








 |
 |
|
Введение и обоснованиеРаспространенные и достаточно мощные, современные персональные компьютеры (ПК) все больше обращают на себя внимания как на средство выполнения распределенных вычислений. ПК, объединенные локальной сетью предприятия или организации, представляют ныне дешевый и достаточно мощный вычислительный ресурс – так называемый гетерогенный кластер. Для решения проблемы организации распределенных вычислений на гетерогенных кластерах существует несколько стандартов, реализующих различные подходы к их выполнению: от традиционного параллельного программирования до организации распределенных вычислительных систем. Очевидно, что платой за высокий уровень абстракции и универсальность объектно-ориентированного подхода распределенных вычислительных систем является потеря производительности, ведь низкий уровень абстракции традиционных параллельных вычислений не позволяет полностью контролировать все операции обмена данных между процессами и зачастую приводит к дополнительным операциям преобразования данных. Поэтому, при переходе к более высокому уровню абстракции данных вполне естественно возникает вопрос, насколько именно уменьшается производительность, а также вопрос выбора круга задач, для которых такой переход является целесообразным. Целью магистерской работы является исследование возможности реализации заданного процесса вычислений на целевом кластере. Вычислительным процессом является моделирование роста популяции биологических клеток в моделирующем окружении Diana[3]. Особенности моделирования такой задачи состоят в расчете состояний большого количества однотипных объектов, которые достаточно слабо информационно связаны между собой. Расчет состояния одной клетки требует решения системы из около сорока диференциально-алгебраических уравнений. Состояния клетки может скачкообразно изменятся в зависимости от набора параметров. При этом имеет место смена системы уравнений для этой клетки. Одно из состояний вызывает деление клетки. Таким образом, количество клеток, подлежащих моделированию, возрастает. Целевой вычислитель – гетерогенный кластер, состоящий из персональных ЭВМ, объединенных в локальную вычислительную сеть института. Поскольку персональные компьютеры являются рабочими станциями сотрудников института, возникает ряд проблем, связанных с недостаточной стабильностью работы вычислительной сети. Компьютеры могут в произвольный момент отключатся от процесса вычислений (например, из-за перезагрузки системы сотрудником). Существующая в таком виде задача разбивается на 2 подзадачи: 1. Создание средств моделирования отдельной клетки 2. Исследование и создание средств управления группой моделей клеток. Ниже эти подзадачи рассмотрены подробнее: Для представления математического описания поведения отдельной клетки было решено разработать отдельный, так называемый «гибридный» тип моделей. Гибридность заключается в способности модели менять собственную систему уравнений в определенный момент времени при наступлении обозначенного события. Примером простой гибридной модели может служить химический сосуд с тремя отверстиями, как изображено на рисунке ниже: 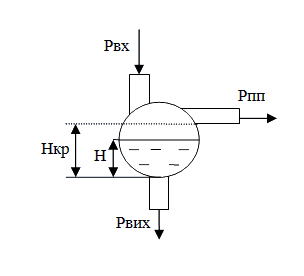
В верхнее отверстие сосуда поступает жидкость с потоком Pвх . Из нижнего отверстия эта жидкость выходит с потоком Pвых. До начала моделирования сосуд уже содержит определенное количество жидкости высотой в H. Если Pвх > Pвых, то уровень воды с течением времени будет возрастать, и когда он достигнет критической высоты Hкр, жидкость начинает вытекать из отверстия переполнения потоком Pпп. Такую модель удобно решать для двух случаев отдельно: когда есть переполнение (H > Hкр), и когда его нет (H < Hкр). При этом, индикатором переключений из одной системы уравнений в другую может служить функция φ: φ = Нкр – Н Если φ < 0 для расчета используется система, когда есть переполнение; Если φ > 0 используется система, когда переполнения нет. Такое поведение может быть представлено сетью петри следующего вида: Моделирование группы моделей клеток (агрегированная модель переменной структуры) должно осуществляться распределенным решателем. В его задания также входят контроль над количеством гибридных моделей, а также обеспечение стабильности работы процесса моделирования на нескольких вычислительных машинах. На данный момент, в моделирующей среде Diana нет действующего решателя гибридных моделей, а значит, данная разработка решателя гибридных моделей и распределенного решателя имеет высокую практическую ценность. Обзор существующих разработокБыл проведен обзор работ магистров прошлых лет, по результатам которого были приняты во внимание работы Бондаревой Е.С. (нет страницы) и Досты М.А. Бондарева Е.С. также занималась разработкой гибридных моделей и решателя гибридных моделей в институте им. Макса Планка г. Магдебурга. Был проанализирован опыт создания решателя гибридной модели ida_petri, основным недостатком которого было признано нарушение модульного похода при создании такого рода решателя. Реализация гибридной модели для данного решателя также имела недостатки, связанные с необходимостью выполнения моделью не свойственных ей функций. По результатам анализа было решено взять существующую модель за основу и внести в нее ряд изменений, а также создать новый решатель гибридных моделей, руководствуясь следующими принципами: 1. Модульный принцип. При создании нового компонента допускается опираться только на стандартизованные интерфейсы существующих компонентов Diana. Запрещено в любой форме привязыватся к внутренней (не стандартизованной) реализации любого модуля 2. Принцип взаимозаменяемости. Поскольку Diana является модульным компонентом, обязательной частью которой являются только ядро моделирующей среды, следует по возможности избегать жесткого привязывания к конкретным компонентам среды, являющихся не обязательными (это касается прежде всего численных методов и решателей), и предоставлять пользователю возможность указать на альтернативный модуль. 3. Принцип разделения функций. Модель по своему определению является пассивным объектом, который не может инициировать действий, в том числе, которые ведут к изменению ее внутреннего представления. Именно по этой причине решатель должен взять на себя функции инициализации расчетов вектора φ и переключение сети петри 4. Принцип абстракции от численных методов. Основным заданием гибридного решателя есть отслеживание моемента смены системы уравнений модели и ее переключение. Решатель не должен знать, каким именно численным методом следует решать заданные системы уравнений, оставляя этот выбор на усмотрение пользователя. То есть, для проведения расчетов он должен опираться только на уже существующие решатели, единственным требованием к которым ставится возможность работы в пошаговом режиме Достой М.А. рассмотрены задачи статической балансировки загрузки процессов на основе представления задач в виде графов, проведена классификация алгоритмов разбиения графов, а также синхронизации процессов и моделирования объектов. Эти разработки могут быть использованы в дальнейшем при разработке распределенного решателя модели переменной структуры. Полученные результатыПоскольку спецификации агрегированной модели переменной структуры еще не существует, разработка распределенного решателя проводилась только на уровне прототипа. Основной целью создания прототипа было определения наиболее оптимальной с точки зрения производительности структуры для решения задач такого рода. Перед проектированием прототипа были проведены ряд экспериментов по сравнению производительности реализаций архитектуры CORBA (на примере omniORB 4.1 [4]) и архитектуре MPI (на примере MPICH2), по результатам которых, предпочтение было отдано технологии CORBA. Условия и результаты тестирования приведены в [1]. Прототип решает выбранный круг задач, однако по упрощенной схеме, а именно обеспечивает: диспетчеризацию запросов на вычисления, выполнение вычислительных задач, поддержку стабильной работы системы, а также дополнительно содержит средства диагностики и измерения производительности работы системы. Структура программного обеспечения приведена ниже: 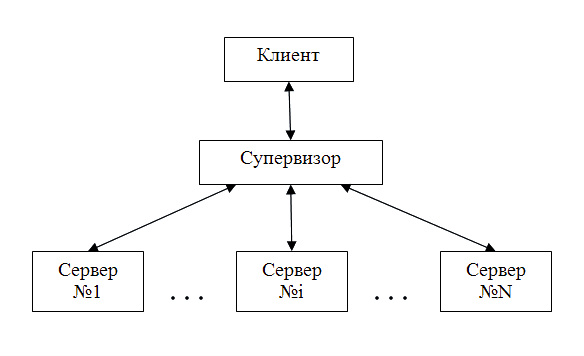
Основой вычислительной системы есть диспетчер задач – так называемы Супервизор. Он принимает заявки на вычисления от клиента и расперделяет эти задачи для исполнения на вычислительных станциях – серверах. Также супервизор в автоматическом режиме следит за стабильностью работы системы. При этом делается предположения, что из строя могут выходить только сервера, ведь нестабильность работы супервизора является критической (неисправимой) неисправностью системы, а возможные неполадки с клиентом – целиком ответственность пользователя, инициировавшего вычислительный процесс. На первый взгляд, присутствие супервизора в качестве посредника при исполнении запросов, а не только как диспетчера, может показаться избыточным. Однако, именно таким образом должна обеспечиватся стабильность работы системы и ее восстановление после отказов, ведь клиентская часть не должна ничего знать о количестве и состоянии серверов. К тому же, если поместить объект супервизора и объект клиента в одном адресном пространстве, такая избыточность существенно не повлияет на производительность системы в целом. В качестве задачи на данный момент осуществляется моделирование 100 часов работы модели Lotka-Volterra (модель «хищник-жертва») с разнообразными начальными условиями. Постановка задачи на моделирование происходит как в синхронном, так и в асинхронном режиме[5]. При этом измеряется время выполнения запросов. Результат работы программы, совмещающей в себе объекты клиента и супервизора, приведены ниже: IOR:010000001d00000049444c3a4261736963586368672f53757065727669736f723a312e30000000 00010000000000000068000000010102000f0000003139322e3136382e33342e31353000001edd0000 0e000000fecb670a4600006dbc00000000000000020000000000000008000000010000000054544101 0000001c00000001000000010001000100000001000105090101000100000009010100 2 Hit ENTER when servers are ready! 3 Server #1 is connected 4 Server #2 is connected 5 Server #3 is connected 6 Server #4 is connected 7 Measuring CPU frequency... 8 Done! (2088.83MHz) 9 Dispatching Job#1 to #1 10 Result[0]: [0]: 0.457116 [1]: 0.658219 in 0.0246823 sec 11 Dispatching Job#2 to #2 12 Result[1]: [0]: 0.511181 [1]: 0.587431 in 0.0234566 sec 13 Dispatching Job#3 to #3 14 Result[2]: [0]: 0.576207 [1]: 0.535499 in 0.0225421 sec 15 Dispatching Job#4 to #4 16 Result[3]: [0]: 0.651776 [1]: 0.498952 in 0.0360794 sec 17 Dispatching Job#5 to #1 18 Result[4]: [0]: 0.737112 [1]: 0.475483 in 0.0176266 sec 19 Dispatching Job#6 to #2 20 Result[5]: [0]: 0.831089 [1]: 0.463494 in 0.0196284 sec 21 Dispatching Job#7 to #3 22 Result[6]: [0]: 0.932033 [1]: 0.46201 in 0.0189825 sec 23 Dispatching Job#8 to #4 24 Result[7]: [0]: 1.03791 [1]: 0.470567 in 0.0231249 sec 25 Total time: 0.186384 sec 26 27 Asynchronus call: 28 Dispatching Job#9 to #1 29 Dispatching Job#10 to #2 30 Dispatching Job#11 to #3 31 Dispatching Job#12 to #4 32 Dispatching Job#13 to #1 33 Dispatching Job#14 to #2 34 Dispatching Job#15 to #3 35 Dispatching Job#16 to #4 36 Result[0]: [0]: 0.457116 [1]: 0.658219 37 Result[1]: [0]: 0.511181 [1]: 0.587431 38 Result[2]: [0]: 0.576207 [1]: 0.535499 39 Result[3]: [0]: 0.651776 [1]: 0.498952 40 Result[5]: [0]: 0.831089 [1]: 0.463494 41 Result[4]: [0]: 0.737112 [1]: 0.475483 42 Result[6]: [0]: 0.932033 [1]: 0.46201 43 Result[7]: [0]: 1.03791 [1]: 0.470567 44 Total time: 0.0724668 sec Диспетчер распределяет работу между четырьмя серверами, которые были подключены в строках 3-6. Далее, в строке 9 выведен результат диспетчеризации первого задания. Его исполнение поручено серверу 1. Результат, получений почти через 0,025 секунд выведен в строке 10. Отчет о выполнении остальных запросов приведен в строках 12-24. Общее время работы приведено в строке 25 и составляет чуть более 0,186 секунд. Начиная со строчки 27, идет отчет о выполнении тех же вычислений в асинхронном режиме. Хоть сам диспетчер и не различает синхронные и асинхронные вызовы, про вызовы диспетчера в асинхронном режиме свидетельствуют непрерывные результаты диспетчеризации запросов в строках 28-35. Только позже поступают результаты вычислений (строки 36-43). При этом порядок поступления результатам в общем случае не имеет строгой зависимости от порядка его диспетчеризации (строки 40-41). В строке 44 присутствует очевидное преимуществ асинхронного режима: время выполнения программы уменьшилось с 0,186 до 0,072 секунд. Направления дальнейшей работыДальнейшая работа планируется в таких направлениях: - Доработка гибридного решателя и проведения серий тестирований для дальнейшего его введения в эксплуатацию - Работа над созданием спецификации агрегированной модели переменной структуры. Определение основных требований и принципов моделирования - В процессе разработки агрегированной модели также планируется проведение дальнейшей работы над прототипом распределенного решателя с целью формулирования и совершенствования спецификации агрегированной модели - Создание распределенного решателя и его интеграция с моделирующей средой Diana Список литературы:1. "ОРГАНІЗАЦІЯ ОБМІНУ НА ГЕТЕРОГЕНИХ КЛАСТЕРАХ: CORBA ЧИ MPI? ПОРІВНЯЛЬНИЙ АНАЛІЗ", Бабенко І, Студентческая научно-техническая конференция "Інформатика та комп’ютерні технології", 2006г 2. Дж. Либерти «С++ Энциклопедия пользователя» 590 стр., ДиаСофт, 2001 3. “Modeling and Simulation Tool Promot/DIVA (DIANA)” by Martin Ginkel, Mykhaylo Krasnyk, 2007, Max-Planck-Gesellschaft, Munchen 4. “The omniORB version 4.1 User's Guide”, Duncan Grisby, Sai-Lai Lo, David Riddoch, 2006 5. “Динамическое взаимодействие клиентов и серверов CORBA”, Александр Цимбал, Технология Клиент-Сервер, 2000 |
||
 |
 |
