
Chumak Dmitry
Faculty: Computer Science and Informatics
Speciality: Software Engineering
Thesis:
Research of distributed databases over cluster compute network
Supervisor: Ladyzhensky Yuri
Abstract*
INTRODUCTION
The compute systems which existed before the database systems appearance operated their own data sets, and this made cooperation of such systems difficult because of data synchronization necessity. Database systems allowed to store data centrally and granted many applications shared access to the same data in a database. As the amount of stored data grew the data allocation problem appeared. Nowadays enterprise databases and data warehouses can be stored neither on a single hard drive nor on a single file server with a lot of hard drives, so data of the same database became to be allocated on the different nodes connected over LAN or Internet. Thus, return to decentralized data processing is typical for large systems [1]. Decentralized data should reflect an organizational structure of an enterprise which consists of several subdivisions operating own data sets. Storing data of several subdivisions in a single distributed database allows to make data public and ensures data allocation in the palaces of its most intensive usage
With the help of distributed databases an opportunity to solve the problem of “informational islands” [1] appears. “Informational islands” correspond to be several databases separated geographically or by incompatible hardware. With the help of distribution technology integration of separated databases into one distributed database is possible.
The objectives of the work: research of distributed database model as a queueing system, finding optimal characteristics of a database cluster.
Distributed databases research implies to find the solution of the following problems:
1. To introduce a transaction processing system (DBMS) as a queueing system.
2. To simulate the transaction processing system as an open queueing system.
3. To find a characteristics of the transaction processing system.
4. To find the dependency between the characteristics of the transaction processing system.
RELATED WORK
In the thesis of Afonov I. V. an example of step-by-step development of analytical performance model 2rc is shown, which includes two-dimensional replication model [2].
In the thesis of Ilyenko O. V. an application of the J2EE technology for the research of a distributed database system efficiency is examined.
In the thesis of Shegal E. I. the problem of sending replies to large union queries from a server to a client is examined.
INTRODUCTION OF A DBMS AS A QUEUEING SYSTEM
Picture 1 shows the path a transaction goes through in a database server.
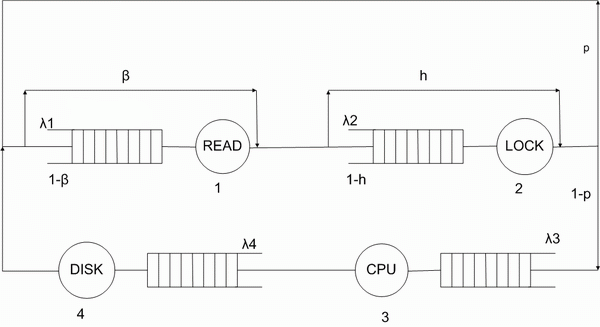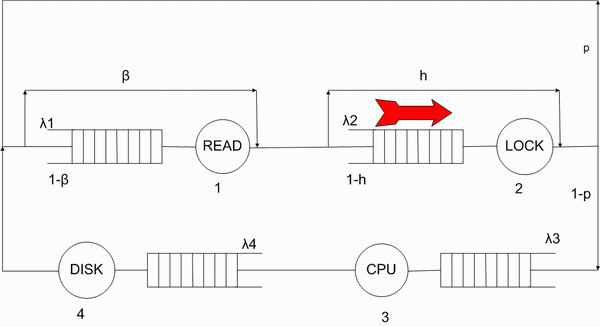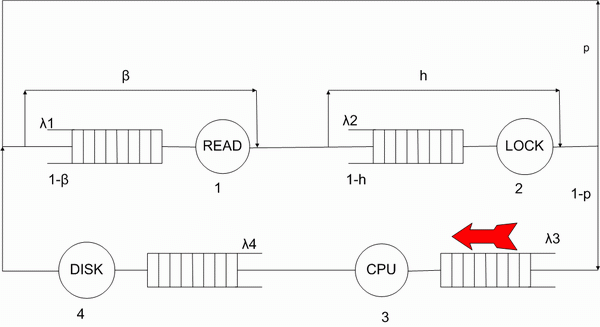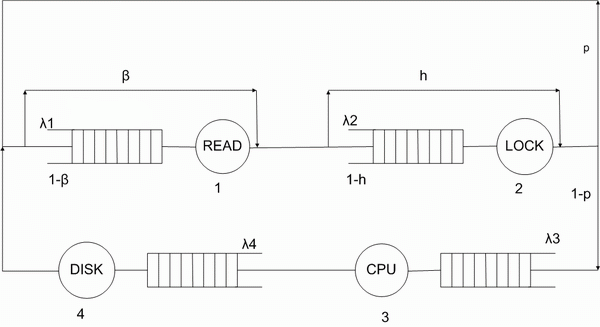
Picture 1 - The path a transaction goes through in a database server. Number of loops - 8. Refresh the page to start the animation.
1. A transaction reads data from the database.
2. The transaction can discover that some data is locked and it will wait until data is released.
3. The transaction can read more data or perform some calculations on the CPU.
4. The transaction writes data on the disk.
The probability p defines the number of transactions acquired by each transaction:
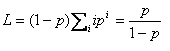
All the service stations have fixed service rate which is not queue-length dependent. Probability h defines probability not to find the lock conflict. Thus,
Here N is the average of lockable items; M is the total number of lockable items.
The arrival rates should satisfy traffic equations 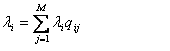 The full set of equations:
The full set of equations:
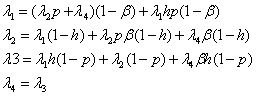
Having solved the set of equations, it is possible to find the transactions arrival rate and other characteristics of the system.
CONCLUSION
Modern database management systems receive thousands of queries per second. Introduction of a DBMS as a queueing system allows simulate a behavior of existing DBMS. Finding the characteristics of a transaction processing systems and finding dependencies between them allows estimate the load on the hardware and calculate optimal modes of DBMS.
* This thesis is not finished. The full version of the thesis will be available in december 2008.
REFERENCES
1. Thomas Connolly, Carolyn Begg. Database Systems: A Practical Approach to Design, Implementation and Management.
2. Harder Uli, Harrison Peter. A queueing network model of Oracle Parallel Server. 2003.
3. David Kroenke. Database Processing.
4. Vincent Rainardi. Building a Data Warehouse: With Examples in SQL Server.
5. Ray Rankins, Paul Bertucci, Chris Gallelli, Alex T. Silverstein. Microsoft® SQL Server 2005 Unleashed.
|
