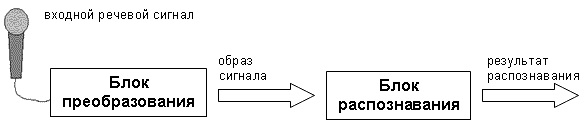
Рисунок 1.1 - Загальна схема розпізнавання мовлення
Русский | Українська
Email: bond005@yandex.ru
ЗМІСТ
Діалог з комп'ютерами, роботами, автоматизованими системами керування за допомогою мовних повідомлень відкриває великі перспективи:
У зв'язку із збільшенням інтенсивності обміну інформацією в системі «людина-машина» особливе значення має зниження навантаження на тактильно-зоровий канали людини. Наприклад, у системах керування цікавою є ідея голосового контролю і управління станом системи (мовне спілкування для контролю стану роботи літака, телефон з голосовими командами, мовне керуванням виробничими процесами). Впровадження голосового інтерфейсу залишить очі і руки оператора (пілота, водія, робочого за верстатом) вільними від перевантаження, що підвищить надійність і якість керування.
Використання мовного діалогу в системах масового обслуговування населення також актуальне [Жожикашвили и др., 2003]. Крім виняткової зручності для населення, такі системи підвищують комерційну вигоду як за рахунок залучення додаткової клієнтури, так і шляхом заміни людини-оператора комп'ютерними системами з голосовим інтерфейсом.
Про все зростаючу необхідність включення мовного інтерфейсу в сучасних людино-машинних системах свідчить і поява комерційних розробок систем, що використовують мовний інтерфейс. Так, NaturallySpeaking фірми Dragon System дозволяє редагувати і форматувати текст за допомогою власного текстового процесора без використання клавіатури та миші. Компанія IBM розробила аналогічну програму, що дозволяє здійснювати мовне введення і форматування тексту в текстовому процесорі MS Word. На практиці ці програми показують недостатньо високі результати (при тестуванні точність не досягла навіть 90% [Лукьянюк, 2006]). Корпорація Microsoft також розпочала активно займатися впровадженням мовного інтерфейсу в свої програмні продукти. За допомогою компонент MS Speech API програміст може організовувати мовний інтерфейс у будь-якій прикладній програмі. Але, не дивлячись на заявлену у фірмовій документації точність розпізнавання 95% [Буторін, 2005], на практиці точність розпізнавання і, отже, надійність програмних систем, що використовують мовний інтерфейс на основі MS Speech API, є невисокою.
1 АНАЛІЗ І КЛАСИФІКАЦИЯ ОСНОВНИХ МЕТОДІВ РОЗПІЗНАВАННЯ МОВЛЕННЯ
Реалізація мовного діалогу заснована на рішенні задачі розпізнавання мовлення. Основні етапи розпізнавання мовлення приведені на рисунку 1.1.
Рисунок 1.1 - Загальна схема розпізнавання мовлення
Залежно від області застосування мовного діалогу вимоги до системи розпізнавання мовлення будуть різними. Наприклад, для систем масового обслуговування населення розпізнавання повинне задовольняти наступним критеріям [Жожикашвили и др., 2003]:
Для систем голосового керування розпізнавання злитого мовлення не є таким актуальним, оскільки керування може здійснюватися за допомогою обмеженого набору команд (ключових слів). У випадках обмеженого доступу до системи керування розпізнавання слів повинне бути дикторозалежним (настроюватися на голос однієї особи або групи осіб). Але точність розпізнавання повинна бути ще вищою, тому що ціна помилки в процесі керування потенційно небезпечними пристроями (літаками, автомобілями і тощо) є дуже високою.
Для створення системи розпізнавання мовлення необхідно вирішити дві головні задачі:
Сучасні пристрої розпізнавання мовлення не забезпечують достатньої точності розпізнавання або розпізнають малу кількість слів, що накладає великі обмеження на їх використання в реальних системах. Це пояснюється не найвдалішим вирішенням вищенаведених задач. Тому розробка мовних інтерфейсів як для різних систем керування, так і для систем масового обслуговування, – це питання, що гостро стоїть на повістці сьогодення.
Існують три базові моделі мовлення:
Найточнішими з погляду розпізнавання є системи, засновані на словарній моделі, але їх область застосування обмежується системами керування, що мають невелику кількість команд. Для розпізнавання злитого мовлення в системах масового обслуговування населення більш придатна фонетична, складова або змішана модель, де використовуються як фонеми і склади, так і цілі слова (цифри, числа, деякі команди) [Жожикашвили и др., 2003].
Сучасні методи розпізнавання грунтуються на:
Еталони формуються шляхом статистичної обробки великого числа шаблонів. Порівняння вхідного сигналу з еталоном можна здійснювати за допомогою нечіткого зіставлення образів [Асаи и др., 1993].
Друга модель розпізнавання є складнішою. У ній процес вимови моделюється за допомогою апаратів прихованих марківських ланцюгів або нейронних мереж [Жожикашвили и др., 2003, Иванов и др., 2002]. Використання останніх дає велику точність, але вимагає застосування ефективного методу навчання системи (інакше навчання може не завершитись успіхом).
Дана робота присвячена розробці мовного каналу керування текстовим процесором Microsoft Word, який доповнюватимемо стандартний візуальний інтерфейс. Раціональне поєднання мовного і стандартного візуального засобів керування процесом вводу та редагування текстової інформації дозволить знизити навантаження на тактильно-зоровий канал людини і завдяки цьому підвищити ефективність його роботи. Функціональна схема такої системи наведена на рисунку 2.1.
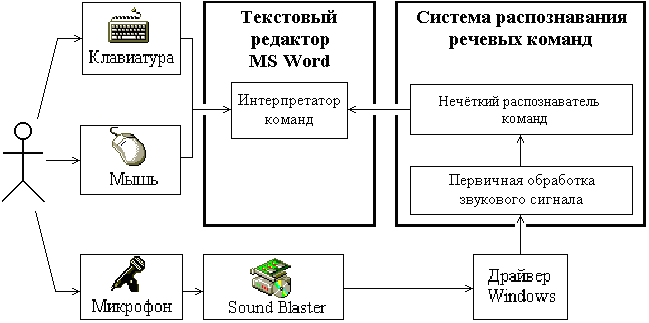
Рисунок 2.1 - Структура мовного каналу керування текстовим редактором MS Word
Як базова модель мовлення використовується словарна модель, оскільки її недолік – велика залежність від словника – в даному випадку є не недоліком, а обмеженням предметної області (кількість мовних команд і, відповідно, об'єм словника відомі заздалегідь), а перевага – найбільша в порівнянні з іншими моделями точність – є істотною.
Розпізнавання мовних команд пропонується здійснювати за допомогою підходу, що базується на зіставленні мовних еталонів. У роботі [Асаи и др., 1993] описаний метод нечіткого зіставлення образів і наведена висока оцінка його ефективності в розпізнаванні англійських, німецьких і японських слів. Проте зміни тривалості однакових мовних образів, обумовлені різною швидкістю вимови звуків одних і тих же слів, у вказаній роботі розглядаються тільки як лінійні з метою зменшення об'єму обчислень. Але зміна довжин мовних образів у загальному випадку є нелінійною [Винцюк, 1987], тому доцільно врахувати цю нелінійність при побудові моделі часової нормалізації.
У даній роботі пропонується використовувати метод нечіткого DTW-зіставлення [Федяев и др., 2006], в якому нелінійна часова нормалізація образів, що порівнюються, здійснюється на основі методу динамічного спотворення часу (Dynamic Time Warping, або DTW). Проводиться порівняльний аналіз ефективності роботи системи розпізнавання, яка використовує лінійну нормалізацію, і системи, що вирівнює довжини образів по алгоритму DTW.
3 МЕТОДИ НЕЧІТКОГО ЗІСТАВЛЕННЯ І НЕЧІТКОГО DTW-ЗІСТАВЛЕННЯ МОВНИХ ОБРАЗІВ
3.1 Отримання інформативних ознак мовного сигналу
Мовний сигнал представляється у вигляді двовимірного спектрального часового образу (СЧО), який можна отримати за допомогою короткострокового перетворення Фур'є (рис.3.1а) [Рабинер и др., 1981]. Такий образ відображає зміну за часом амплітуд заданих частотних складових мовного сигналу і добре виражає особливості мовлення, що дає можливість його використовувати для автоматичного розпізнавання слів, що вимовляються диктором [Чистович и др., 1976]. СЧО дозволяє виділити місцеположення резонансних частот, тобто локальних викидів, що є визначальною особливістю мовного сигналу [Асаи и др., 1993]. На цій підставі СЧО можна перетворити до бінарного вигляду, не втрачаючи вказаних інформативних ознак мовлення, за допомогою наступної заміни: 1 – на місці локального викиду, 0 – в інших місцях. Отриманий образ називають бінарним спектральним часовим образом (БСЧО) і використовують його як віддзеркалення особливостей мовного сигналу (рис. 3.1б).
Як одиниці мови розглядаються слова, набір яких визначає словарний склад мовного спілкування.
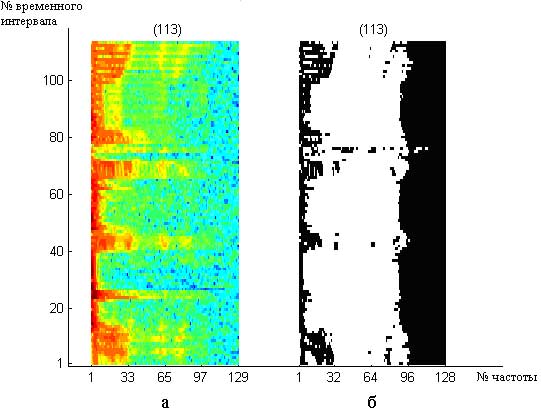
Рисунок 3.1 - Приклад спектрально-часового представлення слова «автоформат»: а – СЧО; б – БСЧО
3.2 Часове вирівнювання мовних образів
Різні реалізації мовних образів, що відносяться до одного і того ж класу, можуть значно відрізнятися один від одного за тривалістю (рис.3.2). Це пов'язано з нестабільністю темпу мовлення диктора, яка викликана впливом інтонації, акценту тощо. Для коректного зіставлення мовних образів необхідно проводити їх вирівнювання за довжиною. Вирівнювання шляхом лінійного стиснення або розтягування однієї реалізації слова до величини іншої вирішує задачу лише частково, оскільки не враховується одна важлива властивість мовного сигналу – нерівномірність його протікання в часі [Винцюк, 1987]. Ця властивість мовлення виражається в нерівномірній зміні тривалості звуків слова при зміні тривалості слова в цілому. Тому зіставлення доцільно виконувати за допомогою нелінійної тимчасової нормалізації [Федяев и др., 2006].
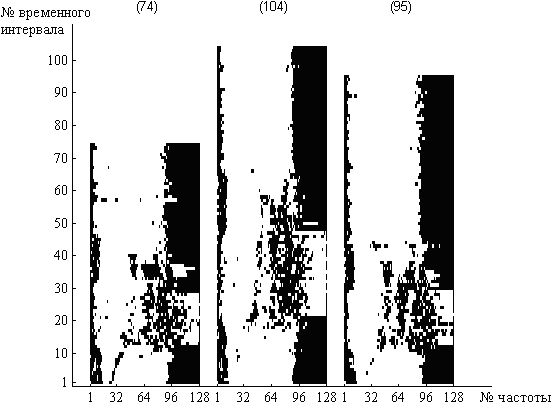
Рисунок 3.2 - БСЧО різних реалізацій слова «Курсив»
Для нелінійного вирівнювання образів, що зіставляються, був використаний алгоритм, заснований на визначенні найкращої відповідності вхідних і еталонних мовних образів, відомий як метод DTW [Wrigley, 2006]. Опишемо суть алгоритму. Позначимо евклідову відстань між i-м рядком матриці вхідного БСЧО та j-м рядком матриці еталона як Dij. Для знаходження рядків матриці вхідного БСЧО, які найкраще відповідають рядкам матриці еталона, визначалася матриця C розміру (M*N) за наступними формулами:
де M – кількість рядків матриці вхідного БСЧО; N – кількість рядків матриці еталона.
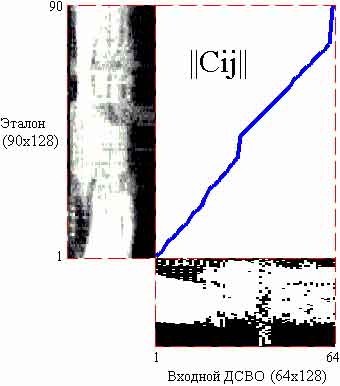
Рисунок 3.3 - Графічне відображення процесу вирівнювання вхідного БСЧО та еталона за алгоритмом DTW
На рис. 3.3 ламаною лінією з’єднані елементи матриці C, що відповідають найбільш схожим рядкам вхідного БСЧО та еталона слова «Маркеры». Вертикальний відрізок будується у разі, коли декілька рядків матриці еталона відповідають одному рядку матриці вхідного БСЧО. Горизонтальний відрізок будується у разі, коли декілька рядків матриці БСЧО відповідають одному рядку матриці еталона. Таким чином, на відміну від алгоритму лінійного приведення довжин, даний алгоритм забезпечує вирівнювання тільки спектрально подібних фрагментів вхідного БСЧО і еталонного образу.
3.3 Метод нечіткого зіставлення мовних образів
Для розпізнавання ізольованих слів, нормалізованих за часом, був застосований метод нечіткого зіставлення з еталоном [Асаи и др., 1993]. Еталонні образи для кожного слова словника формувалися як середнє арифметичне БСЧО різних варіантів вимови даного слова. В результаті формується бінарне нечітке відношення [Кофман, 1982] між множиною F (номерів частот f) і множиною T (номерів часових інтервалів t) у вигляді:
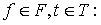 F R T
F R T
де R – нечітке відношення, яке ставить кожній парі елементів 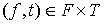 величину функції приналежності
величину функції приналежності 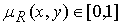 .
.
Позначимо число записаних слів через n, множину слів через I = {i1, i2, ..., in} і множину нечітких відносин, що характерні для кожного слова, через R = {r1, r2, ..., rn}. Вхідний невідомий образ y розглядається як звичайне (чітке) відношення між множиною частот і множиною часових інтервалів. Для нього обчислюються ступені схожості Sj з кожним нечітким відношенням rj . Результатом розпізнавання є слово j, таке, що
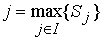
Ступінь схожості обчислюється за наступною формулою:
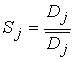 ,
,
де
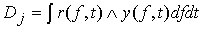 ,
,
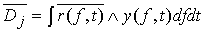 .
.
4 РОЗРОБКА МЕТОДИКИ ПОРІВНЯЛЬНОГО АНАЛІЗУ ПОЧАТКОВОГО ТА ПОЛІПШЕНОГО МЕТОДІВ НЕЧІТКОГО ЗІСТАВЛЕННЯ
Були проведені експериментальні дослідження, направлені на визначення якості розпізнавання слів російської мови за методом нечіткого зіставлення при лінійному і нелінійному вирівнюванні образів. Для експерименту була використана мовна однодикторна база даних, що включала звукозаписи 6 мовних команд керування текстовим процесором: «Автоформат», «Жирный», «Курсив», «Маркеры», «Найти», «Нумерация». Кожна мовна команда була представлена 30 реалізаціями, 15 з яких були використані для навчання системи, а 15 – для тестування. Таким чином, потужності повчальної та тестової множин склали 90 різних реалізацій вищезгаданих 6 слів.
Результати розпізнавання слів тестової множини за методом нечіткого зіставлення з використанням лінійного часового вирівнювання наведені в табл. 4.1, а з використанням часового вирівнювання по алгоритму DTW – в табл. 4.2.
Таблица 4.1 - Результати тестування системи з лінійним вирівнюванням
| Автоформат | Жирный | Курсив | Маркеры | Найти | Нумерация | Разом, % | |
| Автоформат | 15 | 0 | 0 | 0 | 0 | 0 | 100,00 |
| Жирный | 0 | 14 | 0 | 0 | 1 | 0 | 93,22 |
| Курсив | 0 | 0 | 15 | 0 | 0 | 0 | 100,00 |
| Маркеры | 0 | 0 | 0 | 13 | 0 | 2 | 86,67 |
| Найти | 0 | 0 | 0 | 0 | 15 | 0 | 100,00 |
| Нумерация | 0 | 0 | 0 | 0 | 0 | 15 | 100,00 |
| Якість розпізнавання досягла 96,67% | |||||||
Таблица 4.2 - Результати тестування системи з DTW-вирівнюванням
| Автоформат | Жирный | Курсив | Маркеры | Найти | Нумерация | Разом, % | |
| Автоформат | 15 | 0 | 0 | 0 | 0 | 0 | 100,00 |
| Жирный | 0 | 15 | 0 | 0 | 0 | 0 | 100,00 |
| Курсив | 0 | 0 | 15 | 0 | 0 | 0 | 100,00 |
| Маркеры | 0 | 0 | 0 | 15 | 0 | 0 | 100,00 |
| Найти | 0 | 0 | 0 | 0 | 15 | 0 | 100,00 |
| Нумерация | 0 | 0 | 0 | 0 | 0 | 15 | 100,00 |
| Якість розпізнавання досягла 100,00% | |||||||
Для перевірки гіпотези про те, що DTW-вирівнювання не дало суттєвого поліпшення якості розпізнавання, тобто гіпотези про рівність медіан двох вибірок (нульовій гіпотезі), пропонується використати знаковий критерій Вілкоксона з рівнем значущості 0,01 [Ермаков и др., 1982]. Знаковий критерій Вілкоксона не вимагає несуперечності розподілу генеральної сукупності значень випадкової величини нормальному закону [Ермаков и др., 1982], тому він може бути використаний для перевірки гіпотези, яка нас цікавить.
Обчислення виконувалися в системі MATLAB 6.5 [Дьяконов и др., 2001]. В результаті нульова гіпотеза була підтверджена, тобто впровадження DTW-вриівнювання у процедуру нечіткого зіставлення образів не дало суттєвих поліпшень. Але результати проведеного тесту не можна вважати об'єктивними з двох причин:
Зараз завершується формування мовної бази даних об'ємом більш ніж 12600 реалізацій слів, розбитих на 105 класів (мовних команд управління текстовим процесором MS Word). У формуванні мовної бази даних брало участь 43 диктори. Експерименти на матеріалі цієї мовної бази дозволить об'єктивніше порівняти метод нечіткого зіставлення образів, який використовує лінійну тимчасову нормалізацію, та запропоновану в даній роботі його модифікацію, засновану на нелінійній часовій нормалізації.
В результаті роботи був створений метод нечіткого DTW-зіставлення для розпізнавання ізольованих мовних слів, до яких можна віднести мовні команди керування текстовим редактором, і розроблена методика порівняльного аналізу методів розпізнавання ізольованих мовних слів. Застосування цієї методики для оцінки ефективності впровадження DTW-зіставлення у процедуру нечіткого зіставлення образів виявило, що DTW-зіставлення не привело до істотного поліпшення якості роботи методу нечіткого зіставлення образів. Проте необхідні подальші дослідження ефективності використання DTW-зіставлення при нечіткому зіставленні образів, тому що результати проведеного тесту не можна вважати об'єктивними з двох причин:
Надалі планується проведення експериментів на матеріалі мовної бази даних об'ємом більш ніж 12600 реалізацій слів, розбитих на 105 класів (мовних команд керування текстовим процесором MS Word). У формуванні мовної бази даних брало участь 43 диктори. Експерименти на матеріалі цієї мовної бази дозволять більш об'єктивно порівняти метод нечіткого зіставлення образів, який використовує лінійну часову нормалізацію, та запропоновану в даній роботі його модифікацію, засновану на нелінійній часовій нормалізації.
Також у результаті тестування був знайдений оптимальний баланс за критерієм ергономічності між мовною і тактильно-зоровою складовими інтерфейсу з текстовим редактором. Через мовний канал інтерфейсу доцільно організовувати передачу найбільш споживаних команд, а також макрокоманд (послідовностей простих дій), пов'язаних з складним редагуванням документа. Тактильно-зоровий канал доцільно використовувати для передачі команд, пов'язаних з позиціонуванням фрагментів документа в просторі.
На момент написання автореферату (червень 2006) дисертація не є закінченою. Дисертацію планується закінчити у жовтні 2006.