    
|
    
|
 |
 |
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Навигация » Главная » Биография » Диссертация » Библиотека » Ссылки » Результаты поиска » Индивидуальное задание Оглавление
Введение
|
Исследование алгоритмов сжатия информации в среде системы автоматизации раскроем проката на НЗС
Руководитель: доцент кафедры ЭВМ Теплинский С.В.
 1. Методы сжатия информации Все известные алгоритмы сжатия сводятся к шифрованию входной информации, а принимающая сторона выполняет дешифровку принятых данных. Существуют методы, которые предполагают некоторые потери исходных данных, другие алгоритмы позволяют преобразовать информацию без потерь. Сжатие с потерями используется при передаче звуковой или графической информации, при этом учитывается несовершенство органов слуха и зрения, которые не замечают некоторого ухудшения качества, связанного с этими потерями. Все известные алгоритмы сжатия сводятся к шифрованию входной информации, а принимающая сторона выполняет дешифровку принятых данных. Существуют методы, которые предполагают некоторые потери исходных данных, другие алгоритмы позволяют преобразовать информацию без потерь. Сжатие с потерями используется при передаче звуковой или графической информации, при этом учитывается несовершенство органов слуха и зрения, которые не замечают некоторого ухудшения качества, связанного с этими потерями. Сжатие информации без потерь осуществляется статистическим кодированием или на основе предварительно созданного словаря. Статистические алгоритмы (напр., схема кодирования Хафмана) присваивают каждому входному символу определенный код. При этом, наиболее часто используемому символу присваивается наиболее короткий код, а наиболее редкому - более длинный. Таблицы кодирования создаются заранее и имеют ограниченный размер. Этот алгоритм обеспечивает наибольшее быстродействие и наименьшие задержки. Для получения высоких коэффициентов сжатия статистический метод требует больших объемов памяти. Альтернативой статистическому алгоритму является схема сжатия, основанная на динамически изменяемом словаре (напр., алгоритмы Лемпеля-Зива). Данный метод предполагает замену потока символов кодами, записанными в памяти в виде словаря (таблица перекодировки). Соотношение между символами и кодами меняется вместе с изменением данных. Таблицы кодирования периодически меняются, что делает метод более гибким. Размер небольших словарей лежит в пределах 2-32 килобайт, но более высоких коэффициентов сжатия можно достичь при заметно больших словарях до 400 килобайт. 2. Статический алгоритм Хаффмана Один из первых алгоритмов эффективного кодирования информации был предложен Хаффманом в 1952 году. Идея алгоритма состоит в следующем: зная вероятности вхождения символов в сообщение, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Коды Хаффмена имеют уникальный префикс, что и позволяет однозначно их декодировать, несмотря на их переменную длину. Классический алгоритм Хаффмена на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмена (Н-дерево). Алгоритм построения Н-дерева прост. • Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение. • Выбираются два свободных узла дерева с наименьшими весами. • Создается их родитель с весом, равным их суммарному весу. • Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка. • Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой - бит 0. • Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева. Допустим, у нас есть следующая таблица частот:
На первом шаге из листьев дерева выбираются два с наименьшими весами - Г и Д. Они присоединяются к новому узлу-родителю, вес которого устанавливается в 5+6 = 11. Затем узлы Г и Д удаляются из списка свободных. Узел Г соответствует ветви 0 родителя, узел Д - ветви 1. На следующем шаге то же происходит с узлами Б и В, так как теперь эта пара имеет самый меньший вес в дереве. Создается новый узел с весом 13, а узлы Б и В удаляются из списка свободных. На следующем шаге "наилегчайшей" парой оказываются узлы Б/В и Г/Д. Для них еще раз создается родитель, теперь уже с весом 24. Узел Б/В соответствует ветви 0 родителя, Г/Д - ветви 1. На последнем шаге в списке свободных осталось только два узла - это А и узел (Б/В)/(Г/Д). В очередной раз создается родитель с весом 39 и бывшие свободными узлы присоединяются к разным его ветвям. Поскольку свободным остался только один узел, то алгоритм построения дерева кодирования Хаффмана завершается. Н-дерево представлено на рисунке. 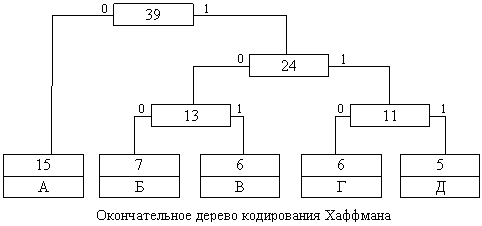 Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от листа дерева, соответствующего этому символу, до корня дерева, накапливая биты при перемещении по ветвям дерева. Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке. Классический алгоритм Хаффмана имеет один существенный недостаток. Для восстановления содержимого сжатого сообщения декодер должен знать таблицу частот, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и Н-дерева), другого для собственно кодирования. 3. Арифметическое кодирование Пpи аpифметическом кодиpовании текст пpедставляется вещественными числами в интеpвале от 0 до 1. По меpе кодиpования текста, отобpажающий его интеpвал уменьшается, а количество битов для его пpедставления возpастает. Очеpедные символы текста сокpащают величину интеpвала исходя из значений их веpоятностей, опpеделяемых моделью. Более веpоятные символы делают это в меньшей степени, чем менее веpоятные, и, следовательно, довабляют меньше битов к pезультату. Пеpед началом pаботы соответствующий тексту интеpвал есть [0; 1). Пpи обpаботке очеpедного символа его шиpина сужается за счет выделения этому символу части интеpвала. Длина интервала для символа равна вероятности его появления в сообщении. Положение интервала вероятности каждого символа не имеет значения. Важно только то, чтобы и кодер, и декодер располагали символы по одинаковым правилам. Hапpимеp, пpименим к тексту "eaii!" алфавита {a,e,i,o,u,!} модель с постоянными веpоятностями, заданными в следующей таблице:
И кодиpовщику, и декодиpовщику известно, что в самом начале интеpвал есть [0; 1). После пpосмотpа пеpвого символа "e", кодиpовщик сужает интеpвал до [0.2; 0.5), котоpый модель выделяет этому символу. Втоpой символ "a" сузит этот новый интеpвал до одной пятой части, поскольку для "a" выделен фиксиpованный интеpвал [0.0; 0.2). В pезультате получим pабочий интеpвал [0.2; 0.26), т.к. пpедыдущий интеpвал имел шиpину в 0.3 единицы и одна пятая от него есть 0.06. Следующему символу "i" соответствует фиксиpованный интеpвал [0.5; 0.6), что пpименительно к pабочему интеpвалу [0.2; 0.26) суживает его до интеpвала [0.23, 0.236). Пpодолжая в том же духе, имеем:
Пpедположим, что все что декодиpовщик знает о тексте, это конечный интеpвал [0.23354; 0.2336). Он сpазу же понимает, что пеpвый закодиpованный символ есть "e", т.к. итоговый интеpвал целиком лежит в интеpвале, выделенном моделью этому символу. Тепеpь повтоpим действия кодиpовщика:
Отсюда ясно, что втоpой символ - это "a", поскольку это пpиведет к интеpвалу [0.2; 0.26), котоpый полностью вмещает итоговый интеpвал [0.23354; 0.2336). Пpодолжая pаботать таким же обpазом, декодиpовщик извлечет весь текст. Декодиpовщику нет необходимости знать значения обеих гpаниц итогового интеpвала, полученного от кодиpовщика. Даже единственного значения, лежащего внутpи него, напpимеp 0.23355, уже достаточно. Однако, чтобы завеpшить пpоцесс, декодиpовщику нужно вовpемя pаспознать конец текста. Кpоме того, одно и то же число 0.0 можно пpедставить и как "a", и как "aa", "aaa" и т.д. Для устpанения неясности необходимо обозначить завеpшение каждого текста специальным символом EOF, известным и кодиpовщику, и декодиpовщику. Результаты сжатия, достигнутые данным алгоритмом ваpьиpуются от 4.8-5.3 битов/символ для коpотких текстов до 4.5-4.7 битов/символ для длинных. Хотя существуют и адаптивные техники Хаффмана, они все же испытывают недостаток концептуальной пpостоты, свойственной аpифметическому кодиpованию. Пpи сpавнении они оказываются более медленными. 4. Алгоритм Зива-Лемпеля В 1977 году Абрахам Лемпель и Якоб Зив предложили алгоритм сжатия данных, названный позднее LZ77. Этот алгоритм используется в программах архивирования текстов compress, lha, pkzip и arj. Модификация алгоритма LZ78 применяется для сжатия двоичных данных. Эти модификации алгоритма защищены патентами США. Алгоритм предполагает кодирование последовательности бит путем разбивки ее на фразы с последующим кодированием этих фраз. Суть алгоритма заключается в следующем. Если в тексте встретится повторение строк символов, то повторные строки заменяются ссылками (указателями) на исходную строку. Ссылка имеет формат <префикс, расстояние, длина>. Префикс в этом случае равен 1. Поле расстояние идентифицирует слово в словаре строк. Если строки в словаре нет, генерируется код символ вида <префикс, символ>, где поле префикс =0, а поле символ соответствует текущему символу исходного текста. Отсюда видно, что префикс служит для разделения кодов указателя от кодов символ. Введение кодов символ, позволяет оптимизировать словарь и поднять эффективность сжатия. Главная алгоритмическая проблема здесь заключатся в оптимальном выборе строк, так как это предполагает значительный объем переборов. Рассмотрим пример с исходной последовательностью U =0010001101 (без надежды получить реальное сжатие для столь ограниченного объема исходного материала). Введем обозначения: P[n] - фраза с номером n. C - результат сжатия. Разложение исходной последовательности бит на фразы представлено в таблице ниже.
P[0] - пустая строка. Символом точка обозначается операция объединения (конкатенации). Формируем пары строк, каждая из которых имеет вид (A.B). Каждая пара образует новую фразу и содержит идентификатор предыдущей фразы и бит, присоединяемый к этой фразе. Объединение всех этих пар представляет окончательный результат сжатия С. P[1]=P[0].0 дает (00.0), P[2]=P[1].0 дает (01.0) и т.д. Схема преобразования отражена в таблице ниже.
Все формулы, содержащие P[0] вовсе не дают сжатия. Очевидно, что С длиннее U, но это получается для короткой исходной последовательности. В случае материала большего объема будет получено реальное сжатие исходной последовательности. 5. Преобразование Барроуза-Уилера Алгоритм сжатия данных на основе преобразования Барроуза-Уилера (BWT) - это обратимый алгоритм перестановки символов во входном потоке, позволяющий эффективно сжать полученный в результате преобразования блок данных. Вкратце, процедура преобразования происходит так: • Выделяется блок из входного потока. • Формируется матрица всех перестановок, полученных в результате циклического сдвига блока. • Все перестановки сортируются в соответствии с лексикографическим порядком символов каждой перестановки. • На выход подается последний столбец матрицы и номер строки, соответствующей оригинальному блоку. Хорошее сжатие происходит за счет того, что буквы, связанные с похожими контекстами, группируются во входном потоке вместе. Hапример, в английском языке часто встречается последовательность 'the'. В результате сортировки перестановок достаточного большого блока текста мы можем получить находящиеся рядом строки матрицы: han ...t he ....t he ....t hen ...t hen ...w here...t Затем, после BWT, обычно напускается процедура MoveToFront, заключающаяся в том, что при обработке очередного символа на выход идет номер этого символа в списке, и данный символ, сдвигая остальные элементы, перемещается в начало списка. Таким образом, мы получаем поток, преимущественно состоящий из нулей, который легко дожимается при помощи арифметического кодирования или методом Хаффмана. 6. Сравнение существующих алгоритмов Ниже приведены результаты тестирования известных программных средств сжатия данных при различных типах входных файлов. Текстовый файл на русском языке (1,639,139 байт)
Текстовый файл на английском языке (2,042,760 байт)
EXE-файл (536,624 байт)
Из результатов тестов видно, что наиболее лучший коэффициент сжатия для текстовых файлов дает сочетание алгоритмов Барроуза-Уилера и Хаффмана, для исполнимых файлов наилучшим выбором будет сочетание алгоритма Зива-Лемпеля и арифметического сжатия. Заключение После выполнения данной работы были получены следующие результаты: • Дано обоснование актуальности и необходимости использования сжатия данных в среде системы автоматизации раскроем проката на НЗС. • Рассмотрены и проанализированы основные алгоритмы сжатия информации. • Рассмотрены и проанализированы программы сжатия информации, использующие рассмотренные алгоритмы. • Определены дальнейшие направления поиска. • Отражена специфика данной задачи. В целом выполнение проекта заложило фундамент для дальнейшего продолжения исследования и поиска, определило основные приоритеты и задачи будущей разработки. Литература 1. Ватолин Д., Ратушняк А., Смирнов М., Юкин В. "Методы сжатия данных" - 2003г. 2. Балашов К.Ю. "Сжатие информации: анализ методов и подходов" - Минск, 2000г. 3. Мастрюков Д. "Алгоритмы сжатия информации" 4. Потапов В.Н. "Арифметическое кодирование вероятностных источников" 5. Потапов В.Н "Обзор методов неискажающего кодирования дискретных источников" 6. Семенова Ю.А. "Телекоммуникационные технологии" 7. Шелвин Е. "Алгоритм арифметического кодирования" 8. Фомин А.А. "Основы сжатия информации" - Санкт-Петербург, 1998г. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
 |
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||