



Стихарь Алина Геннадьевна
Факультет: компьютерных информационных технологий и автоматики
Кафедра: автоматизированных систем управления
Специальность: информационные управляющие системы
Тема магистерской работы:
Методы и алгоритмы компьютеризированной системы
прогнозирования показателей народонаселения
Научный руководитель: к.т.н., доцент Привалов Максим Владимирович

прогнозирования показателей народонаселения»
СОДЕРЖАНИЕ
ВВЕДЕНИЕ1 АКТУАЛЬНОСТЬ ТЕМЫ
2 СВЯЗЬ РАБОТЫ С НАУЧНЫМИ ПРОГРАММАМИ, ПЛАНАМИ, ТЕМАМИ
3 ЦЕЛЬ И ЗАДАЧИ РАЗРАБОКИ И ИССЛЕДОВАНИЯ
4 НАУЧНАЯ НОВИЗНА
5 ПРАКТИЧЕСКОЕ ЗНАЧЕНИЕ ПОЛУЧЕННЫХ РЕЗУЛЬТАТОВ
6 ОБЗОР ИССЛЕДОВАНИЙ И РАЗРАБОТОК ПО ТЕМЕ
6.1 Анализ существующих компьютерных систем прогнозирования показателей народонаселения.
6.2 Принципы построения, структуры компьютерных систем, анализ.
6.3 Обзор существующих методов прогнозирования.
7 МАТЕМАТИЧЕСКАЯ ПОСТАНОВКА ЗАДАЧИ ПРОГНОЗИРОВАНИЯ ПОКАЗАТЕЛЕЙ
НАРОДОНАСЕЛЕНИЯ
ЗАКЛЮЧЕНИЕ
СПИСОК ЛИТЕРАТУРЫ
ВВЕДЕНИЕ
В последнее время происходит регионализация всех областей общественной жизни. Управление развитием региона, в частности планирование его бюджета, требует знания перспективной численности и особенностей возрастной структуры населения. Специфические черты общественного развития, разная степень проявления социально-экономических проблем, в свою очередь, создают как прямое, так и опосредствованное влияние на формирование рождаемости, смертности, миграционных процессов, половозрастной структуры населения, требуют дифференцированного подхода к обоснованию направлений улучшения демографической ситуации в стране [1].
Поэтому все большую актуальность приобретают исследования региональных особенностей воссоздания населения, выявления причинно-следственных связей этого процесса, с экономическим развитием отдельных территорий. Разработка государственной социально-экономической стратегии, оценка и планирование бюджета страны, вызывают потребность в демографическом прогнозировании.
1 АКТУАЛЬНОСТЬ ТЕМЫ
Демографические прогнозы, как было сказано выше, чаще всего используются в качестве основы для планирования. Например, при оценке потребностей страны или региона в новых рабочих местах, учителях, школах, врачах, медицинских сестрах, городском жилье или продуктах питания, необходимо иметь сведения о численности населения, которому будут нужны услуги. Таким образом, демографические прогнозы служат отправной точкой для большинства прогнозов о будущих потребностях. Без глубоких демографических обоснований также невозможно определить размер доходной части бюджета, которая зависит от численности рабочей силы, уровня ее экономической активности и квалификации [2].
Демографические прогнозы важны и для политического диалога. Ключевым аспектом политического процесса является признание того, что проблема существует, и выведение этой проблемы, на политическую повестку дня. Поскольку быстрый рост народонаселения приводит к возникновению многих проблем развития, демографические прогнозы необходимы для того, чтобы проиллюстрировать будущий масштаб проблем.
На данный момент в Украине недостаточное внимание обращается на методы регионального прогнозирования численности и состава население, что и определяет актуальность темы исследования, а высокая значимость и недостаточная практическая разработанность этой проблемы определяют несомненную новизну данного исследования.
2 СВЯЗЬ РАБОТЫ С НАУЧНЫМИ ПРОГРАММАМИ, ПЛАНАМИ, ТЕМАМИ
Квалификационная работа магистра выполнялась на протяжении 2008-2009 гг. в соответствии с научными направлениями кафедры «Автоматизированные системы управления» Донецкого национального технического университета.
3 ЦЕЛЬ И ЗАДАЧИ РАЗРАБОКИ И ИССЛЕДОВАНИЯ
Цель: Обосновать и выбрать метод прогнозирования показателей народонаселения в условиях возможного изменения факторов, и разработать алгоритмы компьютеризованной системы прогнозирования показателей народонаселения.
- Задачи исследования:
- Выполнить математическую формализацию задачи прогнозирования в меняющихся условиях наборов факторов;
- Выполнить постановку задачи экспериментального исследования точности методов;
- Выполнить программную реализацию;
- Экспериментально исследовать точность работы методов деревьев решений и нейронных сетей, при условии изменения наборов факторов;
- На основе выбранного метода разработать алгоритм и программное обеспечение.
Предмет разработки и исследований: методы прогнозирования.
Объект разработки и исследований: задача прогнозирования демографических показателей.
Методы исследований: нейронные сети, решающие деревья.
4 НАУЧНАЯ НОВИЗНА
Научная новизна исследования заключается в применении подхода искусственного интеллекта для решения задачи прогнозирования демографической ситуации на региональном уровне.
5 ПРАКТИЧЕСКОЕ ЗНАЧЕНИЕ ПОЛУЧЕННЫХ РЕЗУЛЬТАТОВ
Практическая значимость исследования определяется тем обстоятельством, что усовершенствованная методика статистического анализа состояния и последствий изменения демографической ситуации на региональном уровне представляет интерес для органов статистики всех уровней.
6 ОБЗОР ИССЛЕДОВАНИЙ И РАЗРАБОТОК ПО ТЕМЕ
6.1 Анализ существующих компьютерных систем прогнозирования показателей народонаселения.
Проведенный анализ существующих компьютерных систем в области прогнозирования показателей народонаселения [3] дал следующие результаты: отечественные разработки в этой области практически отсутствуют, либо они настолько устарели, что не применяются на практике. В основном используются зарубежные системы, которые были «акклиматизированы» и внедрены на территории нашего государства. Ниже будут рассмотрены следующие компьютерные продукты:
– Программный продукт «Прогноз» (отечественная разработка);
– Компьютерная программа для создания различных прогнозов народонаселения «ДемПродж».
6.2 Принципы построения, структуры компьютерных систем, анализ.
Программный продукт «Прогноз» [4].
Рассматриваемая система предназначена для оптимального прогнозирования временных рядов (случайных процессов с дискретным временем) и используется при управлении:
– социально-экономическими системами регионов;
– экономикой промышленных предприятий для прогнозирования спроса на выпускаемую продукцию, затрат на рабочую силу, цен на сырье и материалы, и на этой основе – для прогнозирования экономического положения предприятия;
– финансовыми системами для прогнозирования динамики финансовых показателей и курсов ценных бумаг;
– а также в демографических системах для прогнозирования численности населения и его структуры.
Программный продукт состоит из 5 программных модулей: "Генератор базы данных", "Монитор", "Оценивание параметров", "Прогнозирование процессов", "Вывод информации" и реализует следующие основные функции:
– ввод и хранение данных о реализациях случайных процессов;
– идентификация типа случайного процесса;
– адаптивное оценивание параметров случайных процессов;
– оптимальное при конечном количестве наблюдений прогнозирование случайных процессов;
– определение среднеквадратических ошибок для оптимальных прогнозов;
– выдачу информации об оптимальных прогнозах, среднеквадратических ошибках, оценках параметров, типе процесса и хранящихся значений случайных процессов.
В компьютерной системе реализованы методы оптимального прогнозирования (при конечном количестве наблюдений) для четырех типов случайных процессов, два из которых являются стационарными, а два – нестационарными. Критерием оптимальности является минимум среднеквадратической ошибки прогнозирования. Класс используемых случайных процессов достаточно широк; так, используются стационарные случайные процессы со следующими видами автокорреляционных функций:
– экспоненциальной;
– линейной комбинацией экспоненциальных функций;
– экспоненциальной, умноженной на линейную функцию;
– экспоненциальной, умноженной на линейную комбинацию косинуса и синуса.
Используемые нестационарные процессы определяются моделями, отражающими горизонтальный и наклонный линейные стохастические тренды. Для каждого из используемых в ПП "Прогноз" типов случайных процессов применяются оптимальные при конечном числе наблюдений методы прогнозирования, позволяющие определять прогноз и соответствующую среднеквадратическую ошибку как функции задаваемого пользователем интервала упреждения. Широту используемых в ПП "Прогноз" типов случайных процессов характеризует тот факт, что частными случаями для применяемых соответственно оптимальных методов прогнозирования являются широко известные методы прогнозирования: авторегрессии; наименьших квадратов для линейной функции времени; простого и двойного экспоненциального сглаживания.
Недостатки.
Как известно, в условиях определенности прогнозирование успешно осуществляется на основе традиционных методов математической и экономической статистики. Это позволяет строить обоснованные модели систем в случае большого набора экспериментальных данных, достаточного для доказательства статистических гипотез о характере распределения, и при относительно равномерном их распределении в пространстве параметров. Однако, в сложившихся на сегодняшний день условиях неопределенности, при высокой стоимости экспериментальных данных, или невозможности получения достаточного их количества, или их высокой зашумленности, неполноте и противоречивости такие модели являются неработоспособными. В особенности опасно использование этих моделей при малых статистических выборках, так как полученные на них законы распределения могут быть неустойчивыми. В таких условиях наилучшими оказываются модели, построенные на базе нейронных сетей.
Однако, главным, и очень существенным недостатком продукта «Прогноз», является то, что система не может работать в условиях меняющего набора факторов, т.е. рассмотренный программный продукт не обладает достаточной гибкостью в условиях нашего государства, т.к. социальное и экономическое положение очень не устойчиво и находится в постоянном движении.
Компьютерная программа для создания различных прогнозов народонаселения «ДемПродж» [5].
Система политических моделей «Спектрум» – пятилетний проект «Полиси», финансируемый Управлением международного развития США.
Система политических моделей «Спектрум» – пятилетний проект «Полиси», финансируемый Управлением международного развития США.
Проектом «Полиси» и предшествующими ему проектами были разработаны компьютерные модели, которые анализируют информацию и определяют последствия осуществления программ в области народонаселения, а также проводимой политики. Система моделирования "Спектрум" консолидирует предыдущие модели в интегрированный пакет, содержащий компоненты, приведенные ниже:
– Демография («ДемПродж») – программа, предназначенная для демографических прогнозов;
– Планирование семьи («Фэмплэн») – программа, предназначенная для прогнозирования потребностей в планировании семьи;
– Выгоды-Затраты – программа, предназначена для сравнения затрат на осуществление программ в области планирования семьи с выгодами, получаемыми от этих программ;
– СПИД (Модель последствий СПИДа) – программа, предназначенная для прогнозирования последствий эпидемии СПИДа;
– Информационные Ресурсы для Понимания Влияния Народонаселения на Развитие («РЭПИД») – программа, предназначенная для прогнозирования социальных и экономических последствий высокого уровня рождаемости и быстрого роста народонаселения.
Демографическая модель, входящая в систему «Спектрум», известная под названием «ДемПродж», представляет собой компьютерную программу составления прогнозов в области народонаселения для отдельных стран и регионов. Эта программа требует информации о численности групп населения по возрасту и полу в базовый год, а также данные за текущий год и будущие предположения о суммарном коэффициенте рождаемости, возрастном распределении рождаемости, ожидаемой продолжительности жизни при рождении представителей обоих полов, о наиболее подходящей модельной таблице смертности, а также о масштабах и характере международной миграции. Эта информация используется для прогнозирования численности будущего населения по возрасту и полу на перспективу до 150 лет.
В целом эти вводные данные входят в один их трех процессов, характеризующих народонаселение: рождаемость, смертность миграция. Демографический прогноз учитывает эти процессы, используя информацию об общем уровне каждого из них, и их форму – возрастную модель. Т.о. принцип работы «ДемПродж» основывается на многолетних наблюдениях и сборе моделей данных. Типовые «программы» делают попытку охватить эти модели тем небольшим количеством параметров, которое является оправданным. К примеру, демографический Отдел ООН разработал региональные модели, для характеристики сдвига в деторождении с изменением уровня рождаемости. Они обозначены как модели стран африканской суб-Сахары, арабских и азиатских стран. Аналогично были разработаны модели смертности и миграции.
Недостатки.
Очевидно, если страна географически располагается в Азии или африканской суб-Сахаре или является одной из арабских стран, то пользователи «Демпродж» должны выбрать этот регион. Однако, как обращают внимание сами разработчики, это не всегда является верным. Сперва необходимо проверить первичное распределение рождаемости в стране или регионе и сравнить с модельными таблицами ООН возрастного распределения рождаемости. Т.о. пользователь не знакомый с методикой расчетов, не может в полной мере быть уверенным в правильности выбранной модели. Еще один существенный недостаток состоит в том, что типовые модели построены для слишком обширных по протяженности территорий, и не могут в полной мере отразить все многообразие и особенности демографических процессов, расположенных на них государств, с разными уровнями жизни и экономическим развитием. А о том, что построить верный прогноз для небольшой по протяженности территории (например, для Донецкой области) не может быть и речи. Наиболее существенный недостаток, которым обладает система «ДемПродж» (как и продукт «Прогноз») заключается в ее неработоспособности при изменяющемся наборе факторов.
6.3 Обзор существующих методов прогнозирования.
При использовании традиционных моделей в прогнозировании предполагается, что основные факторы и тенденции прошлого периода сохраняются на период прогноза или можно обосновать и учесть направление их изменений в перспективе. Однако в настоящее время, в условиях переходной экономики, социально-экономические процессы становятся очень динамичными. В этой связи исследователь часто имеет дело с новыми явлениями и с короткими временными рядами. При этом устаревшие данные часто оказываются бесполезными и даже вредными. Таким образом, возникает необходимость строить модели, опираясь в основном на малое количество самых свежих данных, наделяя модели адаптивными свойствами.
Рассмотрев множество методов исследований и прогнозирования, а в частности: регрессионные методы прогнозирования [6], нейросетевой подход [7,8], нечеткую логику [9] и решающие деревья [10], с учетом недостатков и достоинств каждого метода, были отобраны и обоснованы наиболее подходящие для решаемой задачи:
– Регрессионные методы прогнозирования не подходят, так как нельзя построить регрессионную модель на длительный период с необходимой точностью.
- – Недостатками нечетких систем является:
- отсутствие стандартной методики конструирования нечетких систем;
- при введении нового фактора (добавлении лингвистической переменной) необходимо для каждого терма определить функцию принадлежности – то есть система лишена гибкости;
- невозможность математического анализа нечетких систем существующими методами;
- – Модель, представленная в виде дерева решений, имеет ряд преимуществ:
- Возможность извлекать правила из базы данных на естественном языке;
- Не требует от пользователя выбора входных атрибутов;
- Точность моделей;
- Разработан ряд масштабируемых алгоритмов;
- Быстрый процесс обучения;
- Обработка пропущенных значений;
- Работа и с числовыми, и с категориальными типами данных;
Таким образом, моделирование будет осуществляться на основе аппарата нейронных сетей и деревьев решений.
7 МАТЕМАТИЧЕСКАЯ ПОСТАНОВКА ЗАДАЧИ
Временной ряд – это упорядоченная (по времени) последовательность значений некоторой произвольной переменной величины. Каждое отдельное значение данной переменной называется отсчётом временного ряда. Тем самым, временной ряд существенным образом отличается от простой выборки данных [11].
Временной ряд может быть записан в виде: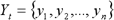
где индекс t указывает на момент времени, в который зафиксировано значение или номер наблюдения.
Временные ряды бывают одномерные и многомерные. Одномерные ряды содержат наблюдения за изменением только одного параметра исследуемого процесса или объекта, а многомерные – за двумя или более параметрами.
Прогнозирование временных рядов заключается в построении модели для предсказания будущих событий основываясь на известных событиях прошлого (ретроспекция), предсказания будущих данных до того как они будут измерены [12].
Все вышесказанное иллюстрирует рис. 7.1:
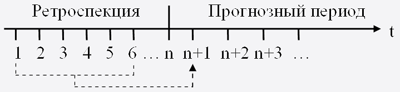
Рисунок 7.1 – Обобщенное представление процесса прогнозирования
Пусть заданы n дискретных отсчетов 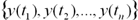 в последовательные моменты времени
в последовательные моменты времени 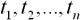 . Тогда задача прогнозирования состоит в предсказании значения
. Тогда задача прогнозирования состоит в предсказании значения 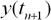 в некоторый будущий момент времени
в некоторый будущий момент времени 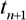 :
:
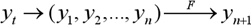 ,
,
где F – функциональный преобразователь, который, в нашем исследовании, представляет собой аппарат нейронных сетей и деревьев решений.
Нейронные сети – это раздел искусственного интеллекта, в котором для обработки сигналов используются явления, аналогичные происходящим в нейронах живых существ [13].
Важнейшая особенность сети, свидетельствующая о ее широких возможностях и огромном потенциале, состоит в параллельной обработке информации всеми звеньями, что позволяет значительно ускорить сам процесс обработки информации. Кроме того, при большом числе межнейронных соединений сеть приобретает устойчивость к ошибкам, возникающим на некоторых линиях.
В настоящее время нейронные сети используются для решения целого ряда задач, одной из которых является задача прогнозирования [14].
В магистерской работе, для решения задачи прогнозирования, в качестве архитектуры нейронной сети была выбрана радиально-базисная сеть (RBF) [15], на вход которой будет подаваться многомерный временной ряд, а результатом прогнозирования является значение временного ряда в требуемый момент времени.
Для повышения качества прогноза необходимо произвести предварительную (препроцессорную) обработку информации, т.к. обычно нейронные сети плохо работают с величинами из широкого диапазона значений, встречающихся во входных данных. Для исключения этого нежелательного явления данные необходимо промасштабировать в диапазон [0...+1] или [–1... +1]. Формула, по которой можно провести масштабирование входных данных, имеет следующий вид:
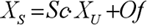 |
(1) |
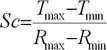 |
(2) |
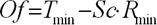 |
(3) |
Где 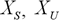 – соответственно, отмасштабированные и исходные входные данные;
– соответственно, отмасштабированные и исходные входные данные;
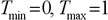 – максимум и минимум целевой функции;
– максимум и минимум целевой функции;
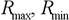 – максимум и минимум входных данных.
– максимум и минимум входных данных.
Радиально-базисная нейронная сеть (рис. 7.2) представляет собой сеть с одним скрытым слоем:
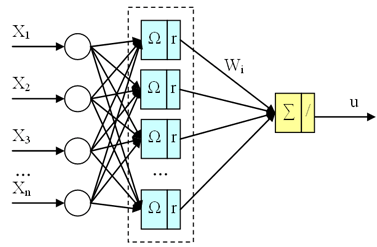
Рисунок 7.2 – Радиально-базисная нейронная сеть
Скрытый слой осуществляет преобразование входного вектора X с использованием радиально-базисных функций (RBF). Практически используются различные радиально-базисные функции. В нашей работе будем использовать наиболее часто употребляемую функцию – Гауссиан, имеющий вид для k-го нейрона:
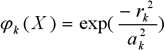 |
(4) |
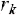 – радиус.
– радиус.
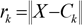 |
(5) |
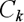 вектор центра RBF, a – параметр функции, называемый шириной.
вектор центра RBF, a – параметр функции, называемый шириной.
Выходной слой сети представляет линейный сумматор, а выход сети описывается выражением:
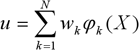 |
(6) |
где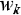 – вес, связывающий выходной нейрон с k-ым нейроном скрытого слоя.
– вес, связывающий выходной нейрон с k-ым нейроном скрытого слоя.
Для того, чтобы понять поведение радиальной базисной сети общего вида, необходимо проследить прохождение вектора входа X.
При задании значений элементам вектора входа каждый нейрон входного слоя выдает значение в соответствии с тем, как близок вектор входа к вектору весов каждого нейрона. Таким образом, нейроны с векторами весов, значительно отличающимися с вектором входа X, будут иметь выходы, близкие к 0, и их влияние на выходы линейных нейронов выходного слоя будет незначительное. Напротив, входной нейрон, веса которого близки к вектору X, выдаст значение, близкое к единице.
Процедура обучения нейронной сети в общем виде имеет вид:
1) Нейроны первого скрытого слоя с радиальными активационными функциями обучаются с помощью статистических методов кластеризации. Т.е. входные данные разбиваются на кластеры, для каждого кластера находится центр (среднее арифметическое) и его D (дисперсия).
2) С помощью градиентного спуска или даже линейной регрессии, определяются веса второго слоя с линейными активационными функциями.
На рис. 7.3 представлена обобщенная схема процедуры обучения нейронной сети.
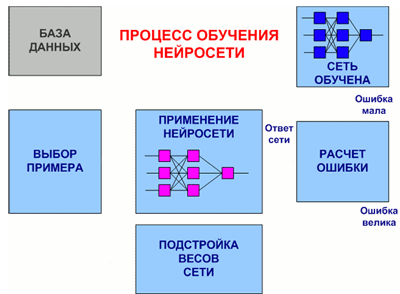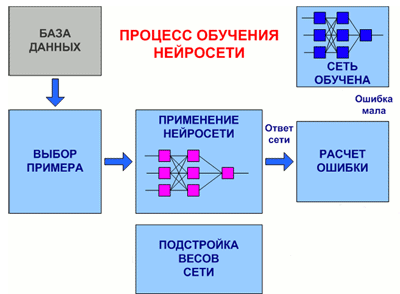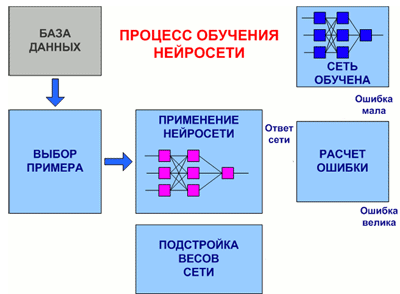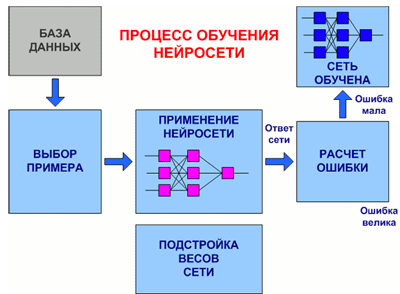
Рисунок 7.3 – Общий вид процедуры обучения нейронной сети
(анимация: объем – 32 864 байт; размер – 450х295; состоит из 16 кадров;
задержка между последним и первым кадрами – 1 000 мс;
задержка между кадрами – 700 мс; цикл повторения – непрерывный)
Доказано, что с помощью радиально-базисных сетей можно сколь угодно точно аппроксимировать заданные функции.
Модель, представленная в виде дерева решений [16], является интуитивно понятной и упрощает понимание решаемой задачи. Алгоритм конструирования дерева решений не требует от пользователя выбора входных атрибутов (независимых переменных). На вход алгоритма можно подавать все существующие атрибуты, алгоритм сам выберет наиболее значимые среди них, и только они будут использованы для построения дерева. В сравнении, например, с нейронными сетями, это значительно облегчает работу, поскольку в нейронных сетях выбор количества входных атрибутов существенно влияет на время обучения.
Большинство алгоритмов конструирования деревьев решений имеют возможность специальной обработки пропущенных значений.
В работе использован масштабируемый алгоритм деревьев решений – SLIQ [17]. Выбор обосновывается тем, что SLIQ относится к классу регрессионных решающих деревьев, т.е. целевая переменная имеет непрерывные значения. Таким образом, SLIQ позволяют установить зависимость целевой переменной от независимых (входных) переменных.
С каждой вершиной, которая не является листом, связано некоторое значение, а каждому ребру, выходящему из узла, также соответствуют некоторое значение, которое является результатом вычисления выражения. Вычисления проводятся, начиная с корня и двигаясь к потомкам, до листа. Каждый лист имеет значение целевой переменной.
Для построения дерева используем следующий алгоритм. Пусть имеется таблица данных X, в которой n атрибутов (к каждому столбцу атрибута 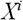 , прикреплен столбец с индексами
, прикреплен столбец с индексами 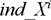 ), и Y – целевая переменная. Первым шагом необходимо выполнить сортировку каждого числового атрибута, причем независимо друг от друга, в связи с чем, необходимо хранить индексы.
), и Y – целевая переменная. Первым шагом необходимо выполнить сортировку каждого числового атрибута, причем независимо друг от друга, в связи с чем, необходимо хранить индексы.
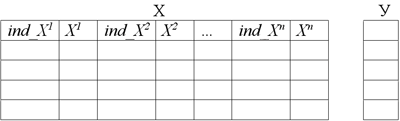
Допустим 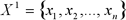 – отсортированные значения числового атрибута
– отсортированные значения числового атрибута 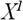 . Так как, любое значение между
. Так как, любое значение между 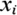 и
и 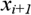 разделит множество на те же самые два подмножества, необходимо исследовать только n-1 возможное разбиение. Середина каждого интервала и считается возможной точкой разбиения (т.е. возможным узлом).
В алгоритме SLIQ каждый узел дерева решений имеет двух потомков. На каждом шаге построения дерева правило вида
разделит множество на те же самые два подмножества, необходимо исследовать только n-1 возможное разбиение. Середина каждого интервала и считается возможной точкой разбиения (т.е. возможным узлом).
В алгоритме SLIQ каждый узел дерева решений имеет двух потомков. На каждом шаге построения дерева правило вида 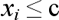 , формируемое в узле, делит заданное обучающую выборку на две части – часть, в которой выполняется правило (потомок – right) и часть, в которой правило не выполняется (потомок – left), все вышеописанное иллюстрирует рис. 7.4.
, формируемое в узле, делит заданное обучающую выборку на две части – часть, в которой выполняется правило (потомок – right) и часть, в которой правило не выполняется (потомок – left), все вышеописанное иллюстрирует рис. 7.4.
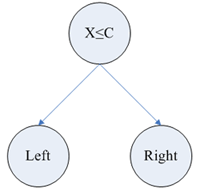
Рисунок 7.4 – Пример решающего дерева
Для выбора оптимального правила используется функция оценки качества разбиения, которая определяется как минимизация SSE (7):
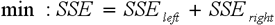 |
(6) |
где SSE каждой части предполагаемого разбиения определяется по формуле:
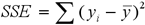 |
(7) |
Описанные вычисления, т.е. рост дерева в ширину, продолжаются до тех пор, пока не будет выполнено правило остановки. К правилам остановки можно отнести: ограничение глубины дерева (остановить дальнейшее построение, если разбиение ведет к дереву с глубиной превышающей заданное значение), использование статистических методов для оценки целесообразности дальнейшего разбиения.
ЗАКЛЮЧЕНИЕ
В ходе выполнения научно-исследовательской работы были проанализированы существующие компьютерные системы прогнозирования показателей народонаселения, выявлены их недостатки, и поставлены требования к разрабатываемой системе. Основным из них является гибкость. В соответствии с проделанным научным поиском по методам исследования и прогнозирования, можно сделать вывод, что моделирование будет осуществляться на основе аппарата нейронных сетей и деревьев решений. Регрессионные методы отброшены, так как нельзя построить регрессионную модель на длительный период с необходимой точностью. Нечеткая логика не будет обеспечивать разрабатываемой системе требуемую гибкость. Модель, представленная в виде дерева решений, не требует от пользователя выбора независимых переменных, т.к. алгоритм сам выберет наиболее значимые среди них. Так же большим достоинством алгоритмов конструирования деревьев решений является возможность специальной обработки пропущенных значений. Наиболее ценное свойство нейронных сетей – способность обучаться на множестве примеров в тех случаях, когда неизвестны закономерности развития ситуации и какие бы, то ни было зависимости между входными и выходными данными. По сравнению с линейными методами статистики (линейная регрессия, авторегрессия) нейронные сети позволяют эффективно строить нелинейные зависимости, более точно описывающие наборы данных, а также способны успешно решать задачи, опираясь на неполную, искаженную, зашумленную и внутренне противоречивую входную информацию.
СПИСОК ЛИТЕРАТУРЫ
1. Пузиков О.С Курс лекций по социально-экономическому прогнозированию: Прогнозирование демографического развития [Электронный ресурс] / Ростов н/Д: Рост. гос. строит. ун-т. 2000. Режим доступа:URL:
http://inpos.com.ua/45
2. Кричевский М.Л. Интеллектуальный анализ данных в менеджменте. Учебное пособие / СПбГУАП. СПб., 2005. – 208 с.
3. Software. Page presents an overview of demographic software and models: [Электронный ресурс]. Режим доступа: URL:
http://www.nidi.knaw.nl
4. Аширова О.Н. Программный продукт «Прогноз» и его основные свойства [Электронный ресурс] / Цукерман Е.В // Международный журнал: Программные продукты и системы – 2000. – №2. – Режим доступа: URL:
http://swsys.ru/index.php?page=article&id=1151
5. John Stover DemProj Version 4 A Computer Program for Making Population Projections: March 2007. – 106 с.
6. Учебник. Методы прогнозирования: Регрессионные методы прогнозирования [Электронный ресурс] / Аналитические технологии для прогнозирования и анализа данных. НейроПроект: 1999-2005. Режим доступа: URL:
http://www.neuroproject.ru/forecasting_tutorial.php
7. Комарцова Л.Г. Нейрокомпьютеры: Учеб. пособие для вузов. – 2-е изд., перераб. и доп. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2004. – 400с.
8. Прогнозирование и классификация экономических систем в условиях неопределенности методами искусственных нейронных сетей: Аналитический обзор. [Электронный ресурс]. Режим доступа:
URL: http://www.nauka-shop.com/mod/shop/categoryID/110/page/34
9. Круглов В.В Интеллектуальные информационные системы: компьютерная поддержка систем нечеткой логики и нечеткого вывода. / Дли М.И. – М.: Физматлит, 2002. – 221 с.
10. Чубукова И.А. Методы классификации и прогнозирования. Деревья решений: конспект лекций. [Электронный ресурс]: Режим доступа: URL: http://www.intuit.ru/department/database/datamining/9/2.html
11. Временной ряд. Глоссарий. [Электронный ресурс] / Режим доступа: URL: http://www.basegroup.ru/glossary/definitions/time_series/
12. Єріна А. М. Статистичне моделювання та прогнозування: Навч. посіб
ник. / – К.: КНЕУ, 2001. – 170 с.
13. Wasserman P.D. Neural Computing: Theory and Practice / Van Nostrand Reinhold, New York, NY 1989. – 189 с.
14. Нейросетевой анализ и прогнозирование: (сборник статей) [Электронный ресурс]. Режим доступа: URL: http://www.netneuro.ru
15. Lendasse А. Approximation by radial basis function networks application.
16. А. Шахиди Деревья решений – общие принципы работы. [Электронный ресурс]. Режим доступа: URL: http://www.basegroup.ru/library/analysis/tree/description/
17. Manish Mehta, Rakesh Agrawal, Jorma Rissanen SLIQ: A Fast Scalable Classifier for Data Mining. / IBM Almaden Research Center, – 15 с.
При написании данного автореферата магистерская работа еще не завершена. Дата окончательного завершения работы: 1 декабря 2009 г. Полный текст работы и материалы по теме могут быть получены у автора или его научного руководителя после указанной даты.

