

Исследование способов распараллеливания в процессе трансляции
Выполнил Неботов Евгений Николаевич
В данной работе исследуются различные способы распараллеливания в процессе трансляции и создаётся интерпретатор с языка Пролог, использующий эти способы для повышения производительности на многопроцессорных системах, кластерах и подобных вычислительных системах.
Содержание
- Введение
- Мотивация
- Актуальность работы
- Цель и задачи исследования
- Методы исследований
- Научная новизна
- Практическая ценность
- Содержание работы
- Пролог как язык логического программирования
- Исследование существующих реализаций Пролога
- Архитектуры вычислительных систем с параллельной организацией вычислений
- Выводы
- Список использованных источников
Введение
В 70-е годы логическое программирование и базы данных развивались одновременно. Пролог - самый популярный язык ПРОграммирования в ЛОГике — появился как результат упрощения более общих методов доказательства теорем для достижения возможности эффективного программирования. Аналогично реляционная модель данных возникла в результате упрощения сложных иерархической и сетевой моделей для обеспечения возможности непроцедурного манипулирования
множественными данными. На протяжении 70-х и в начале 80-х годов Пролог и реляционные базы данных получили широкое распространение не только в академической или научной среде, но и в деловом мире.
Интенсивные исследования взаимосвязи логического программирования и реляционных баз данных проводились с конца 70-х годов главным образом с теоретической точки зрения. Успеху интеграции способствовало то обстоятельство, что Пролог был выбран в качестве парадигмы языка программирования в японском проекте IВМ 5-го поколения. Целью этого проекта является разработка «ЭВМ следующего поколения», ориентированных на применение в области искусственного интеллекта и, следовательно, способных выполнять исключительно большое число логических выводов в единицу времени. Но достигнуть большего быстродействия возможно лишь двумя методами: экстенсивным (лучшие архитектуры, процессоры, большая тактовая частота) или интенсивным (оптимизация, разгрузка кода, распараллеливание). Постоянно обновлять и покупать новое дорогое оборудование менее рентабельно, чем приобрести программное обеспечение, которое работает эффективнее и быстрее на любом имеющемся оборудовании. Распараллеливание в процессе трансляции даёт преимущество в работе программы, в быстродействии выполняемого кода.
Мотивация
Актуальность работы
В свете повального увлечения объектно-ориентированными языками программирования, логическое программирование было забыто, между тем существует определённый ряд задач, который можно решить только с помощью логических языков программирования.
Развитие аппаратной части ЭВМ подошло к тяжелопреодолеваемому барьеру и сейчас для получения ощутимо более мощной системы недостаточно подождать пару месяцев или купи ть подороже, в данный момент актуально увеличение быстродействия и продуктивности за счёт организации и расширения кластеров, сложных многопроцессорных систем, поддержка которых программными продуктами достаточно ограничена.
Исследованию и решению данных вопросов и посвящена работа.
Цели и задачи исследования
Основной целью исследования является анализ существующих методов распараллеливания в процессе трансляции с технологической и функциональной точек зрения, создание при этом системы критериев для их оценки, существующих реализаций языка Пролог.
На основе анализа полученной модели и существующих решений, выработка рекомендаций по созданию веб-ориентированных систем и повышению эффективности их работы
Методы исследования
Главным методом исследования является качественный и количественный анализ реализаций языка Пролог с помощью выработанной системы критериев и сопоставление их с формальной моделью.
Научная новизна
Состоит в получении результатов анализа готовых решений, построении формальной модели и выработке предложений по повышению эффективности работы.
Практическая ценность
Состоит в создании на основе результатов исследования и создании нового интерпретатора языка Пролог, использующего преимущества многопроцессорной системы в процессе трансляции.
Содержание работы
Пролог очень хорошо подходит для описания взаимоотношений между объектами. Поэтому Пролог называют реляционным языком. Причем «реляционность» Пролога значительно более мощная и развитая, чем «реляционность» языков, используемых для обработки баз данных. Часто Пролог используется для создания систем управления базами данных, где применяются очень сложные запросы, которые довольно легко записать на Прологе.
В Прологе очень компактно, по сравнению с императивными языками, описываются многие алгоритмы. По статистике, строка исходного текста программы на языке Пролог соответствует четырнадцати строкам исходного текста программы на императивном языке, решающем ту же задачу. Пролог-программу, как правило, очень легко писать, понимать и отлаживать. Это приводит к тому, что время разработки приложения на языке Пролог во многих случаях на порядок быстрее, чем на императивных языках. В Прологе легко описывать и обрабатывать сложные структуры данных. Проверим эти утверждения на собственном опыте при изучении данного курса.
Прологу присущ ряд механизмов, которыми не обладают традиционные языки программирования: сопоставление с образцом, вывод с поиском и возвратом. Еще одно существенное отличие заключается в том, что для хранения данных в Прологе используются списки, а не массивы. В языке отсутствуют операторы присваивания и безусловного перехода, указатели. Естественным и зачастую единственным методом программирования является рекурсия. Поэтому часто оказывается, что люди, имеющие опыт работы на процедурных языках, медленней осваивают декларативные языки, чем те, кто никогда ранее программированием не занимался, так как Пролог требует иного стиля мышления, отказа от стереотипов императивного программирования.
Как язык программирования Пролог очень хорошо подходит для начального обучения программированию, так как он ориентирован на человеческое мышление в отличие от императивных языков, ориентированных на компьютер. Теми, кто только начинает изучать программирование, Пролог легко осваивается. Практически полное отсутствие синтаксических конструкций, таких как ветвления, циклы и т.д. также влияет на скорость освоения языка. Кроме того, программирование на Прологе, как мне кажется, упорядочивает мышление и позволяет человеку, изучающему этот язык программирования, лучше разобраться в своей мыслительной деятельности. Очень часто для того, чтобы запрограммировать решение задачи, программисту (или эксперту в некоторой предметной области) вначале требуется понять, как он сам решает эту задачу, провести некую формализацию, перевести свои знания из неявных в явные.
Рассмотрим, в каких областях наилучшим образом себя показал Пролог:
-быстрая разработка прототипов прикладных программ;
-автоматический перевод с одного языка на другой;
-создание естественно-языковых интерфейсов для существующих систем;
-символьные вычисления для решения уравнений, дифференцирования и интегрирования;
-проектирование динамических реляционных баз данных;
-экспертные системы и оболочки экспертных систем;
-автоматизированное управление производственными процессами;
-автоматическое доказательство теорем;
-полуавтоматическое составление расписаний;
-системы автоматизированного проектирования;
-базирующееся на знаниях программное обеспечение;
-организация сервера данных или, точнее, сервера знаний, к которому может обращаться клиентское приложение, написанное на каком-либо языке программирования.
Области, для которых Пролог не предназначен: большой объем арифметических вычислений (обработка аудио, видео и т.д.); написание драйверов.
На сегодня существует довольно много реализаций Пролога. Наиболее известные из них следующие: BinProlog, AMZI-Prolog, Arity Prolog, CProlog, Micro Prolog, МПролог, Prolog-2, Quintus Prolog, SICTUS Prolog, Silogic Knowledge Workbench, Strawberry Prolog, SWI Prolog, UNSW Prolog и т. д.
В нашей стране были разработаны такие версии Пролога как Пролог-Д (Сергей Григорьев), Акторный Пролог (Алексей Морозов), а также Флэнг (А. Манцивода, Вячеслав Петухин).
Таблица реализаций Пролога
Реализации Пролога
Название |
Параллелизм |
Разработчик |
Источник |
Платформа |
Parlog |
И-параллелизм |
Parallel Logic Programming Ltd. |
www.parlog.com |
программно |
QuProlog |
мультитрединг |
University of Queensland |
www.itee.uq.edu.au/ |
Unix |
Poplog |
|
Sussex University |
www.poplog.org |
Unix |
Open Prolog |
|
Mike Brady |
www..cs.tcd.ie/ |
Apple |
Newt Prolog |
|
Electechno |
http://www. |
Apple MessagePad Newton |
Акторный пролог |
Морозов А. А. |
www.cplire.ru/Lab144/1251/09010000.htm |
программно |
|
Сiao Prolog |
|
Ciao DevSystem |
www.clip.dia.fi.upm.es/Software/Ciao |
программно |
GNU Prolog |
|
Daniel Diaz |
www.gnu.org/software/prolog/prolog.htm |
программно |
SWI Prolog |
мультитрединг |
The SWI-Prolog Foundation. |
www.swi-prolog.org |
программно |
YAP Prolog |
ИЛИ-параллелизм |
LIACC/Universidade do Porto |
www.ncc.up.pt/~vsc/Yap |
SUN,Linux,SPARC |
B-Prolog |
delaying (coroutining) |
Neng-Fa Zhou |
www.sci.brooklyn.cuny.edu/~zhou/bprolog.htm |
программно |
Aquarius Prolog |
|
University of Southern California |
www.info.ucl.ac.be/people/PVR/aquarius.htm |
UNIX |
Arity Prolog |
мультитрединг |
Arity |
www.arity.com/www.pl/products/ap.htm |
программно |
BinProlog |
мультитрединг |
Binnet |
www.binnetcorp.com/BinProlog |
программно |
Brain Aid Prolog |
|
Martin Ostermann |
www.comnets.rwth-aachen.de/~ost/private.htm |
Transputing |
KLIC |
|
KLIC soft |
ftp.icot.or.jp/ifs/symbolic-proc/unix/klic/klic.tgz |
Sparcs, DEC 7000,Gateway P5-60 |
Архитектуры Вычислительных систем с параллельной организацией вычислений
Классификация Флинна
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М.Флинном. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD,MISD,SIMD,MIMD.
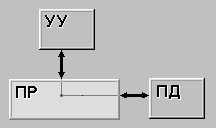
Рисунок 2.1 – SISD
SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины фон-неймановского типа, например, PDP-11 или VAX 11/780. В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом и каждая команда инициирует одну операцию с одним потоком данных. Не имеет значения тот факт, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка - как машина CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными попадают в этот класс.
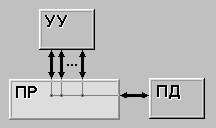
Рисунок 2.2 – SIMD
SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными - элементами вектора. Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производится либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1.
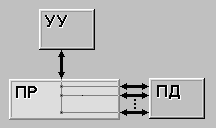
Рисунок 2.3 – MISD
MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей относят конвейерные машины к данному классу, однако это не нашло окончательного признания в научном сообществе. Будем считать, что пока данный класс пуст.
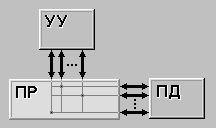
Рисунок 2.4 – MIMD
MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
Итак, что же собой представляет каждый класс? В SISD, как уже говорилось, входят однопроцессорные последовательные компьютеры типа VAX 11/780. Однако, многими критиками подмечено, что в этот класс можно включить и векторно-конвейерные машины, если рассматривать вектор как одно неделимое данное для соответствующей команды. В таком случае в этот класс попадут и такие системы, как CRAY-1, CYBER 205, машины семейства FACOM VP и многие другие.
Бесспорными представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое управляющее устройство контролирует множество процессорных элементов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинаковую команду и выполняет ее над своими локальными данными. Для классических процессорных матриц никаких вопросов не возникает, однако в этот же класс можно включить и векторно-конвейерные машины, например, CRAY-1. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных.
Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы: Cm*, C.mmp, CRAY Y-MP, Denelcor HEP,BBN Butterfly, Intel Paragon, CRAY T3D и многие другие. Интересно то, что если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) не над одиночным векторным потоком данных, а над множественным скалярным потоком, то все рассмотренные выше векторно-конвейерные компьютеры можно расположить и в данном классе.
Предложенная схема классификации вплоть до настоящего времени является самой применяемой при начальной характеристике того или иного компьютера. Если говорится, что компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным базовый принцип его работы, и в некоторых случаях этого бывает достаточно. Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания архитектуры, например dataflow и векторно--конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток - это чрезмерная заполненность класса MIMD. Необходимо средство, более избирательно систематизирующее архитектуры, которые по Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования.
Наличие пустого класса (MISD) не стоит считать недостатком схемы. Такие классы, по мнению некоторых исследователей в области классификации архитектур, могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
Классификация Хокни
Р. Хокни - известный английский специалист в области параллельных вычислительных систем, разработал свой подход к классификации, введенной им для систематизации компьютеров, попадающих в класс MIMD по систематике Флинна.
Как отмечалось выше , класс MIMD чрезвычайно широк, причем наряду с большим числом компьютеров он объединяет и целое множество различных типов архитектур. Хокни, пытаясь систематизировать архитектуры внутри этого класса, получил иерархическую структуру, представленную на рисунке:
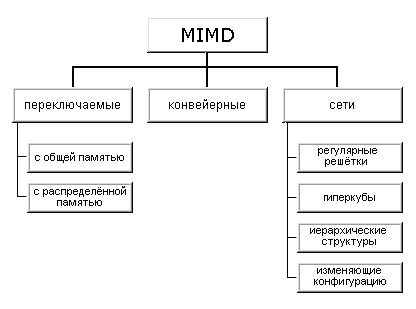
Классификация MIMD систем
Основная идея классификации состоит в следующем. Множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые автор называет конвейерными (например, процессорные модули в Denelcor HEP). Архитектуры, использующие вторую возможность, в свою очередь опять делятся на два класса:
-MIMD компьютеры, в которых возможна прямая связь каждого процессора с каждым, реализуемая с помощью переключателя;
-MIMD компьютеры, в которых прямая связь каждого процессора возможна только с ближайшими соседями по сети, а взаимодействие удаленных процессоров поддерживается специальной системой маршрутизации через процессоры-посредники.
Далее, среди MIMD машин с переключателем Хокни выделяет те, в которых вся память распределена среди процессоров как их локальная память (например, PASM, PRINGLE). В этом случае общение самих процессоров реализуется с помощью очень сложного переключателя, составляющего значительную часть компьютера. Такие машины носят название MIMD машин с распределенной памятью. Если память это разделяемый ресурс, доступный всем процессорам через переключатель, то такие MIMD являются системами с общей памятью (CRAY X-MP, BBN Butterfly). В соответствии с типом переключателей можно проводить классификацию и далее: простой переключатель, многокаскадный переключатель, общая шина.
Многие современные вычислительные системы имеют как общую разделяемую память, так и распределенную локальную. Такие системы автор рассматривает как гибридные MIMD c переключателем.
При рассмотрении MIMD машин с сетевой структурой считается, что все они имеют распределенную память, а дальнейшая классификация проводится в соответствии с топологией сети: звездообразная сеть (lCAP), регулярные решетки разной размерности (Intel Paragon, CRAY T3D), гиперкубы (NCube, Intel iPCS), сети с иерархической структурой, такой, как деревья, пирамиды, кластеры (Cm* , CEDAR) и, наконец, сети, изменяющие свою конфигурацию.
Заметим, что если архитектура компьютера спроектирована с использованием нескольких сетей с различной топологией, то, по всей видимости, по аналогии с гибридными MIMD с переключателями, их стоит назвать гибридными сетевыми MIMD, а использующие идеи разных классов - просто гибридными MIMD. Типичным представителем последней группы, в частности, является компьютер Connection Machine 2, имеющим на внешнем уровне топологию гиперкуба, каждый узел которого является кластером процессоров с полной связью.
Выводы
В магистерской работе будет проанализирован процесс трансляции, способы реализации процессов трансляции, этапы лексического анализа исходного кода, синтаксического анализа, анализа и генерации ошибок. Будут исследованы архитектуры параллельных вычислительных машин.
Начато создание интерпретатора с языка Пролог, имеющего высокую скорость работы благодаря распараллеливанию на этапе трансляции на многопроцессорных или кластерных системах.
Список использованных источников*
- Чери С., Готлоб Г., Танка Л., Логическое программирование и базы данных – М.: Мир, 1992.
- Ильинский Н. И., Язык Пролог в пятом поколении ЭВМ: Сб. статей 1983-1986 гг.- М.:Мир, 1988.
- Стерлинг Л., Шапиро Э. Искусство программирования на языке Пролог.-М.:Мир, 1986 г.
- http://dev.intuit.ru/department/pl/plprolog/1/1.htm, Интернет- Университет информационных технологий, Лекция #1: Введение в язык логического программирования Пролог.
- Легалов А.И. Процедурно-параметрическая парадигма программирования. Возможна ли альтернатива объектно-ориентированному стилю? - Красноярск: 2000. Деп. рук. № 622-В00 Деп. в ВИНИТИ 13.03.2000. - 43 с.
- http://parallel.ru/computers/taxonomy/flynn.htm, Лаборатория Параллельных информационных технологий НИВЦ МГУ, Классификации архитектур вычислительных систем.
- Flynn M. Very high-speed computing system .- Proc. IEEE. 1966. N 54.
- http://alice.stup.ac.ru/~dvn/uproc/books/prolog_morozov/lec2.htm, Логическое и функциональное программирование. Лекция №2
- http://parallel.ru/computers/taxonomy/hockney.htm, Лаборатория Параллельных информационных технологий НИВЦ МГУ, Классификации архитектур вычислительных систем.
*-полный список источников находится здесь(бумажные) и здесь(электронные). Приношу извинения, если на этой странице не были указаны все источники. Адрес для связи - raven@ukr.net.