Биография
Реферат магистерской работы
Ссылки
Поиск по теме
Библиотека
Индивидуальное задание
Автореферат магистерской работы
Содержание
1. Введение.
1.1 Цель.
1.2 Требования.
1.3 Терминология.
1.4 Общее описание.
2. Письменные соглашения и обобщенная грамматика.
2.1 Увеличенная нормальная запись Бекуса-Наура (BNF).
2.2 Основные правила.
3. Параметры протокола.
3.1 Версия HTTP.
3.2 Универсальные Идентификаторы Ресурсов (URI) .
3.2.1 Общий синтаксис.
3.2.2 HTTP URL.
3.2.3 Сравнение URI.
4 Что такое Proxy.
5 Системы балансировки нагрузки Web - серверов.
Заключение.
Литература.
Введение
1 Введение.
1.1 Цель.
Протокол передачи Гипертекста (HTTP) -
протокол прикладного уровня
для распределенных, совместных, многосредных информационных систем.
HTTP используется в World Wide Web (WWW) начиная с 1990 года. Первой
версией HTTP, известной как HTTP/0.9, был простой протокол для
передачи необработанных данных через Интернет. HTTP/1.0, как
определено в RFC 1945 [6], был улучшением этого протокола, позволяя
сообщениям иметь MIME-подобный формат, содержащий метаинформацию о
передаваемых данных и имел модифицированную семантику
запросов/ответов. Однако, HTTP/1.0 недостаточно хорошо учитывал
особенности работы с иерархическими прокси-серверами (hierarchical
proxies), кэшированием, постоянными соединениями, и виртуальными
хостами (virtual hosts). Кроме того, быстрое увеличение не полностью
совместимых приложений, называющих тот протокол, который они
использовали "HTTP/1.0", потребовало введения версии протокола, в
которой были бы заложены возможности, позволяющие приложениям
определять истинные возможности друг друга.
Эта спецификация определяет протокол "HTTP/1.1". Этот протокол
содержит более строгие требования, чем HTTP/1.0, гарантирующие
надежную реализацию возможностей.
Практически информационные системы требуют большей функциональности,
чем просто загрузку информации, включая поиск, модификацию при
помощи внешнего интерфейса, и аннотацию (annotation). HTTP
предоставляет открытый набор методов, которые указывают цель запроса.
Они основаны на дисциплине ссылки, обеспеченной Универсальным
Идентификатором Ресурса (URI) [3][20], как расположение (URL) [4]
или имя (URN), для идентификации ресурса, к которому этот метод
применяется. Сообщения передаются в формате, подобном используемому
электронной почтой, как определено Многоцелевыми Расширениями
Электронной Почты (MIME).
HTTP также используется как обобщенный протокол связи между агентами
пользователей и прокси-серверами/шлюзами (proxies/gateways) или
другими сервисами Интернета, включая такие, как SMTP [16], NNTP [13],
FTP [18], Gopher [2], и WAIS [10]. Таким образом, HTTP закладывает
основы многосредного (hypermedia) доступа к ресурсам для
разнообразных приложений.
1.2 Требования.
Эта спецификация использует те же самые слова для определения
требований к реализации протокола, что и RFC 1123 [8]. Эти слова
следующие:
НЕОБХОДИМО, ДОЛЖЕН (MUST)
Применяется для указания, что данное требование спецификации
необходимо обеспечить в любом случае.
РЕКОМЕНДУЕТСЯ, СЛЕДУЕТ (SHOULD)
Используется для указания, что данное требование спецификации
должно быть обеспечено, если этому не препятствуют серьезные
причины.
ВОЗМОЖНО, МОЖЕТ (MAY)
Используется для указания, что данное требование спецификации
является опциональным и может быть либо реализовано, либо нет -
по необходимости.
Реализация считается несовместимой, если нарушено хотя бы одно
НЕОБХОДИМЫХ требований спецификации протокола. Реализация,
удовлетворяющая всем НЕОБХОДИМЫМ и РЕКОМЕНДУЕМЫМ тредованиям
называется полностью совместимой, а удовлетворяющая всем НЕОБХОДИМЫМ,
но не всем РЕКОМЕНДУЕМЫМ требованиям называется условно совместимой.
1.3 Терминология.
Эта спецификация использует ряд терминов для описания роли
участников, некоторых объектов, и HTTP связи.
Соединение (connection)
Виртуальный канал транспортого уровня, установленный между двумя
программами с целью связи.
Сообщение (message)
Основной модуль HTTP связи, состоящей из структурной
последовательности октетов, соответствующих синтаксису,
определенному в разделе 4 и передаваемых по соединению.
Запрос (request)
Любое HTTP сообщение, содержащее запрос.
Ответ (response)
Любое HTTP сообщение, содержащее ответ.
Ресурс (resource)
Сетевой объект данных или сервис, который может быть
идентифицирован URI. Ресурсы могут
быть доступны в нескольких представлениях (например на нескольких
языках, в разных форматах данных, иметь различный размер, иметь
различную разрешающую способность) или различаться по другим
параметрам.
Объект (entity)
Информация, передаваемая в качестве полезной нагрузки запроса или
ответа. Объект состоит из метаинформации в форме полей заголовка
объекта и содержания в форме тела объекта.
Представление (representation)
Объект включенный в ответ, и подчиняющийся обсуждению
содержимого (Content Negotiation).
Может существовать несколько представлений, связанных со
специфическими состояниями ответа.
Обсуждение содержимого (content negotiation)
Механизм для выбора соответствующего представления во время
обслуживания запроса. Представление
объектов в любом ответе может быть обсуждено (включая ошибочные
ответы).
Вариант (variant)
Ресурс может иметь одно, или несколько представлений, связанных
с ним в данный момент. Каждое из этих представлений называется
"вариант". Использование термина "вариант" не обязательно
подразумевает, что ресурс подчинен обсуждению содержимого.
Клиент (client)
Программа, которая устанавливает соединения с целью посылки
запросов.
Агент пользователя (user agent)
Клиент, который инициирует запрос. Как правило браузеры,
редакторы, роботы (spiders), или другие инструментальные
средства пользователя.
Сервер (server)
Приложение, которое слушает соединения, принимает запросы на
обслуживание и посылает ответы. Любая такая программа способна
быть как клиентом, так и сервером; наше использование данного
термина относится скорее к роли, которую программа выполняет,
создавая специфические соединения, нежели к возможностям
программы вообще. Аналогично, любой сервер может действовать как
первоначальный сервер, прокси-сервер, шлюз, или туннель (tunnel),
изменяя поведение, основываясь на характере каждого запроса.
Первоначальный сервер (origin server)
Сервер, на котором данный ресурс постоянно находится или должен
быть создан.
Прокси-сервер (proxy)
Программа-посредник, которая действует и как сервер, и как
клиент с целью создания запросов от имени других клиентов.
Запросы обслуживаются прокси-сервером, или передаются им,
возможно с изменениями. Прокси-сервер должен удовлетворять
требованиям клиента и сервера, согласно этой спецификации.
Шлюз (gateway)
Сервер, который действует как посредник для некоторого
другого сервера. В отличие от прокси-сервера, шлюз получает
запросы в качестве первоначального сервера для запрошенного
ресурса; клиент запроса может не знать, что он соединяется со
шлюзом.
Туннель (tunnel)
Программа-посредник, которая поддерживает соединение. Один
раз созданный, туннель не рассматривается как часть HTTP связи,
хотя туннель, возможно, был инициализирован запросом HTTP.
Туннель прекращает существовать, когда оба конца соединения
закрываются.
Кэш (cache)
Локальная память, в которой программа хранит сообщения ответов,
и в которой располагается подсистема, управляющая хранением,
поиском и стиранием сообщений. Кэш сохраняет ответы, которые
могут быть сохранены, чтобы уменьшить время ответа и загрузку
сети (траффик) при будущих эквивалентных запросах. Любой клиент
или сервер может иметь кэш, но кэш не может использоваться
сервером, который действует как туннель.
Кэшируемый (cachable)
Ответ является кэшируемым, если кэшу разрешено сохранить копию
ответного сообщения для использования при ответе на последующие
запросы. Даже если ресурс кэшируем, могут
существовать дополнительные ограничения на использование кэшем
сохраненной копии для сходного запроса.
Непосредственный (first-hand)
Ответ считается непосредственным, если он приходит
непосредственно от первоначального сервера без ненужной задержки,
возможно через один или несколько прокси-серверов. Ответ также
является непосредственным, если его правильность только что была
проверена непосредственно первоначальным сервером.
Точное время устаревания (explicit expiration time)
Время, определенное первоначальным сервером и показывающее кэшу,
когда объект больше не может быть возвращен кэшем клиенту без
дополнительной проверки правильности.
Эвристическое время устаревания (heuristic expiration time)
Время устаревания, назначенное кэшем, если не указано точное
время устаревания.
Возраст (age)
Возраст ответа - время, прошедшее с момента отсылки, или
успешной проверки ответа первоначальным сервером.
Время жизни (freshness lifetime)
Отрезок времени между порождением ответа и временем устаревания.
Свежий (fresh)
Ответ считается свежим, если его возраст еще не превысил время
жизни.
Просроченнный (stale)
Ответ считается просроченным, если его возраст превысил время
жизни.
Семантически прозрачный (semantically transparent)
Говорят, что кэш ведет себя "семантически прозрачным" образом в
отношении специфического ответа, когда использование кэша не
влияет ни на клиента запроса, ни на первоначальный сервер, но
повышает эффективность. Когда кэш семантически прозрачен, клиент
получает точно такой же ответ (за исключением промежуточных
(hop-by-hop) заголовков), который получил бы, запрашивая
непосредственно первоначальный сервер, а не кэш.
Указатель правильности (validator)
Элемент протокола (например, метка объекта или время последней
модификации (Last-Modified time)), который используется, чтобы
выяснить, является ли находящаяся в кэше копия эквивалентом
объекта.
1.4 Общее описание.
Протокол HTTP - это протокол запросов/ответов. Клиент посылает
серверу запрос, содержащий метод запроса, URI, версию протокола,
MIME-подобное сообщение, содержащее модификаторы запроса, клиентскую
информацию, и, возможно, тело запроса, по соединению. Сервер
отвечает строкой состояния, включающей версию протокола сообщения,
код успешного выполнения или код ошибки, MIME-подобное сообщение,
содержащее информацию о сервере, метаинформацию объекта, и,
возможно, тело объекта.
Большинство HTTP соединений инициализируется агентом пользователя и
состоит из запроса, который нужно применить к ресурсу на некотором
первоначальном сервере. В самом простом случае, он может быть
выполнен посредством одиночного соединения (v) между агентом
пользователя (UA) и первоначальным сервером (O).
цепочка запросов --------------------->
UA -------------------v------------------- O
<----------------------- цепочка ответов
Более сложная ситуация возникает, когда в цепочке запросов/ответов
присутствует один или несколько посредников. Существуют три
основных разновидности посредников: прокси-сервера, шлюзы, и
туннели. Прокси-сервер является агентом-посредником, который
получает запросы на некоторый URI в абсолютной форме, изменяет все
сообщение или его часть, и отсылает измененный запрос серверу,
идентифицированному URI. Шлюз - это принимающий агент, действующий
как бы уровень выше некоторого другого сервера(ов) и, в случае
необходимости, транслирующий запросы в протокол основного сервера.
Туннель действует как реле между двумя соединениями не изменяя
сообщения; туннели используются, когда связь нужно производить
через посредника (например Firewall), который не понимает
содержание сообщений.
цепочка запросов ----------------------------------->
UA -----v----- A -----v----- B -----v----- C -----v----- O
<------------------------------------ цепочка ответов
На последнем рисунке показаны три посредника (A, B, и C) между
агентом пользователя и первоначальным сервером. Запросы и ответы
передаются через четыре отдельных соединения. Это различие важно,
так как некоторые опции HTTP соединения применимы только к
соединению с ближайшим не туннельным соседом, некоторые только к
конечным точкам цепочки, а некоторые ко всем соединениям в цепочке.
Хотя диаграмма линейна, каждый участник может быть задействован в
нескольких соединениях одновременно. Например, B может получать
запросы от других клиентов, а не только от A, и/или пересылать
запросы к серверам, отличным от C, в то же время, когда он
обрабатывает запрос от А.
Любая сторона соединения, которая не действует как туннель, может
использовать внутренний кэш для обработки запросов. Эффект кэша
заключается в том, что цепочка запросов/ответов сокращается, если
один из участников в цепочке имеет кэшированный ответ, применимый
к данному запросу. Далее иллюстрируется цепочка, возникающая в
результате того, что B имеет кэшированую копию раннего ответа O
(полеченного через C) для запроса, и который не кэшировался ни UA,
ни A.
цепочка запросов ------->
UA -----v----- A -----v----- B - - - - - - C - - - - - - O
<-------- цепочка ответов
Не все ответы полезно кэшировать, а некоторые запросы могут
содержать модификаторы, которые включают специальные требования,
управляющие поведением кэша.
Фактически, имеется широкое разнообразие архитектур и конфигураций
кэшей и прокси-серверов, в настоящее время разрабатываемых или
развернутых в World Wide Web; эти системы включают национальные
иерархии прокси-кэшей, которые сохраняют пропускную способность
межокеанских каналов, системы, которые распространяют во много
мест содержимое кэша, организации, которые распространяют
подмножества кэшируемых данных на CD-ROM, и так далее. HTTP системы
используются в корпоративных интранет-сетях с высокоскоростными
линиями связи, и для доступа через PDA с маломощными линиями и
неустойчивой связи. Цель HTTP/1.1 состоит в поддержании широкого
многообразия конфигураций, уже построенных при введении ранних
версий протокола, а также в удовлетворении потребностей
разработчиков web приложений, требующих высокой надежности, по
крайней мере надежных относительно индикации отказа.
HTTP соединение обычно происходит посредством TCP/IP соединений.
Заданный по умолчанию порт TCP - 80, но могут использоваться и
другие порты. HTTP также может быть реализован посредством любого
другого протокола Интернета, или других сетей. HTTP необходима
только надежная передача данных, следовательно может использоваться
любой протокол, который гарантирует надежную передачу данных;
отображение структуры запроса и ответа HTTP/1.1 на транспортные
модули данных рассматриваемого протокола - вопрос, не решаемый
этой спецификацией.
Большинство реализаций HTTP/1.0 использовало новое соединение для
каждого обмена запросом/ответом. В HTTP/1.1, установленное
соединение может использоваться для одного или нескольких обменов
запросом/ответом, хотя соединение может быть закрыто по ряду причин.
2 Письменные соглашения и обобщенная грамматика.
2.1 Увеличенная нормальная запись Бекуса-Наура (BNF).
Все механизмы, определенные этим документом, описаны как в обычной,
так и в увеличенной нормальной записи Бекуса-Наура (BNF), подобной
используемой в RFC 822 [9]. Разработчик должен быть знаком с такой
формой записи, чтобы понять данную спецификацию. Увеличенная
нормальная запись Бекуса-Наура включает следующие конструкции:
имя = определение
name = definition
Имя правила - это просто его название (не включающее символов
"<" и ">"), и отделяемое от определения символом равенства "=".
Пробел важен только при выравнивании продолжающихся строк,
используемых для указания определений правил, которые
занимают более одной строки. Некоторые основные правила, такие
как SP, LWS, HT, CRLF, DIGIT, ALPHA и т.д, представлены в
верхнем регистре. Угловые скобки используются в определении
всякий раз, когда их присутствие облегчает использование имен
правил.
"литерал"
"literal"
Кавычки окружают литеральный текст. Если не установлено иного,
этот текст регистро-независим.
правило1 | правило2
rule1 | rule2
Элементы, отделяемые полосой ("|") являются вариантами. Например,
"да | нет" принимает значение либо да, либо нет.
(правило1 правило2)
(rule1 rule2)
Элементы, включенные в круглые скобки обрабатываются как
один элемент. Таким образом, "(elem (foo | bar) elem)"
допускает последовательности лексем "elem foo elem" и
"elem bar elem".
*правило
*rule
Символ "*", предшествующий элементу, указывает повторение.
Полная форма - "*element" означает минимум , максимум
вхождений элемента. Значения по умолчанию - 0 и
бесконечность. Таким образом запись "*(element)" допускает
любое число повторений (в том числе ноль); запись "1*element"
требует по крайней мере одно повторение; а "1*2element"
допускает либо один, либо два повторения.
[правило]
[rule]
В квадратные скобки заключают опциональные элементы; "[foo bar]"
эквивалентно "*1(foo bar)".
N правило
N rule
Точное количество повторений: "(element)" эквивалентно
"*(element)"; то есть присутствует точно повторов
элемента. Таким образом 2DIGIT - номер из 2 цифр, а 3ALPHA
- строка из трех алфавитных символов.
#правило
#rule
Конструкция "#" предназначена, подобно "*", для определения
списка элементов. Полная форма - "#element" означает
минимум , максимум вхождений элемента, отделенных одной
или несколькими запятыми (","), и, возможно, линейным пробелом
(LWS). Это обычно делает форму списков очень простой; правило
типа "( *LWS element *( *LWS "," *LWS element)) " можно
представить как "1#элемент". Везде, где используется эта
конструкция, пустые элементы допускаются, но не учитываются при
подсчете представленных элементов. То есть конструкция
"(element), , (element)" допускается, но считаются в ней только
два элемента. Следовательно там, где требуется по крайней мере
один элемент, должен присутствовать по крайней мере один не
пустой элемент. Значения по умолчанию - 0 и бесконечность.
Таким образом запись "#(element)" допускает любое число
повторений (в том числе ноль); запись "1#element" требует по
крайней мере одного повтора ненулевого элемента; а "1*2element"
допускает один или два повтора.
; комментарий
; comment
Точка с запятой, поставленная справа от текста правила, начинает
комментарий, который продолжается до конца строки. Это - простой
способ включения полезных пометок параллельно спецификациям.
подразумевая *LWS
implied *LWS
Грамматика, описанная этой спецификацией основана на словах.
За исключением случаев, в которых отмечено иное, линейный
пробел (LWS) может быть включен между любыми двумя смежными
словами (лексемой или строкой цитирования), и между смежными
лексемами и разделителями (tspecials), не изменяя интерпретацию
поля. Между любыми двумя лексемами должен существовать по
крайней мере один разделитель (tspecials), так как иначе они
интерпретируются как одна лексема.
2.2 Основные правила.
Следующие правила используются в продолжение всей этой спецификации
для описания основных конструкций синтаксического анализа.
Кодированный набор символов US-ASCII определен в ANSI X3.4-1986 [21].
OCTET = <любая 8-битная последовательность данных>
CHAR = <любой US-ASCII символ (октеты 0 - 127)>
UPALPHA = <любой US-ASCII символ верхнего регистра
"A".."Z">
LOALPHA = <любой US-ASCII символ нижнего регистра
"a".."z">
ALPHA = UPALPHA | LOALPHA
DIGIT = <любая US-ASCII цифра "0".."9">
CTL = <любой US-ASCII управляющий символ (октеты
0 - 31) и DEL (127)>
CR = US-ASCII CR, возврат каретки (13)
LF = US-ASCII LF, перевод строки (10)
SP = US-ASCII SP, пробел (32)
HT = US-ASCII HT, метка горизонтальной
табуляции (9)
<"> = US-ASCII двойные кавычки (34)
HTTP/1.1 определяет последовательность CR LF как метку конца строки
во всех элементах протокола, за исключением тела объекта.
Метка конца строки внутри тела объекта определяется соответствующим
медиа типом.
CRLF = CR LF
HTTP/1.1 заголовки занимают несколько строк, если следующая строка
начинается с пробела или метки горизонтальной табуляции. Все
незаполненное пространство строки, включая переход на следующую
строку, имеет ту же семантику, что и SP.
LWS = [CRLF] 1*( SP | HT )
Правило TEXT используется только для описательного содержимого поля
и значений, которые не предназначены, для интерпретации
синтаксическим анализатором сообщений. Слова *TEXT могут содержать
символы из наборов символов (character sets), отличных от
ISO 8859-1 [22], только когда они закодированы согласно правилам
RFC 1522 [14].
TEXT = <любой OCTET, за исключением CTLs,
но содержащий LWS>
Шестнадцатеричные цифры используются некоторыми элементами
протокола.
HEX = "A" | "B" | "C" | "D" | "E" | "F"
| "a" | "b" | "c" | "d" | "e" | "f" | DIGIT
Многие значения полей заголовка HTTP/1.1 состоят из слов,
разделенных LWS или специальными символами. Эти специальные символы
ДОЛЖНЫ находиться в цитируемой строке (quoted string), чтобы быть
использованными в качестве значения параметра.
token = 1*<любой CHAR за исключением CTLs или
tspecials>
tspecials = "(" | ")" | "<" | ">" | "@"
| "," | ";" | ":" | "\" | <">
| "/" | "[" | "]" | "?" | "="
| "{" | "}" | SP | HT
В некоторые поля HTTP заголовка могут быть включены комментарии.
Текст комментария окружается круглыми скобками. Комментарии
допускаются только в полях, содержащих "comment" как часть
определения значения поля. Во всех других полях круглые скобки
рассматриваются частью значения поля.
comment = "(" *( ctext | comment ) ")"
ctext = <любой TEXT не включающий "(" and ")">
Строка текста анализируется как одно слово, если это цитирование,
помеченное двойными кавычками.
quoted-string = ( <"> *(qdtext) <"> )
qdtext = <любой TEXT не включающий <">>
Символ наклонной черты влево ("\") может использоваться как
односимвольный механизм цитирования только внутри конструкций
комментария и строки цитирования (quoted-string).
quoted-pair = "\" CHAR
3 Параметры протокола.
3.1 Версия HTTP.
HTTP использует схему нумерации типа ".", для указания
версии протокола. Стратегия версификации протокола предназначена
для того, чтобы позволить отправителю указать формат сообщения и
свои способности понимания для дальнейшей HTTP связи, прежде чем
он получит что-либо посредством этой связи. При добавлении
компонентов сообщения, которые не воздействуют на поведение
связи, или компонентов, которые добавляются только к расширяемым
значениям поля, номер версии не меняется. Когда внесенные в протокол
изменения добавляют возможности, которые не изменяют общий алгоритм
анализа сообщений, но которые расширяют семантику сообщения и
подразумевают дополнительные возможности отправителя, увеличивается
номер. Когда формат сообщения протокола изменяется
увеличивается номер.
Версия HTTP сообщения обозначается полем HTTP-version в первой
строке сообщения.
HTTP-Version = "HTTP" "/" 1*DIGIT "." 1*DIGIT
Обратите внимание, что major и minor числа ДОЛЖНЫ обрабатываться
как отдельные целые числа и что каждое может состоять более чем из
одной цифры. Таким образом, HTTP/2.4 - более низкая версия, чем
HTTP/2.13, которая в свою очередь ниже чем HTTP/12.3. Нули ДОЛЖНЫ
игнорироваться получателями и НЕ ДОЛЖНЫ посылаться.
Приложения, посылающие сообщения запросов или ответов, которые
описывает эта спецификация, ДОЛЖНЫ включить HTTP версию
(HTTP-version) "HTTP/1.1". Использование этого номера версии
указывает, что посылающее приложение по крайней мере условно
совместимо с этой спецификацией.
HTTP версия приложения - это самая высокая HTTP версия, для которой
приложение является по крайней мере условно совместимым.
Приложения, реализующие прокси-сервера и шлюзы, должны быть
внимательны, когда пересылают сообщения протокола различных версий.
Начиная с момента, когда версия протокола указывает возможности
отправителя, прокси-сервер/шлюз никогда НЕ ДОЛЖЕН посылать
сообщения, версия которых больше, чем HTTP версия отправителя; если
получена более высокая версия запроса, то прокси-сервер/шлюз ДОЛЖЕН
или понизить версию запроса, отдав сообщение об ошибке, или
переключиться на туннельное поведение. У запросов, версия которых
ниже, чем HTTP версия прокси-сервера/шлюза МОЖНО перед пересылкой
увеличить версию; ответ прокси-сервера/шлюза на этот запрос ДОЛЖЕН
иметь ту же самую major версию, что и запрос.
Обратите внимание: Преобразование версий HTTP может включать
модификацию полей заголовка, требуемых или запрещенных в этих
версиях.
3.2 Универсальные Идентификаторы Ресурсов (URI).
URI известны под многими именами: WWW адреса, Универсальные
Идентификаторы Документов, Универсальные Идентификаторы Ресурсов
(URI), и, в заключение, как комбинация Единообразных Идентификаторов
Ресурса (Uniform Resource Locators, URL) и Единообразных Имен
Ресурса (Uniform Resource Names, URN). HTTP определяет URL просто
как строку определенного формата, которая идентифицирует - через
имя, расположение, или любую другую характеристику - ресурс.
3.2.1 Общий синтаксис.
URI в HTTP могут представляться в абсолютной (absolute) форме или
относительно некоторой известной основы URI (relative), в
зависимости от контекста их использования. Эти две формы
различаются тем, что абсолютные URI всегда начинаются с имени
схемы с двоеточием.
URI = ( absoluteURI | relativeURI ) [ "#" fragment ]
absoluteURI = scheme ":" *( uchar | reserved )
relativeURI = net_path | abs_path | rel_path
net_path = "//" net_loc [ abs_path ]
abs_path = "/" rel_path
rel_path = [ path ] [ ";" params ] [ "?" query ]
path = fsegment *( "/" segment )
fsegment = 1*pchar
segment = *pchar
params = param *( ";" param )
param = *( pchar | "/" )
scheme = 1*( ALPHA | DIGIT | "+" | "-" | "." )
net_loc = *( pchar | ";" | "?" )
query = *( uchar | reserved )
fragment = *( uchar | reserved )
pchar = uchar | ":" | "@" | "&" | "=" | "+"
uchar = unreserved | escape
unreserved = ALPHA | DIGIT | safe | extra | national
escape = "%" HEX HEX
reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+"
extra = "!" | "*" | "'" | "(" | ")" | ","
safe = "$" | "-" | "_" | "."
unsafe = CTL | SP | <"> | "#" | "%" | "<" | ">"
national = <любой OCTET за исключением ALPHA, DIGIT,
reserved, extra, safe, и unsafe>
Полную информацию относительно синтаксиса и семантики URL смотрите
RFC 1738 [4] И RFC 1808 [11]. Вышеуказанная нормальная запись
Бекуса-Наура включает национальные символы, недозволенные в
допустимых URL (это определено в RFC 1738), так как HTTP серверы
позволяют использовать для представления части rel_path адресов
набор незарезервированных символов, и, следовательно, HTTP
прокси-сервера могут получать запросы URI, не соответствующие
RFC 1738.
Протокол HTTP не накладывает a priori никаких ограничений на длины
URI. Серверы ДОЛЖНЫ быть способны обработать URI любого ресурса,
который они обслуживают, и им СЛЕДУЕТ быть в состоянии обрабатывать
URI неограниченной длины, если они обслуживают формы, основанные
на методе GET, которые могут генерировать такой URI. Серверу
СЛЕДУЕТ возвращать код состояния 414 (URI запроса слишком длинный,
Request-URI Too Long), если URI больше, чем сервер может обработать.
Обратите внимание: Серверы должны быть осторожны с URI, которые
имеют длину более 255 байтов, потому что некоторые старые
клиенты или прокси-сервера не могут правильно поддерживать
эти длины.
3.2.2 HTTP URL.
"Http" схема используется для доступа к сетевым ресурсам при помощи
протокола HTTP. Этот раздел определяет схемо-определенный синтаксис
и семантику для HTTP URL.
http_URL = "http:" "//" host [ ":" port ] [ abs_path ]
host = <допустимое доменное имя машины
или IP адрес (в точечно-десятичной форме),
как определено в разделе 2.1 RFC 1123>
port = *DIGIT
Если порт пуст или не задан - используется порт 80. Это означает,
что идентифицированный ресурс размещен в сервере, ожидающем TCP
соединений на специфицированном порте port, компьютера host, и
запрашиваемый URI ресурса - abs_path. Использования IP адресов в
URL СЛЕДУЕТ избегать, когда это возможно (смотрите RFC 1900 [24]).
Если abs_path не представлен в URL, он ДОЛЖЕН рассматриваться как
"/" при вычислении запрашиваемого URI (Request-URI) ресурса.
3.2.3 Сравнение URI.
При сравнении двух URI, чтобы решить соответствуют ли они друг
другу или нет, клиенту СЛЕДУЕТ использовать чувствительное к
регистру пооктетное (octet-by-octet) сравнение этих URI, со
следующими исключениями:
o Порт, который пуст или не указан, эквивалентен заданному по
умолчанию порту для этого URI;
o Сравнение имен хостов ДОЛЖНО производиться без учета регистра;
o Сравнение имен схем ДОЛЖНО производиться без учета регистра;
o Пустой abs_path эквивалентен "/".
Символы, отличные от тех, что находятся в "зарезервированных"
("reserved") и "опасных" ("unsafe") наборах
эквивалентны их кодированию как ""%" HEX HEX ".
Например следующие три URI эквивалентны:
http://abc.com:80/~smith/home.html
http://ABC.com/%7Esmith/home.html
http://ABC.com:/%7esmith/home.html
4 Что такое Proxy.
Proxy сервер - это промежуточный компьютер, который
является посредником ("proxy" - посредник) между Вашим компьютером и
интернетом. Через него проходят все Ваши обращения в Internet. Proxy
их обрабатывает, и результаты (скаченные из Internet файлы) передает
Вам.
Proxy-сервер может многое. Он способен:
- ускорить Вашу работу с Internet;
- сделать Ваше путешествие по Сети анониным;
- позволить входить в чаты, даже если Вас заблокировали;
- помочь посмотреть те сайты, к которым закрыл доступ Ваш
системный администратор;
- и многое другое.
Вы можете спросить "А зачем мне нужен какой-то
там прокси? Мне и так хорошо". Действительно, еще с детства мы
знаем, что кратчайшее расстояние между двумя точками - прямая :-) Но
хитрость состоит в том, что нам-то нужно не кратчайшее расстояние, а
наилучшая скорость связи. А высокая скорость не обязательно является
следствием кратчайшего расстояния.
Представьте себе следующую ситуацию: Вы живете в
городе "A", и хотите попасть в далекий город "B" (или к Вам хотят
приехать из этого города). Вы можете воспользоваться обычным
транспортом - автобусом или железной дорогой. Но ехать таким
транспортом до места назначения очень долго. А если Вы с помощью
автобуса доберетесь до другого города - "C", где есть аэропорт, то
самолетом долетите гораздо быстрее до Вашего пункта назначения
(города "B"). Причем город "C" может находиться еще дальше от "B",
чем Ваш город "A".
Попросту говоря:
"A" >>>>(поездом)>>>> "B"
получается дольше, чем
"A" >>>(поездом)>>> "C"
>>>(самолетом)>>>>"B"
Аналогичная схема используется и тут: Вы соединяетесь с
proxy-сервером (из "A" в "C"), а proxy-сервер, используя выделенную
линию или оптоволокно (самолет) передает или получает данные с
web-сервера (из "C" в "B").
То есть связь без proxy реализуется по следующей схеме:
Ваш компьютер >>>> web-сайты
А при использовании proxy-сервера схема выглядит так:
Ваш компьютер >>>> proxy >>>> web-сайты
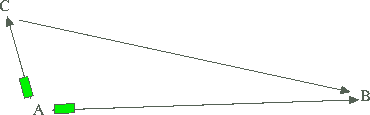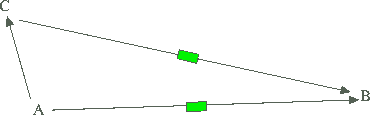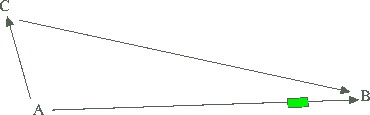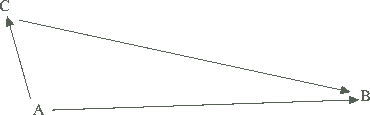
где:

запрос на получение файла / странички

установленное соединение с сервером
Разумеется, для того чтобы proxy-сервер был "самолетом", Вам
понадобится найти подходящий (поближе к Вам) и достаточно мощный
сервер (это выявляется опытным путем).
5 Системы балансировки нагрузки Web - серверов.
Инструменты для настройки производительности Web-сереров
Индустрия электронной коммерции продолжает
развиваться, и сегодня все новые компании начинают общаться со
своими клиентами с помощью Web. Высокопроизводительный сайт,
способный предоставлять материалы быстро и без сбоев, не только
помогает привлекать новых клиентов. Он становится важнейшей
предпосылкой успешной деятельности предприятий электронной торговли
и повышения их конкурентоспособности. Едва ли потенциальные клиенты
когда-нибудь вернутся на раздражающе "тихоходный" узел, где
посетитель подолгу ждет реакции на свой запрос, а то и вовсе
остается без ответа. Вот почему при планировании инфраструктуры узла
Web в любой организации мерам по повышению его производительности
следует уделять особое внимание.
Существует несколько способов повышения
быстродействия сайта: можно увеличить полосу пропускания, установить
высокопроизводительное сетевое оборудование, разработать эффективные
приложения для Web, оптимизировать и модернизировать программные и
аппаратные компоненты Web-сервера, а также взять на вооружение
технологию кэширования в среде Web.
Еще один способ повышения производительности узла
Web состоит в том, чтобы увеличить количество Web-серверов и сайтов
и размещать на них "зеркальные" копии материалов. Таким образом
можно распределить общую нагрузку по всем компонентам системы и
сократить время возврата информации при выполнении сервером
внутренних процедур обработки клиентских запросов. При этом
сохраняются и существующие серверы, поскольку выводить их из
эксплуатации и заменять новыми не придется.
Распределение, или выравнивание нагрузок,
приходящихся на несколько серверов, позволяет избежать такой
ситуации, когда передаваемые по сети Web пакеты лавиной обрушиваются
на один сервер, в то время как другие простаивают без дела. Для
распределения нагрузки между Web-серверами обычно используется
функция DNS, именуемая циклической выборкой (round-robin feature),
которая предусматривает возможность круговой передачи IP-адреса
любого Web-сервера, составляющего сайт, любому клиенту; в итоге все
Web-серверы становятся в равной степени загружены трафиком. Однако
этот механизм недостаточно эффективен в тех средах, где возможности
аппаратных и программных компонентов отдельных Web-серверов
неравнозначны. Понятно, что в среде с распределенной нагрузкой
оснащенная двумя 450-мегагерцевыми процессорами Pentium III и
памятью емкостью 1 Гбайт система под управлением Windows 2000 Server
может взять на себя более тяжелую ношу, нежели система Windows NT
Server с одним 300-мегагерцевым процессором Pentium II и 256 Мбайт
памяти. Однако с точки зрения процедуры циклической выборки службы
DNS между этими системами нет никакой разницы; более того, данная
функция "не имеет представления" о доступности того или иного
Web-сервера, поскольку не может определить, работоспособен компьютер
или вышел из строя.
Не так давно поставщики наладили выпуск систем
балансировки нагрузки - программных продуктов, которые выравнивают
нагрузку, распределяя ее по нескольким серверам. Кроме того, они
повышают отказоустойчивость Web-серверов: в случае отказа одной
машины направляют пакеты данных на другой сервер или сайт. Таким
образом, время ожидания сокращается, а число необработанных запросов
сводится к минимуму. Системы балансировки нагрузки можно
использовать как при наличии лишь одного Web-сайта, так и при работе
с целым рядом узлов. Получив представление о том, что такое системы
балансировки нагрузки и как они работают, можно определить наиболее
важные их характеристики, которые следует учитывать при выборе
средства выравнивания нагрузки.
Что такое система балансировки нагрузки
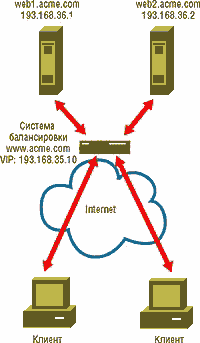
ЭКРАН 1. Система балансировки для одного сайта.
Система балансировки нагрузки Web-серверов - это
инструментальное средство, предназначенное для переадресации
клиентских запросов на наименее загруженный или наиболее подходящий
Web-сервер из группы машин, на которых хранятся зеркальные копии
информационного ресурса. Клиент не подозревает о том, что обращается
к целой группе серверов: все они представляются ему в виде некоего
единого виртуального сервера. Предположим для примера, что мы
обслуживаем один Web-сайт и имеем при этом два Web-сервера:
web1.acme.com с IP-адресом 193.168.36.1 и web2.acme.com с IP-адресом
193.168.36.2. Эту конфигурацию иллюстрирует Рисунок 1. Представляя
наш сайт пользователям Internet, система балансировки нагрузки
использует имя виртуального компьютера (пусть это будет имя
www.acme.com), а также виртуальный IP-адрес (VIP-адрес - скажем,
193.168.35.10). Чтобы связать имя виртуальной системы и
соответствующий VIP-адрес с двумя нашими Web-серверами, мы должны
опубликовать имя системы и ее VIP-адрес на сервере DNS. Система
балансировки нагрузок постоянно контролирует нагрузки и степень
готовности каждого из Web-серверов. Когда на узел http://www.acme.com/ заглядывает
посетитель, его запрос поступает не на один из Web-серверов, а в
систему балансировки нагрузки. Эта система и принимает решение о
том, на какой сервер направить запрос. При этом она руководствуется
такими критериями, как загрузка каждого подопечного сервера, а также
соблюдает условия и правила, сформулированные администратором. Затем
система балансировки нагрузки направляет запрос клиента
соответствующему серверу (как правило, она же направляет ответ
сервера клиенту, но это зависит от конкретной реализации).
Системы распределения нагрузки могут к тому же
обеспечивать выравнивание нагрузок нескольких Web-сайтов. Напомню
читателям, что применение нескольких сайтов позволяет размещать
серверы-"дублеры" (зеркальные Web-серверы) ближе к посетителям сайта
и сокращать задержки при обмене информацией между сайтом и
клиентами. Кроме того, при наличии нескольких Web-сайтов появляется
возможность равномерно распределять нагрузку между ними, а также
обеспечивать высокую степень их готовности и отказоустойчивость в
случае нарушений в работе сайта (будь то по причине сбоев в системе
энергоснабжения или из-за потери связи с Internet в вычислительном
центре). При наличии нескольких сайтов, как показано на Рисунке 2,
все системы балансировки нагрузок на всех сайтах имеют одно общее
имя виртуальной системы, но разные VIP-адреса. Так, системе
балансировки 1 на сайте 1 в Нью-Йорке присвоено имя виртуальной
главной машины http://www.acme.com/ с VIP-адресом
193.168 .35.10. А балансировщик 2 на сайте 2 в Лос-Анджелесе,
пользующийся тем же именем виртуальной главной машины, имеет уже
другой VIP-адрес - 193.200.1.10. Связи всех систем балансировки с
локальными Web-серверами устанавливаются так же, как и в случае с
одним сайтом. Наряду с мониторингом нагрузок локальных серверов
системы балансировки обмениваются со своими "коллегами" на других
сайтах информацией о конфигурации и загрузке; при этом проверяется и
степень готовности сайта. В итоге все системы балансировки имеют в
своем распоряжении общую картину распределения нагрузок и готовности
к работе различных узлов. При наличии нескольких сайтов системы
балансировки нагрузок часто параллельно выполняют еще одну задачу:
берут на себя роль серверов DNS, обслуживающих имя виртуальной
системы. Получив через DNS сигнал от клиента, указавшего данное имя,
система балансировки возвращает клиенту VIP-адрес сайта, наиболее
подходящего с учетом текущего уровня нагрузки, степени удаленности
от клиента и других параметров. Затем клиент автоматически получает
доступ к этому узлу.
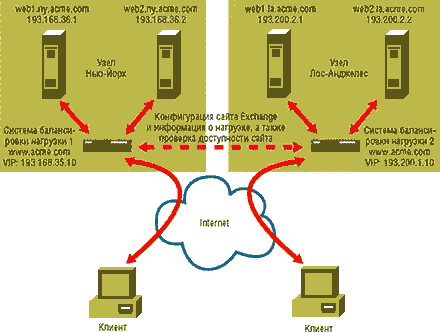
ЭКРАН 2. Система балансировки для нескольких сайтов.
Системы балансировки нагрузок делятся на три
категории: аппаратные устройства (hardware appliances), сетевые
коммутаторы и программные решения. Системы балансировки на базе
аппаратного устройства можно рассматривать как "черный ящик"; обычно
это функционирующая под управлением UNIX или фирменной ОС машина с
процессором Intel, на которой установлена разработанная поставщиком
система балансировки нагрузки. Такие системы соответствуют
спецификации Plug and Play (PnP), что облегчает работу
администраторов узлов Web. Для реализации систем балансировки на
базе сетевых коммутаторов используются коммутаторы второго и
третьего уровня. В отличие от аппаратных решений эти системы не
предусматривают установки дополнительных устройств, через которые
Web-серверы подключаются к коммутатору. Если при организации службы
распределения нагрузки в пуле Web-серверов используются программные
продукты, то можно обойтись без модификации имеющихся сетевых
средств и оборудования. Программные пакеты устанавливаются на
существующих Web-серверах или на специальных серверах выравнивания
нагрузки. Список поставщиков систем балансировки нагрузки и их
изделий приводится во врезке "Дополнительная информация о системах
балансировки". О решениях, предлагаемых корпорацией Microsoft,
рассказано во врезке "Службы балансировки Load-Balancing Services
компании Microsoft".
Вне зависимости от того, к какой категории
относится та или иная система балансировки нагрузки, она выполняет
следующие задачи: контроль за нагрузкой и состоянием серверов,
правильный выбор сервера, который будет отвечать на запрос клиента,
и управление трафиком между клиентом и сервером.
Заключение
В этой работе было выполнено исследование протокола HTTP и разработка программного
обеспечения WEB - сервера.
Список использованной литературы:
1. Б.Кришнамурти, Дж.Рексфород "WEB - протоколы. Теория и практика", 2002, 592 с.
2. Дилип Найк "Стандарты и протоколы Интернета", 1999, 384 с.
Ниже приведены ссылки на первоисточники
1.www.citforum.ru/internet/webservers/proxy_inf/proxyinf_1.shtml
По данной ссылке лежит статья "Что такое Proxy и зачем он нужен".
2.www.citforum.ru/internet/webservers/websbal.shtml
По данной ссылке лежит статья "Системы балансировки нагрузки Web-серверов".