|
|
|
| Main page | Masters site | DonNTU site | Search on DonNTU |
|---|
Boiko Anna (annushka_b@mail.ru)Group ASC00aTheme of work: "Projecting of computer subsystem of data compressing by method of genetic programming"The chief of work is Orlov Yury Konstantinovich |
|---|
| Autobiography |
| Master work |
| Report about searching |
| Links catalogue |
| Library |
| Individual task |
Abstract on theme of master work1. Description of data domain 1.1 The object of exploration 1.2 The problem of data keeping 2. The analysis of existing systems of compression 2.1 Use of the compressed tables 2.2 Bit packing 2.3 Arithmetic coding 3. The choice of a direction of development 3.1 Genetic programming as a method of compression of the data 3.2 Generalization of results of scientific search and analysis List of used literature IntroductionThe question about economical coding of information has been put in early seventy's, but it hasn't lost its actuality till nowadays. Lots of contemporary researchers note unsufficient theoretic work in this problem and inefficiency of data compression support. Interest in task of data compression in ODBC has been conditioned on an attempt to reduce physical volume of data bases. The value of input-output subsystem amounted the main part of equipment. Therefore it was very economically to use methods of data compression. Little increase of strokes processor used for coding and decoding was compensated for reduction of costs on input-output subsystem. This result of using data compression is claimed nowadays. Actually slump in prices on filing equipment was accompanied by corresponding increase of data base volume. Nevertheless at present time interest is shifting to increase of system of data control productivity by using comressing. Using of data compressing in ODBC is connected with solution of many tasks. Any realization of economical coding in ODBC is bound up with compromise between the range of compressing, required volume of online storage, number of conversion to external memory, calculating costs. It's need to use specific methods and modes of economical coding, as far as common methods don't satisfy a number of requirements. Practical value of realization is achieved only with providing fast access to any record or data element. Compressing methods with saving order are also claimed. They allow to make comparison operation without data decoding.
The problem of realization of data compressing in [ŃÓÁÄ] has also such aspects as optimization of query execution to compressed data, effective compressing of query execution results, economical coding of metadata, an estimate of advisability of separate elements compression, a choice of compression algorithm and its factors.
Because of progress in computer and engineering explorations the flow of information we get from many areas of science and technic increased in hundreds and thousands times. With the development of globalization and fusion it was normal to appear a lots of universal projects and organizations which aimed to join all knowledges in whole system and used data as much as possible. There's a great number of such areas of world processes exploring. In this work it's examined one of them. It's the science of amnion - hydrology. Exceptional role of water in the life of human being conditions on huge and constantly increasing attention to exploring hydrosphere. The main work on earth-based observation, gaining information about hydrosphere condition is made by national meteorological, hydrological and geological services and hydroeconomic organizations of countries. Founding of national services and international co-operation services in hydrology reserching starts in the midlle of XIX century when in 1853 the programm of meteorology observaton has been developed to raise life safety in the sea. As a result of the progress in various scientific areas in XX century it has been developed and improved many methods of hydrology components observation. Corresponding measures have been accepted to exchange data beetween hydrology services. Developments in area of exploring satellites and computer technologies have leaded to creation the worldwide complex operation system called as Universal service of the weather that includes the global system of telecommunication and the global system of data processing. It has been also created the global oceanographic data collection system. Today at the terrestrial globe near 9 thousand stations works at the land. They make observations over air humidity, nebulosity, quantity of precipitations (among them 350 have been automotized or partly automotized). About 700 sea crafts make observations over numerous parameters of World ocean water condition (temperature, salinity and mineral composition of waters, currents directions). These data are enlarged with observations from commercial scout planes (near 10 thousand summaries in day). Nowadays there are huge quantity of insitutes and organization that go in for hydrological researching. It's invented and realized dozen of thousands universal programms and projects. In 2003 the group of scientinsts from Japany, USA and Europe prepared the programm of global ocean exploring. Throughout the world it has been arranged about 3 thousand of self-submered sensors. During 3-4 years they have been gathering detailed data about currants, have been fixing fluctuation in temperature, concentration of solt and other parameters which as an specialist opinion will help to predict change in climate of our planet. This experinment has been called "Argo-programm". Equiped with specialized apparatus sensors submerge at a depth of 2 kilometers and stay there for ten hours. After then devices about meter in length and 20 centimeters in diameter emerge automatically, get in touch with satellites, transmit information to land-based stations and then go under water again. To keep and automatize all data it's created specialized data banks. In the countries with a small territory it's customary to create unifed bank for all components of hydrosphere or 2-3 banks that gather information about basic hudrological components. Such an enormous volume of information that must be processed every day (and the main problem is keeping information during thousand years for further analisys) leads to necessity of data compression and further restoration with minimum of loses. The problem of data keepingThe large volumes of the collected information and the requirements to reduction of terms of its granting to the consumers cause necessity of use for its processing and generalization of modern electronic engineering. For a storage and automation of generalization of the information the special databanks are created. In the countries with small on the area by territory it is accepted to create uniform banks for all components of hydrosphere or two - three banks assembling the information on atmospheric components of hydrosphere, water objects of a land, World ocean (including internal seas, sea mouth of the rivers). The effective sanction of information resources and open access to the spatially allocated experimental data are based on use of information service of global networks the Internet, i.e. on the basis of Web-technologies. With this purpose the systems of the reference with structures metadata, providing the tax both distribution of experimental data and results of thematic processing are developed, thus the archive is united with the regional centres of geoecological monitoring by a global network the Internet. The important element is the development of structure of the interface, archiving and network exchange of the data of remote sounding. It requires development of retrieval systems and realization of the removed interactive access of the external users on a network the Internet to experimental data and electronic catalogues of processing, granting to the users of an opportunity for interactive access to them in a mode on-line. Modern line of development of the programs of research of the Earth from space is the creation in a number of the countries of electronic libraries of the space information. These national information systems use flows of satellite various tasks, given for the decision, of remote sounding determined as by scientific community, and concrete branches of industrial activity. For example, in USA for information support of the national system of supervision of the Earth from space (EOS) NASA has created EOSDIS - the ramified infrastructure of the collecting, archiving and distribution of the satellite data to the consumers. The system EOSDIS has concentrated huge files geospatial given, received from satellites. It creates serious problems at organization of a storage and access to the satellite data, as the standard software packages of databases can not them effectively process. For example, each staff of the device ŇĚ of the satellite Landsat in six spectral channels (sanction 30 ě) and one thermal (sanction 120 ě) covers the area 170 ő 185 square kilometers. In result volume of such staff of the satellite Landsat reaches 400 Mbytes. The daily volumes of the raw satellite data , acting in system EOSDIS, are estimated in 480-490 Gbytes. Volume of the processed data in system EOSDIS reaches 1600 Gbytes per day.
Role and importance of system of a storage are determined by constantly growing value of the information in a modern society, the opportunity of a data access and management by them is a necessary condition for performance of business - processes.
The irrevocable loss of the data subjects business of serious danger. The lost computing resources can be restored, and the lost data, at absence of the competently designed and introduced system of reservation, any more are not subject to restoration.
On the data Gartner, among the companies, injureds of accidents and survived large irreversible loss corporate given, 43 % could not continue the activity.
In the majority of systems of support of acceptance of the decisions (ŃĎĎĐ) the large volumes of the data are usually used which are stored in the several very large tables. At development of similar systems of the requirement to disk space can quickly grow. Now storehouses of the data of volume of hundred terrabytes meet even more often. At the decision of problems with the disk space which has appeared in Oracle 9i Release 2 opportunities of compression of the table can essentially reduce volume of disk space used by the tables of a database and, in some cases, to increase productivity of searches. The opportunity of compression of the tables in Oracle9i Release 2 is realized by removal of duplicated values of the base, given from the tables. The compression is carried out at a level of blocks of a database. When the table is determined as compressed, the server reserves a place in each block of a database for a storage of one copy of the data meeting in this block in several places. this reserved place is named as the table of symbols. The data, marked for compression, are stored only in the table of symbols, instead of in lines of the data. At occurrence in a line given, marked for compression, in a line, instead of data, the index on the appropriate data in the table of symbols is remembered. The economy of a place is reached at the expense of removal of superfluous copies of values of the data in the table. The compression of the table does not influence the user or developer of the applications in any way. The developers address to the table equally, irrespective of, it is compressed whether or not, therefore SQL-searches should not be changed, when you decide to compress the table. The parameters of compression of the table are usually established and change by the managers or architects of a database, and the participation in this process of the developers or users is minimal. The basic reason of use of compression of the table is the economy of disk space. The table in the compressed kind usually occupies less places. The compression of the table in Oracle9i Release 2 allows essentially to save disk space, is especial in databases containing the large tables only for reading. If to take into account the additional requirements to loading and insert of the data, and also correctly to choose the tables - candidates for compression, the compression of the tables can appear a tremendous way of economy of disk space and, in some cases, increase of productivity of searches.
But there are disadvantages:
The method of bit packing consists in coding value of attribute by bit sequences of fixed length. For each compressed column it is required to store the appropriate table of code conversion. The word length of code sequences is defined by amount of various numbers, which values are really accepted by attribute, or capacity of a range of definition of attribute. It is obvious, that required length of a code N is equal [log 2 n ], where n is a capacity of set of real or allowable values of attribute. The given method is considered in one of earliest clauses on compression of databases. The method is mentioned alongside with other receptions under the name " bit compression ". The packing of bits is a simple way of compression at a level of value of attributes, which realization is easy. Also it is important, that at the appropriate realization is kept an order. But a problem at use of the given method is the processing of occurrence of new values of attribute. In this case it can be required to recode all values of a column, if [log 2 n ] becomes more initial N. Essence of a method: for each column is minimal and maximum value. The values which have got inside of this range, are consistently coded. Length of a code word is constant and is defined(determined) by the size of a range. An example: let there is a sequence of lines from two fields = {(100, 21), (98, 24), (103, 29)}. For the first field a range [98, 103], for second - [21, 29]. The capacity of the first set of values is equal 6, second - 9. Therefore will be submitted as: = {(0102, 00002), (0002, 00112), (1012, 10002)}. It is obvious, that if the compression is applied to fields of fixed length, their new length also is fixed. For each column it is necessary to store(keep) only borders of a range and, probably, length. The code conversion is required only in case of an output of value for borders of a range. The degree of compression is stronger than all depends on distribution of values of each attribute for recordings stored in one page. It is possible cardinally to improve compression at the expense of redistribution of recordings on pages at processing at a file level.
The method of packing of bits can not supply a significant degree of compression concerning other methods, that, nevertheless, in many applications can compensate by high speed of data processing and preservation an order.
Completely other decision offers so-called arithmetic coding. The arithmetic coding is a method allowing to pack symbols of the entrance alphabet lost-free provided that is known distribution of frequencies of these symbols and is optimal, since the theoretical border of a degree of compression is achieved. The prospective required sequence of symbols, at compression by a method of arithmetic coding is considered as some binary fraction from an interval [0, 1). The result of compression is represented as a sequence of binary figures from recording this fraction.
The idea of a method consists in the following: the initial text is considered as recording of this fraction, where each entrance symbol is "figure" with weight proportional to probability of its occurrence. It explains an interval appropriate to the minimal and maximal probabilities of occurrence of a symbol in a flow.
Idea of genetic programming (GP) - for the first time has offered Coza in 1992, basing on the concept of genetic algorithms (GA). This idea consists that as against GA in GP all operations are made not above lines, and above trees. Thus the same operators, as well as in GA are used: selection, crossing and mutation.
In GP the hromosomes are the programs. The programs are submitted as trees with functional (intermediate) and terminal (final) elements. Terminal elements are the constants, action and function without arguments, functional - function using arguments.
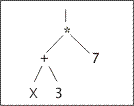
To apply GP to any problem, it is necessary to determine: The first main step in preparation of use of genetic programming should identify set of terminals. The set of terminals, alongside with a set of functions, represents components, from which the computer program for the complete or partial decision of a problem will be created. The second step consists in definition of functional set, which elements should be used for generation of mathematical expressions. Each computer program (that is, analyzed tree, mathematical expression) is a composition of functions from set of functions F and terminals from terminal set T (in case of programs - functions it is constants and variable).
The set of possible internal sites (not sheet), used in trees of parse used in genetic programming, refers to as as functional set:
Space of search of genetic programming is the set all possible recursion compositions of functions of set C. In functional set can be applied arithmetic, mathematical, áóëĺâű and other functions. The terminal set can be entered by variables, constants or directive commands. The sets F and T should have properties of locking and sufficiency. THE LOCKING requires that each function from set F should be capable to accept by argument any values and types of the data, which can be returned by any function from set C. It warns mistakes in execution time of the programs received by genetic programming. For maintenance of a condition of isolation it is possible to use protection of operations - compulsory reduction of the acting data to a range determined by concrete operation. For example, the operation of extraction of a root can be protected from occurrence of negative argument by compulsory account of the module from this argument. Alternative to protection can be automatic correction of mistakes in the program or application of the penalties for mistakes. THE SUFFICIENCY demands that the functions from set C should be capable to express the decision of the put task, that is, that the decision belonged to set all possible recursive compositions of functions from C. However to prove, that the chosen set C it is enough, it is possible only in rare cases. Therefore, at a choice of this set, as well as at a choice of the basic operations of genetic algorithm, it is necessary to rely only on intuition and experimental experience.
The generalized circuit of genetic algorithm
Pic. 2 - Animation. Hromosome generation. To reproduction push button on the picture The purpose of use of genetic programming for compression of the data is, that for the large set of the entering data (should do not matter what sorts, i.e. it can be temperature, humidity, pressure, any other factors and parameters of hydrological researches) to pick up functions, which optimum turn off these data and allow then at an available type of function, and also its factors to receive these given for processing. If there are 1000 points fixing any parameters, the method of compression will consist in selection 5-6 or more functions, with the help of which association it will be possible then to receive all set of points. Except for compression of the data the given work assumes the simultaneous analysis of the data, which can be traced on the large temporary pieces and thus not necessarily đŕńęîäčđîâŕíčĺ. So for example at the analysis of temperature, seeing, that the function of temperature has an approximate kind of a straight line it is possible to reduce measurements on the given site of object or to make them by more discrete. The scientific character of work consists in drawing up of the algorithm of search of such functions, definition of an interval, in which the prospective factors of functions, and also rating of productivity of such algorithm can lay depending on different volumes of sets.
Thus it is possible to allocate the following tasks and purposes of the master work:
|