Intl. Conf. on Database Theory, 1997 January.
14. J. Yang, K. Karlapalem, and Q. Li. Algorithms for Materialized View Design in Data Warehousing Environment. In Proc. of the 23th VLDB Conference, 1997 August.
15. Турчак И.Н. Численные методы. - М, 1986. С. 413.
16. Андреев В.В. Генетические и нейронные алгоритмы: Конспект лекций. - Чебоксары: ЧГУ, 2001. С. 308.
17. Курейчик В.М. Генетические алгоритмы. - Таганрог, 1998. С. 453.
18. Оре О. Теория графов. М.: Наука, 1968. С. 214.
19. Замбицкий Д.К., Лозовану Д.Д. Алгоритмы решения оптимизационных задач на сетях. - Кишинев, Штиинца: 1983. С. 350.
20. Басакер Р., Саати Т. Конечные графы и сети. - М.: Наука, 1974. С. 388.
21. Билл Инмон. Производительность систем хранилищ данных. Performance In The Data Warehouse Environment. 2000 г. №4. - С. 41-48.
22. Вон Ким. Три основных недостатка современных хранилищ данных. Performance In The Data Warehouse Environment. 2000 г. №4. - С. 120-127.
23. Кривда Ш. Раскопки сокрытых данных. "Открытые системы", 2000 г. №8
24. Адомавичус Г., Тужилин А. Использование методов добычи данных для создания профилей потребителей. "Открытые Системы" 2001 г. №05-06
25. Сахаров А.А. Принципы проектирования и использования многомерных баз данных (на примере Oracle Express Server). СУБД, N3/ 1996.
26. Шапот М. Интеллектуальный анализ данных в системах поддержки принятия решений. "Открытые системы" 1998 №1 с. 30-35
|






