|
Оглавление
Первоисточник
http://www.msiu.ru/~kaw25/resources/C/Daitel/glava6.htm
Библиотека
Глава
6
Тупики
Оттяжки
и проволочки —
самая ужасная форма отказа.
К.
Норткот Паркинсон
Разорвите
цепи объятий —
и гуляйте и пляшите, пока
можете.
Вистан
Хью Оден
Ссора
быстро прекращается, когда один из участников покидает
поле боя,—
не может быть столкновения, если нет двух спорящих
сторон.
Сенека
6.1
Введение
6.2
Примеры тупиков
6.2.1
Транспортная пробка как пример
тупика
6.2.2
Простой пример тупика при распределении
ресурсов
6.2.3
Тупики в системах спулинга
6.3
Аналогичная проблема — бесконечное
откладывание
6.4
Концепции ресурсов
6.5
Четыре необходимых условия для возникновения
тупика
6.6
Основные направления исследований по проблеме
тупиков
6.7
Предотвращение тупиков
6.7.1
Нарушение условия «ожидания дополнительных
ресурсов»
6.7.2
Нарушение условия
неперераспределяемости
6.7.3
Нарушение условия «кругового
ожидания»
6.8
Предотвращение тупиков и алгоритм
банкира
6.8.1
Алгоритм банкира, предложенный
Дейкстрой
6.8.2
Пример надежного состояния
6.8.3
Пример ненадежного состояния
6.8.4
Пример перехода из надежного состояния в
ненадежное
6.8.5
Распределение ресурсов согласно алгоритму
банкира
6.8.6
Недостатки алгоритма банкира
6.9
Обнаружение тупиков
6.9.1
Графы распределения ресурсов
6.9.2
Приведение графов распределения
ресурсов
6.10
Восстановление после тупиков
6.11
Тупики как критический фактор для будущих
систем
6.1
Введение
Говорят,
что в мультипрограммной системе процесс находится в
состоянии тупика, дедлока, или клинча,
если он ожидает некоторого события, которое никогда
не произойдет. Системная тупиковая ситуация, или
«зависание» системы — это ситуация, когда один или более
процессов оказываются в состоянии
тупика.
В
мультипрограммных вычислительных машинах одной из
главных функций операционной системы является
распределение ресурсов. Когда ресурсы разделяются между
многими пользователями, каждому из которых
предоставляется право исключительного управления
выделенными ему конкретными ресурсами, вполне возможно
возникновение тупиков, из-за которых процессы некоторых
пользователей никогда не смогут
завершиться.
В
настоящей главе обсуждается проблема тупиков и
приводятся основные результаты научных исследований,
посвященных вопросам предотвращения, обхода,
обнаружения тупиков и вопросам восстановления
после них. Рассматривается также тесно связанная
проблема бесконечного откладывания, когда
процесс, даже не находящийся в состоянии тупика, ожидает
события, которое может никогда не произойти из-за
«необъективных» принципов, заложенных в системе
планирования ресурсов.
Рассматриваются
возможные компромиссные решения с точки зрения накладных
затрат на включение средств борьбы с тупиками и
ожидаемых от этого выгод. В некоторых случаях цена,
которую приходится платить за то, чтобы сделать систему
свободной от тупиков, слишком высока. В других случаях,
например в системах управления процессами реального
времени, просто нет иного выбора, поскольку
возникновение тупика может привести к катастрофическим
последствиям.
6.2 Примеры
тупиков
По-видимому,
простейший способ создания тупика проиллюстрировал Холт
(Но72) в программе, написанной на языке PL/I и
предназначенной для того, чтобы привести процесс к
тупику при работе под управлением операционной системы
OS/360.
REVENGE:
PROCEDURE OPTIONS(MAINJASK);
WAIT(EVENT);
END
REVENGE;
Процесс,
связанный с приведенной программой, будет все время
ждать, чтобы произошло событие EVENT; однако в этой
программе не предусмотрена сигнализация о наступлении
ожидаемого события. Системе придется обнаруживать, что
данный процесс «завис», а затем аннулировать задание,
чтобы выйти из тупиковой ситуации. Тупики подобного типа
обнаруживать исключительно сложно.
6.2.1
Транспортная пробка как пример
тупика
На
рис. 6.1 показана транспортная пробка, которая
периодически возникает в наших городах. Ряд автомобилей
пытаются проехать через перегруженный транспортом
участок города, однако движение оказывается полностью
парализованным. Здесь образовался абсолютный затор, так
что необходимо вмешательство полиции, чтобы постепенно и
осторожно подать автомобили назад из зоны затора и тем
самым ликвидировать «пробку». В конце
концов
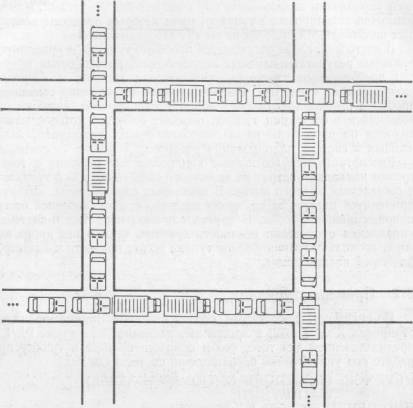
Рис.
6.1 Тупиковая
ситуация—транспортная пробка.
нормальное
движение машин восстанавливается, однако подобные
ситуации связаны с большими неприятностями, затратами
нервных усилий и значительными потерями
времени.
6.2.2
Простой пример тупика при распределении
ресурсов
В
операционных системах тупики в большинстве случаев
возникают в результате обычной конкуренции за обладание
выделяемыми, или закрепляемыми ресурсами (т. е.
ресурсами, которые в каждый момент времени отводятся
только одному пользователю и которые поэтому иногда
называются ресурсами последовательного
использования). На рис. 6.2 показан простой пример
тупика подобного рода. На этом графе распределения
ресурсов представлены два процесса (в виде
прямоугольников) и два ресурса (в виде окружностей).
Стрелка, направленная от ресурса к процессу,
показывает,
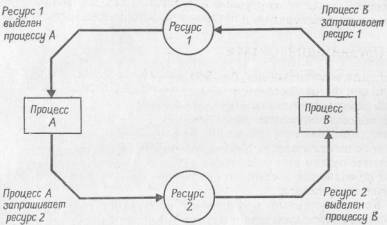
Рис.
6.2 Простая
тупиковая ситуация. Данная система оказалась в тупиковой
ситуации, поскольку каждый процесс удерживает ресурс,
запрашиваемый другим процессом, причем ни один из
процессов не хочет освободить принадлежащий ему
ресурс.
что
данный ресурс принадлежит или был выделен данному
процессу. Стрелка, направленная от процесса к ресурсу,
показывает, что данный процесс требует, но пока еще не
получил в свое распоряжение данный ресурс. На рисунке
изображена система в состоянии тупика; процесс А
удерживает в своем распоряжении ресурс 1, а для
продолжения выполнения ему необходим ресурс 2. Процесс В
удерживает ресурс 2, а для продолжения работы ему нужен
ресурс 1. Каждый процесс ждет, чтобы другой процесс
освободил нужный ему ресурс, причем каждый не
освобождает свой ресурс до тех пор, пока другой не
освободит свой ресурс, и т. д. Такое состояние кругового
ожидания характерно для систем в тупиковом
состоянии.
6.2.3
Тупики в системах спулинга
Системы
спулинга часто оказываются подвержены тупикам. Режим
спулинга (ввода-вывода с буферизацией) применяется для
повышения производительности системы путем изолирования
программы от такого низкоскоростного периферийного
оборудования, как устройства ввода данных с перфокарт и
принтеры. Если, например, программе, выдающей строки
данных на принтер, приходится ждать распечатки каждой
строки перед передачей следующей строки, то такая
программа будет выполняться медленно. Чтобы повысить
скорость выполнения программы, строки данных,
предназначенные для печати, вначале записываются на
более высокоскоростное устройство, например дисковый
накопитель, где они временно хранятся до момента
распечатки. В некоторых системах спулинга программа
должна сформировать все выходные данные — только после
этого начинается реальная распечатка. В связи с этим
несколько незавершенных заданий, формирующих строки
данных и записывающих их в файл спулинга для печати,
могут оказаться в тупиковой ситуации, если
предусмотренная емкость буфера будет заполнена до того,
как завершится выполнение какого-либо задания. Для
восстановления, или выхода из подобной тупиковой
ситуации, мог бы потребоваться перезапуск, рестарт
системы с потерей всей работы, выполненной до этого
момента. Если система попадает в тупиковую ситуацию
таким образом, что у оператора ЭВМ остаются возможности
управления, то в качестве менее радикального способа
восстановления работоспособности можно предложить
уничтожение одного или нескольких заданий, пока у
остающихся заданий не окажется достаточно свободного
места в буфере, чтобы они могли
завершиться.
Когда
системный программист производит генерацию операционной
системы, он задает размер буферных файлов для спулинга.
Один из способов уменьшить вероятность тупиков при
спулинге заключается в том, чтобы предусмотреть
значительно больше места для файлов спулинга, чем
потребуется согласно предварительной оценке. Подобное
решение не всегда осуществимо, если память дефицитна.
Более распространенное решение состоит в том, что для
процессов входного спулинга устанавливаются ограничения,
с тем чтобы они не могли принимать дополнительные
задания, когда файлы спулинга начинают приближаться к
некоторому порогу насыщения, например, оказываются
заполненными на 75 процентов. Такой подход может
привести к некоторому снижению производительности
системы, однако это — та цена, которую приходится
платить за уменьшение вероятности
тупика.
Современные
системы являются в этом смысле гораздо более
совершенными. Они могут позволять начинать распечатку до
того, как завершится очередное задание, с тем чтобы
полный или почти полный файл спулинга опустошался
полностью или частично уже в процессе выполнения
задания. Во многих системах предусматривается
динамическое распределение буферной памяти, так что,
если отведенного места в памяти оказывается мало, для
файлов спулинга выделяется дополнительная память.
Преимущества спулинга в общем случае оказываются гораздо
более весомыми, чем те проблемы, о которых шла речь
выше, однако мы хотели бы, чтобы читатель имел
представление о потенциальных сложностях проектирования
операционных систем.
6.3
Аналогичная проблема — бесконечное
откладывание
В
системе, где процессам приходится ждать, пока она
принимает решения по распределению ресурсов и
планированию, возможно возникновение ситуации, при
которой предоставление процессора некоторому процессу
будет откладываться на неопределенно долгий срок, в то
время как система будет уделять внимание другим
процессам. Такая ситуация, называемая бесконечным
откладыванием, часто может приводить к столь же
неприятным последствиям, как и
тупик.
Бесконечное
откладывание процесса может происходить из-за
«дискриминационной» политики планировщика ресурсов
системы. Когда ресурсы распределяются по приоритетному
принципу, может случиться, что данный процесс будет
бесконечно долго ожидать выделения нужного ему ресурса,
поскольку будут постоянно приходить процессы с более
высокими приоритетами. Ожидание — непременный факт нашей
жизни и безусловно важный аспект внутренней работы
вычислительных машин. При разработке операционных систем
необходимо предусматривать справедливое, а также
эффективное управление процессами, находящимися в
состоянии ожидания. В некоторых системах бесконечное
откладывание предотвращается благодаря тому, что
приоритет процесса увеличивается по мере того, как он
ожидает выделения нужного ему ресурса. Это называется
старением процесса. В конце концов, ожидающий
процесс получит более высокое значение приоритета, чем у
всех приходящих процессов, и будет
обслужен.
Для
описания и анализа систем, которые имеют дело с
управлением ожидающими объектами, создан формальный
аппарат — математическая теория очередей. Основы теории
очередей представлены в гл. 15 «Аналитическое
моделирование».
6.4 Концепции
ресурсов
Операционная
система выполняет по преимуществу функции администратора
ресурсов. Она отвечает за распределение обширных наборов
ресурсов различных типов. Отчасти именно благодаря
такому разнообразию типов ресурсов разработка
операционных систем является столь интересной темой.
Рассмотрим ресурсы, которые являются «оперативно
перераспределяемыми»1),
такие, как центральный процессор и основная память;
программа, занимающая в данный момент некоторую область
основной памяти, может быть вытеснена или передана
другой программе. Программа пользователя, которая выдала
запрос на ввод-вывод, практически не может работать с
основной памятью в течение длительного периода ожидания
завершения данной операции ввода-вывода. В
вычислительной машине самым динамичным ресурсом
является, по-видимому, центральный процессор.
Центральный процессор должен работать в режиме быстрого
переключения (мультиплексирования), обслуживая большое
число конкурирующих процессов, чтобы все эти процессы
могли продвигаться с приемлемой скоростью. Если
конкретный процесс достигает точки, когда он не может
эффективно использовать центральный процессор (как это
бывает в течение длительного периода ожидания завершения
операций ввода-вывода), право управления центральным
процессором отбирается у этого процесса и
предоставляется другому процессу. Таким, образом,
организация динамического переключения ресурсов является
исключительно важным фактором для обеспечения
эффективной работы мультипрограммных вычислительных
систем.
Определенные
виды ресурсов являются оперативно неперераспределяемыми
в том смысле, что их нельзя произвольно отбирать у
процессов, за которыми они закреплены, например,
лентопротяжные устройства, как правило, выделяются
конкретным процессам на периоды от нескольких минут до
нескольких часов. Лентопротяжный механизм, закрепленный
за одним процессом, нельзя просто отобрать у этого
процесса и передать другому.
Некоторые
виды ресурсов допускают разделение между несколькими
процессами, а некоторые предусматривают лишь монопольное
использование индивидуальными процессами. Накопители на
магнитных дисках иногда закрепляются за индивидуальными
процессами, однако чаще содержат файлы, принадлежащие
многим процессам. Основная память и центральный
процессор коллективно используются многими
процессами.
Данные
и программы — это также ресурсы, которые требуют
соответствующей организации управления и распределения.
Так, в мультипрограммных системах многим пользователям
может одновременно понадобиться прибегнуть к услугам
программы-редактора. Однако иметь собственную копию
редактора в основной памяти для каждого пользователя
было бы неэкономично. Поэтому в память записывается одна
копия кода подобной программы и несколько копий
соответствующих данных, по одной для каждого
пользователя. Поскольку с таким кодом могут одновременно
работать многие пользователи, он не должен изменяться.
Код программы, который не может изменяться во время
выполнения, называется реентерабельным, или
многократно входимым. Код, который может
изменяться, но предусматривает повторную инициализацию
при каждом выполнении, называется кодом
последовательного (многократного) использования.
С реентерабельным кодом могут: коллективно работать
несколько процессов одновременно, а с кодом
последовательного использования — только один процесс в
каждый конкретный момент времени.
Когда
речь идет о конкретных разделяемых ресурсах, мы должны
четко представлять себе, могут ли они реально
использоваться несколькими процессами одновременно или
несколькими процессами, но только одним из них в каждый
момент времени. Именно с ресурсами второго вида чаще
всего оказывается связанным возникновение
тупиков.
6.5 Четыре
необходимых условия возникновения
тупика
Коффман,
Элфик и Шошани (Со71) сформулировали следующие четыре
необходимых условия наличия
тупика.
·
Процессы
требуют предоставления им права монопольного управления
ресурсами, которые им выделяются (условие
взаимоисключения) .
·
Процессы
удерживают за собой ресурсы, уже выделенные им, ожидая в
то же время выделения дополнительных ресурсов (условие
ожидания ресурсов).
·
Ресурсы
нельзя отобрать у процессов, удерживающих их, пока эти
ресурсы не будут использованы для завершения работы
(условие
неперераспределяемости).
·
Существует
кольцевая цепь процессов, в которой каждый процесс
удерживает за собой один или более ресурсов, требующихся
следующему процессу цепи (условие кругового
ожидания).
6.6 Основные
направления исследований по проблеме
тупиков
В
связи с проблемой тупиков были проведены одни из
наиболее интересных исследований в области информатики и
операционных систем. Результаты этих исследований
оказались весьма эффективными в том смысле, что
позволили разработать четкие методы решения многих
распространенных проблем. В исследованиях по проблеме
тупиков можно выделить следующие четыре основные
направления:
·
предотвращение
тупиков;
·
обход
тупиков;
·
обнаружение
тупиков;
·
восстановление
после тупиков.
При
предотвращении тупиков целью является обеспечение
условий, исключающих возможность возникновения тупиковых
ситуаций. Такой подход является вполне корректным
решением в том, что касается самого тупика, однако он
часто приводит к нерациональному использованию ресурсов.
Тем не менее различные методы предотвращения тупиков
широко применяются в практике
разработчиков.
Цель
средств обхода тупиков заключается в том, чтобы можно
было предусматривать менее жесткие ограничения, чем в
случае предотвращения тупиков, и тем самым обеспечить
лучшее использование ресурсов. При наличии средств
обхода тупиков не требуется такой реализации системы,
при которой опасность тупиковых ситуаций даже не
возникает. Напротив, методы обхода тупиков учитывают
подобную возможность, однако в случае увеличения
вероятности конкретной тупиковой ситуации здесь
принимаются меры по аккуратному обходу тупика. (См.
обсуждение алгоритма банкира, который предложил
Дейкстра, ниже в настоящей главе.)
Методы
обнаружения тупиков применяются в системах,
которые допускают возможность возникновения тупиковых
ситуаций как следствие либо умышленных, либо
неумышленных действий программистов. Цель средств
обнаружения тупиков — установить сам факт возникновения
тупиковой ситуации, причем точно определить те процессы
и ресурсы, которые оказались вовлеченными в данную
тупиковую ситуацию. После того как все это сделано,
данную тупиковую ситуацию в системе можно будет
устранить.
Методы
восстановления после тупиков применяются для
устранения тупиковых ситуаций, с тем чтобы система могла
продолжать работать, а процессы, попавшие в тупиковую
ситуацию, могли завершиться с освобождением занимаемых
ими ресурсов. Восстановление — это, мягко говоря, весьма
серьезная проблема, так что в большинстве систем оно
осуществляется путем полного выведения из решения одного
или более процессов, попавших в тупиковую ситуацию.
Затем выведенные процессы обычно перезапускаются с
самого начала, так что почти вся или даже вся работа,
проделанная этими процессами,
теряется.
6.7
Предотвращение тупиков
До
сих пор разработчики систем при решении проблемы тупиков
чаще всего шли по пути исключения самих возможностей
тупиков. В настоящем разделе рассматриваются различные
методы предотвращения тупиков, а также оцениваются
различные последствия их реализации как для
пользователя, так и для систем, особенно с точки зрения
эксплуатационных характеристик и эффективности
работы.
Хавендер
(Hv68) показал, что возникновение тупика невозможно,
если нарушено хотя бы одно из указанных выше четырех
необходимых условий. Он предложил следующую
стратегию.
·
Каждый
процесс должен запрашивать все требуемые ему ресурсы
сразу, причем не может начать выполняться до тех пор,
пока все они не будут ему
предоставлены.
·
Если
процесс, удерживающий определенные ресурсы, получает
отказ в удовлетворении запроса на дополнительные
ресурсы, этот процесс должен освободить свои
первоначальные ресурсы и при необходимости запросить их
снова вместе с дополнительными.
·
Введение
линейной упорядоченности по типам ресурсов для всех
процессов; другими словами, если процессу выделены
ресурсы данного типа, в дальнейшем он может запросить
только ресурсы более далеких по порядку
типов.
Отметим,
что Хавендер предлагает три стратегических принципа, а
не четыре. Каждый из указанных принципов, как мы увидим
в следующих разделах, имеет целью нарушить какое-нибудь
одно из необходимых условий существования тупика. Первое
необходимое условие, а именно условие взаимоисключения,
согласно которому процессы получают право на монопольное
управление выделяемыми им ресурсами, мы не хотим
нарушать, поскольку нам, в частности, нужно
предусмотреть возможность работы с закрепленными
ресурсами.
6.7.1
Нарушение условия «ожидания дополнительных
ресурсов»
Первый
стратегический принцип Хавендера требует, чтобы процесс
сразу же запрашивал все ресурсы, которые ему
понадобятся. Система должна предоставлять эти ресурсы по
принципу «все или ничего». Если набор ресурсов,
необходимый процессу, имеется, то система может
предоставить все эти ресурсы данному процессу сразу же,
так что он получит возможность продолжить работу. Если в
текущий момент полного набора ресурсов, необходимых
процессу, нет, этому процессу придется ждать, пока они
не освободятся. Однако, когда процесс находится в
состоянии ожидания, он не должен удерживать какие-либо
ресурсы. Благодаря этому предотвращается возникновение
условия «ожидания дополнительных ресурсов» и тупиковые
ситуации просто невозможны.
На
первый взгляд это звучит неплохо, однако подобный подход
может привести к серьезному снижению эффективности
использования ресурсов. Например, программа, которой в
какой-то момент работы требуются 10 лентопротяжных
устройств, должна запросить — и получить — все 10
устройств, прежде чем начать выполнение. Если все 10
устройств необходимы программе в течение всего времени
выполнения, то это не приведет к серьезным потерям.
Рассмотрим, однако, случай, когда программе для начала
работы требуется только одно устройство (или, что еще
хуже, ни одного), а оставшиеся устройства потребуются
лишь через несколько часов. Таким образом, требование о
том, что программа должна
запросить
и
получить все эти устройства, чтобы начать выполнение, на
практике означает, что значительная часть ресурсов
компьютера будет использоваться вхолостую в течение
нескольких часов.
Один
из подходов, к которому часто прибегают разработчики
систем с целью улучшения использования ресурсов в
подобных обстоятельствах, заключается в том, чтобы
разделять программу на несколько программных шагов,
выполняемых относительно независимо друг от друга.
Благодаря этому можно осуществлять выделение ресурсов
для каждого шага программы, а не для целого процесса.
Это позволяет уменьшить непроизводительное использование
ресурсов, однако связано с увеличением накладных
расходов на этапе проектирования прикладных программ, а
также на этапе их выполнения.
Такая
стратегия существенно повышает вероятность бесконечного
откладывания, поскольку не все требуемые ресурсы могут
оказаться свободными в нужный момент. Вычислительная
система должна позволить завершиться достаточно большому
числу заданий и освободить их ресурсы, чтобы ожидающее
задание смогло продолжить выполнение. В течение периода,
когда требуемые ресурсы накапливаются, их нельзя
выделять другим заданиям, так что эти ресурсы
простаивают. В настоящее время существуют противоречивые
мнения о том, кто должен платить за эти неиспользуемые
ресурсы. Некоторые разработчики считают, что, поскольку
ресурсы накапливаются для конкретного пользователя, этот
пользователь должен платить за них, даже в течение
периода простоя ресурсов. Однако другие разработчики
считают, что это привело бы к нарушению принципа
предсказуемости платы за ресурсы, если
пользователь попытается выполнить свою работу в период
пиковой загрузки машины, ему придется платить гораздо
больше, чем в случае, когда машина относительно
свободна.
6.7.2
Нарушение условия
неперераспределяемости
Второй
стратегический принцип Хавендера, рассматриваемый здесь
независимо от других, предотвращает возникновение
условия неперераспределяемости. Предположим, что система
позволяет процессам, запрашивающим дополнительные
ресурсы, удерживать за собой ранее выделенные ресурсы.
Если у системы достаточно свободных ресурсов, чтобы
удовлетворять все запросы, тупиковая ситуация не
возникнет. Посмотрим, однако, что произойдет, когда
какой-то запрос удовлетворить не удастся. В этом случае
один процесс удерживает ресурсы, которые могут
потребоваться второму процессу для продолжения работы, а
этот второй процесс может удерживать ресурсы,
необходимые первому. Это и есть
тупик.
Второй
стратегический принцип Хавендера требует, чтобы процесс,
имеющий в своем распоряжении некоторые ресурсы, если он
получает отказ на запрос о выделении дополнительных
ресурсов,
должен
освобождать свои ресурсы и при необходимости запрашивать
их снова вместе с дополнительными. Такая стратегия
действенно ведет к нарушению условия
неперераспределяемости, подобным образом можно забирать
ресурсы у удерживающих их процессов до завершения этих
процессов.
Но
этот способ предотвращения тупиковых ситуаций также не
свободен от недостатков. Если процесс в течение
некоторого времени использует определенные ресурсы, а
затем освобождает эти ресурсы, он может потерять всю
работу, проделанную до данного момента. На первый взгляд
такая цена может показаться слишком высокой, однако
необходим реальный ответ на вопрос «насколько часто
приходится платить такую цену?» Если такая ситуация
встречается редко, то можно считать, что в нашем
распоряжении имеется относительно недорогой способ
предотвращения тупиков. Если, однако, такая ситуация
встречается часто, то подобный способ обходится дорого,
причем приводит к печальным результатам, особенно когда
не удается вовремя завершить высокоприоритетные или
срочные процессы.
Одним
из серьезных недостатков такой стратегии является
возможность бесконечного откладывания процессов.
Выполнение процесса, который многократно запрашивает и
освобождает одни и те же ресурсы, может откладываться на
неопределенно долгий срок. В этом случае у системы может
возникнуть необходимость вывести данный процесс из
решения, с тем чтобы другие процессы получили
возможность продолжения работы. Нельзя игнорировать и
вероятный случай, когда процесс, откладываемый
бесконечно, может оказаться не очень «заметным» для
системы. В такой ситуации возможно поглощение процессом
значительных вычислительных ресурсов и деградация
производительности системы.
6.7.3
Нарушение условия «кругового
ожидания»
Третий
стратегический принцип Хавендера исключает круговое
ожидание. Поскольку всем ресурсам присваиваются
уникальные номера и поскольку процессы должны
запрашивать ресурсы в порядке возрастания номеров,
круговое ожидание возникнуть не
„может.
Такой
стратегический принцип реализован в ряде операционных
систем, однако это оказалось сопряжено с определенными
трудностями.
·
Поскольку
запрос ресурсов осуществляется в порядке возрастания их
номеров и поскольку номера ресурсов назначаются при
установке машины и должны «жить» в течение длительных
периодов времени (месяцев или даже лет), то в случае
введения в машину новых типов ресурсов может возникнуть
необходимость переработки существующих программ и
систем.
·
Очевидно,
что назначаемые номера ресурсов должны отражать
нормальный порядок, в котором большинство заданий
фактически используют ресурсы. Для заданий, выполнение
которых соответствует этому порядку, можно ожидать
высокой эффективности. Если, однако, заданию требуются
ресурсы не в том порядке, который предполагает
вычислительная система, то оно должно будет захватывать
и удерживать ресурсы, быть может, достаточно долго еще
до того, как они будут фактически использоваться. А это
означает потерю эффективности.
·
Одной
из самых важных задач современных операционных систем
является ^предоставление пользователю максимальных
удобств для работы («дружественной» обстановки).
Пользователи должны иметь возможность разрабатывать свои
прикладные программы при минимальном «загрязнении своей
окружающей среды» из-за ограничений, накладываемых
недостаточно удачными аппаратными и программными
средствами. Последовательный порядок заказа ресурсов,
предложенный Хавендером, действительно исключает
возможность возникновения кругового ожидания, однако
безусловно отрицательно сказывается при этом на
возможности пользователя свободно и легко писать
прикладные программы.
6.8
Предотвращение тупиков и алгоритм
банкира
Если
даже необходимые условия возникновения тупиков не
нарушены, то все же можно избежать тупиковой ситуации,
если рационально распределять ресурсы, придерживаясь
определенных правил. По-видимому, наиболее известным
алгоритмом обхода тупиковых ситуаций является алгоритм
банкира, который предложил Дейкстра (Di 65); алгоритм
получил такое любопытное наименование потому, что он как
бы имитирует действия банкира, который, располагая
определенным источником капитала, выдает ссуды и
принимает платежи. Ниже мы изложим этот алгоритм
применительно к проблеме распределения ресурсов в
операционных системах.
6.8.1
Алгоритм банкира, предложенный
Дейкстрой
Когда
при описании алгоритма банкира мы будем говорить о
ресурсах, мы будем подразумевать ресурсы одного и того
же типа, однако этот алгоритм можно легко распространить
на пулы ресурсов нескольких различных типов. Рассмотрим,
например, проблему распределения некоторого количества
t идентичных лентопротяжных
устройств.
Операционная
система должна обеспечить распределение некоторого
фиксированного числа t одинаковых лентопротяжных
устройств между некоторым фиксированным числом
пользователей и. Каждый пользователь заранее
указывает максимальное число устройств, которые ему
потребуются во время выполнения своей программы на
машине. Операционная система примет запрос пользователя
в случае, если максимальная потребность этого
пользователя в лентопротяжных устройствах не превышает
t.
Пользователь
может занимать или освобождать устройства по одному.
Возможно, что иногда пользователю придется ждать
выделения дополнительного устройства, однако
операционная система гарантирует, что ожидание будет
конечным. Текущее число устройств, выделенных
пользователю, никогда не превысит указанную максимальную
потребность этого пользователя. Если операционная
система в состоянии удовлетворить максимальную
потребность пользователя в устройствах, то пользователь
гарантирует, что эти устройства будут использованы и
возвращены операционной системе в течение конечного
периода времени.
Текущее
состояние вычислительной машины называется надежным,
если операционная система может обеспечить всем
текущим пользователям завершение их заданий в течение
конечного времени. (Здесь опять-таки предполагается, что
лентопротяжные устройства являются единственными
ресурсами, которые запрашивают пользователи.) В
противном случае текущее состояние системы называется
ненадежным.
Предположим
теперь, что работают n
пользователей.
Пусть
l(i) представляет текущее количество
лентопротяжных устройств, выделенных i
пользователю. Если, например, пользователю 5
выделены четыре устройства, то l(5)=4. Пусть
т(i) — максимальная потребность пользователя
i, так что если пользователь 3 имеет максимальную
потребность в двух устройствах, то m(3)=2. Пусть
c(t) — текущая потребность пользователя, равная
его максимальной потребности минус текущее число
выделенных ему ресурсов. Если, например, пользователь 7
имеет максимальную потребность в шести лентопротяжных
устройствах, а текущее количество выделенных ему
устройств составляет четыре, то мы
получаем
с
(7)=m
(7) - 1(7)=6 - 4=2.
В
распоряжении операционной системы имеются t
лентопротяжных устройств. Число устройств,
остающихся для распределения, обозначим через а.
Тогда а равно t минус суммарное число
устройств, выделенных различным
пользователям.
Алгоритм
банкира, который предложил Дейкстра, говорит о том, что
выделять лентопротяжные устройства пользователям можно
только в случае, когда после очередного выделения
устройств состояние системы остается надежным. Надежное
состояние — это состояние, при котором общая ситуация с
ресурсами такова, что все пользователи имеют возможность
со временем завершить свою работу. Ненадежное состояние
— это состояние, которое может со временем привести к
тупику.
6.8.2
Пример надежного состояния
Предположим,
что в системе имеются двенадцать одинаковых
лентопротяжных устройств, причем эти накопители
распределяются между тремя пользователями, как
показывает состояние I.
Состояние
I
|
|
Текущее
количество
выделенных устройств |
|
Максимальная
потребность |
|
Пользователь
(1) |
1 |
|
4 |
|
Пользователь
(2) |
4 |
|
6 |
|
Пользователь
(3) |
5 |
|
8 |
|
Резерв |
|
2 |
|
Это
состояние «надежное», поскольку оно дает возможность
всем трем пользователям закончить работу. Отметим, что в
текущий момент пользователь (2) имеет четыре выделенных
ему устройства и со временем потребует максимум шесть,
т. е. два дополнительных устройства. В распоряжении
системы имеются двенадцать устройств, из которых десять
в настоящий момент в работе, а два — в резерве. Если эти
два резервных устройства, имеющихся в наличии, выделить
пользователю (2), удовлетворяя тем самым максимальную
потребность этого пользователя, то он сможет продолжать
работу до завершения. После завершения пользователь (2)
освободит все шесть своих устройств так что система
сможет выделить их пользователю (1) и пользователю (3).
Пользователь (1) имеет одно устройство и со временем ему
потребуется еще три. У пользователя (3) — пять устройств
и со временем ему потребуется еще три. Если пользователь
(2) возвращает шесть накопителей, то три из них можно
выделить пользователю (1), который получит таким образом
возможность закончить работу и затем возвратить четыре
накопителя системе. После этого система может выделить
три накопителя пользователю (3), который тем самым также
получает возможность закончить работу. Таким образом,
основной критерий надежного состояния — это
существование последовательности действий, позволяющей
всем пользователям закончить
работу.
6.8.3
Пример ненадежного состояния
Предположим,
что двенадцать лентопротяжных устройств, имеющихся в
системе, распределены согласно состоянию
II.
Состояние
II
|
|
Текущее
количество
выделенных устройств |
|
Максимальная
потребность |
|
Пользователь
(1) |
8 |
|
10 |
|
Пользователь
(2) |
2 |
|
5 |
|
Пользователь
(3) |
1 |
|
3 |
|
Резерв |
|
1 |
|
Здесь
из двенадцати устройств системы одиннадцать в настоящий
момент находятся в работе и только одно остается в
резерве. В подобной ситуации независимо от того, какой
пользователь запросит это резервное устройство, мы не
можем гарантировать, что все три пользователя закончат
работу. И действительно, предположим, что пользователь
(1) запрашивает и получает последнее оставшееся
устройство. При этом тупиковая ситуация может возникать
в трех случаях, когда каждому из трех процессов
потребуется запросить по крайней мере одно
дополнительное устройство, не возвратив некоторое
количество устройств в общий пул
ресурсов.
Здесь
важно отметить, что термин «ненадежное состояние'!)
не. предполагает, что в данный момент существует или в
какое-то время обязательно возникнет тупиковая ситуация.
Он просто говорит о том, что в случае некоторой
неблагоприятной последовательности событий система может
зайти в тупик.
6.8.4
Пример перехода из надежного состояния в
ненадежное
Если
известно, что данное состояние надежно, это вовсе не
означает, что все последующие состояния также будут
надежными. Наш механизм распределения ресурсов должен
тщательно анализировать все запросы на выделение
ресурсов, прежде чем удовлетворять их. Рассмотрим,
например, случай, когда система находится в текущем
состоянии, показанном как состояние
III.
Предположим
теперь, что пользователь (3) запрашивает дополнительный
ресурс. Если бы система удовлетворила этот запрос, она
перешла бы в новое состояние, состояние
IV.
Конечно,
состояние IV не обязательно приведет к тупиковой
ситуации. Если, однако, состояние III было надежным, то
состояние IV стало ненадежным. Состояние IV
характеризует систему,
Состояние
III
|
|
Текущее
количество
выделенных устройств |
|
Максимальная
потребность |
|
Пользователь
(1) |
1 |
|
4 |
|
Пользователь
(2) |
4 |
|
6 |
|
Пользователь
(3) |
5 |
|
8 |
|
Резерв |
|
2 |
|
Состояние
IV
|
|
Текущее
количество
выделенных устройств |
|
Максимальная
потребность |
|
Пользователь
(1) |
1 |
|
4 |
|
Пользователь
(2) |
4 |
|
6 |
|
Пользователь
(3) |
6 |
|
8 |
|
Резерв |
|
1 |
|
в
которой нельзя гарантировать успешное завершение всех
процессов пользователей. В резерве здесь остается только
один ресурс, в то время как в наличии должно быть
минимум два ресурса, чтобы либо пользователь (2), либо
пользователь (3) могли завершить свою работу, возвратить
занимаемые ими ресурсы системе и тем самым позволить
остальным пользователям закончить
выполнение.
6.8.5
Распределение ресурсов согласно алгоритму
банкира
Сейчас
уже должно быть ясно, каким образом осуществляется
распределение ресурсов согласно алгоритму банкира,
который предложил Дейкстра. Условия «взаимоисключения»,
«ожидания дополнительных ресурсов» и
«неперераспределяемости» выполняются. Процессы могут
претендовать на монопольное использование ресурсов,
которые им требуются. Процессам реально разрешается
удерживать за собой ресурсы, запрашивая и ожидая
выделения дополнительных ресурсов, причем ресурсы нельзя
отбирать у процесса, которому они выделены. Пользователи
не ставят перед системой особенно сложных задач,
запрашивая в каждый момент времени только один ресурс.
Система может либо удовлетворить, либо отклонить каждый
запрос. Если запрос отклоняется, пользователь удерживает
за собой уже выделенные ему ресурсы и ждет определенный
конечный период времени, пока этот запрос в конце концов
не будет удовлетворен. Система удовлетворяет только
те запросы, при которых ее состояние остается надежным.
Запрос пользователя, приводящий к переходу системы в
ненадежное состояние, откладывается до момента, когда
его все же можно будет выполнить. Таким образом,
поскольку система всегда поддерживается в надежном
состоянии, рано или поздно (т. е. в течение конечного
времени) все запросы можно будет удовлетворить и все
пользователи смогут завершить свою
работу.
6.8.6
Недостатки алгоритма банкира
Алгоритм
банкира представляет для нас интерес потому, что он дает
возможность распределять ресурсы таким образом, чтобы
обходить тупиковые ситуации. Он позволяет продолжать
выполнение таких процессов, которым в случае системы с
предотвращением тупиков пришлось бы ждать. Однако у
этого алгоритма имеется ряд серьезных недостатков, из-за
которых разработчик системы может оказаться вынужденным
выбрать другой подход к решению проблемы
тупиков.
·
Алгоритм
банкира исходит из фиксированного количества
распределяемых ресурсов. Поскольку устройства,
представляющие ресурсы, зачастую требуют технического
обслуживания либо из-за возникновения неисправностей,
либо в целях профилактики, мы не можем считать, что
количество ресурсов всегда остается
фиксированным.
·
Алгоритм
требует, чтобы число работающих пользователей оставалось
постоянным. Подобное требование также является
нереалистичным. В современных мультипрограммных системах
количество работающих пользователей все время меняется.
Например, большая система с разделением времени вполне
может обслуживать 100 или более пользователей
одновременно. Однако текущее число обслуживаемых
пользователей непрерывно меняется, быть может, очень
часто, каждые несколько секунд.
·
Алгоритм
требует, чтобы банкир—распределитель ресурсов
гарантированно удовлетворял все запросы за некоторый
конечный период времени. Очевидно, что для реальных
систем необходимы гораздо более конкретные
гарантии.
·
Аналогично,
алгоритм требует, чтобы клиенты (т. е. задания или
процессы) гарантированно «платили долги» (т. е.
возвращали выделенные им ресурсы) в течение некоторого
конечного времени. И опять-таки для реальных систем
требуются гораздо более конкретные
гарантии.
·
Алгоритм
требует, чтобы пользователи заранее указывали свои
максимальные потребности в ресурсах. По мере того как
распределение ресурсов становится все более динамичным,
все труднее оценивать максимальные потребности
пользователя. Вообще говоря, поскольку компьютеры
становятся более «дружественными» по отношению к
пользователю, все чаще встречаются пользователи, которые
не имеют ни малейшего представления о том, какие ресурсы
им потребуются.
6.9
Обнаружение тупиков
Обнаружение
тупика — это установление факта, что возникла тупиковая
ситуация, и определение процессов и ресурсов,
вовлеченных в эту тупиковую ситуацию. Алгоритмы
обнаружения тупиков, как правило, применяются в
системах, где выполняются первые три необходимых условия
возникновения тупиковой ситуации. Эти алгоритмы затем
определяют, не создался ли режим кругового
ожидания.
Применение
алгоритмов обнаружения тупиков сопряжено с определенными
дополнительными затратами машинного времени. Таким
образом, здесь мы снова сталкиваемся с необходимостью
прибегать к компромиссным решениям, столь
распространенным в операционных системах. Будут ли
накладные расходы, связанные с реализацией алгоритмов
обнаружения тупиковых ситуаций, в достаточной степени
оправданы потенциальными выгодами от локализации и
устранения тупиков? В данный момент мы этот вопрос
рассматривать не будем, а лучше сосредоточим свое
внимание на описании алгоритмов, позволяющих
обнаруживать тупики.
6.9.1
Графы распределения ресурсов
При
рассмотрении задачи обнаружения тупиков применяется
весьма распространенная нотация, согласно которой
распределение ресурсов и запросы изображаются в виде
направленного графа. Квадраты обозначают процессы, а
большие кружки — классы идентичных ресурсов. Малые
кружки, находящиеся внутри больших, обозначают
количество идентичных ресурсов каждого класса. Например,
если в большом кружке с меткой R1 содержатся три малых
кружка, это говорит о том, что система имеет в
наличии три эквивалентных ресурса типа
R1.
На
рис. 6.3 показаны отношения, которые могут быть
представлены на графе запросов и распределения ресурсов.
На рис. б.З(а) показано/что процесс Р1 запрашивает
ресурс типа R1. Стрелка от квадрата Р1 доходит только до
большого кружка — это говорит о том, что в текущий
момент запрос от процесса на выделение данного ресурса
находится в стадии рассмотрения.
На
рис. 6.3(6) показано, что процессу Р2 выделен ресурс
типа R2 (один из двух идентичных ресурсов),— здесь
стрелка прочерчена
от
малого кружка, находящегося внутри большого кружка R2,
до квадрата Р2.
На
рис. 6.3(в) показана ситуация, в некоторой степени
приближающаяся к потенциальному тупику: процесс РЗ
запрашивает ресурс R3, выделенный процессу
Р4.
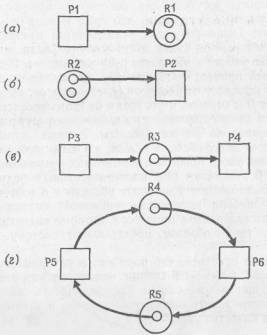
Рис.
6.3
Граф запросов и распределения ресурсов: .а) процесс Р1
запрашивает ресурс типа R1;
б)
ресурс типа R2 выделен процессу
Р2;
в)
процесс РЗ запрашивает ресурс R3, который выделен
процессу Р4;
г)
процессу Р5 выделен ресурс R5, необходимый процессу Р6,
которому выделен ресурс R4, необходимый процессу Р5
(«круговое ожидание»).
На
рис. 6.3(г) показана небольшая система в тупиковой
ситуации, когда процесс Р5 запрашивает ресурс R4,
который выделен процессу Р6, который запрашивает ресурс
R5, который выделен процессу Р5, который в свою очередь
запрашивает ресурс R4 — это пример «кругового ожидания»,
типичного для системы в состоянии
тупика.
Графы
запросов и распределения ресурсов динамично меняются по
мере того, как процессы запрашивают ресурсы, получают их
в свое распоряжение, а через какое-то время возвращают
операционной системе.
6.9.2
Приведение графов распределения
ресурсов
Задача
механизма обнаружения тупиков — определить, не возникла
ли в системе тупиковая ситуация. Одним из способов
обнаружения тупиков является приведение, или редукция
графа,— это позволяет определять процессы, которые могут
завершиться, и процессы, которые будут оставаться в
тупиковой ситуации.
Если
запросы ресурсов для некоторого процесса могут быть
удовлетворены, то мы говорим, что граф можно
редуцировать на этот процесс. Такая редукция
эквивалентна изображению графа в том виде, который он
будет иметь в случае, если данный процесс завершит свою
работу и возвратит ресурсы системе. Редукция графа на
конкретный процесс изображается исключением стрелок,
идущих к этому процессу от ресурсов (т. е. ресурсов,
выделенных дан-' ному процессу) и стрелок к ресурсам от
этого процесса (т. е. текущих запросов данного процесса
на выделение ресурсов). Если граф можно редуцировать
на все процессы, значит, тупиковой ситуации нет, а если
этого сделать нельзя, то все «нередуцируемые» процессы
образуют набор процессов, вовлеченных в тупиковую
ситуацию.
На
рис. 6.4 показан ряд последовательных редукций графа,
которые в конце концов позволяют убедиться в том, что
для этого конкретного набора процессов тупиковой
ситуации нет. На рис. 6.3(г) показана пара процессов,
которые являются «нередуцируемыми» и, таким образом,
представляют систему в тупиковой
ситуации.
Здесь
важно отметить, что порядок, в котором осуществляется
редукция графа, не имеет значения: окончательный
результат в любом случае будет тем же самым.
Справедливость такого утверждения продемонстрировать
относительно легко, и читатель может сам это сделать в
качестве упражнения.
6.10
Восстановление после тупиков
Систему,
оказавшуюся в тупике, необходимо вывести из него,
нарушив одно или несколько необходимых условий его
существования. При этом, как правило, несколько
процессов потеряют частично или полностью уже
проделанную ими работу. Однако это обойдется гораздо
дешевле, чем оставлять систему в тупиковой ситуации.
Сложность восстановления системы, т. е. ее вывода из
тупика, обусловливается рядом
факторов.
·
Прежде
всего, в первый момент вообще может быть неочевидно, что
система попала в тупиковую
ситуацию.
·
В
большинстве систем нет достаточно эффективных средств,
позволяющих приостановить процесс на неопределенно
долгое время, вывести его из системы и возобновить его
выполнение впоследствии. В действительности некоторые
процессы, например процессы реального времени, должны
работать непрерывно и не допускают приостановки и
последующего возобновления.
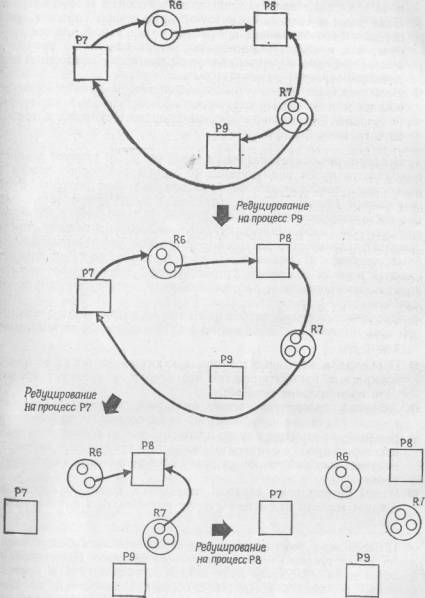
Рис.
6.4 Редукция
графа.
·
Если
даже в системе существуют эффективные средства
приостановки/возобновления процессов, то их
использование требует, как правило, значительных затрат
машинного времени, а также внимания
высококвалифицированного оператора. А подобного
оператора может и не быть.
·
Восстановление
после тупика небольших масштабов требует обычно и
небольшого количества работы; крупный же тупик (с
участием десятков или даже сотен процессов) может
потребовать громадной работы.
В
современных системах восстановление после тупиков обычно
выполняется путем принудительного вывода некоторого
процесса из системы, чтобы можно было использовать его
ресурсы. Этот выведенный процесс обычно теряется, однако
теперь остальные процессы получают возможность завершить
свою работу. В некоторых случаях необходимо уничтожить
несколько процессов, чтобы освободить количество
ресурсов, достаточное для завершения работы остающихся
процессов. Здесь сам термин «восстановление» кажется в
какой-то степени неправомерным. Это все равно что
говорить о восстановлении работоспособности руки путем
ампутации пальца.
Процессы
могут выводиться из системы в соответствии с некоторой
приоритетностью. Здесь мы также сталкиваемся с
несколькими трудностями.
·
Процессы,
вовлеченные в тупиковую ситуацию, могут не иметь
конкретных приоритетов, так что оператору придется
принимать произвольное решение.
·
Значения
приоритетов могут оказаться неправильными или в какой-то
степени нарушаться из-за определенных особых
соображений, например в случае планирования по конечному
сроку некоторый процесс с относительно низким
приоритетом временно получает высокий приоритет ввиду
приближающегося конечного срока.
·
Чтобы
оптимальным образом определить, какой из процессов
следует вывести из системы, могут потребоваться
значительные усилия.
По
всей вероятности, самый целесообразный способ
восстановления после тупиков — это эффективный механизм
приостановки/ возобновления процессов. Этот механизм
позволяет нам кратковременно переводить процессы в
состояние ожидания, а затем активизировать ожидающие
процессы, причем без потери результатов работы.
Исследования в этой области имеют важное значение не
только в связи с проблемой выхода из тупиковых ситуаций.
Так, например, может возникнуть необходимость на
какое-то время выключить систему, а затем запустить ее
снова с той же точки без
потери
промежуточных результатов. В подобном случае механизм
приостановки/возобновления может оказаться весьма
эффективным. Средства рестарта с контрольной точки,
реализованные во многих системах, обеспечивают
приостановку/возобновление вычислений с потерей
результатов только после последней контрольной точки (от
момента, когда запоминалось состояние системы). Однако в
конструкции многих систем такой достаточно эффективный
механизм контрольных точек с рестартом не предусмотрен.
Поэтому разработчикам прикладных программ обычно
приходится тратить усилия на включение контрольных точек
с возможностью рестарта в свою программу, так что если
речь не идет о программах, выполнение которых требует
много часов машинного времени, подобный механизм
применяется редко.
Тупики
могут приводить к катастрофическим последствиям в
некоторых системах реального времени. Так, система
управления процессами реального времени, ответственная
за нормальную работу нефтеперерабатывающего предприятия,
просто обязана непрерывно функционировать, поскольку от
этого зависит безопасность и нормальная деятельность
предприятия. В подобных условиях малейшего риска
оказаться в тупике быть не должно. Что же делать, если
тупиковая ситуация все же возникнет? Очевидно, что ее
необходимо мгновенно обнаруживать и устранять. Однако
всегда ли это возможно? Таковы некоторые из проблем, не
позволяющие спокойно спать разработчикам операционных
систем.
6.11 Тупики
как критический фактор для будущих
систем
В
современных вычислительных системах тупиковые ситуации
обычно рассматриваются как неприятность ограниченного
характера. В большинстве систем реализуются основные
методы предотвращения тупиков, предложенные Хавендером,
причем эти методы кажутся вполне
удовлетворительными.
Однако
в будущих системах тупики станут в гораздо большей мере
критическим фактором — по нескольким
причинам.
·
Эти
системы будут в гораздо большей степени ориентированы на
асинхронную параллельную работу, чем прежние системы с
преобладанием последовательных режимов. Всеобщее
распространение получат мультипроцессорные архитектуры,
а параллельные вычисления займут доминирующее положение.
Попросту говоря, в системах будет гораздо больше
операций, выполняемых
одновременно.
·
В
этих системах будет реализовано преимущественно
динамическое распределение ресурсов. Процессы получат
возможность свободно захватывать и освобождать ресурсы
по мере необходимости. Пользователям не придется
заблаговременно, до начала выполнения своих программ,
достаточно точно оценивать свои потребности в ресурсах.
В действительности с появлением «дружественных»
интерфейсов будущего, о которых сейчас много говорят,
большинство пользователей сможет практически не
задумываться о том, какие ресурсы потребуются для
выполнения их процессов.
·
Среди
разработчиков операционных систем растет тенденция
рассматривать данные как ресурс, и в связи с этим
количество ресурсов, которыми должны будут управлять
операционные системы, резко
увеличится.
Таким
образом, в будущих вычислительных машинах
ответственность за распределение ресурсов с недопущением
тупиков будет ложиться на операционную систему. Если
учесть, что вычислительные ресурсы становятся дешевле,
то вполне целесообразно, чтобы компьютер и его
операционная система приняли на себя подобные
расширенные функции.
Заключение
Тупики
(дедлоки) и близкая к ним проблема бесконечного
откладывания — важные факторы, которые должны учитывать
разработчики операционных систем. Один процесс может
оказаться в тупиковой ситуации, если он будет ждать
наступления события, которое никогда не произойдет. Два
или более процессов могут попасть в тупик, при котором
каждый процесс будет удерживать ресурсы, запрашиваемые
другими процессами, в то время как самому ему требуются
ресурсы, удерживаемые другими. Системы со спулингом
оказываются чреваты тупиковыми ситуациями, когда
выделенная область буферной памяти заполняется до того,
как процессы завершат свою работу.
Динамически
перераспределяемые ресурсы у процесса можно отобрать, а
динамически неперераспределяемые — нельзя. Выделенные,
или закрепленные ресурсы в каждый конкретный момент
времени может монопольно использовать только один
процесс. Реентерабельный код в процессе своего
выполнения не изменяется; несколько выполняющихся
процессов могут использовать его коллективно, что
позволяет сэкономить основную память. Код многократного
последовательного использования в период с начала до
конца выполнения может использовать только один процесс;
этот код во время работы может меняться, однако для
каждого нового процесса он сам повторно инициализирует
себя.
Для
возникновения тупиковой ситуации должны существовать
четыре необходимых условия: «взаимоисключение»,
«ожидание дополнительных ресурсов»,
«неперераспределяемость» и «круговое ожидание».
«Взаимоисключение» означает, что процессы заявляют
исключительные права на управление своими ресурсами;
«ожидание дополнительных ресурсов» означает, что
процессы могут удерживать за собой ресурсы, ожидая
выделения им дополнительных запрошенных ресурсов;
«неперераспределяемость» означает, что ресурсы нельзя
принудительно отнимать у процессов; а «круговое
ожидание» означает, что существует цепочка процессов, в
которой каждый процесс удерживает ресурс, запрашиваемый
другим процессом, который в свою очередь удерживает
ресурс, запрашиваемый следующим процессом, и т.
д.
Основные
направления научных исследований в области тупиков — это
предотвращение тупиков (если обеспечить нарушение хотя
бы одного необходимого условия, то в системе полностью
исключается всякая возможность возникновения тупика);
обход тупиков (здесь тупиковая ситуация в принципе
допускается, однако в случае ее приближения принимаются
соответствующие предупредительные меры — предполагается,
что такое принципиальное допущение тупиковой ситуации
позволяет достичь более рационального использования
ресурсов); обнаружение тупиков (здесь возникающие тупики
локализуются, с выдачей соответствующей информации для
привлечения внимания операторов и системы) и
восстановление после тупиков (здесь обеспечивается выход
из тупиковых ситуаций — почти всегда с некоторой потерей
результатов текущей работы).
Предотвращение
тупиков можно обеспечить, если нарушается одно или более
необходимых условий тупиковых ситуаций. Только условие
взаимоисключения нарушать нельзя, поскольку мы должны
предусматривать взаимоисключающее использование многих
видов системных ресурсов. Условие ожидания
дополнительных ресурсов можно нарушить, если
потребовать, чтобы пользователи заблаговременно
запрашивали все необходимые ресурсы; система либо
удовлетворяет такой запрос в целом, либо отвергает его и
заставляет пользователя ждать до тех пор, пока не
освободятся все нужные ему ресурсы. Нарушение условия
неперераспределяемости можно обеспечить, если
потребовать, чтобы пользователь, который удерживает
некоторые ресурсы и не получает удовлетворения своего
запроса на дополнительные ресурсы, вначале освободил все
удерживаемые ресурсы, а затем запросил их все сразу, что
достаточно неприятно. Кругового ожидания можно не
допустить, если потребовать, чтобы пользователи
запрашивали ресурсы в некотором заранее определенном в
системе порядке; легко показать, что таким образом
предотвращается возможность возникновения циклов в графе
распределения ресурсов.
Основу
для реализации механизмов обхода тупиковых ситуаций
составляет алгоритм банкира, который предложил Дейкстра.
Согласно этому алгоритму считается, что состояние
системы надежно, если имеется возможность завершить
выполнение всех пользовательских программ и возвратить
ресурсы системе; говорят, что состояние ненадежно, если
нельзя гарантировать завершение работы всех
пользователей. Ненадежное состояние не обязательно
приводит к тупиковой ситуации; система, находящаяся в
ненадежном состоянии, может успешно выйти из него, если
события сложатся достаточно благоприятно. Алгоритм
банкира содержит несколько серьезных недостатков,
которые не позволяют использовать его в современных
операционных системах, однако он представляет
несомненный теоретический интерес, быть может, как база
для создания более подходящих алгоритмов обхода
тупиковых ситуаций в будущих операционных
системах.
Графы
распределения ресурсов удобны тем, что позволяют видеть
«состояние ресурсов» системы. Метод редукции графов
позволяет обнаруживать тупики.
Восстановление
после обнаружения тупика обычно осуществляется путем
вывода из системы одного или нескольких процессов,
вовлеченных в тупиковую ситуацию; при этом их ресурсы
освобождаются, с тем чтобы их можно было предоставить
другим процессам. Восстановление в современных системах
производится сложно и неэффективно. Усовершенствованные
средства приостановки/возобновления процессов должны
существенно улучшить возможности выхода из тупиковых
ситуаций.
Тупики
в современных системах обычно рассматриваются как
достаточно редкая неприятность. В будущих системах
тупиковые ситуации могут стать гораздо более критическим
фактором, поскольку эти системы будут работать при
гораздо более динамичном распределении ресурсов и
большем количестве одновременно выполняемых
процессов.
Терминология
алгоритм
банкира, который предложил Дейкстра (Dijkstra's Banker's
Algorithm)
бесконечное
откладывание (indefinite
postponement)
восстановление
после тупика (deadlock recovery)
выделенный,
или закрепленный, или монопольно используемый ресурс
(dedicated resource)
граф
распределения ресурсов (resource allocation
graph)
динамическое
распределение ресурсов (dynamic resource
allocation)
контрольная
точка/рестарт (checkpoint/restart)
надежное
состояние (safe state)
ненадежное
состояние (unsafe state)
необходимые
условия для существования тупиков (necessary conditions
for deadlock)
неперераспределяемый
ресурс (nonpreemptible resource)
«нередуцируемый»
процесс (irreducible process)
обнаружение
тупиков (deadlock detection)
обход
тупиков (deadlock avoidance)
перераспределяемый
ресурс (preemptible resource)
предотвращение
тупиков (deadlock prevention)
предсказуемость
платы за ресурсы (predictability of resource
charges)
редукция,
или приведение графа распределения ресурсов (reduction
of a resource allocation graph)
реентерабельная
процедура (reentrant procedure)
«редуцируемый»
процесс (reducible process)
ресурс
последовательного повторного использования (serially
reusable resource)
стандартный
способ распределения Хавендера (Standard Allocation
Pattern of Havender)
старение
процесса (aging)
тупик,
тупиковая ситуация, дедлок
(deadlock)
условие
взаимоисключения (mutual exclusion
condition)
условие
«кругового взаимоожидания» («circular wait»
condition)
условие
«неперераспределяемости» («no-preemption»
condition)
условие
«ожидания дополнительных ресурсов» («wait for»
condition)
Упражнения
6.1Дайте
определение понятия тупика.
6.2Приведите
"пример тупика с участием всего лишь одного
процесса.
6.3Приведите
пример простого тупика с участием трех процессов и трех
ресурсов. Начертите соответствующий граф распределения
ресурсов.
6.4Рассмотрите
предпосылки для создания систем со спулингом. Почему эти
системы зачастую чреваты тупиковыми
ситуациями?
6.5Предположим,
что система со спулингом подвержена тупикам. Как
разработчик операционных систем, какие средства могли бы
вы предусмотреть в данной операционной системе, чтобы
помочь оператору обеспечивать выход из тупиковых
ситуаций без потери работы, проделанной до этого момента
любым из процессов пользователя, вовлеченных в тупиковую
ситуацию?
6.6Современные
системы со спулингом зачастую допускают, чтобы
распечатка данных начиналась еще до того, как процесс
закончит свое выполнение. Предположим, что процесс
сформировал 1000 строк для печати и что эти строки были
приняты механизмами спулинга и помещены на диск
Предположим, что этот процесс будет продолжать
выполняться и со временем сформирует 19 000 оставшихся
строк для печати. После формирования первых 1000 строк
освободился принтер и началась распечатка этой первой
тысячи строк. Что, по вашему мнению, произойдет, когда
завершится распечатка этих строк, в каждом из следующих
случаев:
а)
процесс закончил выдачу оставшихся 19 000 строк на
диск.
б)
процесс еще продолжает
выполняться.
В
своих рассуждениях вы должны учитывать, что отпечатанный
листинг не должен иметь каких-либо пропусков — он должен
выглядеть так, как если бы все 20 000 строк печатались
непрерывно.
6.7Многие
из первых систем со спулингом работали, имея
фиксированный объем
буферной
памяти для спулинга. Современные системы являются более
динамичными в том смысле, что операционная система может
увеличивать объем буферной памяти для спулинга в
процессе работы. Каким образом это помогает уменьшить
вероятность тупиковых ситуаций? Однако подобная система
все же может попасть в тупиковую ситуацию.
Как?
6.8Что
такое «бесконечное откладывание»? Чем оно отличается от
тупика? Что у них общего?
6.9Предположим,
что данная система допускает бесконечное откладывание
для определенных категорий объектов. Каким образом вы
как разработчик систем можете обеспечить предотвращение
бесконечного откладывания?
6.10Обсудите
последствия бесконечного откладывания для каждого из
следующих типов систем:
а)
системы пакетной обработки;
б)
системы разделения времени;
в)
системы реального времени.
6.11Почему
возможность динамического перераспределения ресурсов
является критическим фактором для успешной работы
мультипрограммных вычислительных
систем?
6.12Обсудите
каждый из следующих видов
ресурсов:
а)
перераспределяемый ресурс;
б)
неперераспределяемый ресурс;
в)
разделяемый ресурс (ресурс, коллективного
пользования);
г)
выделенный, или закрепленный
ресурс;
д)
реентерабельный код;
е)
код многократного последовательного
использования.
6.13Сформулируйте
четыре необходимых условия существования тупика.
Приведите краткое интуитивное обоснование причин, по
которым каждое отдельно взятое условие
необходимо.
6.14Рассмотрите
транспортную пробку, показанную на рис. 6.1. Обсудите
каждое из необходимых условий существования тупика
применительно к транспортной
пробке.
6.15Какие
четыре направления научных исследований по проблеме
тупиков упомянуты в тексте? Кратко рассмотрите каждое из
них.
6.16Чтобы
условие «ожидание дополнительных ресурсов» было
нарушено, по методу Хавендера процессы должны сразу
запрашивать все ресурсы, которые им понадобятся, только
после этого система может разрешить их выполнение. То
есть система предоставляет им ресурсы по принципу «все
или ничего». Это один из наиболее широко
распространенных способов предотвращения тупиков.
Обсудите его достоинства и недостатки. ,
;
6.17Предложенное
Хавендером нарушение условия «неперераспределяемости» не
стало популярным для исключения возможности тупиковых
ситуаций. Почему?
6.18Предложенный
Хавендером способ нарушения условия «кругового
ожида-ния» реализован во многих системах. Обсудите его
достоинства и недостатки.
6.19Покажите,
что стандартный способ распределения Хавендера,
нарушающий условие «кругового ожидания», действительно
предотвращает образование циклов в графах распределения
ресурсов,
6.20Объясните,
почему средства обхода тупиков интуитивно кажутся более
привлекательными по сравнению со средствами
предотвращения тупиков.
6.21В
контексте алгоритма банкира определите, является ли
каждое из приведенных ниже состояний надежным или
ненадежным. Если состояние надежно, то покажите, каким
образом могут завершиться все процессы. Если состояние
ненадежно, покажите, каким образом может возникнуть
тупик.
Состояние
А
|
|
Текущее
количество
выделенных устройств |
|
Максимальная
потребность |
|
Пользователь
(1) |
2 |
|
6 |
|
Пользователь
(2) |
4 |
|
7 |
|
Пользователь
(3) |
5 |
|
6 |
|
Пользователь
(4) |
0 |
|
2 |
|
Резерв |
|
1 |
|
Состояние
Б
|
|
Текущее
количество
выделенных устройств |
|
Максимальная
потребность |
|
Пользователь
(1) |
4 |
|
8 |
|
Пользователь
(2) |
3 |
|
9 |
|
Пользователь
(3) |
5 |
|
8 |
|
Пользователь
(4) |
0 |
|
0 |
|
Резерв |
|
2 |
|
6.22Сам
факт, что состояние является ненадежным, не обязательно
говорит о том, что в системе возникнет тупик. Объясните,
почему это так. Приведите пример ненадежного состояния и
покажите, каким образом все процессы могут завершиться
без тупика.
6.23Алгоритм
банкира, который предложил Дейкстра, имеет ряд
недостатков, препятствующих его эффективному применению
в реальных системах. Прокомментируйте, почему каждое из
указанных ниже ограничений может рассматриваться как
недостаток алгоритма банкира.
а)
Количество распределяемых ресурсов считается
постоянным.
б)
Число работающих пользователей считается
постоянным.
в)
Операционная система гарантирует, что запросы на ресурсы
будут удовлетворяться за конечное
время.
г)
Пользователи гарантируют, что они возвратят системе
занимаемые ими ресурсы в течение конечного
времени.
д)
Пользователи должны заранее указывать свои максимальные
потребности в ресурсах.
6.24Если
система не исключает тупиков, то при каких
обстоятельствах будете вы обращаться к алгоритму их
обнаружения?
6.25Для
алгоритма обнаружения тупиков, основанного на редукции
графа, покажите, что порядок редукций не имеет значения,
в любом случае будет достигнут один и тот же конечный
результат.
6.26Почему
восстановление после тупиков является столь трудной
проблемой?
6.27Почему
так сложно выбирать, какие из процессов следует
«выбросить» при восстановлении после
тупика?
6.28В
данной главе мы говорили о том, что эффективные средства
приостановки/ /возобновления процессов играют важную
роль при выходе из тупиковых ситуаций. Проблема
«приостановки/возобновления» представляет большой
интерес для разработчиков операционных систем, причем
пока что она еще не имеет удовлетворительного
решения.
а)
Объясните, почему так важно обеспечивать
приостановку/возобновление
процессов.
б)
Объясните, почему так сложно реализовать эффективный
механизм приостановки/возобновления
процессов.
6.29Почему
проблема тупиков станет, по всей вероятности, более
критическим фактором для будущих операционных
систем?
6.30В
предположении, что первые три необходимых условия
существования тупика выполнены, прокомментируйте
правомерность следующей стратегии: всем процессам
присваиваются уникальные значения приоритетов. Когда
имеется более чем один процесс, ожидающий освобождения
некоторого ресурса, и этот ресурс освобождается, он
выделяется ожидающему процессу с наивысшим
приоритетом.
6.31Предположим,
что все ресурсы идентичны, они могут захватываться и
освобождаться строго по одному в каждый конкретный
момент времени, причем ни одному процессу никогда не
требуется больше ресурсов, чем имеется в системе:
укажите, сможет ли возникнуть тупик в каждой из
следующих систем:
|
|
Число
процессов |
Число
ресурсов |
|
а) |
1 |
1 |
|
б) |
1 |
2 |
|
в) |
2 |
1 |
|
г) |
2 |
2 |
|
д) |
2 |
3 |
Предположим
теперь, что ни одному из процессов никогда не
потребуется более двух ресурсов. Укажите, может ли
возникнуть тупик в каждой из следующих
систем:
|
|
Число
процессов |
Число
ресурсов |
|
е) |
1 |
2 |
|
ж) |
2 |
2 |
|
з) |
2 |
3 |
|
и) |
3 |
3 |
|
к) |
3 |
4 |
6.32Иногда
информации относительно максимальных потребностей
процессов в ресурсах достаточно для того, чтобы
обеспечить обход тупиков без значительных затрат
рабочего времени. Рассмотрим, например, следующую
ситуацию (Холт): набор из т процессов коллективно
использует я идентичных ресурсов. Ресурсы могут
захватываться и освобождаться строго по одному в каждый
момент времени. Ни одному процессу никогда не требуется
более n ресурсов. Сумма максимальных потребностей
для всех процессов строго меньше m+n. Покажите,
что в подобной системе тупики
невозможны.
Литература
|
(Ch80)
|
Chang
Е., "«-Philosophers: An Exercise in Distributed
Control", Сотриter Networks, Vol. 4, April
1980, pp. 71—76. |
|
(Со71)
|
Coffman
E. G., Jr., Elphick M., Shoshani A., "System
Deadlocks" Computing Surveys, Vol. 3, No.
2, June 1971, pp. 67—78.
|
|
(D165)
|
Dijkstra
E. W., Cooperating Sequential Processes,
Technological University, Eindhoven, The
Netherlands, 1965. |
|
(D168)
|
Dijkstra
E. W., "The Structure of the Т. Н. E.
Multiprogramming System", С ACM, Vol. 11,
No. 5, May 1968, pp. 341—346.
|
|
(Fo71)
|
Fontao
R. O., "A Concurrent Algorithm for Avoiding
Deadlocks", Proc. Third ACM Symposium on
Operating Systems Principles, October 1971.
pp. 72-79. |
|
(Fr73)
|
Frailey
D. J., "A Practical Approach to Managing Resources
and Avoiding Deadlock" CACM, Vol. 16, No. 5, May
1973, pp. 323—329. |
|
(Ge81)
|
Gelernter
D., "A DAG Based Algorithm for Prevention of
Store-and-Forward Deadlock in Packet Networks",
IEEE Trans, on Computers Vol 30, October
1981, pp. 709—715. |
|
(На69)
|
Habermann
A. N., "Prevention of System Deadlocks", CACM,
Vol 12 No. 7, July 1969, pp. 373—377, 385.
|
|
(На78)
|
Habermann
A. N., "System Deadlocks", Current Trends in
Programming Methodology, Vol. Ill, Englewood
Cliffs, N. J.: Prentice-Hall, 1978 pp. 256—297.
|
|
(Hv68)
|
Ha
vender J. W., "Avoiding Deadlock in Multitasking
Systems", IBM Systems Journal, Vol. 7, No.
2, 1968, pp. 74—84. |
|
(Не70)
|
Hebalkar
P. G., "Deadlock-Free Sharing of Resources in
Asynchronous Systems", M. I. T. Project MAC
TR-75, September 1970.
|
|
(Но71)
|
Holt
R. C, "Comments on the Prevention of System
Deadlocks", CACM, Vol. 14, No. 1, January
1971, pp. 36—38. |
|
(Но71а)
|
Holt
R.C.,On Deadlock Prevention in Computer
Systems, Ph. D. Thesis, Ithaca, N. Y.: Cornell
University, 1971. |
|
(Но71Ь)
|
Holt
R. C., "Some Deadlock Properties of Computer",
Proc. Third ACM Symposium on Operating Systems
Principles, October 1971, pp. 64 — 71.
|
|
(Но72)
|
Holt
R. C., "Some Deadlock Properties of Computer
Systems", ACM Computing Surveys, September
1972, pp. 179—196. |
|
(Hw73)
|
Howard
J. H., "Mixed Solutions for the Deadlock Problem",
CACM, Vol. 16 No. 7, July 1973,
427—430. |
|
(Ka80)
|
Kameda
T, "Testing Deadlock-Freedom of Computer
Systems”, JACM, Vol. 27, April 1980, pp.
280 — 290. |
|
(Lo80)
|
Lomet
D., "Subsystems of Processes with Deadlock
Avoidance”, IEEE Trans on Soft. Eng., Vol.
6, May 1980, pp. 297-303.
|
|
(Ne80)
|
Nezu
K., “System Deadlocks Resolution”, AFIPS Conf.
Proc., Vol. 49, 1980, pp.
257-260. |
|
(Se75)
|
Sekino
L. C., “Multiple Concurrent Updates”, In D. Kerr
(ed.), Proc. Intl. Conf. On Very Large Data
Bases, September 1975, pp.
505-507. |
|
(Sh69)
|
Shoshani
A., Bernstein A. J., “Synchronization in a
Parallel-Accessed Data Bases”, CACM, Vol. 12, No.
11, 1969, pp.
604-607. |
1)
В оригинале такой тип ресурсов называют
preemtible. Соответствующего установившегося
русского термина пока нет. Поэтому мы будем употреблять
практически как эквивалентные такие термины, как
переключаемый, переходящий, динамичный, оперативно
перераспределяемый. Прим.
ред. |