

Алейкін Владислав Валерійович
Спеціальність: Програмне забезпечення автоматизованих систем
Тема випускної роботи: Розподілена система розпізнавання текстової інформації
Керівник: доцент, к.т.н. Ладиженський Юрій Валентинович



Автореферат
Розподілена система розпізнавання текстової інформації
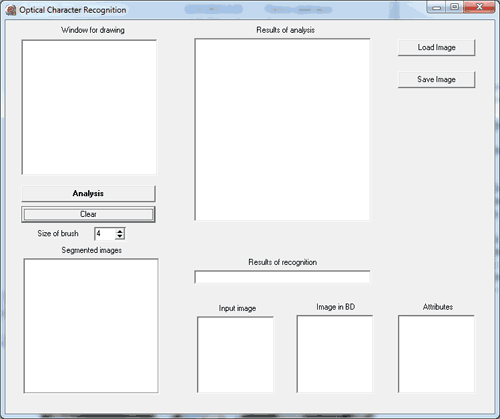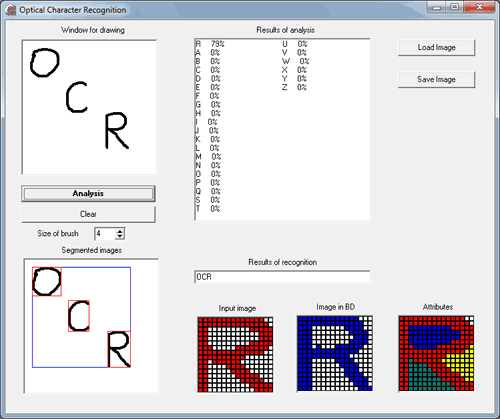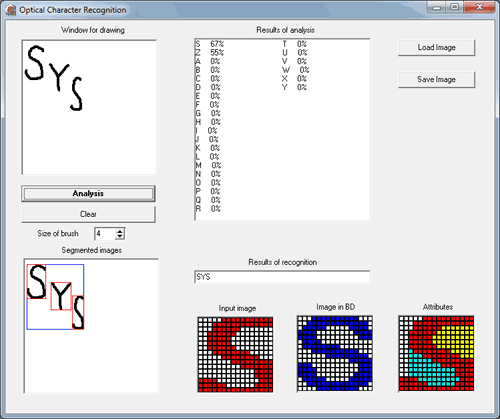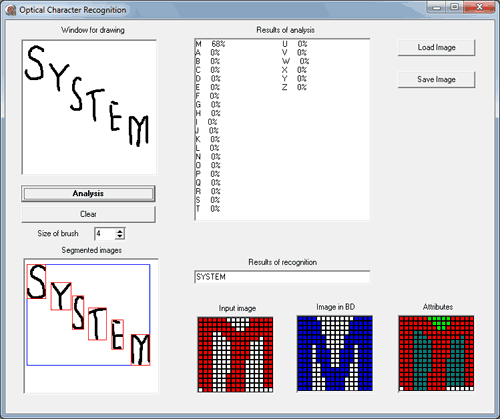
Система розпізнавання текстової інформації
(Анімація: об'єм - 87 КБ, кількість кадрів - 10, кількість циклів повторення - 7, розмір - 500x419)
(Анімація: об'єм - 87 КБ, кількість кадрів - 10, кількість циклів повторення - 7, розмір - 500x419)
Зміст
Введення
1 Актуальність теми
2 Наукова новизна
3 Плановані практичні результати
4 Огляд досліджень і розробок по темі
5 Основна ідея роботи
5.1 Опис реалізованого алгоритму
5.2 Покарщення якостi роспiзнавання
Результати роботи
Література
Введення
Сучасні технологічні, виробничі та офісні системи в процесі свого функціонування використовують інформацію про маркування об'єктів. Інформація про маркування вантажів, вагонів, контейнерів, виробів дозволяє раціональним чином організовувати процес технологічної обробки, вести облік і контроль виробів і матеріалів, прогнозувати потребу в них. В основі процесів використання маркування лежить технологія автоматизованого розпізнавання структурованих символів. Потреба в такій технології викликала необхідність створення методів, моделей та систем розпізнавання структурованих символів.
На даний час такі технології реалізуються трьома методами – структурним, ознаковим і шаблонним. Кожен з методів орієнтований на свої умови застосування, для яких він є ефективним. Кожен метод має вади. Найбільш суттєві з них – висока чутливість до афінних і проективних спотворень [1, 10].
Технологічні умови отримання інформації про маркування не дозволяють повністю усунути спотворення. Тому задача розробки методів розпізнавання структурованих символів, нечутливих (або слабко чутливих) до афінних і проективній спотворень, залишається актуальной.Технологічні умови отримання інформації про маркування не дозволяють повністю усунути спотворення. Тому завдання розробки методів розпізнавання структурованіх сімволів, нечутлівіх (або Слабкий чутлівіх) до афінних і проектівній спотворень, залишається актуальною.
1 Актуальність теми
Існує ряд програмних продуктів, які здатні розпізнавати скановані документи високої якості з текстовою інформацією з імовірністю більше 90%. Тому можна використовувати такі програми в офісах при розпізнаванні документів, а також в промисловості для контролю продукції і маркуваннi деталей.
При розпізнаванні паперових документів на практиці помилки в 10 буквах на одному аркуші не так значимі, як помилки, що одержанi в промисловій галузi. Різні умови навколишнього середовища при отриманні знімків деталей (рис. 1), а так само можливі пошкодження маркування (відколи, подряпини, плями та ін) призводять до зниження ймовірності коректного розпізнавання символу на деталі. Існуючі програмні продукти розпізнавання текстової інформації здатні прибрати слабкі перешкоди у вигляді зернистого шуму, пов'язаного з низькою якістю зйомки. Більш великі перешкоди наявні програмні продукти не здатні визначити і видалити зі знімків [2,5,8].

Рисунок 1 - Приклад промислового зображення
2 Наукова новизна
Існуючі програмні системи показують низький відсоток розпізнавання зображень з підвищеним шумом і спотвореннями.
Наукова новизна системи що розроблюється, полягає в застосуванні розподіленої обробки зображень з накладеними спотвореннями.
3 Плановані практичні результати
Після закінчення розробки системи буде отриманий працездатний програмний продукт, призначений для ефективного розпізнавання текстової інформації з підвищеним рівнем шуму на зображеннях.
4 Огляд досліджень і розробок по темі
У світі існують аналогічні програмні продукти. Найбільш успішним продуктами є:
1) ABBYY FineReader. Даний продукт здатний з високою ефективністю роспiзнавати офіснi документи різної якості, але при застосуванні на зображеннях з промислової сфери демонструє низьку ефективність. Компанія ABBYY поширює свої модулі розпізнавання окремо від продукту FineReader, але вартість використання модулів досить велика.
2) OCRopus – OPEN-SOURCE технологія, заснована на програмному забезпеченні "Tesseract", вирішує завдання індексації відсканованих документів, які можуть містити будь-яку суміш тексту, зображень та сторонніх плям. Система орієнтована тільки на офісне використання. Застосування в промисловій сфері дає низькі результати.
На національному рівні схожих систем не існує. Не було знайдено ніяких даних про плановану розробці подібної системи.
У ДонНТУ дослідженням задачі розпізнавання символів займалися наступні особи:
1) Ісаєнко Олександра Петрівна, «Використання нейронних мереж для розв'язання задач розпізнавання образів». У розробці не передбачається реалізація видалення шуму;
2) Дрига Костянтин Владиславович, «Розпізнавання зашумленних і спотворених образів за допомогою неокогнітрона». Розробка не включає етапів передобробки зображень, що знижує ефективність роботи розпізнавача. У моїй розробці передбачен модуль передобробки, який усуває явні недолiки на зображеннях, і розпізнавач виконує більш успішне визначення символу.
5 Основна ідея роботи
Розглянемо основні підходи для вирішення задачі розпізнавання символів: шаблонний, ознаковий, структурний.
При шаблонному методі проводиться порівняння зображення, що треба розпiзнати, з еталонними зразками з бази даних системи. При порівнянні обирається той еталон, який буде мінімально відрізняється від аналізованого зображення. Перевага методу – висока точність розпізнавання дефектних символів. Недолік методу – неможливість розпізнати шрифт, який хоч трохи відрізняється від закладеного в систему.
Структурні методи розпізнавання зберігають інформацію не про поточечном написанні символу, а про його топологію. Еталон містить інформацію про взаємне розташування окремих складових частин символу. Перевага методу – стійкість до зсуву і повороту символу на невеликий кут, до різних стильових варіацій шрифтів [2]. Однак, при повороті на кут, більший десяти градусів, даний метод не може бути використаний для розпізнавання символів.
Ознаковi методи базуються на тому, що зображенню ставиться у відповідність N-мірний вектор ознак. Розпізнавання полягає в порівнянні вектора ознак з набором еталонних векторів тієї ж розмірності. Переваги методу – простота реалізації, хороша узагальнююча здатність, висока швидкiсть розпiзнавання. Недолік методу – висока чутливість до дефектів зображення [2].
Всі зазначені методи обмежені в галузях застосовності. Необхідно розробити метод розпізнавання, що базується на застосуванні ознак, інваріантних до афінних і проективній перетворень. В якості таких ознак пропонується використовувати топологічні особливості символів, які отримуються за допомогою методів аналізу форми зображення [1].
5.1 Опис реалізованого алгоритму
Даний метод є комбінацією трьох описаних підходів і складається з двох етапів:
– Уточнення – обчислення ознак символу. На даному етапі на вхід подається аналізоване зображення, на виході отримується вектор ознак для образу;
– Розпізнавання – застосування методу шаблонного зіставлення для розпізнавання символу. На вхід подається зображення, що аналiзується, і вектор ознак для вхідного образу. Порівняння вхідного образу відбувається тільки з тими еталонними образами, у яких вектор ознак збігається з вхідним вектором для образу, що аналiзується. На виході отримується результат розпізнавання.
Перший етап дозволяє скоротити кількість еталонних образів для другого етапу, на якому знаходиться найбільш схожий образ.
Зображення символів мають характерні, специфічні частини, які можуть служити ознаками. Для символу ознаками є частини типу «затока» і «озеро». Найбільш значущими є «затока» і «озеро». «Затоки» примикають однією стороною до символу, а іншою - до границi образу. «Озера» не примикають до границi образу, вони знаходяться всередині символу. Наприклад, у символу 'B' існує два «озера» (рис. 2а), а у символу «N» – два «затоки» (рис. 2б).

a b
Рисунок 2 – Виділення морфологічних ознак
Таких ознак цілком достатньо, щоб дати припущення про досліджуваний символі. Але важливо знати, в якій частині символу знаходиться ознака, а також кількість ознак.
Введемо вектор Х, що містить ознаки символу. Значення елемента вектора є кількість відповідних ознак. Наприклад, х [1] – верхня затока, х [2] – права затока, х [3] – нижня затока, х [4] – ліва затока, х5 – озеро, і х [3] = 2 означає, що символ має двi нижніх затоки. Для еталонних образів символів можна обчислити вектора ознак.
Для виділення таких ознак, як «затока» і «озеро» необхідно до аналізованого символу застосувати морфологічні оператори [2, 3, 4].
Фундаментальними морфологічними операторами для множин є нарощення і ерозія, які визначаються наступним чином:
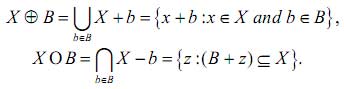
Де: Х – вхідний образ; х – одиничний елемент вхідного образу; B – структуруючим елемент (СЕ) у вигляді матриці; b – одиничний елемент структурованної матриці; z – тимчасова матриця для обробки.
Оператор нарощування потовщує символ на розмір структуруючого елемента B. Ерозія виконує зворотну дію – оператор робить символ тоншим.
Для визначення областей «заток» і «озер» використовуються оператори розмикання і замикання:
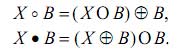
Розмикання пригнічує гострі виступи і прорізає вузькі перешийки на зображенні X, тоді як замикання заповнять вузькі затоки і малі отвори. Використовуючи поєднання таких операторів можна отримати ознаки образу. Вихідне зображення перетворюється в зображення, що містить області «заток» і «озер» Отримані області будуть розташовуватися окремо одна від одної [1, 2, 4].
Як приклад виконання описанного методу нижче представлені результати, якi отримані програмою (рис. 3). На рисунку ліворуч показано вихідний аналізований символ, а праворуч - результат виділення ознак «озер» і «заток», знизу наведено вектор, що характеризує символ.

Ха = (0, 0, 0, 1, 1) Хw = (0, 0, 2, 1, 0)

Хz = (1, 1, 0, 0, 0) Хp = (0, 0, 0, 0, 1)
Рисунок 3 - Результат застосування операторів виділення ознак
Даний метод добре працює на друкованих символах. У символах, написаних від руки, застосування методу виявляє помилкові ознаки, які знижують точність розпізнавання або призводять до повної помилки розпізнавання символу.
Експериментальним шляхом було визначено, що слід вважати несправжніми ознаками ті області, площа яких менше 7 пікселів, якщо розмір всієї матриці аналізованого символу становить 256 пікселів [5].
Після визначення вектора ознак слід визначити його приналежність до певного класу символів. Інформацію про класи зберігається в базі даних у вигляді таблиці (табл. 1).
Таблиця 1 - Таблиця класів
| № | Х(L, R, T, B, C) | Клас |
| 1 | 0 0 0 1 1 | A, R |
| 2 | 0 0 0 0 2 | B |
| 3 | 0 1 0 0 0 | C, E, F, G |
| 4 | 0 0 0 0 1 | D, O, P, Q |
| 5 | 0 0 1 1 0 | H |
| 6 | 0 0 0 0 0 | J, I, T, L |
| 7 | 0 1 1 1 0 | K |
| 8 | 0 0 1 2 0 | M |
| 9 | 1 1 0 0 0 | S, Z |
| 10 | 0 0 1 0 0 | U, V, Y |
| 11 | 0 0 2 1 0 | W |
| 12 | 1 1 1 1 0 | X |
З таблиці 1 видно, що для англійського алфавіту буде виділено 12 класів, з яким надалі буде будуватися асоціація розпізнається символу. Одному вектору ознак може відповідати декілька символів (рис. 4, 5).
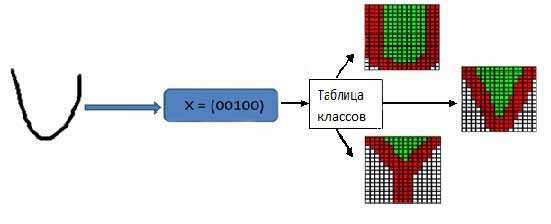
Рисунок 4 – Виділення класу для символу 'U'
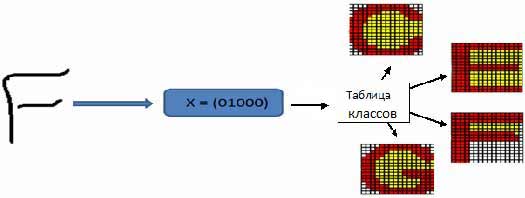
Рисунок 5 – Виділення класу для символу ‘F’
Другий етап алгоритму реалізує знаходження найбільш схожого образу символу серед обраного класу на першому етапі. Найбільш схожий образ є той, у якого відрізняються найменша кількість пікселів від вхідного зображення:
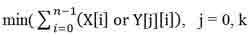
Де X - вхідний образ, У [j] - еталонний образ, n - розмір зображення, k - кількість еталонних образів.
Так як символ може бути написаний під різним кутом, в базу еталонних образів слід внести два додаткових вектора ознак, які обчислюються при повороті символу на 15 градусів і -15 градусів [6]. Такий підхід дозволяє охопити практично всі варіанти написання символів, але при цьому:
1) точність розпізнавання підвищується за рахунок розширення еталонних образів;
2) сповільнюється виконання програми, бо порівняння відбувається з трьома наборами еталонних образів.
5.2 Покарщення якостi роспiзнавання
Під час тестування було вибрано 100 рукопечатних символів. З них під час тестування було розпізнано 87, що становить 87% розпізнавання.
Для отримання більш високої оцінки розпізнавання було вирішено розширити чисельнiсть еталонних образів з одного використовуваного шрифту до десяти шрифтів різного написання. Тепер кожен символ має десять еталонних образів і відповідно 10 різних векторних ознак. Через це відбувається перетин одного класу з іншим, що утрудняє розпізнавання.
Для вирішення цієї проблеми другий етап алгоритму був вдосконалений. Зміна полягає в обчисленні середнього арифметичного відсотків подібності для 10 варіантів написання символу. При цьому необхідно пропускати еталонні образи, у яких вектор ознак відрізняється від аналізованого образу. Такий підхід дозволяє обробити лише ті символи, які не сильно відрізняються від аналізованого, що дає більш точну оцінку. На рисунках 6, 7 наведені результати застосування описаного підходу [1, 7, 9].

Рисунок 6 – Розпізнавання символу ‘U’
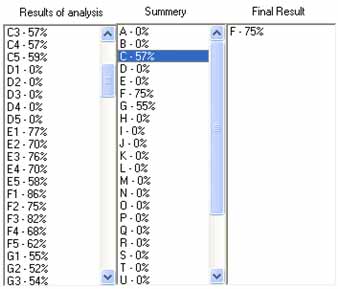
Рисунок 7 – Розпізнавання символу ‘V’
Для зниження кількості перевіряються еталонних образів були введені додаткові ознаки для кожного символу. Вторинний вектор ознак Y складається з наступних ознак:
– y1 – відношення площ НЗ до ВЗ, y1 = 0 при відношенні меншому 0.5, y1 = 1 при відношенні, що прагне до 1, y1 = 2 при відношенні більшому 1
– y2 – відношення площ ПЗ до О, y2 = 0 при відношенні меншому 0.5, y2 = 1 при відношенні більшому 0.5;
– y3 – відношення площ НЗ до ЛЗ, y3 = 0 при відношенні меншому 1, y3 = 1 при відношенi більшому 1;
– y4 – відношенні висоти О до висоти символу, y4 = 0 при відношенні, що прагне до 0.5, y4 = 1 при відношенні, що прагне до 1;
– y5 – кількість «заток» і «озер» після застосування операції генерація долин до вихідному зображенню з використанням СЕ у формі відрізка довжиною рівного висоті символу, що розташовуються під кутами 45 і 135 градусів до осі абсцис, і проведення логічного додавання з результатами виконаної раніше операції генерації долин, y5 приймає значення рівне кількості «заток» і «озер»;
– y6 – відношення в ВЗ кількості пікселів сірого кольору в першому рядку до кількості сірих пікселів під другим рядком, кількості пікселів сірого кольору у другому рядку до кількості сірих пікселів в третьому рядку, і так далі до останнього рядка, в якому є сірі пікселі ВЗ, y6 = 0 при плавному зростаннi віднощення, y6 = 1 при різкому стрибку у віднощеннi або майже при рівних віднощеннi;
– y7 – розташування О щодо середини символу, y7 = 0 при О, розташованому у верхній частині символу, y7 = 1 при О, розташованому в нижній частині символу.
Після застосування вторинного вектора ознак кількість аналізованих еталонних образів знижується, що значно прискорює обробку при розпізнаванні.
Після внесення описаних змін точність розпізнавання на тому ж наборі з 100 образів підвищилася з 87% до 93%.
Результати роботи
У ході вивчення проблеми розпізнавання символів була розроблена програмна система, заснована на методах морфологічного аналізу символів.
Використане поєднання методів дозволяє розпізнавати символи з імовірністю 93%. Розпізнавання стійко до спотворень, отриманих через афіннi перетворення масштабу й повороту.
У ході розробки:
1) Застосовано морфологічні ознаки: «затока» і «озеро». Дані ознаки описують структуру символів у вигляді топологічних особливостей, інваріантних до проективних та афінних перетворень;
2) Використано швидкі морфологічні перетворення, що дозволяють побудувати ефективні алгоритми обробки і корекції бінарних зображень за рахунок виключення операції послідовного перебору пікселів всередині аналізованого образу;
3) Отримано програмну систему розпізнавання символів iз спотвореннями.
Література
1. Гонсалес Р., Вудс Р. Цифровая обработка изображений. — М.: Техносфера, 2005. — с. 1110 — 1148.
2. Форсайт Д., Понс Д. Компьютерное зрение. Современный подход. – М.: Вильямс, 2004. — с. 603 – 610.
3. Л. Шапиро, Дж. Стокман Компьютерное зрение. Пер. с англ. — М.: БИНОМ. Лаборатория знаний,. 2006.— 752 с.
4. Wood J. Invariant pattern recognition: A review. Pattern Recognition. – 1996 – Vol. 29(1). – P. 1 – 17.
5. Бондаренко А.В., Галактионов В.А., Желтов С.Ю. Исследование подходов к построению систем автоматического считывания символьной информации. – М.: Изд-е ИПМ им. М.В. Келдыша РАН, 2003. – с. 5 – 10.
6. Alexander G. Mamistvalov. N-Dimensional Moment Invariants and Conceptual Mathematical Theory of Recognition n-Dimensional Solids. IEEE Press, – 1998. – Vol. 20. – P. 1 – 9. [Электронный ресурс] / Alexander G. Mamistvalov – Режим доступа: http://portal.acm.org/citation.cfm?id=284985
7. Саймон Хайкин. Нейронные сети. Полный курс. Издание второе (исправленное). Прэнтис Холл, 2006. – с 239 – 298.
8. Ричардс С., Вудс Р. Цифровая обработка изображений. – М.: Техносфера, 2005. – 1072 с.
9. George N. Sazaklis “Geometric methods for optical character recognition”, New York State University. – 1997. – P. 1 – 19. [Электронный ресурс] / George N. Sazaklis – Режим доступа: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.39.4698
10. Sameer Singh. Shape Detection Using Gradient Features for Handwritten Character Recognition School of Computing, University of Plymouth, 2001. – P. 1 – 13. [Электронный ресурс] / Sameer Singh – Режим доступа: http://www.computer.org/portal/web/csdl/doi/10.1109/ICPR.1996.546811

© Магістр ДонНТУ Алейкiн Владислав Валерiйович, 2010