
Автореферат з теми:
Аналіз, дослідження й удосконалення методів реалістичної візуалізації тривимірних моделей об'єктів і сцен з використанням функціонального опису
Укладач:
Іванова Катерина Володимирівна
Науковий керівник:
к.т.н., доцент кафедри ПМІ Зорі Сергій Анатолійович
Автореферат за темою випускної роботи
Вступ
Метою даної наукової роботи є аналіз методів і алгоритмів реалістичної візуалізації тривимірних сцен по класу трасування променів, їх загальних характеристик, і дослідження можливості їх використання для сцен з функціональним описом.
Об'єктом дослідження даної роботи є методи реалістичної візуалізації тривимірних моделей об'єктів.
Предмет дослідження — реалізація методів трасування променів на паралельних архітектурах графічних процесорів.
3D-візуалізація — це точне уявлення різних об'єктів в об’ємі. Візуалізація об'єктів — створення за допомогою двомірної або тривимірної графіки реалістичних (зазвичай фотореалістичних) графічних зображень, що в точності повторюють всі пропорції й деталі кінцевого продукту або будівлі, з тим, щоб про нього можна було отримати вичерпне зорове уявлення що до його реального появи.
Пристрої для перетворення персональних комп'ютерів в маленькі суперкомп'ютери відомі досить давно. Ще в 80-х роках минулого століття на ринку пропонувалися так звані трансп'ютерів, які вставлялися в поширені тоді слоти розширення ISA.
Останнім часом естафета паралельних обчислень перейшла до масового ринку, так чи інакше пов'язаного з тривимірними іграми. Універсальні пристрої з багатоядерними процесорами для паралельних векторних обчислень, які використовуються в 3D-графіці, досягають високої пікової продуктивності, яка універсальним процесорам не під силу. Звичайно, максимальна швидкість досягається лише в ряді зручних завдань і має деякі обмеження, але такі пристрої вже почали досить широко застосовувати у сферах, для яких вони споконвічно і не призначалися. Відмінним прикладом такого паралельного процесора є процесор Cell, розроблений альянсом Sony—Toshiba—IBM і вживаний в ігровій приставці Sony PlayStation 3, а також і всі сучасні відеокарти від компаній NVIDIA і AMD.
Дослідження можливості застосування технологій паралельних обчислень і є метою даної роботи.
Трасування променів (ray tracing) — метод машинної графіки, що дозволяє створювати фотореалістичні зображеня будь-яких тривимірних сцен. Трасування променів моделює проходження променів світла через зображувану сцену. Фотореалізм досягається шляхом математичного моделювання оптичних властивостей світла і його взаємодії з об'єктами. Але для отримання якісних реалістичних зображень потрібні значні тимчасові та обчислювальні ресурси.
Завдання реалізації трасування променів намагаються вирішувати безліч вчених: Horn, D. R., Sugerman, J., Houston, M., and Hanrahan реалізовували алгоритм пошуку по kd дереву з коротким стеком і пакетом променів, Попов С. — алгоритм без застосування стека і пакетів променів.
Трасування променів (Ray tracing)
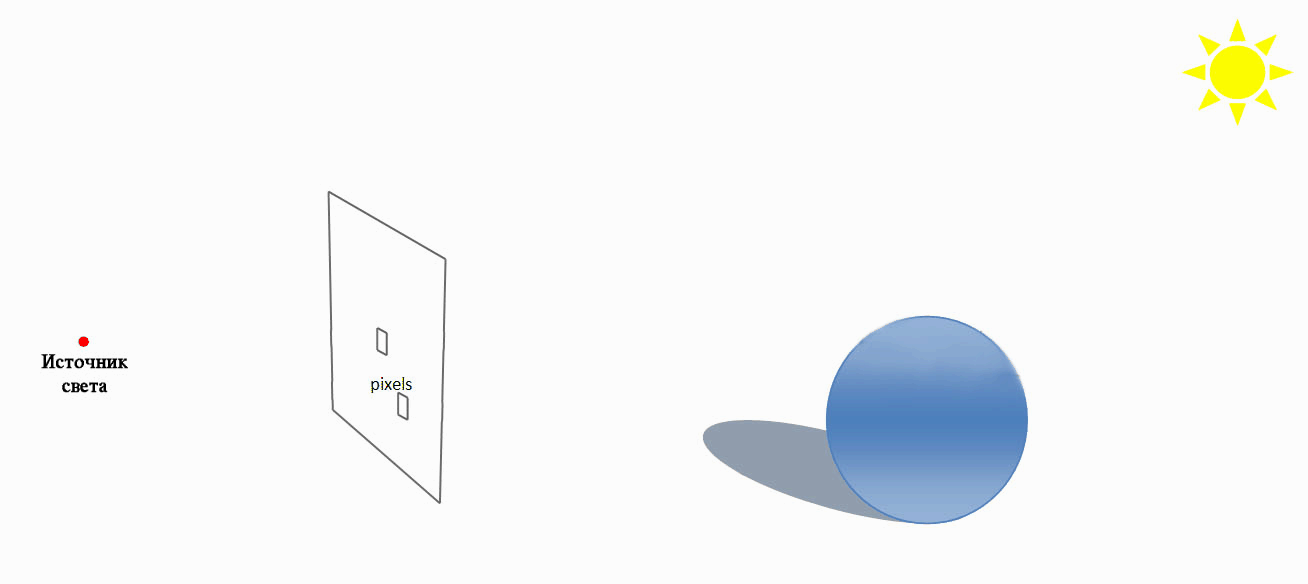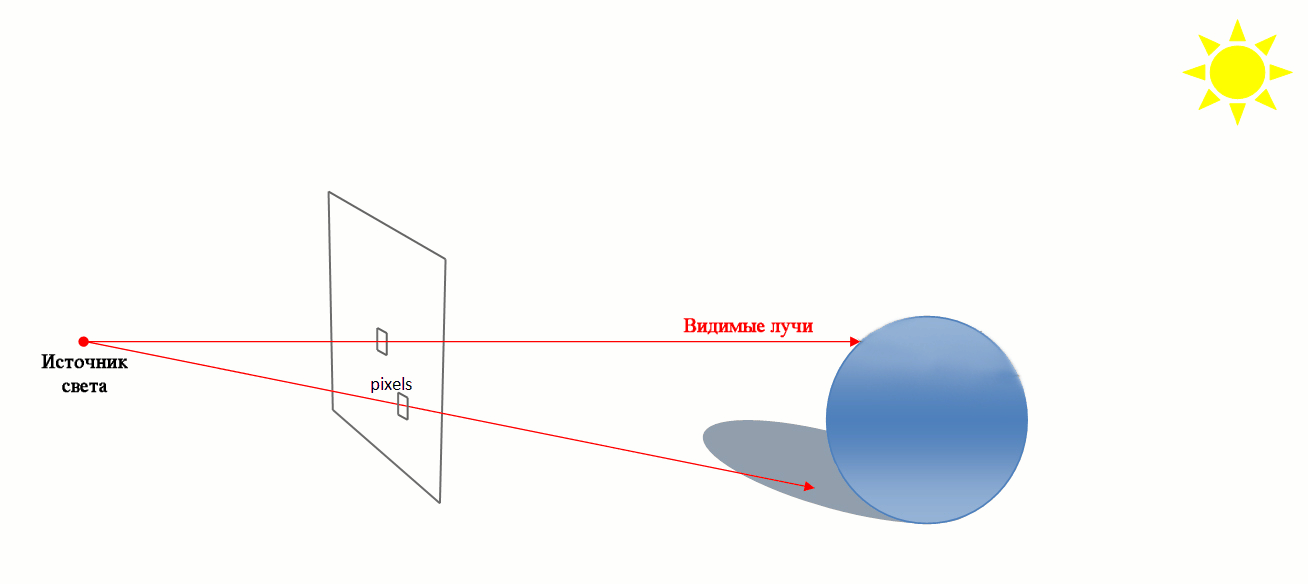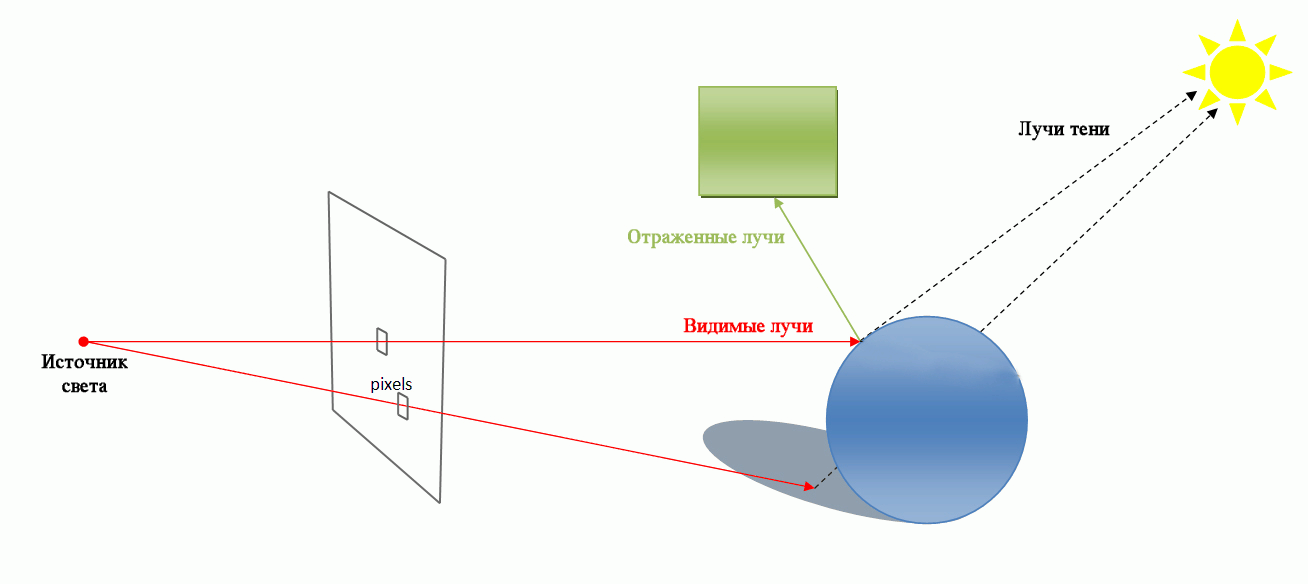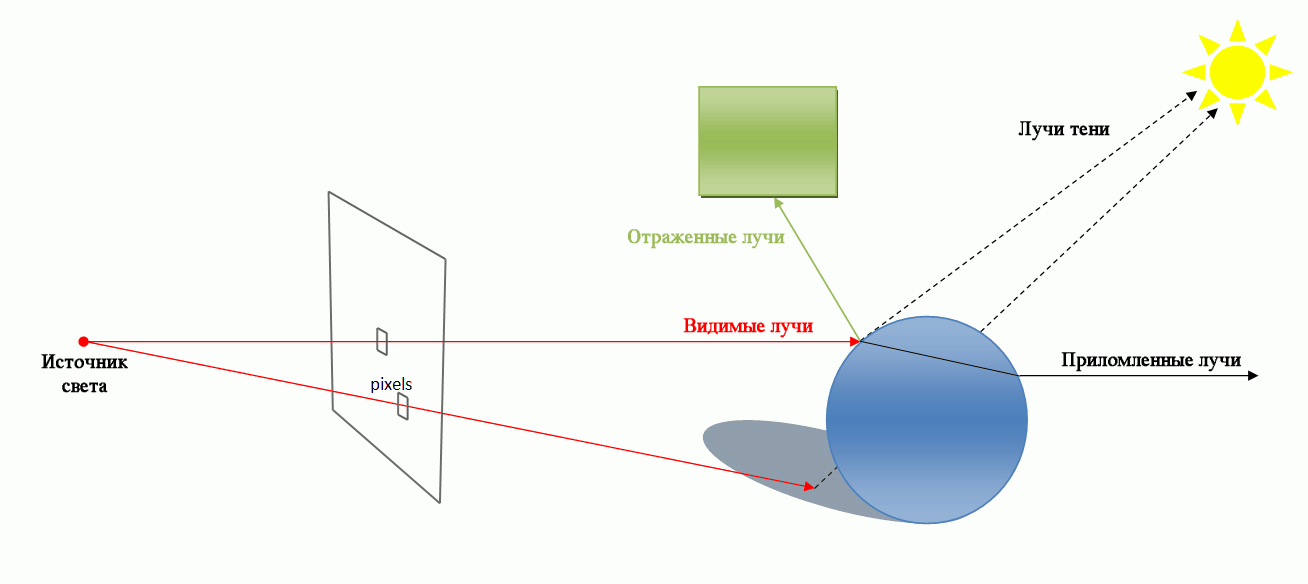

Технологія CUDA
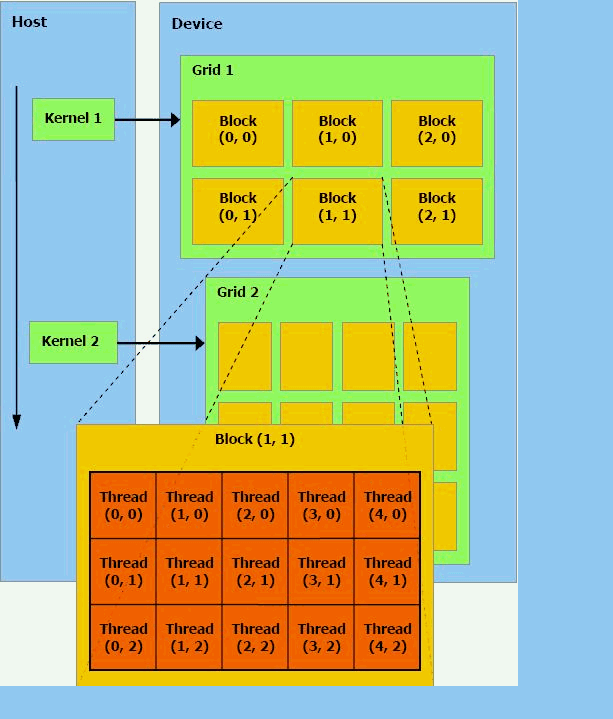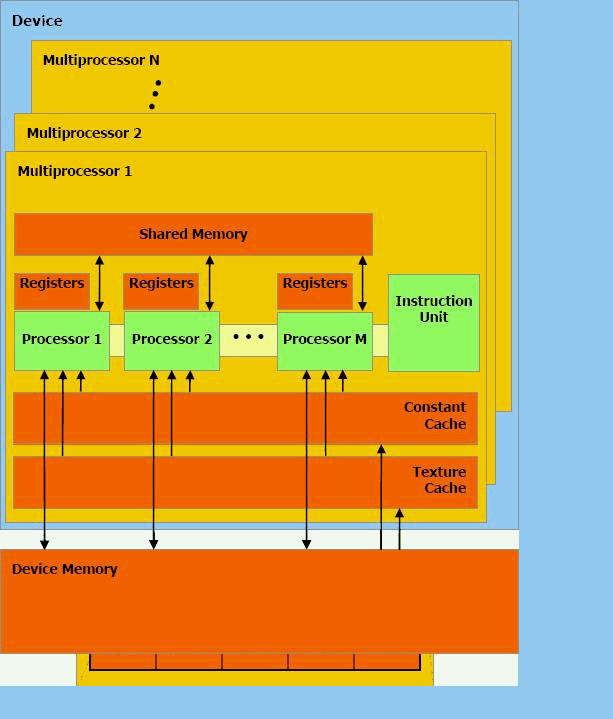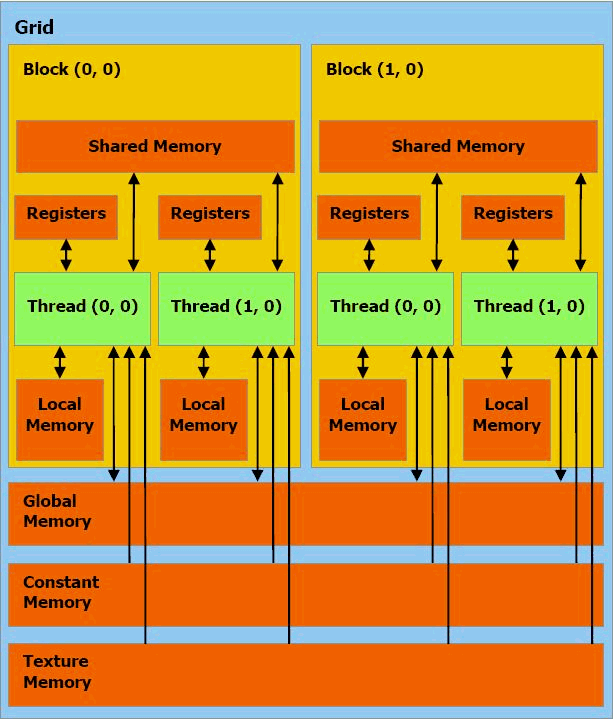
Анімація була створена за допомогою програми mp_gif_animator, має об'єм 149Кб, складається з 5 кадрів і триває 35 секунд
Для 3D відеоприскорювачів ще кілька років тому з'явилися перші технології неграфічний розрахунків загального призначення GPGPU (General-Purpose computation on GPUs). Адже сучасні відеочіпи містять сотні математичних виконавчих блоків, і ця потужність може використовуватися для значного прискорення безлічі обчислювально інтенсивних додатків. Розробники задумали зробити так, щоб GPU розраховували не тільки зображення в 3D додатках, але і застосовувалися в інших паралельних розрахунках.
Обчислення на GPU розвивалися і розвиваються дуже швидко. Компанією NVIDIA, що є однією з основних виробників відеочіпів, була розроблена платформи під назвою CUDA (Compute Unified Device Architecture). Платформа CUDA — C-подібна мова програмування зі своїм компілятором і бібліотеками для обчислень на GPU. Дана модель програмування GPU виконаний з урахуванням прямого доступу до апаратних можливостей відеокарт.
Технологія CUDA активно розвивається, відбувається введення нових додаткові компонент і можливостей для розробників. Фахівці розробляють різні тривимірні сцени із застосуванням різноманітних текстур, і так само активно займаються написанням обчислювальних програм на графічних процесорах.
Таким чином, задача дослідження та удосконалення методів реалістичної візуалізації тривимірних моделей об'єктів і сцен з використанням паралельних обчислень на GPU відеокарт є актуальною.
Зростання частот універсальних процесорів наштовхнувся на фізичні обмеження і високе енергоспоживання, і збільшення їх продуктивності дедалі частіше відбувається за рахунок розміщення декількох ядер в одному чіпі. Процесори, що продаються зараз містять лише до чотирьох ядер (подальше зростання не буде швидким) і вони призначені для звичайних додатків, використовують MIMD — множинний потік команд і даних. Кожне ядро працює окремо від інших, виконуючи різні інструкції для різних процесів.
Наприклад, в відеочіпах NVIDIA основний блок — це мультипроцесор з вісьмома-десятьма ядрами і сотнями ALU в цілому, кількома тисячами регістрів і невеликою кількістю поділюваної загальної пам'яті. Крім того, відеокарта містить швидку глобальну пам'ять з доступом до неї всіх мультипроцесорів, локальну пам'ять в кожному мультипроцесорі, а також спеціальну пам'ять для констант.
Ядра CPU створені для виконання одного потоку послідовних інструкцій з максимальною продуктивністю, а GPU проектуються для швидкого виконання великої кількості потоків інструкцій, що виконуються паралельно. Універсальні процесори оптимізовані для досягнення високої продуктивності єдиного потоку команд, що обробляє і цілі числа і числа з плаваючою крапкою. При цьому доступ до пам'яті випадковий.
У відеочіпів робота проста і від початку розпаралелина. Відеочіп приймає на вході групу полігонів, проводить всі необхідні операції, і на виході видає пікселі. Обробка полігонів і пікселів незалежна, їх можна обробляти паралельно, окремо один від одного. Тому через відначально паралельної організації роботи в GPU використовується велика кількість виконавчих блоків, які легко завантажити, на відміну від послідовного потоку інструкцій для CPU. Крім того, сучасні GPU також можуть виконувати більше однієї інструкції за такт (dual issue).
Розробка програмних продуктів із застосуванням технології CUDA дозволить більш ефективно здійснювати розв’язання завдань, пов'язаних з високим ступенем паралелізму, оскільки основою обчислювальної архітектури CUDA є концепція: одна команда на безліч даних — SIMD (Single Instruction Multiple Data).
Це дозволяє ефективно вирішувати завдання великої обчислювальної складності, наприклад, відомі задачі реалістичної 3D-графіки — трасування променів в реальному часі, 3D-моделювання, візуалізації тривимірних сцен з розрахунком фізично-реалістичного освітлення і складними матеріалами, а також підвищувати ефективність існуючих методів роботи з графікою.
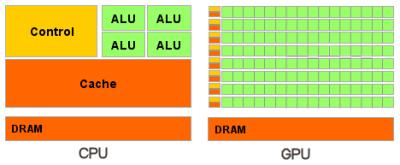
На відміну від сучасних універсальних CPU, відеочіпи призначені для паралельних обчислень з великою кількістю арифметичних операцій. І значно більше число транзисторів GPU працює за прямим призначенням — обробки масивів даних, а не керує виконанням (flow control) нечисленних послідовних обчислювальних потоків. Це схема того, скільки місця в CPU і GPU займає різноманітна логіка:
У підсумку, основою для ефективного використання потужностей GPU в наукових та інших неграфічний розрахунках є розпаралелювання алгоритмів на сотні виконавчих блоків, що є у відеочіпах. Наприклад, безліч додатків по молекулярному моделювання відмінно пристосовани для розрахунків на відеочіпах, вони вимагають великих обчислювальні потужності і тому зручні для паралельних обчислень. А використання декількох GPU дає ще більше обчислювальних потужностей для вирішення подібних завдань.
Виконання розрахунків на GPU показує відмінні результати в алгоритмах, що використовують паралельну обробку даних. Тобто, коли одну й ту ж послідовність математичних операцій застосовують до великого обсягу даних. При цьому кращі результати досягаються, якщо відношення числа арифметичних інструкцій до числа звернень до пам'яті досить велика. Це пред'являє менші вимоги до управління виконанням (flow control), а висока щільність математики і великий обсяг даних скасовує необхідність у великих кешах, як на CPU.
У результаті всіх описаних вище відмінностей, теоретична продуктивність відеочіпів значно перевершує продуктивність CPU. Компанія NVIDIA наводить такий графік зростання продуктивності CPU і GPU за останні кілька років:
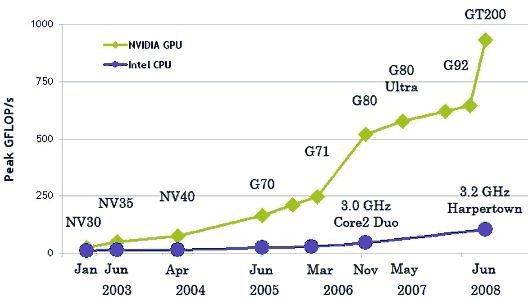
Застосування технології CUDA дозволяє розпаралелити обчислення, що дозволить підвищити швидкість виконання методів обробки тривимірних об'єктів і сцен дозволить більш якісно та ефективно реалізовувати реалізм створюваних сцен, надасть можливості для більш детального розрахунку сцен і об'єктів, застосувавши додаткові алгоритми роботи з об'єктами, наприклад, більш якісна прорисовку відображень і тіней, наводити об'єкти нетрадиційними способами, як, наприклад, функціональним описом
Також велике значення має той факт, що операції обчислення виконуються на тих самих процесорах, що і їх подальша прорисовка, що також скорочує час виконання операції і підвищує точність, оскільки результатами обчислень є числа з плаваючою точкою (вже анонсується вихід нового продукту iray, який дозволить проводити розрахунки проектів засобами mental ray 3.8, задіявши при цьому не центральний процесор, який, по суті, для такої категорій розрахунків не призначений, а GPU NVIDIA).
Таким чином, практичною цінністю роботи слід вважати підвищення продуктивності відомих методів 3D-графіки, і, отже, підвищення якості і реалізму синтезованих сцен, здешевлення апаратури для систем 3D-графіки.
Найперші спроби такого застосування були вкрай примітивними і обмежувалися використанням деяких апаратних функцій, таких, як растеризації і Z-буферизація.
У середньому, при перенесенні обчислень на GPU, у багатьох задачах досягається прискорення в 5-30 разів, у порівнянні зі швидкими універсальними процесорами. Найбільші цифри (близько 100-кратного прискорення і навіть більше!) досягаються на коді, який не дуже добре підходить для розрахунків за допомогою блоків SSE, але цілком зручний для GPU.
Основні програми, в яких зараз застосовуються обчислення на GPU: аналіз та обробка зображень і сигналів, симуляція фізики, обчислювальна математика, обчислювальна біологія, фінансові розрахунки, бази даних, динаміка газів і рідин, криптографія, адаптивна променева терапія, астрономія, обробка звуку, біоінформатика , біологічні симуляції, комп'ютерний зір, аналіз даних (data mining), цифрове кіно і телебачення, електромагнітні симуляції, геоінформаційні системи, військові застосування, гірське планування, молекулярна динаміка, магнітно-резонансна томографія (MRI), нейромережі, океанографічні дослідження, фізика частинок, симуляція згортання молекул білка, квантова хімія, трасування променів, візуалізація, радари, гідродинамічний моделювання (reservoir simulation), штучний інтелект, аналіз супутникових даних, сейсмічна розвідка, хірургія, ультразвук, відеоконференції.
- 1. Аналіз методів і алгоритмів реалістичної візуалізації тривимірних сцен по класу трасування променів, зменшення обчислювальної складності створюваних додатків за рахунок застосування технологій паралельного програмування.
- 2. Розробити ефективну реалізацію задачі трасування променів для реалістичної візуалізації тривимірних сцен за допомогою технології CUDA.
- 3. Оцінити ефективність реалізації засобами комп'ютерного моделювання для сцен з функціональним описом.
Метод трасування променів дозволяє створювати якісні, барвисті тривимірні сцени, до того ж він добре піддається розпаралеленню, що дозволить отримати добру його реалізацію застосувавши технологію CUDA.
Представлена компанією NVIDIA програмно-апаратна архітектура для розрахунків на відеочіпа CUDA добре підходить для вирішення широкого кола завдань з високим паралелізмом. CUDA працює на великій кількості відеочіпів NVIDIA, і покращує модель програмування GPU, значно спрощуючи її і додаючи велику кількість можливостей, таких як колективна пам'ять, можливість синхронізації потоків, обчислення з подвійною точністю і цілочислені операції.
Цілком імовірно, що в силу широкого розповсюдження відеокарт у світі, розвиток паралельних обчислень на GPU сильно вплине на індустрію високопродуктивних обчислень.
Універсальні процесори розвиваються досить повільно, у них немає таких стрибків продуктивності. По суті, хай це й звучить занадто гучно, усі хто потребує швидких обчислювань відтепер можуть отримати недорогий персональний суперкомп'ютер на своєму столі, іноді навіть не вкладаючи додаткових коштів, оскільки відеокарти NVIDIA широко поширені. Не кажучи вже про збільшення ефективності в термінах GFLOPS / $ і GFLOPS / Вт, які так подобаються виробникам GPU.
Майбутнє безлічі обчислень явно за паралельними алгоритмами, майже всі нові рішення і ініціативи спрямовані в цей бік.
Але, звичайно, GPU не замінять CPU. У їх теперньому вигляді вони і не призначені для цього. Зараз відеочіпи поступово рухаються у бік CPU, стаючи все більш універсальними (розрахунки з плаваючою точкою одинарної і подвійної точності, цілочислені обчислення), так і CPU стають все більш «паралельними», обзаводиться великою кількістю ядер, технологіями багатопоточності, не говорячи про появу блоків SIMD і проектів гетерогенних процесорів. Швидше за все, GPU і CPU в майбутньому просто зіллються. Відомо, що багато компаній, у тому числі Intel і AMD працюють над подібними проектами. І неважливо, чи будуть GPU поглинені CPU, або навпаки.
Один з нечисленних недоліків CUDA — слабка переносимість. Ця архітектура працює тільки на відеочіпа цієї компанії, та ще й не на всіх, а починаючи з серії GeForce 8 і 9 і відповідних Nvidia Quadro і Tesla. Так, таких рішень у світі дуже багато, NVIDIA призводить цифру в 90 мільйонів CUDA-сумісних відеочіпів. Це просто чудово, але ж конкуренти пропонують свої рішення, відмінні від CUDA.
Застосування технології CUDA для роботи з тривимірною графікою дозволить ефективно вирішувати завдання з великої обчислювальною складністю, наприклад, відомі завдання реалістичною 3D-графіки — трасування променів в реальному часі, 3D-моделювання, візуалізації тривимірних сцен з розрахунком фізично-реалістичного освітлення і складними матеріалами, а також підвищувати ефективність існуючих методів роботи з графікою, підвищити якість і реалізм синтезованих сцен, здешевити апаратуру для систем 3D-графіки.
- 1. Берилло А. NVIDIA CUDA — Неграфические вычисления на графических процессорах / iXBT, 23.09.2008, http://ixbt.com/video3/cuda-1.shtml
- 2. Демченко Л. Механика виртуальности: RayTracing / КомпьютерраOnline, 17.11.2004, — http://www.computerra.ru/hitech/36685/
- 3. Ray-traycing.ru / Лаборатория компьютерной графики, — http://ray-tracing.ru
- 4. CUDA Zone / сайт NVIDIA, — http://www.nvidia.ru/object/cuda_home_new_ru.html
- 5. Профессиональные решения NVIDIA для ускорения работы с трехмерной графикой / archi.ru, 22.12.2009, — http://archi.ru/tech/news_21081.html
- 6. Куликов А.И., Овчинникова Т.Э. Метод трассировки лучей / Интернет университет информационных технологий intuit.ru, — http://www.intuit.ru/department/graphics/graphalg/6/5.html
- 7. CUDA идёт Прогресс. Рендеринг на видеокартах NVIDIA Quadro и Tesla / Server News, 25.05.2009, — http://server-news.ru/.../224-cuda-idyot-progress-rendering-na-videokartax.html
- 8. Технология CUDA от NVIDIA / CadStudio, 16.11.2009, — http://cadstudio.ru/news/news-about-world/311-cuda-nvidia.html
- 9. Сидоров B. Что такое NVIDIA CUDA? / Netler.ru, — http://netler.ru/pc/cuda.htm
- 10. Фролов В., Игнатенко А. Интерактивная трассировка лучей и фотонные карты на GPU / Труды конференции ГрафиКон'2009, Москва, Россия, стр. 255-262. PDF, — .../97_Paper.pdf