Source: http://inside.hlrs.de/htm/Edition_01_06/article_01.htm
The NEC SX-8: A European Flagship for Supercomputing
• Michael M. Resch • Matthias Müller • Peter Lammers
Höchstleistungsrechenzentrum Stuttgart (HLRS)
• Holger Berger • Jörg Stadler
NEC
When in spring 2004 HLRS announced the final decision for its procurement for a supercomputer [1] the time for installation was still about a year away. The system purchased was projected to be the fastest supercomputer in Europe. At the time of announcement this was true both in terms of peak performance and sustained performance. During the last year since the publication of the article a number of things happened. The Spanish government announced the purchase of a cluster based on standard components. The French government agency CEA made a decision for another cluster with a similar architecture. Both of these systems show a larger peak performance. It remains to be seen what the actual level of performance is that can be achieved for the users of these three systems.
In this article we present the installation set up at Stuttgart including the systems that surround the SX-8 in order to create a workbench for supercomputing. First performance figures indicate that the assumptions and promises made during the procurement phase can be fulfilled. The level of performance is very good in general and for many examples even exceeds our expectations.
Introduction
In this article we want to give a description of the new system and present some of the first results that were achieved. At the time of publication of the most recent issue of inSiDE the reader will be able to check at least for further Linpack results at the top 500 webpage [2]. It may, however, be more interesting to look at Jack Dongarra’s new High Performance Computing Challenge Benchmark [3]. The project that Dongarra started aims to complement the traditional linpack benchmark. The 23 individual tests in the HPC Challenge benchmark do not measure the theore¬tical peak performance of a computer. Rather, they provide information on the performance of the computer in real applications. The tests do not measure processor performance but criteria that are decisive for the user such as the rate of transfer of data from the processor to the memory, the speed of communication between two processors in a supercomputer, the response times and data capacity of a network. Since the tests measure various aspects of a system, the results are not stated in the form of one single figure. In their entirety, the measurements enable an assessment of how effectively the system performs high performance computing applications. When the benchmark was run for the predecessor model of the NEC SX-8 – the SX-6 – it took the lead in 13 out of 23 categories showing the high potential that vector supercomputers still have when real performance is at stake.
A Supercomputing Workbench
When the Höchstleistungsrechenzentrum Stuttgart (HLRS) started its request for proposals it was clear from the beginning that the system offered would have to be part of a larger concept of supercomputing called the Stuttgart Teraflop Workbench [4]. The basic concept foresees a central file system where all the data reside during the scientific or industrial workflow. A variety of systems of different performance and architecture are directly connected to the file system. Each of them can be used for special purpose activities. We distinguish between systems for pre-processing, simulation and post-processing (see figure 1).
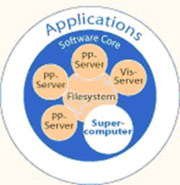
Figure 1: The Stuttgart Teraflop Workbench Concept
As described in a previous contribution here [1] the decision was made to go with NEC as the key partner to build the workbench. The schematic configuration is briefly shown in figure 2.

Figure 2:
Technical description of the workbench concept as implemented by NEC
The concept is centred around the global file system of NEC. SX-8, Asama (IA64 shared memory system) and a cluster of Intel Nocona processors all have direct access to the same data via fibre channel. In the following we briefly describe these main three systems with a focus on the SX-8.
The SX-8 System
The SX-8 series was announced by NEC in autumn 2004 as the next step of the SX series that had been extremely successful in Japanese and European supercomputing over the last 10 years. The SX-4 had repeatedly replaced Cray vector systems in the mid 90s. The SX-5 was seen to be the leading system in vector supercomputing in the late 90s. The SX-6 was the basis for the Earth Simulator – a system that dominated the top 500 list for nearly three years.
The SX-8 continues this successful line by improving the concepts and making use of most recent production technology. The key improvements are:
CPU
The CPU is manufactured in 90nm technology. It uses copper wiring and the vector pipes operate at 2GHz. The CPU LSI is connected via high density I/O pads to the node circuit board. Advanced technology is used for the signal transmission.
The vector unit is the most important part of the SX-8 CPU. It consists of a set of vector registers and arithmetic execution pipes for addition, multiplication, division and square root. The hardware square root vector pipe is the latest addition to the SX-8 CPU architecture and is only available on the SX-8. Each of the arithmetic pipes is four way parallel, i.e. can produce four results per cycle. A high speed load/store pipe connects the vector unit to the main memory.
The traditional vector performance of a single CPU is 16 GFLOP/s. Together with the new square root vector pipe and the scalar unit the total peak performance adds up to 22 GFLOP/s.

Figure 3:
Schematic view of an SX-8 CPU
Node & Interconnect
Each node of the SX-8 is an 8-way shared memory system. The outstanding feature of the node is the extremely high memory bandwidth of 64 GB/s for each processor or a total of 512 GB/s for the overall node. Given the vector performance of 16 GF/s this results in a peak memory transfer rate of 4 Byte for every flop that the processor performs. With these numbers the SX-8 outperforms all its competitors in the field by a factor of about 3 with only the Cray vector systems being able to compete.
The IXS interconnect is a 128x128 crossbar switch. Each individual link has a peak bidirectional bandwidth of 16GB/s. Again this outperforms competing networks – especially in the cluster field. However, it has to be mentioned that 8processors share the bandwidth. Still the system has an acceptable communication balance – which is also reflected by first linpack results shown below.

Figure 4:
Schematic view of an SX-8 node
Software
The SX-8 operating system “SUPER-UX” is based on UNIX System V industry standard:
Preprocessing/Postprocessing
Two hardware systems complement the SX-8 installation. One is an IA64 based shared memory system that serves for pre-processing and file serving. Code named AsAmA it consists of 2 TX-7 nodes with 32 processors each. One of the nodes is equipped with 512 GB of memory in order to allow preparation of large parallel jobs. We found that still most users prepare their mesh on one processor before they decompose it and transfer it to the parallel system. Given that the main memory of the core system is 9 TB we decided for one node with large memory to be able to prepare large jobs.
A cluster based on Intel EM64T processors and Infiniband technology is added to the workbench. It serves both for post-processing/visualization and as a compute server for multi-disciplinary applications. The later often require different types of architectures for different types of disciplines. The 200 node cluster is connected by a Voltaire Infiniband switch with a bandwidth of 10 GB/s.
Summary of HLRS Installation
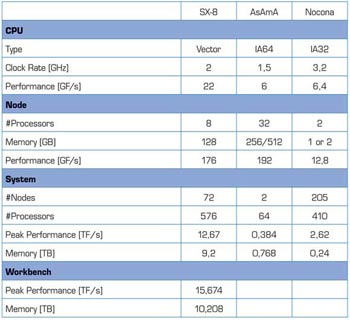
Table 1: Basic installation and performance parameters
Installation Schedule
The system is set up in the newly built computer room of the Höchstleistungsrechenzentrum Stuttgart (HLRS). While construction work for the office part of the building was still under way the computer room was finished and the set up of the system began in December 2004. The first 36 nodes were rolled in at the end of January and were set up within three weeks. NEC did intensive testing before handing over the first 36 nodes to the Höchstleistungsrechenzentrum Stuttgart (HLRS) in March. The Intel EM64T cluster was set up within a few days in January together with the first AsAmA front end node.
The second 36 nodes were brought in late in March to be set up during April. The final installation of the overall system was scheduled after the deadline of this contribution. Acceptance will take about one month such that the full system could be operational by June/July 2005.
Installation and First Results
Linpack
One of the first applications to run on any new system is the linpack benchmark that defines the ranking of any system in the top 500 list. As soon as the system was installed linpack results were measured for 72 nodes. The theoretical peak performance of the 72 nodes with their 576 processors is 9,2 TFLOP/s. Average microprocessor systems and clusters usually exhibit a level of performance of 50% -70% for the linpack benchmark. The Earth Simulator had shown 87,5% of its peak performance in the linpack benchmark. Our expectation was hence to achieve about 95% of peak performance in a linpack run on 72 nodes. The results were much better as can be seen in figure [4]. With 72 nodes (576 processors) the SX-8 achieves a sustained linpack performance of about 8,92 TF/s which is about 97% of the peak performance.
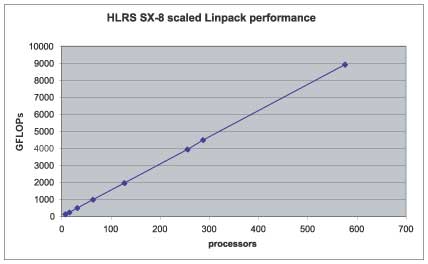
Figure 5: Linpack performance on 72 nodes (576 processors) of the SX-8
Computational Fluid Dynamics
First benchmarks were done on the system shortly after the 36 nodes were set up. The benchmark run was a Lattice-Boltzmann code called BEST and the measurements were done by Peter Lammers from the Höchstleistungsrechenzentrum Stuttgart (HLRS). First results are shown in the figure below.
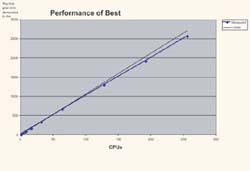
Figure 6:
Performance measurements for the Lattice-Boltzmann code BEST
The figure shows not only excellent speedup – owed to the high performance IXS switch – but also demonstrates that up to 256 processors we see an extremely high efficiency for the single processor. We achieve 13 GF/s for one processor and about 11 GF/s per processor for the 256 processor case.
The key finding here is that the system already now exceeds our expectations by far. Our hope – and part of the contract – was that for a single application we could achieve about 4 TF/s of sustained performance. The figures show that today with 288 processors we already achieve about 2,9 TF/s. The sustained performance for the full 576 processor system is expected to be at about 5 TF/s.
Considering that this is not an application kernel but a real CFD simulation case the result confirms our decision for a vector based system.
Who are the Users?
As all systems that are run by the Höchstleistungsrechenzentrum Stuttgart (HLRS) the new SX-8 vector system and the attached cluster of Intel Nocona processors is made available to a large group of users both from industry and research. Every scientist in Germany doing public research in an organization that is not directly funded by the federal government can apply for compute time on the system. A scientific steering committee continuously evaluates proposal and grants access to the system solely based on scientific merit of the proposal and on the proven necessity to use a supercomputer system. Access for European users is possible through special research projects.
The Teraflop Workbench Initiative
In order to further support users and projects and in order to extend the reach of vector systems in terms of application fields Höchstleistungsrechenzentrum Stuttgart (HLRS) and NEC set up the Teraflop Workbench Initiative [5].
The first goal is to demonstrate the efficiency of NEC SX vector systems and that these systems can deliver Teraflop/s application performance for a broad range of research and ISV codes. Secondly, NEC Linux clusters and SMP systems will form together with the SX vector system an environment that allows to perform the complete pre-processing – simulation – post-processing – visualization workflow in an integrated and efficient way.
To show the application performance NEC and HLRS work together in selected projects with scientific and industrial developers and end users. Their codes come from areas like computational fluid dynamics, bioinformatics, structural mechanics, chemistry, physics, combustion, medical applications and nanotechnology. The Teraflop Workbench is open to new participants. An application has to demonstrate scientific merit as well as suitability and demand for Teraflop performance in order to qualify.
Industrial Usage
The whole workbench is made available for industrial usage through the public private partnership hww (High Performance Computing for Science and Industry) – a company that was set up together with T-Systems and Porsche in 1995. The systems are integrated into the security concepts of hww and are operated jointly by Höchstleistungsrechenzentrum Stuttgart (HLRS) and T-Systems.
Accounting and billing is done on a full cost model which includes investment, maintenance, software, electricity, cooling, operation staff, insurance, and overhead costs for running the public private partnership. Through T-Systems the systems are open to German Aerospace Research Centre DLR, to DaimlerChrysler and to small and medium sized enterprises.
Summary
With the new SX-8 system installed at the Höchstleistungsrechenzentrum Stuttgart (HLRS) German users have access to the best performing system in Europe which can compete with the leading installations in the world. Applications that have been optimized for leading edge processors will greatly benefit from the architecture. This will include codes that are cache optimized as first tests show. New applications will be brought to supercomputing through the Teraflop Workbench initiative which will guarantee that the full portfolio of scientific fields will turn the new system into a real scientific and industrial teraflop workbench.
The integration of various architectures into a single system turns the overall system into an excellent tool to be used in the scientific and industrial work flow and production processes. This increases the chance to open supercomputing for new scientific communities and industrial application fields.

Literature
[1] Michael M. Resch
“The next generation supercomputer at HLRS”, inSiDE, Vol. 2, No. 1, 2004
[2] TOP500
http://www.top500.org/
[3] HPCC Benchmark
icl.cs.utk.edu/hpcc/index.html
[4] Michael M. Resch, Uwe Küster, Matthias Müller, Ulrich Lang
A Workbench for Teraflop Supercomputing, SNA’03, Paris, France, September 22-24, 2003
[5] Stuttgart Teraflop Workbench Initiative
http://www.teraflop-workbench.de/
• Michael M. Resch
• Matthias Müller
• Peter Lammers
Höchstleistungsrechenzentrum Stuttgart (HLRS)
• Holger Berger
• Jörg Stadler
NEC