Андрианова Ольга Сергеевна
Факультет: вычислительной техники и информатикиКафедра: компьютерных систем мониторинга
Специальность: компьютерный эколого-экономический мониторинг
Тема магистерской диссертации:
"Скрытая передача больших массивов информации путем стегокодирования WAV-файлов"
Научный руководитель: Губенко Наталья Евгеньевна, доцент, к.т.н.
В.М. Федоров, П.Ю., Юрков
Россия, г. Таганрог, Технологический институт ЮФУ
СЕГМЕНТАЦИЯ СИГНАЛОВ НА ОСНОВЕ ДИСКРЕТНОГО
ВЕЙВЛЕТ-ПРЕОБРАЗОВАНИЯ
Аннотация
Для сегментации сигналов, в частности речевых, на квазистационарные участки использовалась величина ошибки между исходным сигналом и аппроксимацией сигнала при декомпозиции/синтезе с использованием дискретного вейвлет-преобразования. Статистический анализ результатов сегментации выполнялся на базе речевых данных для 10 человек и 36 фонем, размеченных вручную опытным лингвистом. Точность разработанного метода сегментации составила 91% независимо от типа фонемы. Основным достоинством предложенного метода является высокая точность определения границ сегментов фонем, а также простота алгоритма сегментирования.
Введение
Одной из важных задач обработки и распознавания сигналов, таких как битовые последовательности, речевые сигналы. является сегментация на участки.
Такая задача возникает при стегоанализе мультимедийных контейнеров, содержащих скрытые данные, а также сегментация речевого сигнала на фонемы в соответствии с фонетической транскрипцией языка. На сегодняшний момент при решении задачи сегментации речевого сигнала имеется два подхода к решению: разделение на фиксированные участки с последующим распознаванием их принадлежности к определенным фонемам и определение границ между фонемами с последующим распознаванием выделенной фонемы. В современных системах распознавания речи преобладает первый подход ввиду отсутствия надежных алгоритмов сегментации границ между фонемами.
Рассмотрим подробнее проблему сегментации речевого сигнала. Как отмечено в [1], точность сегментации в значительной степени определяет надежность работы системы автоматического распознавания речи. Кроме того, сегментация повышает точность аутентификации/идентификации пользователя по голосу за счет определения типа сегмента – гласный, назальный, фрикативный или смычка, что определяет методы решения обратной задачи относительно формы речевого тракта данного пользователя.
Известны два вида алгоритмов сегментации речевого сигнала: сегментация при условии, что известна последовательность фонем данной фразы [2,3], другой вид алгоритмов не использует априорной информации о фразе, и при этом границы сегментов определяются по степени изменения акустических характеристик сигнала [4]. Иногда выделяют в отдельный вид алгоритмы, которые принимают решение как на основе априорной информации, так и на основе изменения акустических характеристик.
Рассмотрим некоторые существующие алгоритмы сегментации речевого сигнала. Алгоритмы, основанные на статических характеристиках сегмента, так в [5] сегмент фрикативных звуков распознавался путем определения частоты центра тяжести спектра, длительности глухого участка и степени изрезанности сглаженного спектра, вычисляемой как отношение максимальной производной по частоте на средней трети фрикативного к максимальной энергии на всем звукосочетании. Анализ статических характеристик сегмента, например путем усреднения его спектра, далеко не всегда приводит к точной сегментации. Поэтому значительное внимание уделяется динамическим свойствам речевого сигнала. Простейший вариант использования динамики состоит в оценке различия амплитудного спектра в соседних кадрах. Предлагается также использовать и фазовые различия в разных частотных областях.
В работах [1,6] использован алгоритм с сочетанием динамических и статических характеристик сигнала, в результате показано, что использование динамических и статических свойств позволяет эффективно производить анализ речевого сигнала.
Дискретное вейвлет-преобразование речевого сигнала
Из литературных источников следует [1, 6], что речевой сигнал состоит из квазистационарных участков, которые соответствуют вокализованным и шипящим фонемам, и участков с достаточно быстрыми изменениями в спектре сигнала (межфонемные переходы, взрывные и смычные фонемы, внутрисловные переходы, речь-пауза). В пределах стационарных участков значительную роль для анализа речи играют спектральные особенности сигнала, определяемые передаточной характеристикой речевого тракта, изменяющейся в процессе артикуляции.
Рассмотрим несколько иной алгоритм сегментации, основанный на предположении, что в момент перехода от одного фонетического элемента речевого сигнала к другому появляется невязка параметров сигнала, приводящая к их изменению. Фиксация такого изменения может осуществляться различными методами, например, с использованием как линейного, так и нелинейного предсказания параметров речевого сигнала, а также их корреляция. Авторами были рассмотрены несколько вариантов такого анализа, которые приводили к значительным ошибкам в точности определения границ фонетических элементов, пропускам границ и ложным срабатываниям. Самым сложным моментом является выбор метода принятия решения, в соответствии с которым определяется граница между фонетическими элементами.
Рассмотрим возможность сегментации сигнала, основанную на анализе ошибок, возникающих при аппроксимации сигнала, которую будем осуществлять с помощью дискретного вейвлет-преобразования.
При аппроксимации сигнал можно представить в виде совокупности последовательных приближений грубой (аппроксимирующей) сm(t) и уточненной (детализирующей) dm(t) составляющих с последующим их уточнением итерационным методом. Каждый шаг уточнения соответствует определенному масштабу am (т.е. уровню m) анализа (декомпозиции) и синтеза (реконструкции) сигнала. Полученное таким образом представление каждой из составляющих сигнала можно рассматривать как во временной, так и в частотной областях.
Согласно концепции
кратномасштабного анализа [7], сигнал
S(t) декомпозируется на две функции ![]()
![]() ,
,
где
![]() –
аппроксимирующая и детализирующая функции соответственно.
–
аппроксимирующая и детализирующая функции соответственно.
Таким образом, образуются
две новые последовательности ![]() и
и ![]()
С учетом того, что масштабирующая функция образует базис соответствующего пространства, можно получить
![]()
![]()
![]()
получив, таким образом, полностью дискретный процесс декомпозиции. Последовательности h и g называются фильтрами. Отметим, что c и d имеют «половинную» длину по сравнению с h (хотя, конечно, на данном этапе все последовательности бесконечны).
Обратный процесс
заключается в получении g из c и d
Длина последовательности h вдвое
больше длины последовательности c или d. Для декомпозиции сигнала в
данной работе было использовано быстрое вейвлет-преобразование, называемое также
алгоритмом Маллата. Оно реализует основанный на фильтрации итерационный
алгоритм. Описание алгоритма Для сегментации речевого
сигнала была проведена декомпозиция сигнала с помощью алгоритма Маллата, с
последующим восстановлением сигнала. Использовалось 10 уровневое разложение
сигнала на основе вейвлетов Симлета 6 порядка. Вычислялась ошибка между
восстановленным
Далее проводилась
фильтрация полученных значений ошибки фильтром нижних частот с частотой среза
равным 0. 025fd, где fd – частота дискретизации речевого сигнала. На рис.1
приведено отфильтрованное значение ошибки для слова «авангард».
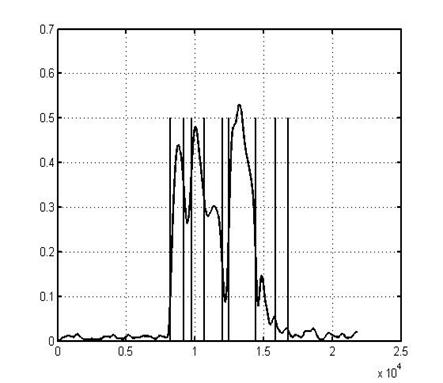
Рисунок 1 - Значение величины
ошибки аппроксимированного речевого сигнала для слова «авангард». Вертикальные линии – ручное
разбиение речевого сигнала на фонемы Вертикальными линиями
нанесены границы фонем данного слова, полученные при ручной сегментации. Как видно из рисунка, на
участках речевого сигнала соответствующих фонемам, ошибка аппроксимации
меняется слабо, при переходе от фонемы к фонеме наблюдается резкое изменение
значений ошибки. Для определения границы был разработан алгоритм, определяющий
середину участка перехода между фонемами. На рис. 2 показана
зависимость скорости изменения ошибки при переходе от одной фонемы к другой.
Предполагалось, что максимальное значение скорости изменения ошибки
соответствует значению границ между фонемами.
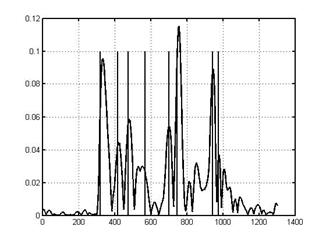
Рисунок 2 - Зависимость
скорости изменения ошибки. Вертикальными линиями
нанесены границы между фонемами Вычисление границ
межфонемного перехода определяется по центрам пиков скорости изменения ошибки с
оптимальной квадратичной интерполяцией. Причем, пик исключается, если имеется
более высокий пик в пределах допустимой ширины пика, задаваемой из анализа
экспериментальных данных. Поиск пиков, определяющих
межфонемные переходы, осуществляется по порогу, задаваемому условием
На рис. 3 приведен речевой
сигнал слова «авангард» с нанесенными границами фонем (вертикальные линии),
определенными описанным методом.
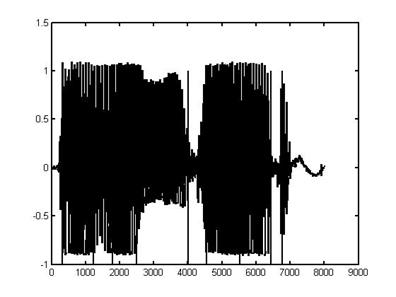
Рисунок 3 - Речевой сигнал
слова «авангард». Вертикальные линии –
границы фонем Как видно из рисунка,
имеется одно лишнее выделение сегмента фонемы гласного «а» между фонемами «г» и
«р». Для исследования алгоритма
было использовано 280 слов, произнесенных 10 разными дикторами. Все слова были
размечены на фонетические сегменты опытным лингвистом вручную. Алфавит разметки
состоял из 36 фонем. Параметры записи речевого сигнала: 110025Гц, 16 бит. На
имеющейся базе данных точность алгоритма сегментации составила 85%. При этом
было найдено на 9% больше границ, чем отмечено при ручной разметке, а число
пропущенных границ составило 6%. В 75% случаев отличие от ручной разметки было
менее 15 мс. Основную часть пропущенных границ составляли слабовыраженные
переходы либо переходы между короткими сегментами. Таким образом, предложенный
алгоритм автоматической сегментации демонстрирует достаточно близкое
соответствие ручной разметки, а также не требует никаких предварительных
указаний о составе речевого сигнала. Основным достоинством
предложенного метода является высокая точность определения границ сегментов
фонем, а также простота алгоритма сегментирования. Данный метод сегментации
предполагается использовать в системе выделения ключевых слов в потоке
непрерывной речи. Работа выполнена при
поддержке гранта РФФИ 05-07-90372-в
Библиографический список 1. Сорокин В.Н., Цыплихин
А.И. Сегментация и распознавание гласных. Информационные
процессы,
Т.
4 2004. № 2 – С.
202-220 2.
Ganapathiraju A., Hamaker J., Picone J., Doddington G.R. and Ordowski M.
Syllable-Based Large Vocabulary Continuous Speech Recognition. IEEE Transactions
on Speech and AudioProcessing, 2001, vol. 9, no. 4, pp. 358–366. 3. Wilpon J.G.,
Juang B-H. and Rabiner L.R. An investigation on the use of acoustic sub-word
units for automatic speech recognition. Proc. Int. Conf. Acous., Speech, and
Sig. Processing, Dallas, TX, 1987, pp. 821–824. 4. Kamakshi
Prasad, Nagarajan, Hema Murthy Automatic segmentation of continuous speech using
minimum phase group delay functions. Speech Communication, 2004, vol. 42, pp.
429–446. 5. Ali A.M.A.,
Spiegel J.V. Acoustic-phonetic features for the automatic classification of
fricatives // J. Acoust. Soc. Am., 2001,
V. 109, N. 5, Pt. 1, P. 2217-2235. 6. Цыплихин А.И., Сорокин
В.Н. Сегментация речи на кардинальные элементы. Информационные процессы, Т. 6 .
2006. № 3. – С. 177–207 7. Воробьев В.И., Грибунин
В.Г. Теория и практика вейвлет–преобразования. – СПб 1999, – С.1-204. ![]()
![]()
![]()