
Чумак Дмитрий Юрьевич
Факультет: Вычислительной техники и информатики
Специальность: Программное обеспечение автоматизированных систем
Тема выпускной работы:
Исследование распределенных баз данных на кластерной вычислительной сети
Руководитель: Ладыженский Юрий Валентинович
Автореферат*
ВВЕДЕНИЕ
Вычислительные системы, существовавшие до появления систем с базами данных оперировали собственными наборами данных, что делало совместную работу таких систем сложной из-за необходимости синхронизации данных. Системы с базами данных позволили хранить данные централизовано, позволяя многим приложениям получать совместный доступ к одним и тем же данным, хранящимся в базе. С ростом объемов хранимых данных возникла проблема размещения больших объемов данных. В современных условиях базы и хранилища данных уровня предприятия не могут храниться не только на одном жестком диске, о и на одном файловом сервере с множеством дисков. В связи с этим данные одной и той же базы данных стали размещаться на различных узлах, соединенных через локальную сеть или интернет. Таким образом для крупных систем характерен обратный переход к децентрализованной обработке данных [1]. Децентрализованные данные должны отражать организационную структуру предприятия, состоящего из нескольких подразделений, оперирующих собственными наборами данных. Хранение данных нескольких подразделений предприятия в одной распределенной базе данных, позволяет, во-первых, сделать их общедоступными, а во-вторых, обеспечить их размещение в местах наиболее интенсивного использования, что повышает эффективность использования информации.
С помощью распределенных баз данных появляется возможность решить проблему так называемых «информационных островов» [1], которые представляют собой несколько баз данных, разобщенных географически или посредством несовместимой аппаратуры и требующих совместной обработки. С помощью технологии распределения возможна интеграция разобщенных баз данных в одну распределенную базу данных.
Цели работы: исследование модели распределенной базы данных как системы массового обслуживания, нахождение оптимальных характеристик кластера баз данных.
Исследование распределенных баз данных в рамках магистерской работы подразумевает решение следующих задач:
1. Представление системы обработки транзакций (СУБД) как системы с очередями.
2. Моделирование системы обработки транзакций как разомкнутой СМО типа M|M|S [2].
3. Нахождение основных характеристик системы обработки транзакций, таких, как средняя длина очереди, среднее время ожидания обслуживания, среднее время пребывания в системе, вероятность того, что транзакция будет ожидать.
4. Получение зависимостей между основными характеристиками системы обработки транзакций.
ОБЗОР СУЩЕСТВУЮЩИХ РАБОТ
Среди существующих работ в первую очередь нужно выделить исследования магистров ДонНТУ.
В магистерской работе Афонова И. В. показан пример пошаговой разработки аналитической модели производительности 2rc, которая содержит в себе двумерную модель репликации. Модель 2rc учитывает взаимодействие между репликацией и коммуникационной частью системы и представляет сбалансированную модель и базы даннях, и коммуникативной части реплицированной системы баз даннях. В модели учитывается качество выбора схемы репликации — качество выбора даннях для репликации и выбора узлов для размещения копий данных. Результаты расчетов показывают, как параметры схемы частичной 2D репликации влияют на время отклика, пропускную способность и масштабируемость системы.
В магистерской работе Ильенко О. В. рассмотрено применение технологии J2EE для исследования эффективности распределенной системы с базами данных.
В магистерской работе Шегаль Е. И. рассмотрена проблема передачи ответов на большие запросы-обьединения с сервера на клиент. Суть проблемы заключается в избыточности передаваемых данных. Основная цель исследований — минимизация стоимости передачи результатов запросов. Решением данной проблемы является декомпозиция запросов на промежуточные виды. В основе метода декомпозиции лежит разбиение больших запросов на подзапросы. Ответы на подзапросы передаются клиенту и клиент по ним формирует ответ на исходный запрос.
ПРЕДСТАВЛЕНИЕ СИСТЕМЫ ОБРАБОТКИ ТРАНЗАКЦИЙ (СУБД) КАК СИСТЕМЫ С ОЧЕРЕДЯМИ
На рисунке 1 показан путь, который проходят транзакции в сервере баз данных [2].
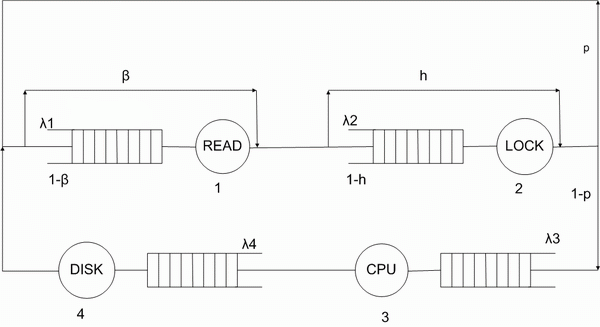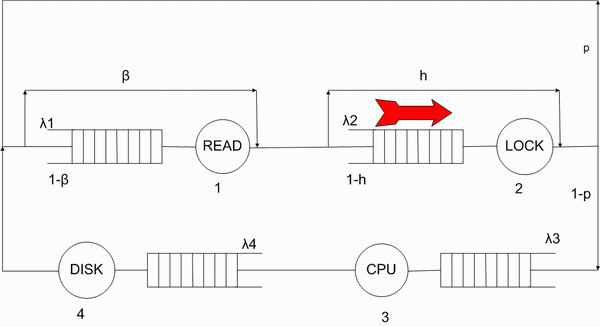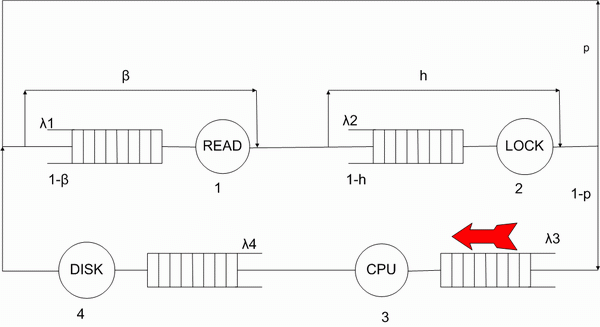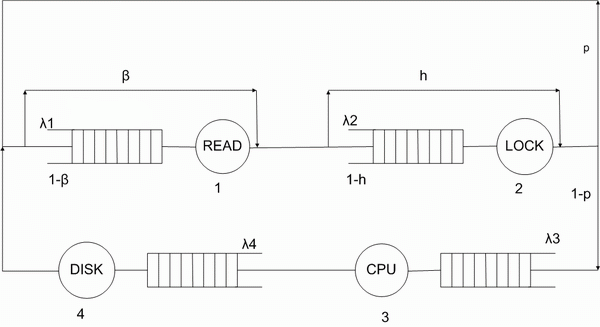
Рисунок 1 - Путь, который проходят транзакции в сервере баз данных. Количество циклов - 8. Для возобновления анимации, обновите страницу.
1. Транзакция читает данные из базы данных.
2. Транзакция может обнаружить, что некоторые данные заблокированы. Это означает, что ей придется ждать освобождения всех блокировок. Время обслуживания будет зависеть от общего времени обслуживания системы.
3. Транзакция может прочитать больше данных или выполнит некоторые вычисления на CPU с вероятностью p или 1-p соответственно.
4. После вычислений на CPU транзакции требуется записать данные на диск.
Вероятность p определяет количество блокировок, запрашиваемых каждой транзакцией в среднем:
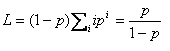
Все станции обслуживания имеют фиксированную частоту обслуживания, которая не зависит от длины очереди. Частота обслуживания для Lock-сервера определяется итеративно. На первом шаге время обслуживания устанавливается в ноль. На следующих шагах оно будет пропорционально общему времени отклика на предыдущем шаге. Вероятность h определяет вероятность не встретить блокировку. Если блокировки нет, то процесс выполняется без задержки. Если есть конфликт, то процессу приходится ждать окончания блокировки. Таким образом,
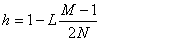
Здесь N — это среднее количество блокируемых элементов, а M — общее количество блокируемых элементов.
Частота поступления заявок должна удовлетворять переходным уравнениям 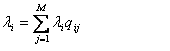 , где , где 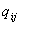 - это вероятность для заявки пройти из станции обслуживания i к станции обслуживания j по окончанию обслуживания в центре i. Полный набор уравнений выглядит так: - это вероятность для заявки пройти из станции обслуживания i к станции обслуживания j по окончанию обслуживания в центре i. Полный набор уравнений выглядит так:
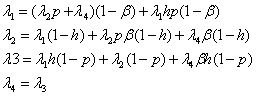
Решив систему уравнений, можно найти частоту поступления заявок в систему, а затем остальные характеристики модели.
ЗАКЛЮЧЕНИЕ
Современные системы управления базами данных получают ежесекундно несколько тысяч запросов на обработку данных. Представление системы обработки транзакций как системы массового обслуживания позволяет промоделировать поведение существующих СУБД в реальных условиях. Нахождение основных характеристик системы обработки транзакций и получение зависимостей между ними позволит оценить нагрузку на аппаратное обеспечение вычислительных систем с базами данных, вычислить оптимальные режимы функционирования систем обработки транзакций, дать практические рекомендации для сокращения времени ожидания транзакций, осуществить балансировку нагрузки между экземплярами кластерной СУБД, сделать выводы об эффективности размещения распределенных данных.
*Примечание: данная версия магистерской работы не является окончательной, полную версию работы можно будет получить у автора после ее защиты в декабре 2008 г.
ЛИТЕРАТУРА
1. Коннолли Томас, Бегг Каролин. Базы данных. Проектирование, реализация и сопровождение. Теория и практика. 3-е издание. : Пер. с англ. — М. : Издательский дом «Вильямс», 2003. — 1440 с. : ил.
2. Harder Uli, Harrison Peter. A queueing network model of Oracle Parallel Server. 2003.
3. Д. Крёнке. Теория и практика построения баз данных. 8 изд. - СПб.: Питер, 2003. 800 с.:ил.
4. Vincent Rainardi. Building a Data Warehouse: With Examples in SQL Server.
5. Ray Rankins, Paul Bertucci, Chris Gallelli, Alex T. Silverstein. Microsoft® SQL Server 2005 Unleashed.
|
