



Стіхар Аліна Геннадіївна
Факультет: комп’ютерних інформаційних технологій та автоматики
Кафедра: автоматизованих систем управління
Спеціальність: інформаційні управляючі системи
Тема магістерської роботи:
Методи та алгоритми комп’ютеризованої системи
прогнозування показників народонаселення
Науковий керівник: к.т.н., доцент Привалов Максим Володимирович

прогнозування показників народонаселення»
ЗМІСТ
ВВЕДЕННЯ1 АКТУАЛЬНІСТЬ ТЕМИ
2 ЗВ'ЯЗОК РОБОТИ З НАУКОВИМИ ПРОГРАМАМИ, ПЛАНАМИ, ТЕМАМИ
3 МЕТА ТА ЗАДАЧІ РОЗРОБКИ І ДОСЛІДЖЕННЯ
4 НАУКОВА НОВИЗНА
5 ПРАКТИЧНЕ ЗНАЧЕННЯ ОТРИМАНИХ РЕЗУЛЬТАТІВ
6 ОГЛЯД ДОСЛІДЖЕНЬ І РОЗРОБОК ПО ТЕМІ
6.1 Аналіз існуючих комп'ютерних систем прогнозування показників народонаселення.
6.2 Принципи побудови, структури комп'ютерних систем, аналіз.
6.3 Огляд існуючих методів прогнозування.
7 МАТЕМАТИЧНА ПОСТАНОВКА ЗАДАЧІ ПРОГНОЗУВАННЯ ПОКАЗНИКІВ НАРОДОНАСЕЛЕННЯ
ВИСНОВОК
СПИСОК ЛІТЕРАТУРИ
ВВЕДЕННЯ
Останнім часом відбувається регіоналізація всіх сфер суспільного життя. Управління розвитком регіону, зокрема планування його бюджету, вимагає знання перспективної чисельності і особливостей вікової структури населення. Специфічні риси суспільного розвитку, різний ступінь прояву соціально-економічних проблем, у свою чергу, створюють як прямий, так і опосередкований вплив на формування народжуваності, смертності, міграційних процесів, статевовікової структури населення, вимагають диференційованого підходу до обґрунтування напрямів поліпшення демографічній ситуації в країні [1].
Тому все більшої актуальності набувають дослідження регіональних особливостей відтворення населення, виявлення причинно-наслідкових зв'язків цього процесу, з економічним розвитком окремих територій. Розробка державної соціально-економічної стратегії, оцінка і планування бюджету країни, викликають потребу в демографічному прогнозуванні.
1 АКТУАЛЬНІСТЬ ТЕМИ
Демографічні прогнози, як було сказано вище, найчастіше використовуються як основа для планування. Наприклад, при оцінці потреб країни або регіону в нових робочих місцях, вчителях, школах, лікарях, медичних сестрах, міському житлі або продуктах харчування, необхідно мати зведення про чисельність населення, якому будуть потрібні послуги. Таким чином, демографічні прогнози служать відправною крапкою для більшості прогнозів про майбутні потреби. Без глибоких демографічних обґрунтувань також неможливо визначити розмір прибуткової частини бюджету, яка залежить від чисельності робочої сили, рівня її економічної активності і кваліфікації [2].
Демографічні прогнози важливі і для політичного діалогу. Ключовим аспектом політичного процесу є визнання того, що проблема існує, і виведення цієї проблеми, на політичний порядок денний. Оскільки швидке зростання народонаселення приводить до виникнення багатьох проблем розвитку, демографічні прогнози необхідні для того, щоб проілюструвати майбутній масштаб проблем.
На даний момент в Україні недостатня увага звертається на методи регіонального прогнозування чисельності та складу населення, що і визначає актуальність теми дослідження, а висока значущість і недостатня практична розробленість цієї проблеми визначають безперечну новизну даного дослідження.
2 ЗВ'ЯЗОК РОБОТИ З НАУКОВИМИ ПРОГРАМАМИ, ПЛАНАМИ, ТЕМАМИ
Кваліфікаційна робота магістра виконувалася впродовж 2008-2009 рр. відповідно до наукових напрямків кафедри «Автоматизовані системи управління» Донецького національного технічного університету.
3 МЕТА ТА ЗАДАЧІ РОЗРОБКИ І ДОСЛІДЖЕННЯ
Мета: Обґрунтувати та вибрати метод прогнозування показників народонаселення в умовах можливої зміни чинників, і розробити алгоритми комп'ютеризованої системи прогнозування показників народонаселення.
- Задачі дослідження:
- Виконати математичну формалізацію задачі прогнозування в змінних умовах наборів чинників;
- Виконати постановку задачі експериментального дослідження точності методів;
- Виконати програмну реалізацію;
- Експериментально дослідити точність роботи методів дерев рішень і нейронних мереж, за умови зміни наборів чинників;
- На основі вибраного методу розробити алгоритм і програмне забезпечення
Предмет розробки і досліджень: методи прогнозування.
Об'єкт розробки і досліджень: задача прогнозування демографічних показників.
Методи досліджень: нейронні мережі, дерева рішень.
4 НАУКОВА НОВИЗНА
Наукова новизна дослідження полягає в застосуванні підходу штучного інтелекту для вирішення задач прогнозування демографічної ситуації на регіональному рівні.
5 ПРАКТИЧНЕ ЗНАЧЕННЯ ОТРИМАНИХ РЕЗУЛЬТАТІВ
Практична значущість дослідження визначається тією обставиною, що вдосконалена методика статистичного аналізу стану і наслідків зміни демографічній ситуації на регіональному рівні представляє інтерес для органів статистики всіх рівнів.
6 ОГЛЯД ДОСЛІДЖЕНЬ І РОЗРОБОК ПО ТЕМІ
6.1 Аналіз існуючих комп'ютерних систем прогнозування показників народонаселення.
Проведений аналіз існуючих комп'ютерних систем в області прогнозування показників народонаселення [3] дав наступні результати: вітчизняні розробки в цій області практично відсутні, або вони настільки застаріли, що не застосовуються на практиці. В основному використовуються зарубіжні системи, які були «акліматизовані» і впроваджені на території нашої держави. Нижче будуть розглянуті наступні комп'ютерні продукти:
– Програмний продукт «Прогноз» (вітчизняна розробка);
– Комп'ютерна програма для створення різноманітних прогнозів народонаселення «Демпродж».
6.2 Принципи побудови, структури комп'ютерних систем, аналіз.
Програмний продукт «Прогноз» [4].
Дана система призначена для оптимального прогнозування часових рядів (випадкових процесів з дискретним часом) і використовується при управлінні:
– соціально-економічними системами регіонів;
– економікою промислових підприємств для прогнозування попиту на продукцію, що випускається, витрат на робочу силу, цін на сировину і матеріали, і на цій основі – для прогнозування економічного стану підприємства;
– фінансовими системами для прогнозування динаміки фінансових показників і курсів цінних паперів;
– а також у демографічних системах для прогнозування чисельності населення і його структури.
Програмний продукт складається з 5 програмних модулів: "Генератор бази даних", "Монітор", "Оцінювання параметрів", "Прогнозування процесів", "Виведення інформації" і реалізує наступні основні функції:
– введення та зберігання даних про реалізації випадкових процесів;
– ідентифікація типу випадкового процесу;
– адаптивне оцінювання параметрів випадкових процесів;
– оптимальне при кінцевій кількості спостережень прогнозування випадкових процесів;
– визначення середньоквадратичних помилок для оптимальних прогнозів;
– видачу інформації про оптимальні прогнози, середньоквадратичних помилки, оцінки параметрів, тип процесу і значень випадкових процесів, що зберігаються.
У комп'ютерній системі реалізовані методи оптимального прогнозування (при кінцевій кількості спостережень) для чотирьох типів випадкових процесів, два з яких є стаціонарними, а два – нестаціонарними. Критерієм оптимальності є мінімум середньоквадратичної помилки прогнозування. Клас використовуваних випадкових процесів достатньо широкий; так, використовуються стаціонарні випадкові процеси з наступними видами автокореляційних функцій:
– експоненціальною;
– лінійною комбінацією експоненціальних функцій;
– експоненціальною, помноженою на лінійну функцію;
– експоненціальною, помноженою на лінійну комбінацію косинуса і синуса.
Використовувані нестаціонарні процеси визначаються моделями, що відображають горизонтальний і похилий лінійні стохастичні тренди. Для кожного з використовуваних в ПП "Прогноз" типів випадкових процесів застосовуються оптимальні при кінцевому числі спостережень методи прогнозування, що дозволяють визначати прогноз і відповідну середньоквадратичну помилку як функції інтервалу випередження, що задається користувачем. Широту використовуваних в ПП "Прогноз" типів випадкових процесів характеризує той факт, що окремими випадками для вживаних відповідно оптимальних методів прогнозування є широко відомі методи прогнозування: авторегресії; найменших квадратів для лінійної функції часу; простого і подвійного експоненціального згладжування.
Недоліки.
Як відомо, в умовах визначеності прогнозування успішно здійснюється на основі традиційних методів математичної і економічної статистики. Це дозволяє будувати обґрунтовані моделі систем у разі великого набору експериментальних даних, достатнього для доказу статистичних гіпотез про характер розподілу, і при відносно рівномірному їх розподілі в просторі параметрів. Проте, в умовах невизначеності, що склалися на сьогоднішній день, при високій вартості експериментальних даних, або неможливості отримання достатньої їх кількості, або їх високої зашумленості, неповноті і суперечності такі моделі є непрацездатними. Особливо небезпечне використання цих моделей при малих статистичних вибірках, оскільки отримані на них закони розподілу можуть бути нестійкими. У таких умовах якнайкращими виявляються моделі, побудовані на базі нейронних мереж.
Проте, головним, і дуже істотним недоліком продукту «Прогноз», є те, що система не може працювати в умовах набору чинників, що змінюються, тобто розглянутий програмний продукт не володіє достатньою гнучкістю в умовах нашої держави, оскільки соціальне і економічне положення дуже не стійке і знаходиться в постійному русі.
Комп'ютерна програма для створення різних прогнозів народонаселення «Демпродж» [5].
Система політичних моделей «Спектрум» – п'ятирічний проект «Поліси», що фінансується Управлінням міжнародного розвитку ЗША.
Проектом «Поліси» і попередніми йому проектами були розроблені комп'ютерні моделі, які аналізують інформацію і визначають наслідки здійснення програм в області народонаселення, а також політики, що проводиться. Система моделювання "Спектрум" консолідує попередні моделі в інтегрований пакет, що містить компоненти, приведені нижче:
– Демографія («Демпродж») – програма, призначена для демографічних прогнозів;
– Планування сім'ї («Фемплен») – програма, призначена для прогнозування потреб в плануванні сім'ї;
– Вигоди-Витрати – програма, призначена для порівняння витрат на здійснення програм в області планування сім'ї з вигодами, що отримуються від цих програм;
– СНІД (Модель наслідків СНІДУ) – програма, призначена для прогнозування наслідків епідемії СНІДУ;
– Інформаційні Ресурси для Розуміння Впливу Народонаселення на Розвиток («РЕПІД») – програма, призначена для прогнозування соціальних і економічних наслідків високого рівня народжуваності і швидкого зростання народонаселення.
Демографічна модель, що входить в систему «Спектрум», відома під назвою «Демпродж», є комп'ютерною програмою складання прогнозів в області народонаселення для окремих країн і регіонів. Ця програма вимагає інформацію про чисельність груп населення за віком та статтю в базовий рік, а також дані за поточний рік і майбутні припущення про сумарний коефіцієнт народжуваності, віковий розподіл народжуваності, очікувану тривалість життя при народженні представників обох статей, про найбільш відповідну модельну таблицю смертності, а також про масштаби і характер міжнародної міграції. Ця інформація використовується для прогнозування чисельності майбутнього населення за віком та статтю на перспективу до 150 років.
В цілому ці вхідні дані входять в один з трьох процесів, що характеризують народонаселення: народжуваність, смертність міграція. Демографічний прогноз враховує ці процеси, використовуючи інформацію про загальний рівень кожного з них, і їх форму – вікову модель.
Т.ч. принцип роботи «Демпродж» ґрунтується на багаторічних спостереженнях і зборі моделей даних. Типові «програми» роблять спробу охопити ці моделі тією невеликою кількістю параметрів, яка є виправданою.
Наприклад, демографічний Відділ ООН розробив регіональні моделі, для характеристики зрушення в народжуваності дітей із зміною рівня народжуваності. Вони позначені як моделі країн африканської Суб-сахари, арабських і азіатських країн. Аналогічно були розроблені моделі смертності і міграції.
Недоліки.
Очевидно, якщо країна географічно розташовується в Азії або африканській Суб-сахаре або є однією з арабських країн, то користувачі «Демпродж» повинні вибрати цей регіон. Проте, як звертають увагу самі розробники, це не завжди є вірним. Спершу необхідно перевірити первинний розподіл народжуваності в країні або регіоні і порівняти з модельними таблицями ООН вікового розподілу народжуваності. Т.ч. користувач не знайомий з методикою розрахунків, не може повною мірою бути упевненим в правильності вибраної моделі. Ще один істотний недолік полягає в тому, що типові моделі побудовані для дуже обширних по протяжності територій, і не можуть повною мірою відобразити все різноманіття і особливості демографічних процесів, розташованих на них держав, з різними рівнями життя і економічним розвитком. А про те, щоб побудувати вірний прогноз для невеликої по протяжності території (наприклад, для Донецької області) не може бути і мови. Найбільш істотний недолік, яким володіє система «Демпродж» (як і продукт «Прогноз») полягає в її непрацездатності при наборі чинників, що змінюється.
6.3 Огляд існуючих методів прогнозування.
При використанні традиційних моделей в прогнозуванні передбачається, що основні чинники і тенденції минулого періоду зберігаються на період прогнозу або можна обґрунтувати і врахувати напрям їх змін в перспективі. Проте в даний час, в умовах перехідної економіки, соціально-економічні процеси стають дуже динамічними. В зв'язку з цим дослідник часто має справу з новими явищами і з короткими часовими рядами. При цьому застарілі дані часто виявляються даремними і навіть шкідливими. Таким чином, виникає необхідність будувати моделі, спираючись в основному на малу кількість найсвіжіших даних, наділяючи моделі адаптивними властивостями.
Розглянувши безліч методів досліджень та прогнозування, а зокрема: регресійні методи прогнозування [6], нейромережевий підхід [7,8], нечітку логіку [9] і дерева рішень [10], з урахуванням недоліків і достоїнств кожного методу, були відібрані і обґрунтовані найбільш підходящі для вирішуваної задачі:
– Регресійні методи прогнозування не підходять, оскільки не можна побудувати регресійну модель на тривалий період з необхідною точністю.
- – Недоліками нечітких систем є:
- відсутність стандартної методики конструювання нечітких систем;
- при введенні нового чинника (додаванні лінгвістичної змінної) необхідно для кожного терму визначити функцію приналежності – тобто система позбавлена гнучкості;
- неможливість математичного аналізу нечітких систем існуючими методами;
- – Модель, представлена у вигляді дерева рішень, має ряд переваг:
- Можливість добувати правила з бази даних на природній мові;
- Не вимагає від користувача вибору вхідних атрибутів;
- Точність моделей;
- Розроблений ряд масштабованих алгоритмів;
- Швидкий процес навчання;
- Обробка пропущених значень;
- Робота і з числовими, і з категоріальними типами даних;
– Найбільш цінна властивість нейронних мереж – здатність навчатися на безлічі прикладів в тих випадках, коли невідомі закономірності розвитку ситуації і які б, то ні було залежності між вхідними і вихідними даними.
В порівнянні з лінійними методами статистики (лінійна регресія, авторегресія) нейронні мережі дозволяють ефективно будувати нелінійні залежності, які більш точно описують набори даних, а також здатні успішно вирішувати задачі, спираючись на неповну, спотворену, зашумлену і внутрішньо суперечливу вхідну інформацію.
Нейромережеві методи є універсальними апроксиматорами, мають гнучку структуру і, по думках експертів, дають якнайкращі результати.
Таким чином, моделювання здійснюватиметься на основі апарату нейронних мереж і дерев рішень.
7 МАТЕМАТИЧНА ПОСТАНОВКА ЗАДАЧІ ПРОГНОЗУВАННЯ ПОКАЗНИКІВ НАРОДОНАСЕЛЕННЯ
Часовий ряд – це впорядкована (за часом) послідовність значень деякої довільної змінної величини. Кожне окреме значення даної змінної називається відліком часового ряду. Тим самим, часовий ряд істотним чином відрізняється від простої вибірки даних [11].
Часовий ряд може бути записаний у вигляді: 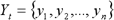
де індекс t указує на момент часу, в який зафіксовано значення або номер спостереження.
Часові ряди бувають одновимірні і багатовимірні. Одновимірні ряди містять спостереження за зміною тільки одного параметра досліджуваного процесу або об'єкту, а багатовимірні – за двома або більш параметрами.
Прогнозування часових рядів полягає в побудові моделі для прогнозу майбутніх подій ґрунтуючись на відомих подіях минулого (ретроспекція), прогнози майбутніх даних до того як вони будуть зміряні [12].Все вищесказане ілюструє рис. 7.1:
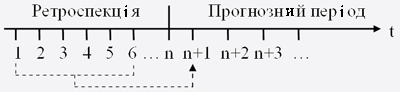
Рисунок 7.1 – Узагальнене представлення процесу прогнозування
Нехай задані n дискретних відліків 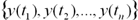 в послідовні моменти часу
в послідовні моменти часу 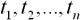 . Тоді задача прогнозування полягає в прогнозі значення
. Тоді задача прогнозування полягає в прогнозі значення 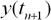 в деякий майбутній момент часу
в деякий майбутній момент часу 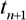 :
:
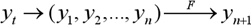 ,
,
де F – функціональний перетворювач, який, в нашому дослідженні, є апарат нейронних мереж і дерев рішень.
Нейронні мережі – це розділ штучного інтелекту, в якому для обробки сигналів використовуються явища, аналогічні тим, що відбувається в нейронах живих істот [13].
Найважливіша особливість мережі, що свідчить про її широкі можливості і величезний потенціал, полягає в паралельній обробці інформації всіма ланками, що дозволяє значно прискорити сам процес обробки інформації. Крім того, при великому числі міжнейроних з'єднань мережа набуває стійкість до помилок, що виникають на деяких лініях.В даний час нейронні мережі використовуються для вирішення цілого ряду задач, одним з яких є задача прогнозування [14].
У магістерській роботі, для вирішення задачі прогнозування, як архітектура нейронної мережі була вибрана радіально-базисна мережа (RBF) [15], на вхід якої подаватиметься багатовимірний часовий ряд, а результатом прогнозування є значення часового ряду в необхідний момент часу.
Для підвищення якості прогнозу необхідно провести попередню (препроцесорну) обробку інформації, оскільки зазвичай нейронні мережі погано працюють із величинами з широкого діапазону значень, що зустрічаються у вхідних даних. Для виключення цього небажаного явища дані необхідне промасштабувати в діапазон [0...+1] або [-1... +1]. Формула, по якій можна провести масштабування вхідних даних, має наступний вигляд:
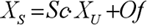 |
(1) |
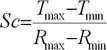 |
(2) |
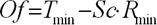 |
(3) |
Де 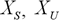 – відповідно, відмасштабовані та початкові вхідні дані;
– відповідно, відмасштабовані та початкові вхідні дані;
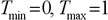 – максимум і мінімум цільової функції;
– максимум і мінімум цільової функції;
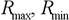 – максимум і мінімум вхідних даних.
– максимум і мінімум вхідних даних.
Радіально-базисна нейронна мережа (рис. 7.2) є мережею з одним прихованим шаром:
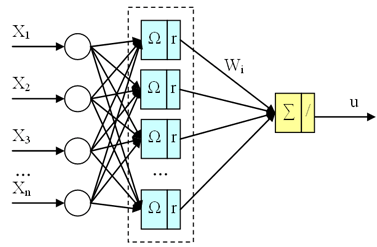
Рисунок 7.2 – радіально-базисна нейронна мережа
Прихований шар здійснює перетворення вхідного вектора X з використанням радіально-базисних функцій (RBF). Практично використовуються різні радіально-базисні функції. У нашій роботі використовуватимемо функцію, що найбільш часто вживається, – Гауссіан, що має вигляд для k-го нейрона:
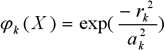 |
(4) |
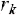 – радіус.
– радіус.
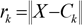 |
(5) |
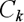 вектор центру RBF, a – параметр функції, званий шириною.
вектор центру RBF, a – параметр функції, званий шириною.
Вихідний шар мережі представляє лінійний суматор, а вихід мережі описується виразом:
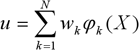 |
(6) |
де 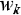 – вага, що пов'язує вихідний нейрон з k-им нейроном прихованого шару.
– вага, що пов'язує вихідний нейрон з k-им нейроном прихованого шару.
Для того, щоб зрозуміти поведінку радіальної базисної мережі загального вигляду, необхідно прослідкувати проходження вектора входу X.
При завданні значень елементам вектора входу кожен нейрон вхідного шару видає значення відповідно до того, як близько вектор входу до вектора вагів кожного нейрона. Таким чином, нейрони з векторами вагів, що значно відрізняються з вектором входу X, матимуть виходи, близькі до 0, і їх вплив на виходи лінійних нейронів вихідного шару буде незначним. Навпаки, вхідний нейрон, ваги якого близькі до вектора X, видасть значення, близьке до одиниці.
Процедура навчання нейронної мережі в загальному вигляді має вигляд:
1) Нейрони першого прихованого шару з радіальними активаційними функціями навчаються за допомогою статистичних методів кластеризації. Тобто вхідні дані розбиваються на кластери, для кожного кластера знаходиться центр (середнє арифметичне) і його D (дисперсія).
2) За допомогою градієнтного спуску або навіть лінійної регресії, визначаються ваги другого шару з лінійними активаційними функціями.
На рис. 7.3 представлена узагальнена схема процедури навчання нейронної мережі.
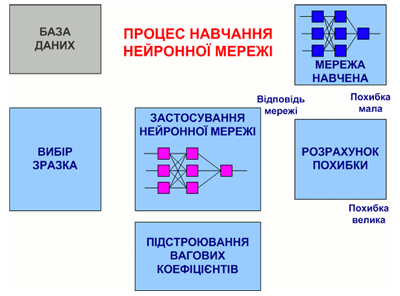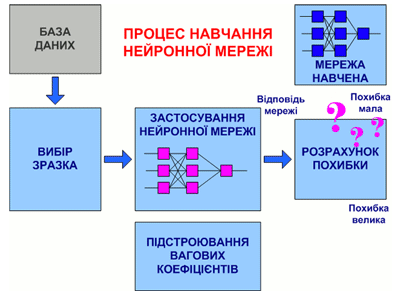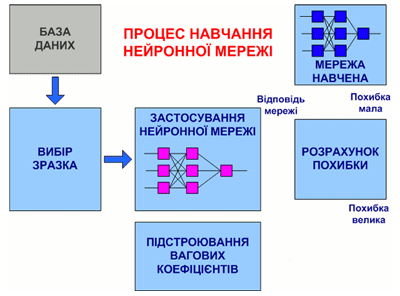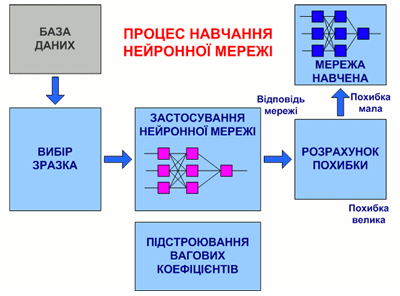
Рисунок 7.3 – Загальний вид процедури навчання нейронної мережі
(анімація: об'єм – 32 864 байт; розмір – 450х295; складається з 16 кадрів;
затримка між останнім і першим кадрами – 1 000 мс;
затримка між кадрами – 700 мс; цикл повторення – безперервний)
Доведено, що за допомогою радіально-базисних мереж можна скільки завгодно точно апроксимувати задані функції.
Модель, представлена у вигляді дерева рішень [16], є інтуїтивно зрозумілою і спрощує розуміння вирішуваної задачі. Алгоритм конструювання дерева рішень не вимагає від користувача вибору вхідних атрибутів (незалежних змінних). На вхід алгоритму можна подавати всі існуючі атрибути, алгоритм сам вибере найбільш значущі серед них, і лише вони будуть використані для побудови дерева. У порівнянні, наприклад, з нейронними мережами, це значно полегшує роботу, оскільки в нейронних мережах вибір кількості вхідних атрибутів істотно впливає на час навчання.
Більшість алгоритмів конструювання дерев рішень мають можливість спеціальної обробки пропущених значень.
У роботі використаний масштабований алгоритм дерев рішень – SLIQ [17]. Вибір обґрунтовується тим, що SLIQ відноситься до класу регресійних дерев рішень, тобто цільова змінна має безперервні значення. Таким чином, SLIQ дозволяють встановити залежність цільової змінної від незалежних (вхідних) змінних.
З кожною вершиною, яка не є листом, зв'язано деяке значення, а кожному ребру, що виходить з вузла, також відповідають деяке значення, яке є результатом обчислення виразу. Обчислення проводяться, починаючи з кореня і рухаючись до нащадків, до листа. Кожен лист має значення цільової змінної.
Для побудови дерева використовуємо наступний алгоритм. Хай є таблиця даних X, в якій n атрибутів (до кожного стовпця атрибуту 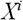 , прикріплений стовпець з індексами
, прикріплений стовпець з індексами 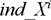 ), і Y – цільова змінна. Першим кроком необхідно виконати сортування кожного числового атрибуту, причому незалежно один від одного, у зв'язку з чим, необхідно зберігати індекси.
), і Y – цільова змінна. Першим кроком необхідно виконати сортування кожного числового атрибуту, причому незалежно один від одного, у зв'язку з чим, необхідно зберігати індекси.
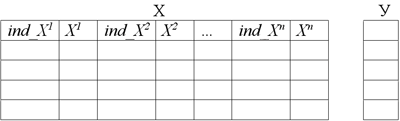
Допустимо 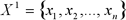 – відсортовані значення числового атрибуту
– відсортовані значення числового атрибуту 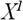 . Оскільки, будь-яке значення між
. Оскільки, будь-яке значення між 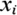 i
i 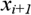 розділить множину на ті ж самі дві підмножини, необхідно досліджувати тільки n-1 можливе розбиття. Середина кожного інтервалу i вважається за можливу точку розбиття (тобто можливим вузлом).
розділить множину на ті ж самі дві підмножини, необхідно досліджувати тільки n-1 можливе розбиття. Середина кожного інтервалу i вважається за можливу точку розбиття (тобто можливим вузлом).
У алгоритмі SLIQ кожен вузол дерева рішень має двох нащадків. На кожному кроці побудови дерева правило виду 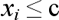 , формоване у вузлі, ділить задану навчальну вибірку на дві частини – частина, в якій виконується правило (нащадок – right) і частина, в якій правило не виконується (нащадок – left), все вищеописане ілюструє рис. 7.4.
, формоване у вузлі, ділить задану навчальну вибірку на дві частини – частина, в якій виконується правило (нащадок – right) і частина, в якій правило не виконується (нащадок – left), все вищеописане ілюструє рис. 7.4.
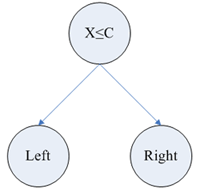
Рисунок 7.4 – Приклад дерева рішень
Для вибору оптимального правила використовується функція оцінки якості розбиття, яка визначається як мінімізація SSE (7):
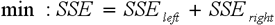 |
(6) |
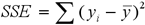 |
(7) |
Описані обчислення, тобто зростання дерева завширшки, продовжуються до тих пір, поки не буде виконано правило зупинки. До правил зупинки можна віднести: обмеження глибини дерева (зупинити подальшу побудову, якщо розбиття веде до дерева з глибиною, що перевищує задане значення), використання статистичних методів для оцінки доцільності подальшого розбиття.
ВИСНОВОК
В ході виконання науково-дослідної роботи були проаналізовані існуючі комп'ютерні системи прогнозування показників народонаселення, виявлені їх недоліки, і поставлені вимоги до системи, що розробляється. Основною з них є гнучкість. Відповідно до виконаного наукового пошуку по методах дослідження і прогнозування, можна зробити висновок, що моделювання здійснюватиметься на основі апарату нейронних мереж і дерев рішень. Регресійні методи відкинуті, оскільки не можна побудувати регресійну модель на тривалий період з необхідною точністю. Нечітка логіка не забезпечуватиме системі, що розробляється, необхідну гнучкість. Модель, представлена у вигляді дерева рішень, не вимагає від користувача вибору незалежних змінних, оскільки алгоритм сам вибере найбільш значущі серед них. Так само великою позитивною якістю алгоритмів конструювання дерев рішень є можливість спеціальної обробки пропущених значень. Найбільш цінна властивість нейронних мереж – здатність навчатися на безлічі прикладів в тих випадках, коли невідомі закономірності розвитку ситуації і які б, то ні було залежності між вхідними і вихідними даними. В порівнянні з лінійними методами статистики (лінійна регресія, авторегресія) нейронні мережі дозволяють ефективно будувати нелінійні залежності, які найбільш точно описують набори даних, а також здатні успішно вирішувати задачі, спираючись на неповну, спотворену, зашумлену і внутрішньо суперечливу вхідну інформацію.
СПИСОК ЛІТЕРАТУРИ
1. Пузиков О.С Курс лекций по социально-экономическому прогнозированию: Прогнозирование демографического развития [Электронный ресурс] / Ростов н/Д: Рост. гос. строит. ун-т. 2000. Режим доступа:URL:
http://inpos.com.ua/45
2. Кричевский М.Л. Интеллектуальный анализ данных в менеджменте. Учебное пособие / СПбГУАП. СПб., 2005. – 208 с.
3. Software. Page presents an overview of demographic software and models: [Электронный ресурс]. Режим доступа: URL:
http://www.nidi.knaw.nl
4. Аширова О.Н. Программный продукт «Прогноз» и его основные свойства [Электронный ресурс] / Цукерман Е.В // Международный журнал: Программные продукты и системы – 2000. – №2. – Режим доступа: URL:
http://swsys.ru/index.php?page=article&id=1151
5. John Stover DemProj Version 4 A Computer Program for Making Population Projections: March 2007. – 106 с.
6. Учебник. Методы прогнозирования: Регрессионные методы прогнозирования [Электронный ресурс] / Аналитические технологии для прогнозирования и анализа данных. НейроПроект: 1999-2005. Режим доступа: URL:
http://www.neuroproject.ru/forecasting_tutorial.php
7. Комарцова Л.Г. Нейрокомпьютеры: Учеб. пособие для вузов. – 2-е изд., перераб. и доп. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2004. – 400с.
8. Прогнозирование и классификация экономических систем в условиях неопределенности методами искусственных нейронных сетей: Аналитический обзор. [Электронный ресурс]. Режим доступа:
URL: http://www.nauka-shop.com/mod/shop/categoryID/110/page/34
9. Круглов В.В Интеллектуальные информационные системы: компьютерная поддержка систем нечеткой логики и нечеткого вывода. / Дли М.И. – М.: Физматлит, 2002. – 221 с.
10. Чубукова И.А. Методы классификации и прогнозирования. Деревья решений: конспект лекций. [Электронный ресурс]: Режим доступа: URL: http://www.intuit.ru/department/database/datamining/9/2.html
11. Временной ряд. Глоссарий. [Электронный ресурс] / Режим доступа: URL: http://www.basegroup.ru/glossary/definitions/time_series/
12. Єріна А. М. Статистичне моделювання та прогнозування: Навч. посіб
ник. / – К.: КНЕУ, 2001. – 170 с.
13. Wasserman P.D. Neural Computing: Theory and Practice / Van Nostrand Reinhold, New York, NY 1989. – 189 с.
14. Нейросетевой анализ и прогнозирование: (сборник статей) [Электронный ресурс]. Режим доступа: URL: http://www.netneuro.ru
15. Lendasse А. Approximation by radial basis function networks application.
16. А. Шахиди Деревья решений – общие принципы работы. [Электронный ресурс]. Режим доступа: URL: http://www.basegroup.ru/library/analysis/tree/description/
17. Manish Mehta, Rakesh Agrawal, Jorma Rissanen SLIQ: A Fast Scalable Classifier for Data Mining. / IBM Almaden Research Center, – 15 с.
При написанні даного автореферату магістерська робота ще не завершена. Дата остаточного завершення роботи: 1 грудня 2009 р. Повний текст роботи і матеріали по темі можуть бути отримані у автора або його наукового керівника після вказаної дати.

