Speech Signal Compression using Neural Network Technologies
Izjumov V.V.
Introduction
In sphere of telecommunications always was a question: on how to provide communication as a lot of subscribers is possible, on as it's possible for smaller quantity of channels. For the decision of this question scientific communities put huge quantity of money in development of a compression of speech signals that leads to reduction in information capacity of speech messages transferred on liaison channels and reduction in price of services of a communication facility. Except it, the compression of speech signals is demanded and in military area and other department for maintenance of the classified information.
As it's necessary to pay attention to fast growth of computer network. At improvement quality of vocoder speech, at speeds less that 4 Kbit/s to become possible the communications on computer networks.
Development of new methods of low high-speed compression makes possible creation of new appositions [1]:
- speech paging;
- automatic speech help service;
- military apposition;
- Internet speech communication.
Modern achievements in the field of creation of high-efficiency computing elements, such as microcontrollers of digital processing of signal allow to improve begound all bounds practically methods and algorithms of digital processing of a speech signal.
An Abstract
As is know the speech signal possesses the big redundancy for maintenance of a good noise stability in various conditions of environment. At transition to digital method of processing of speech signals and data transmission on digital liaison channels it is possible, due to redundancy of a speech signal, to lower volume of the transmitted information. That conducts to depreciation of liaison channels and increase of their throughput.
At present there are some approaches to a compression of a speech signal:
- coding the form of signal;
- coding parameters of a source of signal (a speech path and a source of excitation);
- coding elements of speech (phonemes);
- coding linguistic elements (word, phrases).
Coding of the form of signal allows to reach a compression of a speech signal with comprehensible quality, at to 24 Kbit/s. The given compression is reached due to application of adaptive differential pulse code modulation (standard G.271 or G.279).
Coding of parameters of source of a signal is carried out by calculation of the parameters describing transfer function of a speech path of the person. For example, such parameters are coefficients of a linear prediction (model of autoregress). In the given category of coding of parameters of a source of a signal will reach a limit in 2400 bits per second (standard FS1015)
Coding of elements of speech and coding of linguistic elements at present is extensive and completely not investigated category of methods of a compression of speech. The given coding is carried out by methods of recognition and synthesis of speech. Often coding occurs by means of hidden Markov models (HMM) and neural network. Unfortunately, the give kind of coding yet doesn't possess sufficient accuracy and stability for introduction in telecommunication services.
The Received and Expected Results.
At present considers a question of speech coding signal in a stream of phonemes by its recognition. The basic methods of recognition of phonemes such as HMM, neural networks and their combinations are considered. The given method I demand preliminary transformation of a speech signal with the purpose of reception of a vector of properties of time of a signal speech describing the given moments. Elements of a vector are made of coefficient of transformation such as, Fourier transformation, Wavelet transformation or coefficient of a linear prediction. Lack of the given technique that the kind and quantity of factors of transformation are set in advance and can bear the produplicated or unnecessary information about speech a signal.On the basis of work [2] is found the property of neuron to find correlation between a signal and weight function. On the basis of the give property the following structure of system of recognition of phonemes in a speech signal has been offered
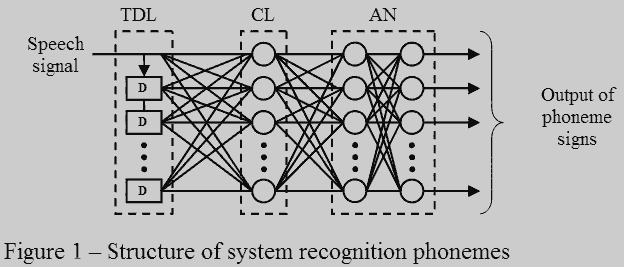
The entrance signal of speech acts on am input of a time-delay line (TDL), which forms an entrance vector of the neural network representing a piece of a signal entering in analyzing staff. From a line of a delay the signal acts on a correlation layer (CL) of neurons depends on that, how many it is necessary to generate correlates. From a correlation layer the signal acts on an input analyzing network (AN) consisting of 2 layers of neurons. In the second layer of an analyzing network every neuron corresponds to an attribute of a separate phoneme. Output of an analyzing layer are signal, which showing what phoneme at present probably is in an entrance signal. The given system possesses that advantage, that at it's training in a correlation layer the group of correlators a speech signal will be formed, that's the entrance vector of neural network with necessary properties describing a speech signal is automatically formed. The quantity of properties depends on quantity of neurons, entering in the given layer. In analyzing layer the method of the analysis of data correlators and their comparison to attributes of phonemes will be formed. It would be desirable to notice, that in an operating conditions speeds of work of the given system will not exceed speed of work of system with the analyzer on the basis of Fourier transformation or wavelet transformation. At present system of recognition of phonemes is in stage of development and experimentation, In the further it is planned to develop a technique of training of the given network, and also to develop a technique of quality assurance of work of the given system. The ending of work and reception of result is planned to the beginning of 2008.
Bibliography
- Ăŕëóíîâ Â.Č., Âčęňîđîâ Ŕ.Á. Ŕíŕëčňč÷ĺńęčé îáçîđ ďî ďđîáëĺěĺ ęîäčđîâŕíč˙ đĺ÷ĺâűő ńčăíŕëîâ. - www.auditech.ru
- Čçţěîâ Â.Â. Đŕńďîçíŕâŕíčĺ đĺ÷č íŕ îńíîâĺ čńęóńńňâĺííîé íĺéđîííîé ńĺňč ń ďđ˙ěîé ďîäŕ÷ĺé đĺ÷îâîăî ńčăíŕëŕ.
