Солдатова Виктория Александровна
Специальность:
| |
|
Солдатова Виктория Александровна |
|
Специальность: |
"Программное обеcпечение автоматизированных систем" |
| Тема магистерской работы: | "Исследование адаптивных алгоритмов маршрутизации в компьютерных сетях" |
| Научный руководитель: | доц., канд. техн. наук Ладыженский Юрий Валентинович |
| E-mail: | _sunshine@mail.ru |
СОДЕРЖАНИЕ
1. Актуальность темы
2. Обзор имеющихся исследований и разработок
3. Определение и характеристики маршрутизации
3.1 Общая постановка задачи маршрутизации
3.2 Классификация алгоритмов маршрутизации
3.3 Основные характеристики задачи маршрутизации
4. Алгоритмы маршрутизации
4.1 Алгоритмы проверки состояния линии связи
4.2 Дистанционно-векторные алгоритмы
4.3 Адаптивный, оптимальный алгоритм маршрутизации Daemon
5. AntNet – адаптивный, базирующийся на агентах алгоритм маршрутизации
5.1 Принципы поведения муравьев
5.2 Применение роевого интеллекта к задаче маршрутизации
5.3 Описание алгоритма AntNet и его характеристик
5.4 Расчет укрепляющего коэффициента
6. Результаты исследования поведения алгоритмов маршрутизации
Заключение
Литература
С каждым годом количество пользователей компьютерных сетей растет. Это, в свою очередь, обуславливает рост сложности структур сетей и взаимодействия между ними. Соответственно усложняется и поиск оптимальных путей в сети для быстрой доставки запросов пользователей сети, т.е. усложняется задача маршрутизации.
Маршрутизация пакетов в сети занимает одно из важных мест в управлении сетью. Под маршрутизацией обычно понимают доставку пакетов из одного узла сети в другой, максимизируя при этом производительность сети. Задачу маршрутизации в сети решают специальные устройства - маршрутизаторы. Алгоритм маршрутизации - это часть программного обеспечения маршрутизатора, отвечающая за выбор выходной линии, на которую поступивший пакет должен быть передан. Выбор одного из возможных в маршрутизаторе направлений зависит от текущей топологии сети, длин очередей в узлах коммутации и т.п.
В виду сложности структур современных компьютерных сетей, задача маршрутизации не решается в полной мере. В большинстве случаев это связано с маршрутизаторами [1], не справляющимися с поддержанием таблиц маршрутизации и выбором оптимальных маршрутов для данного класса трафика. Поэтому возникает задача исследования существующих алгоритмов маршрутизации с целью улучшения их характеристик, или создания новых алгоритмов маршрутизации.
В данной работе описаны различные виды алгоритмов маршрутизации. Большинство алгоритмов уже используются для решения задачи маршрутизации в сетях. Однако эти алгоритмы не всегда соответствуют выдвигающимся к ним требованиям. Поэтому в работе [2] был предложен новый подход к задаче маршрутизации - алгоритм AntNet. Это адаптивный, базирующийся на агентах алгоритм маршрутизации, который демонстрирует лучшие результаты производительности, среди всех рассмотренных алгоритмов [2]. Алгоритм AntNet использует для маршрутизации данных по сети роевых интеллект. Такой интеллект присущ некоторым видам социальных насекомых (муравьи, осы, пчелы, термиты).
Целью магистерской работы является реализация алгоритма Antnet и сравнение его с другими алгоритмами маршрутизации.
Впервые алгоритм AntNet был описан Джанни Ди Каро (Gianni Di Caro) и Марко Дориго (Marco Dorigo) в 1998 году в работе [2]. Дориго и Ди Каро протестировали этот алгоритм, используя, построенную ими, дискретно-событийную модель.
Шондерверд (Schoonderwoerd) и другие в 1996-1997 гг. [3,4] рассмотрели маршрутизацию как возможную область применения роевого интеллекта. Их подход к управлению сетью с помощью муравьев (ABC - ant-based control) используется при маршрутизации данных в телефонных сетях и во многом отличается от алгоритма AntNet. Кроме того, в 1997 году Субраманиан (Subramanian), Друшель (Druschel) и Чен (Chen) предложили свой алгоритм [5], базирующий на поведении колонии муравьев в природе. Данный алгоритм был применен к сетям с коммутацией пакетов и являлся расширением ABC-алгоритма, предложенного Шондервердом.
Маршрутизация может быть представлена в следующем виде. Пусть дан направленный взвешенный граф G=(V,E), в котором каждый узел из множества V представляет собой устройство, обрабатывающее и передающее данные, а каждое ребро из множества E является линией связи. Основной задачей алгоритмов маршрутизации является передача данных из узла источника в узел приемник, максимизируя при этом производительность сети. При моделировании алгоритмов маршрутизации возникают две проблемы, затрудняющие процесс создания системы. Во-первых, поток данных не является статическим, во-вторых, он имеет стохастический характер.
Способ реализации описанных трех функции сильно зависит от технологии передачи и коммутации пакетов, положенной в основу сети, и от особенностей других взаимодействующих уровней приложений. Отправка трафика пользователя может происходить с использованием двух базовых операций сети: коммутация каналов и коммутация пакетов (которые также связанные с понятиями ориентированный и неориентированный на соединение.) При коммутации каналов на стадии установки соединения ищутся и резервируются ресурсы сети, которые впоследствии будут предоставлены каждой новой сессии. В этом случае все пакеты данных, принадлежащие одной и той же сессии, будут направлены по одному и тому же пути. От маршрутизаторов требуется хранение информации об активной сессии. При коммутации пакетов нет стадии резервирования, информация о состоянии не хранится на маршрутизаторах, и пакеты данных могут отправляться по разным путям. В каждом промежуточном узле принимается самостоятельное решение о выборе выходной линии, по которой будет отправлен пакет данных в узел приемник.
В данной работе используются сети с коммутацией пакетов.
Общим параметром для всех видов алгоритмов маршрутизации является таблица маршрутизации. Таблица маршрутизации располагается в каждом узле сети, и содержит всю информацию о ней. Эта информация, в свою очередь используется маршрутизаторами для создания маршрутов отправки пакетов данных. Тип информации, содержащейся в маршрутных таблицах, зависит исключительно от алгоритма маршрутизации.
В централизованных алгоритмах главное управляющее устройство отвечает за обновление таблиц маршрутизации всех узлов и/или принимает каждое решение о маршрутизации. Централизованные алгоритмы могут быть использованы только в частных случая и для малых сетей. В общем, задержки необходимые для сбора информации о состоянии сети и для трансляции запроса на обновление данных делает такие алгоритмы неприменимыми на практике. Более того, централизованные системы не являются отказоустойчивыми. В данной работе рассматривается только распределенная маршрутизация, разделяющая вычисление маршрутов между узлами сети, которые обмениваются необходимой информацией.
В статических системах маршрутизации путь, который проходит пакет, определяется только на основе его источника и приемника, без рассмотрения текущего состояния сети. Этот путь обычно выбирается как кратчайший относительно выбранного стоимостного критерия, и может быть изменен только за счет поврежденных линий связи или узлов.
Адаптивные маршруты, в принципе, более привлекательны, так как они могут адаптировать способ маршрутизации к временным и к пространственным изменениям трафика. Как недостаток такого подхода выделяют то, что слишком частые изменения в сети могут стать причиной колебаний в выбранных путях. Это обстоятельство, в свою очередь, может привести к созданию циклических путей, а также к большим отклонениям в выполнении алгоритма. К тому же адаптивная маршрутизация может привести к противоречивым ситуациям, которые могут возникнуть при выходе из строя узлов, линий связи или при изменении локальной топологии. Однако, все эти проблемы устойчивости более характерны для сетей неориентированных на соединение.
Минимальные маршруты позволяют пакетам выбирать только пути с минимальной стоимостью, в то время как неминимальные алгоритмы позволяют делать выбор между всеми доступными путями, используя при этом некоторые эвристические стратегии.
Оптимальная маршрутизация имеет доступ ко всей сети и ко всем ее объектам для оптимизации функции всех отдельных потоков линий связи (обычно эта функция является суммой стоимостей путей назначенных в соответствии со средними задержками пакетов) [6].
Маршрутизация, определяющая кратчайшие пути, объективно определяет кратчайший путь (минимальную стоимость) между двумя узлами. Учитывая содержание в таблицах маршрутизации различной информации, алгоритмы нахождения кратчайших путей могут быть поделены на два класса: дистанционно-векторные и алгоритмы состояния связи.
Оптимальная маршрутизация является статической и требует знания всех характеристик трафика. Алгоритмы нахождения кратчайших путей более гибкие, они не требуют априорных знаний о моделях трафика, и, на данный момент, наиболее распространены среди алгоритмов маршрутизации.
Существуют две основные характеристики, на которые существенное влияние оказывает алгоритм маршрутизации - пропускная способность (количество обслуживания) и средняя задержка пакета (качество обслуживания) [6]. Маршрутизация считается хорошей, если ей удается увеличить пропускную способность и уменьшить среднюю задержку пакета.
Маршрутизация взаимодействует с управлением потоками в определении характеристик посредством механизма обратной связи, представленном на рисунке 3.1.
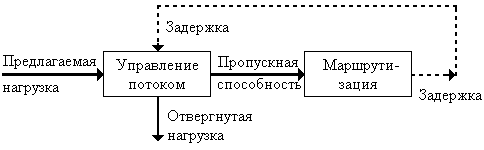
Рисунок 3.1 - Взаимодействие между маршрутизацией и управлением потока с помощью механизма обратной связи
Величины задержки пакетов и пропускной способности зависят от решений, принятых алгоритмом маршрутизации. Однако на пропускную способность в большей степени влияет алгоритм управления потоками. Такие алгоритмы обычно действуют на основе поддержания баланса между пропускной способностью и средней задержкой [6]. Поэтому если алгоритму маршрутизации удается более успешно поддерживать малую задержку, то алгоритм управления потоками разрешает принимать сеть больше трафика. Хотя точный баланс между задержкой и пропускной способностью устанавливается алгоритмом управления потоками, хорошая маршрутизация в условиях большого предлагаемого трафика дает предпочтительную кривую задержка - пропускная способность, по которой действует алгоритм управления потоками (см. рис. 3.2).
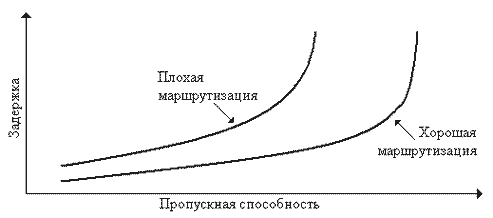
Рисунок 3.2 - Кривые зависимости задержки от пропускной способности для хорошей и плохой маршрутизации
Маршрутизация с проверкой состояния линий связи, в общем, имеет следующий вид.
Во время инициализации маршрутизатор определяет стоимость линии для каждого из своих сетевых интерфейсов. Затем маршрутизатор передает эту информацию всем остальным маршрутизаторам в сети, а не только соседним. Далее маршрутизатор следит за состоянием своих линий связи. При значительном изменении (радикально меняется стоимость линии, создается новая линия, становится недоступной существующая линия), маршрутизатор снова объявляет о стоимости своих линий всем маршрутизаторам конфигурации.
Поскольку каждый маршрутизатор получает информацию о стоимости линий от всех маршрутизаторов, каждый маршрутизатор должен рассчитать топологию всей конфигурации, а затем вычислить кратчайший путь к каждой сети. Выполнив расчет, маршрутизатор может сформировать маршрутную таблицу с данными о первом ретрансляционном участке в направлении каждого потенциального получателя. Поскольку при таком подходе к маршрутизации, маршрутизатор имеет данные обо всей сети, то нет необходимости использовать распределенную версию алгоритма маршрутизации, применяемой, например, в дистанционно-векторных алгоритмах. Вместо этого маршрутизатор может воспользоваться любым алгоритмом определения кратчайшего пути. На практике используют алгоритм Дейкстры [1].
В программе ROUTING_SIMULATOR планируется реализовать такие алгоритмы маршрутизации как OSPF [1,2,7] и SPF [2].
Для дистанционно-векторной маршрутизации требуется, чтобы каждый узел (маршрутизатор или хост, на котором реализован протокол RIP [8] (Routing Information Protocol - протокол маршрутной информации)) обменивался информацией с соседними узлами. Для работы алгоритма каждый узел хранит три вектора [1]:
| -Wx = [ w(x,1), . . . , w(x,M) ] | - вектор стоимости линий, где |
| M – количество сетей, с которыми напрямую соединен
узел x; w(x,i) - стоимость линии, которая ассоциируется с выходом каждого узла для каждой присоединенной сети i. |
|
| - Lx = [ L(x,1), . . . , L(x,N) ] | - вектор расстояния для узла x, где |
| L(x,j) - текущая оценка минимальной задержки от узла
x до сети j; N - количество сетей в конфигурации. |
|
| - Rx = [ R(x,1), . . . , R(x,N) ] | - вектор следующего ретрансляционного участка узла x, где |
| R(x,j) - следующий маршрутизатор на текущем маршруте от узла x до сети j. | |
Периодически (каждые 30 секунд) каждый узел обменивается своим вектором расстояний с соседями. На основе всех входящих векторов расстояний узел x обновляет оба своих вектора следующим образом:
 |
, где |
В программе ROUTING_SIMULATOR планируется реализовать дистанционно-векторный алгоритм маршрутизации BF (Bellman-Ford - распределенный алгоритм Беллмана-Форда) [1,2]. Также к классу дистанционно-векторынх алгоритмов относят алгоритмы Q-R (Q-Routing) [2,9] и PQ-R (Predictive Q-Routing) [2]. Оба эти алгоритма основываются на известном направлении Reinforcement Learning [9] (обучение подкреплением).
Целью оптимальной маршрутизации является оптимизация (минимизация) функции всех потоков линии связи [2]. Оптимальные модели маршрутизации также называют потоковыми моделями, потому что они пытаются оптимизировать весь средний поток, присутствующий в сети.
Алгоритм Daemon является приближением к идеальному алгоритму маршрутизации. Использование Daemon при исследовании поведения различных алгоритмов маршрутизации позволяет определить эмпирическую границу производительности, которая вообще может быть достигнута. С помощью этой эмпирической границы возможно получение некоторой информации, о том, какие еще улучшения могут быть сделаны. При отсутствии каких-либо априорных предположений о статистике трафика, эмпирическая граница может быть определена алгоритмом "демоном", способным к чтению любого состояния очередей и любого элемента сети, и способного рассчитывать мгновенные "реальные" стоимости для всех линий связи и путей назначения на основании пересчета кратчайших путей для каждого хопа пакета во всей сети. Очевидно, что реализация такого "идеального" алгоритма в реальных сетях невозможна.
В работе [2] стоимости линий связи, используемые для расчета кратчайших путей, определяются следующей формулой:
 |
, где |
Коррекция определяется весовым коэффициентом ![]() равным 0.4 [2]. Следует отметить, что способ вычисления Cl
может быть произвольным.
равным 0.4 [2]. Следует отметить, что способ вычисления Cl
может быть произвольным.
В последние два десятилетия при оптимизации сложных систем исследователи все чаще применяю природные механизмы поиска наилучших решений. В частности для решения оптимизационных задач используют так называемый роевый интеллект (Swarm Intelligence), основанный на поведение социальных насекомых. На Земле около двух процентов насекомых являются социальными, половину из них составляют муравьи, поэтому наибольшее распространение получили алгоритмы, использующие поведение муравьев в природе. Также к социальным насекомым относят термитов, некоторый вид пчел и ос.
Муравьи относятся к социальным насекомым, живущим внутри некоторого коллектива - колонии. Поведение муравьев при транспортировании пищи, преодолении препятствий, строительстве муравейника и других действиях зачастую приближается к теоретически оптимальному.
Основу социального поведения "муравьев" составляет самоорганизация. Под самоорганизацией понимают множество динамических механизмов, обеспечивающих достижение системой глобальной цели в результате низкоуровневого взаимодействия ее элементов. Принципиальной особенностью такого взаимодействия является использование элементами системы только локальной информации. При этом исключается любое централизованное управление и обращение к глобальному образу, представляющему систему во внешнем мире. Самоорганизация является результатом взаимодействия следующих четырех компонентов [10]:
Муравьи используют два способа передачи информации: прямой (например, обмен пищей) и непрямой - стигмержи (stigmergy) [2]. Стигмержи - это распределенный во времени тип взаимодействия, когда один субъект взаимодействия изменяет некоторую часть окружающей среды, а остальные используют информацию об ее состоянии позже, когда находятся в ее окрестности. В природе стигмержи осуществляется через феромон (pheromone) - специальный секрет, оставляемый как след при перемещении муравья. Чем больше концентрация феромона на пути, тем больше муравьев будет по нему двигаться. Со временем феромон испаряется, что позволяет муравьям адаптировать свое поведение под изменения внешней среды. Распределение феромона по пространству передвижения муравьев является своего рода динамически изменяемой глобальной памятью муравейника. Любой муравей в фиксированный момент времени может воспринимать и изменять лишь одну локальную ячейку этой памяти [10].
Поведение муравьев в природе можно использовать для решения задачи маршрутизации.
Представим компьютерную сеть как окрестность, в которой взаимодействуют муравьи, при этом узлы этой сети будут являться источниками пищи для муравьев. Узлы соединены линиями связи, на которых муравьи могут отставлять след феромона. Каждый узел в сети характеризуется двумя структурами данных: локальной моделью трафика и вероятностной таблицей маршрутизации. Муравьев в такой сети будем называть мобильными агентами. Каждый мобильный агент движется от одного узла сети к другому (от муравейника к источнику пищи), при этом собирая информацию о линиях связи, соединяющих эти узлы. Чтобы распространить собранную информацию по сети, агент должен вернуться в узел, отправивший его. Для этого у каждого агента существует память, организованная в виде стека, в которую записан весь маршрут движения агента от узла-источника в узел-приемник. При выборе пути движения от узла-источника в узел-приемник через промежуточные узлы агенты используют вероятностное правило выбора пути. Вероятность выбора пути прямо пропорциональна количеству феромонов на этом пути. То есть, линии связи, содержащие большее количество феромонов, являются наиболее удобными маршрутами для пересылки пакетов в сети. В результате своего движения агенты должны собрать информацию о состоянии трафика и обновить главные структуры данных узла.
Проиллюстрировать такой подход можно рисунком 5.1.
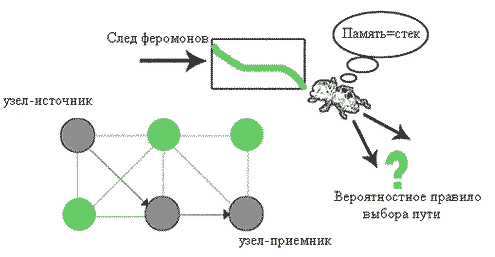
Рисунок 5.1 - Применение поведения муравьев к задаче маршрутизации
Аналогию с колонией муравьев в [2] использовали М. Дориго (Marco Dorigo) и Д. Ди Каро (Gianni Di Caro) для создания распределенного, адаптивного алгоритма маршрутизации AntNet.
В этом алгоритме моделирование искусственной колонии муравьев протекает в итерационном процессе. Здесь каждый муравей строит решение, используя два типа локально достижимой информации: информация специфичная для задачи (например, время достижения узла сети), и информация, добавленная муравьем во время предыдущей итерации алгоритма. Фактически, во время построения решения, каждый муравей собирает информацию, содержащую характеристики задачи и собственную производительность, и, далее, использует эту информацию для модификации представления задачи, с локальной точки зрения других муравьев. Представление о задачи модифицируется таким образом, что информация, содержащейся в предыдущем хорошем решении может быть использована для построения новых лучших решений.
Перед тем, как описать основные шаги алгоритма, следует определить структуры данных и характеристики, с которыми будет оперировать алгоритм.
AntNet легко описывается в терминах двух множеств однородных мобильных агентов, называемых соответственно вперед идущие (Forward ants, В-муравьи) и назад идущие муравьи (Backward ants, Н-муравьи). Агенты каждого множества имеют одинаковую структуру, но по-разному ведут себя в окружающей среде; то есть, у них могут быть разные входы и разные, независимые выходы. Агенты общаются косвенным путем, обмениваясь информацией, которую они совместно читают или записывают в две структуры данных, хранящихся в узле сети k (см. рис 5.2) [2].
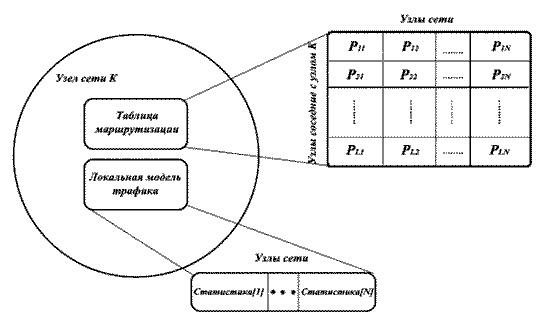
Рисунок 5.2 - Структура узла сети, использующей алгоритм маршрутизации AntNet
Из рисунка 5.2 видно, что узел сети содержит две структуры данных:
Для каждого узла-приемника d в сети, вычисленные
значения математического ожидания и дисперсии, ![]() и
и ![]() , представляют собой ожидаемое
значение времени достижения этого узла и, соответственно, стабильность этого
ожидаемого времени. Опыты показали [2], что для расчета статистики лучше использовать
экспоненциальную модель:
, представляют собой ожидаемое
значение времени достижения этого узла и, соответственно, стабильность этого
ожидаемого времени. Опыты показали [2], что для расчета статистики лучше использовать
экспоненциальную модель:
где ok->d - новое исследуемое время движения агента из узла k в узел d.
Движущееся окно наблюдений Wd используется для расчета значения Wbestd лучшего времени движения агентов по направлению к узлу d, наблюдаемого в последних w опытах. После каждого нового опыта значение w увеличивается на модуль |W|max, где |W|max - максимально допустимый размер окна наблюдений. Значение Wbestd представляет собой краткосрочную память, выражающую движущуюся эмпирическую нижнюю границу оценки времени достижения узла d из текущего узла.
T и M могут рассматриваться как локальная память узлов, которая содержит различные аспекты сетевой динамики сети. Модель M содержит абсолютные оценки расстояния/времени ко всем узлам, в то время как таблица маршрутизации содержит относительные вероятностные измерения полезности для каждой пары линия связи - узел-приемник при использовании такого метода маршрутизации на всей сети.
Таким образом, после определения основных структур данных алгоритма его можно описать в следующем виде:
 Sk->d.
Sk->d.
 и
и  , и для определения лучшего значения, передаваемого в окно наблюдения Wd'. В этом
случае используется параметрическая модель времени движения муравья к узлу назначения d'. Среднее значение времени
движения муравья к узлу назначения d' и его дисперсия могут сильно варьироваться, в зависимости от состояний трафика:
"плохое" время (путь) при низкой загрузке трафика может быть "хорошим" при сильной загрузке трафика. Статистическая модель должна
уметь выявлять эти изменения и исследовать помехоустойчивость системы при колебаниях трафика.
, и для определения лучшего значения, передаваемого в окно наблюдения Wd'. В этом
случае используется параметрическая модель времени движения муравья к узлу назначения d'. Среднее значение времени
движения муравья к узлу назначения d' и его дисперсия могут сильно варьироваться, в зависимости от состояний трафика:
"плохое" время (путь) при низкой загрузке трафика может быть "хорошим" при сильной загрузке трафика. Статистическая модель должна
уметь выявлять эти изменения и исследовать помехоустойчивость системы при колебаниях трафика.
В алгоритме AntNet для, того чтобы искусственные муравьи могли определить является ли этот путь хорошим, то есть как часто другие муравьи используют его, вводится специальный укрепляющий коэффициент, аналог феромонов.
Авторы алгоритма определяют укрепляющий коэффициент r=r(T,Mk) [2], как функцию от времени движения муравья,
которое рассчитано относительно локальной модели трафика. Коэффициент r это безразмерная величина,
r (0,1], используемая текущим узлом k как положительный укрепляющий коэффициент для
узла f, из которого пришел Н-муравей Bd->s. Коэффициент r учитывает некоторое среднее число
наблюдаемых величин и их дисперсии для расчета полезности времени движения T, такого что, чем меньше T, тем выше r.
Вероятность Pfd' увеличивается за счет укрепляющего коэффициента следующим образом [2]:

Вероятности Pnd' для узла назначения d' других соседних узлов n получают неявно отрицательные укрепляющие коэффициенты с использованием нормализации. Т.е. их значения уменьшаются, так что сумма вероятностей остается равной 1 [2]:
Укрепляющий коэффициент является критической величиной, которая может быть определена с точки зрения трех аспектов:
В [2] предлагается два способа вычисления укрепляющего коэффициента r:
Wbest это лучшее время, полученное муравьем при движении по направлению к узлу d,
в окне наблюдений W. Максимальный размер окна (максимально кол-во рассмотренных опытов до изменения значения Wbest)
устанавливается на основе коэффициента  , который предсталяет собой весовой коэффициент,
определяющий количество эффективных опытов, которые действительно влияют на оценку значения математического ожидания.
, который предсталяет собой весовой коэффициент,
определяющий количество эффективных опытов, которые действительно влияют на оценку значения математического ожидания.
Isup и Iinf это оценки границ доверительных интервалов математического ожидания
(соответственно нижняя и верхня граница). Iinf устанавливается равным Wbest, а
 , где
, где  , а коэффициент
, а коэффициент  уровень уверенности [2].
уровень уверенности [2].
Первое слагаемое в формуле для расчета укрепляющего коэффициента показывает отношение между текущим и лучшим временем движения агента. Это слагаемое корректируется вторым слагаемым, которое показывает, как сильно значение T отклоняется от Iinf относительно расширения доверительного интервала, т.е., учитывает постоянство в последних временах обхода. Коэффициенты с1 и с2 это весовые коэффициенты, определяющие важность каждого слагаемого. Первое слагаемое наиболее важно, в то время как второе - играет роль корректора. В работе [2] установлено, что поведение алгоритма довольно стабильно для значений с2 в пределах от 0.15 до 0.35. Весовые коэффициенты с1 и с2 в [2] соответственно установлены с1=0.7 и с2=0.3.
Алгоритм устойчив к изменениям значения , которое определяет уровень уверенности:
изменяя уровень уверенности в пределах от 75% до 95%, производительность почти не меняется. Лучшие результаты были получены при
значениях в пределах 75%-80% [2].
Окончательно, значение r преобразуется с использованием сжимающей функции s(x) [2]:
Сжатие значений r позволяет системе быть более чувствительной к определению наилучших (высоких) значение r, при этом иметь тенденцию к насыщению плохих (близких к 0) значение r: сжимается нижняя часть значений и расширяется их верхняя часть. Таким образом, выделяются хорошие результаты, а роль низких значений укрепляющего коэффициента понижается.
Коэффициент a/Nk в формуле для сжимающей функции определяет параметрическую зависимость сжатого значений укрепляющего коэффициента от количества |N|k соседей укрепляемого узла k: чем больше количество соседей, тем больше укрепляющий коэффициент (см. рис. 5.3).
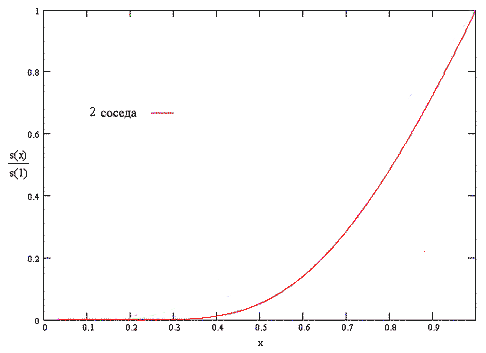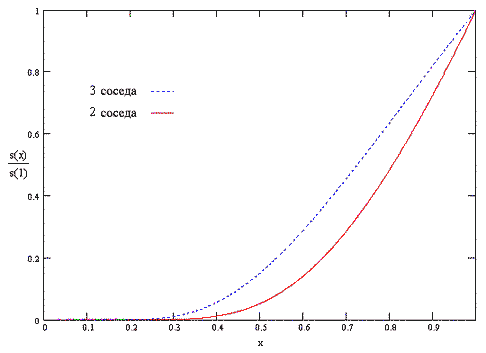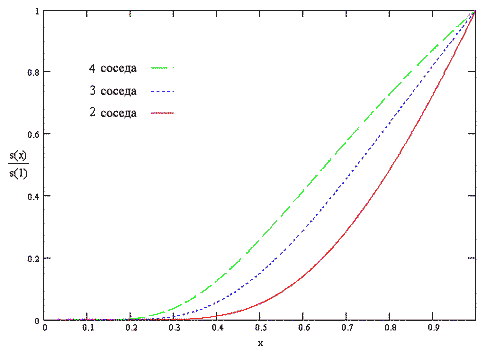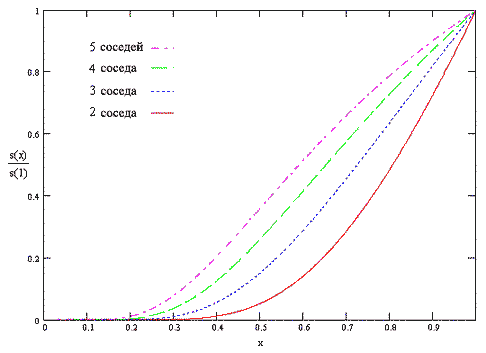
Рисунок 5.3 - Пример использования сжимающей функции для переменного количества соседних узлов
На данный момент система ROUTING_SIMULATOR позволяет промоделировать два алгоритма маршрутизации: AntNet и OSPF. Целью сравнения двух алгоритмов было получение двух характеристик: пропускной способности (байт/сек) и потери пакетов (пакетов/сек).
Эксперименты проводились на сети с 8-ю узлами (см. рис. 6.1), пропускная способность линий связи которой равна 1 МБит/с. Для создания рабочей нагрузки, между всеми парами узлов сети открываются сессии передачи пакетов данных. Каждая сессия имеет скорость передачи (bit rate) 105 байт/сек. Длина пакетов данных , которыми обмениваются узлы, составляет 512 байт.
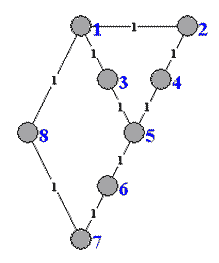
Рисунок 6.1 - Простая компьютерная сеть
Моделирование поведения алгоритмов длилось 300 виртуальных секунд. На 100-й секунде моделирования происходит резкое изменение скорости передачи данных в сессии между 1-м и 6-м узлами с 105 байт/сек на 1.4*106 байт/сек, т.е. 1-й узел выступает в роли хот-спота [2]. Выключение хот-спота происходит на 200-ой секунде.
Для алгоритмов AntNet и OSPF получены графики для пропускной способности сети между 1-м и 6-м узлами и общей потери пакетов в сети.
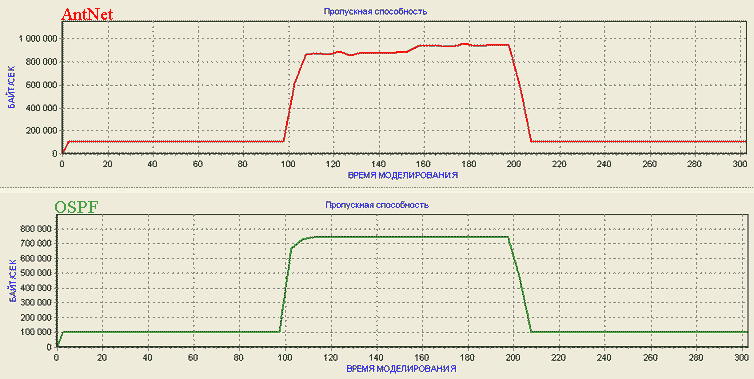
Рисунок 6.2 - Графики пропускной способности (байт/сек) для алгоритмов AntNet и OSPF
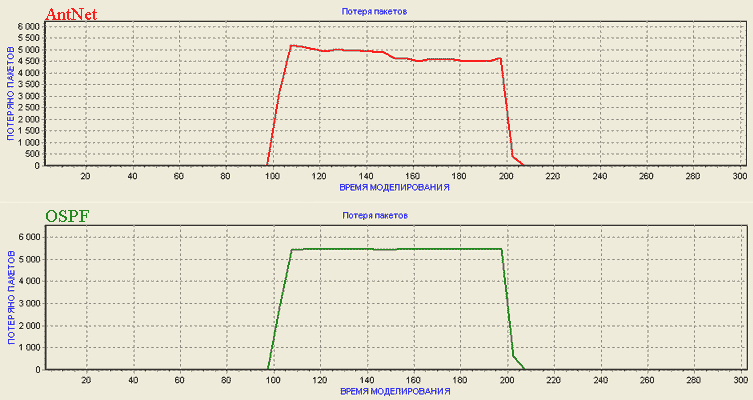
Рисунок 6.3 - Потеря пакетов для алгоритмов AntNet и OSPF
Из рисунков 6.2 и 6.3 видно, что до включения хот-спота в узле №1 пропускная способность между 1-м и 6-м узлами для обоих алгоритмов одинакова и составляет 100000 байт/сек. При включении хот-спота пропускная способность и уровень потери пакетов резко возрастают. Для алгоритма OSPF эти характеристики со временем стабилизируются (перестают изменяться), вплоть до момента выключения хот-спота. Алгоритм AntNet, напротив, все время пытается изменить маршрутные таблицы для оптимизации работы сети. Вследствие этого пропускная способность для AntNet постоянно растет, а уровень потери пакетов - снижается.
Маршрутизация играет важную роль в обслуживании коммуникационных сетей. При правильно организованной маршрутизации возможно оптимизировать такие важные показатели производительности сети как пропускная способность и задержка пакетов.
В результате проведенной работы реализовано два алгоритма маршрутизации - AntNet и OSPF. При исследовании поведения алгоритмов в одинаковых экспериментальных условиях было получено, что производительность алгоритма AntNet лучше, чем у OSPF. Для объективной оценки производительности AntNet необходимо сравнить его еще с некоторыми адаптивными алгоритмами маршрутизации, такими как BF, Q-R, PQ-R и SPF. Реализация этих алгоритмов планируется в дальнейших исследованиях.