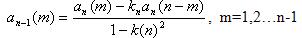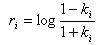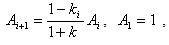|
|||||||||||
|
|||||||||||
|
РЕФЕРАТ квалификационной работы магистра «Разработка компьютеризированной системы контроля доступа с использованием аутентификации по голосу» ВВЕДЕНИЕ
СПИСОК ЛИТЕРАТУРЫ ВВЕДЕНИЕ Информация в наше время – самый дорогой и востребованный товар. Она дает власть над людскими массами или позволяет обогнать конкурентов. На защиту информации мобилизованы самые высокие технологии. Первейшая их задача – не допустить к ней постороннего человека, то есть надежно распознать, кто «свой», а кто нет. Но так, если карту доступа можно элементарно украсть, а PIN-коды не особенно удобны, их приходится запоминать и каждый раз вводить. Очевидный выход – использовать для идентификации само человеческое тело, его параметры, по-научному называемые биометрическими. Среди различных биометрических систем голосовая аутентификация имеет следующие преимущества:
1 АКТУАЛЬНОСТЬ ТЕМЫ РАБОТЫ Перед любым предприятием в современном мире остро стоит проблема защиты от несанкционированного доступа к своим материальным (помещения, здания) и виртуальным (компьютерные базы данных) ресурсам. Биометрическое решение этой проблемы – наиболее надежная и комплексная технология, из имеющихся в мире технологий, в области разработки решений по аутентификации пользователей. Согласно международной конференции, посвященной «голосовой биометрии», которая ежегодно проводится в США, аутентификация по голосу стремительно развивается и с каждым годом пользуется все большим спросом [1]. Однако до сих пор нерешенным вопросом остается выбор оптимального набора признаков, которые бы минимизировали ошибки первого и второго рода. 2 ЦЕЛЬ И ЗАДАЧИ, РЕШАЕМЫЕ В РАБОТЕ Целью магистерской работы является минимизация ошибок 1-го и 2-го рода и увеличение скорости аутентификации в компьютеризированной системе контроля доступа с использованием аутентификации по голосу. Для достижения цели магистерской работы необходимо решить следующие задачи:
3 ПРЕДПОЛАГАЕМАЯ НАУЧНАЯ НОВИЗНА Предполагаемая новизна магистерской работы: минимизация ошибок 1-го и 2-го рода за счет выбора эффективной комбинации методов выделения уникальных признаков и их классификаторов. 4 ОБЗОР ИССЛЕДОВАНИЙ И РАЗРАБОТОК ПО ТЕМЕ 4.1 На национальном уровне В нашей стране, в отличии от стран зарубежья, практически отсутствуют исследования и разработки по данной теме. В Украине данной темой занимаются в Институте проблем искусственного интеллекта [2], Харьковском национальном университете радиоэлектроники [3], Национальном техническом университете Украины «Киевском политехническом институте» [4]. 4.2 На глобальном уровне Рассмотрим следующие зарубежные системы:
Voice Key Service – система голосовой биометрической аутентификации, разработанная российской компанией «Центр речевых технологий» (ЦРТ) [5]. Технология Voice Key использует уникальные характеристики физиологического строения речевого тракта каждого человека. В ее основе лежит запатентованный компанией ЦРТ алгоритм, использующий спектрально-формантный метод выделения и сравнения биометрических признаков. Достоинства:
Недостатки:
SPIRIT SV-система – система аутентификации, разработанная российской компанией SPIRIT Corp [6]. Эта система способны работать в различных приложениях: от аутентификации диктора для локальных систем безопасности до удаленной аутентификации по телефону, что может быть применимо, например, для банковских служб и электронной коммерции. Конкретное решение может быть сделано SPIRIT Corp., включая портинг системы на заданную платформу и обеспечение телекоммуникационной поддержки. Вводимый диктором речевой сигнал (после запроса системы) подвергается следующей обработке: предварительная фильтрация; эквалайзинг для компенсации линейных искажений в микрофоне и телефонной линии; исключение участков сигнала, не содержащих речь; интеллектуальное детектирование наименее зашумленных участков речевого сигнала; выделение информативных признаков из указанных участков речевого сигнала (как правило, это спектральные признаки, в частности, кепстральные коэффициенты или их модификации). Информативные признаки содержат информацию о тексте парольной фразы и особенностях ее произнесения конкретным диктором. Затем происходит классификация вводимого речевого образца. При аутентификации осуществляется оценка близости предъявляемого образца к эталону (модели данного диктора) и производится сравнение этой оценки с порогом. Принятие решения производится по минимуму расстояния между предъявляемым образцом и ближайшей моделью из набора моделей голосов дикторов, входящих в заданную группу. Отбор на предмет принадлежности к группе осуществляется путем сравнения указанного расстояния с порогом. Система выполнена на платформе WINTEL со следующими минимальными требованиями: платформа Win32 (Windows 98SE/2000), процессор Intel Pentium MMX 200 MHz или выше, ОЗУ 32 Мб, звуковая карта, микрофон, наушники, среда MS Visual C ++ 6.0 Достоинства:
Недостатки:
Speech Secure – система идентификации голоса, разработанная американской компании Nuance Technology [7]. Первоначально в процессе регистрации, система по специальным алгоритмам, создает модель голоса, используя уникальные характеристики голоса звонящего. Система сохраняет модели голоса (описание структуры голоса и особенностей голосового тракта) как часть профиля абонента. Во время аутентификации (идентификации) эти модели используются для определения степени соответствия голоса звонящего голосам записанных ранее людей. На основе этой информации система принимает решение по проведению операции. Система доступна через веб-интерфейс. Полная версия включает:
Достоинства:
Недостатки:
5 ОПИСАНИЕ ОБЪЕКТА КОМПЬЮТЕРИЗАЦИИ Объектом компьютеризации в данной работе является система контроля доступа с использованием аутентификации по голосу. Аутентификация диктора – способ проверки подлинности, позволяющий достоверно убедиться в том, что субъект действительно является тем, за кого он себя выдает, на основании сравнения голоса с хранящимся в системе эталоном. Под голосовой аутентификацией понимается следующая ситуация [8]. Говорящий произносит фразу, а компьютеризированная система распознавания индивидуальных характеристик голоса должна подтвердить или отвергнуть индивидуальность говорящего. В принципе произнести фразу может как истинный пользователь, так и злоумышленник. Задаваясь стоимостью возможных потерь в случае возможного несанкционированного доступа злоумышленника можно (для данной системы) рассчитать вероятность, с которой система не должна пропускать чужого. Задачей начального этапа аутентификации диктора по тембру голоса является преобразование в речевой сигнал генерируемых речевой системой человека звуков [9]. Звук, как известно, представляет собой механические колебания, распространяющиеся в окружающей среде (средой распространения служит воздух). Давление звуковой волны воспринимается микрофоном и преобразуется им в электрический аналоговый сигнал. Для дальнейшей обработки необходимо провести преобразование информационного образа речи из аналогового сигнала в дискретный. Эту задачу решает аналого-цифровой преобразователь. АЦП осуществляет дискретизацию и квантование речевого сигнала. Дискретизация заключается в разбиении непрерывного сигнала на ряд дискретных отсчетов, каждый из которых представляет значение аналогового сигнала в соответствующий момент времени. Дискретизация позволяет сократить количество информации, подлежащей дальнейшей обработке, до необходимого минимума. Однако частота дискретизации, т.е. число отсчетов в секунду, должна быть достаточно велика, иначе могут быть пропущены важные изменения сигнала, присутствующие в его аналоговой форме. Согласно теореме Котельникова частота дискретизации F0 должна быть, как минимум, в два раза выше максимальной частоты преобразуемого сигнала Fmах. При меньшей частоте дискретизации начинает теряться информация, которая активно используется при распознавании. Особенно это важно для распознавания в условиях шумов. Но сильно увеличивать частоту дискретизации нет смысла: при незначительном увеличении полезной информации начинает увеличиваться количество бесполезной информации (шумов). На практике частоту дискретизации следует выбирать даже несколько больше, чем рекомендует теорема Котельникова, так как в теореме рассматривается идеализированный случай. Частотный диапазон речи находится в пределах 100-4000 Гц. Т.к. максимальная частота речи Fmах=4 кГц, то F0 должна быть несколько больше, чем 3*Fmах=12 кГц. В нашем случае мы используем частоту дискретизации F0 =22050 Гц. Квантование заключается в округлении замеренного аналогового сигнала с точностью до младшего разряда АЦП. Таким образом, квантованный сигнал может принимать только фиксированные значения с шагом, равным цене младшего разряда, в то время, как исходный сигнал был непрерывным и мог принимать любое значение. Необходимое количество разрядов АЦП n можно определить из выражения:
где D – требуемый динамический диапазон в дБ. Интенсивность звука во время речи изменяется примерно от 20 дБ (шепот) до 70 дБ (громкий разговор), таким образом динамический диапазон может достигать 50 дБ. Исходя из этого количество разрядов АЦП должно быть не менее 8. В нашем случае мы используем разрядность 16 бит. Важнейшим параметром систем аутентификации является коэффициент надежности – вероятность ошибок 1-го и 2-го рода. Ошибки возникают в результате того, что при сравнении реального идентификатора и идентификатора в базе данных существует сложность достижения идеального соответствия (100% совпадения). Поэтому вводится порог, который однозначно должен определить процент соответствия, при котором идентификатор будет признан соответствующим. Введение такого порога может привести к ошибкам ложного не распознавания или ложного опознавания:
Каждая данная система может перестраиваться таким образом, что ошибки одного рода могут быть уменьшены за счет увеличения ошибок другого рода (даже при сохранении всех других факторов, влияющих на вероятность ошибки: длительность и характер речевого сообщения, помехи и т.п.). Изменение соотношения ошибок первого и второго рода достигается за счет изменения порога принятия решения и выбора набора признаков. 6 АНАЛИЗ УНИКАЛЬНЫХ ИНДИВИДУАЛЬНЫХ ПРИЗНАКОВ, ХАРАКТЕРИЗУЮЩИХ ЛИЧНОСТЬ ГОВОРЯЩЕГО Важнейшим элементом успешного распознавания дикторов является выбор информативных признаков (речевых параметров), способных эффективно представлять информацию об особенностях речи конкретного диктора. К ним предъявляются следующие требования:
В качестве уникального вектора признаков можно использовать одномерный частотный вектор кепстральных коэффициентов, а также вектор, составленный из его производных [10]. Кепстральные коэффициенты определяются в соответствии со схемой, представленной на рис. 6.1:
Рисунок 6.1 – Общая схема кепстрального анализа сигнала (FFT – блок быстрого преобразования Фурье сигнала, LOG – блок логарифмирования спектра, IFFT – блок обратного быстрого преобразования Фурье) Линейное предсказание является одним из наиболее эффективных методов при оценке основных параметров речевого сигнала, таких как, например, период основного тона, функция площади речевого тракта и т.п. Важность метода обусловлена высокой точностью получаемых оценок и относительной простотой вычислений. Основной принцип метода линейного предсказания состоит в том, что текущий отчет речевого сигнала можно аппроксимировать линейной комбинацией предшествующих отчетов. Коэффициенты предсказания при этом определяются однозначно минимизацией среднего квадрата разности между отчетами речевого сигнала и их предсказанными значениями (на конечном интервале) [11]. Еще в качестве вектора признаков можно использовать коэффициенты отражения. Физический смысл коэффициентов отражения состоит в определении величины волны, отраженной на границе двух акустических труб. Коэффициенты отражения рассчитываются путем преобразования вектора коэффициентов предсказывающего фильтра a в коэффициенты отражения соответствующей решетчатой структуры по следующему рекурсивному алгоритму:
Данные формулы основаны на рекурсивном алгоритме Левинсона. Для его реализации в цикле перебираются элементы вектора a, начиная с последнего и заканчивая вторым. Иногда используются также функции от коэффициентов отражения – логарифмические отношения площадей (Log-Area Ratio – LAR) [12]:
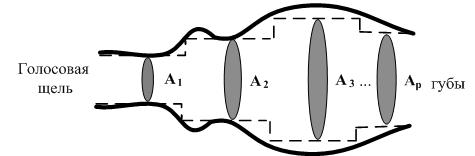
где ki – коэффициенты отражения. Еще одним признаком являются площади поперечных сечений акустических труб. Голосовой тракт можно представить в виде последовательности р акустических труб одинаковой длины и различных диаметров, имеющие площади поперечных сечений Ai [13]. Представление голосового тракта в виде последовательности труб изображено на рис. 6.2. Площади поперечных сечений Ai акустических труб вычисляется через коэффициенты отражения:
где р – порядок линейного предсказателя,
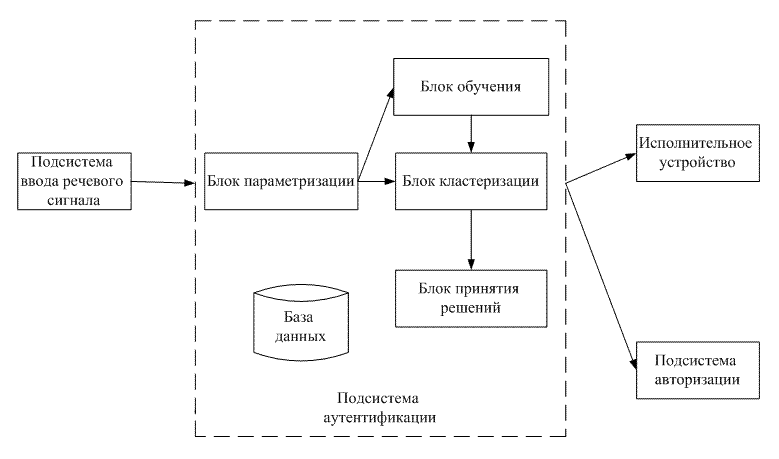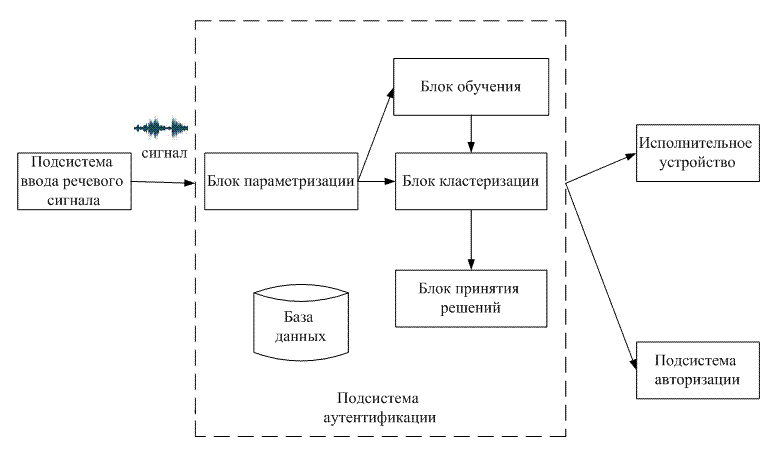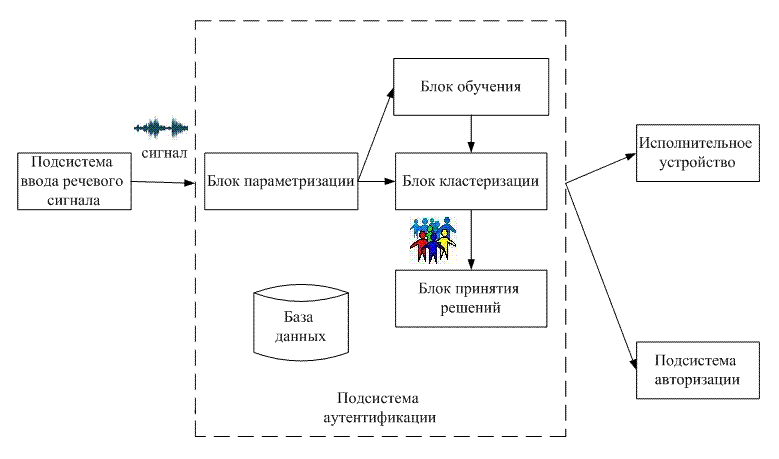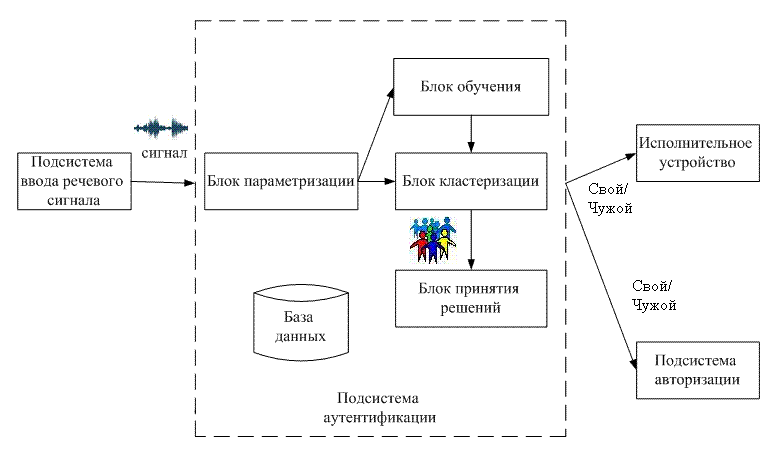
Рисунок 6.2 – Представление голосового тракта ввиде последовательности труб Заметим, что коэффициенты отражения определяют соотношение площадей соседних секций. Таким образом, площади поперечного сечения не определяются абсолютно точно, но все-таки эти площади часто бывают сходными с конфигурацией голосового тракта, используемого человеком при речеобразовании. 7 ВЫБОР СТРУКТУРЫ КОМПЬЮТЕРИЗИРОВАННОЙ СИСТЕМЫ КОНТРОЛЯ ДОСТУПА С ИСПОЛЬЗОВАНИЕМ АУТЕНТИФИКАЦИИ ПО ГОЛОСУ Структура компьютеризированной системы контроля доступа с использованием аутентификации по голосу представлена на рис. 7.1.
Рисунок 7.1 – Структура компьютеризированной системы контроля доступа с использованием аутентификации по голосу (анимация: объем – 51 765 байт; размер – 779х459; состоит из 4 кадров; задержка между последним и первым кадрами – 1 500 мс; задержка между кадрами – 800 мс; цикл повторения – непрерывный) Данная система состоит из двух основных подсистем: подсистемы ввода речевого сигнала и подсистемы аутентификации. Первая расположена на стороне клиента и обеспечивает ввод речевого сообщения пользователя через микрофон, которое записывается в файл .wav с форматом аудио PCM, 22050 кГц, 16 бит, моно. Сформированный сигнал из этой подсистемы направляется на серверную подсистему аутентификации, которая состоит из базы данных, блока параметризации, обучения, кластеризации и принятия решений. В блоке параметризации происходит выделение признаков, характеризующих личность диктора. Блок кластеризации использует данные блока обучения и текущий параметризованный сигнал. На основе данных классификации и порогового значения блок принятия решения формирует решение: диктор свой или чужой. Сформированный результат поступает (в зависимости от конкретных задач) или на исполнительное устройство, или в подсистему авторизации. 8 ПЛАНИРУЕМЫЕ ПРАКТИЧЕСКИЕ РЕЗУЛЬТАТЫ После анализа уникальных индивидуальных признаков, характеризующих личность диктора, а также методов классификации дикторов, на основании практических результатов исследований выберем те признаки (в сочетании с определенным эффективным классификатором), которые будут иметь наилучшие показатели, т.е. наименьшие ошибки первого и второго рода. При этом скорость аутентификации должна быть не более 30 сек. Далее планируется разработка обеспечивающей части данной компьютеризированной системы с использованием наиболее эффективного признака или их комбинации и выбранного метода классификации. Потом будет проведено тестирование системы и необходимая отладка. ЗАКЛЮЧЕНИЕ В ходе выполнения научно-исследовательской работы были проанализированы существующие компьютеризированные системы контроля доступа с использованием аутентификации по голосу и выявлены их недостатки. Проанализировавав уникальные индивидуальные признаки, характеризующие личность говорящего, выбрали те признаки, которые просты в измерении и дают представление об особенностях речи конкретного диктора. Также предложена структура компьютеризированной системы контроля доступа с использованием аутентификации по голосу. СПИСОК ЛИТЕРАТУРЫ
При написании данного автореферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2010 г. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты. © ДонНТУ 2010, Кулибаба О.В. |
|||||||||||

|
ДонНТУ >>
Портал магистров ДонНТУ Автобиография| Реферат| Библиотека| Ссылки| Отчет о поиске| Индивидуальное задание |
||||||||||