
Вступ
Більше 40 років розвитку систем візуалізації, особливо, систем реального часу, привели до значної розмаїтості як алгоритмічних, так і архітектурних рішень. Реалізації графічних систем можна порівнювати по комплексному показнику - відношенню якості отриманого зображення до апаратурної складності системи, тобто її вартості. Сучасні графічні системи, дозволяють для кожного конкретного застосування формувати свою архітектуру системи. Графічні апаратні й програмні системи є високопродуктивними й, у той же час, досить дорогими. У зв'язку із цим актуальним завданням на сучасному етапі є правильний вибір конфігурації системи, тобто досягнення необхідної якості шляхом мінімальних витрат.
Метою роботи є дослідження та аналіз ефективної оптимізації алгоритму трасировки променів, при яких зменшиться остаточна вартість графічного пристрою для трасировки сцени через зменшення остаточної кількості GPU та збільшиться швидкість синтезу зображення.
Наукова значимість
Розробка прискореної системи синтезу фото реалістичних зображень за допомогою впровадження інтерполяції пікселей.
Алгоритм трасування променів
Метод трасування променів забезпечує генерацію зображень фотографічної якості. Вважається, що метод трасування променів дає найбільший можливий ступінь реалізму. При побудові зображення промінь посилається в заданому напрямку для оцінки прихожої відтіля світлової енергії. Ця енергія визначається освітленістю першої поверхні, що зустрілася на шляху. Механізм виникнення освітленості наступний.
Кожне джерело світла випускає промені у всіх напрямках. Потрапляючи на поверхню, промінь частково переломлюється, частково відбивається і частково розсіюється. Проходячи через прозорий матеріал, промінь перетерплює природне ослаблення.
Розрізняють пряме і зворотне трасування променів.
Пряме трасування променів дуже неефективне через те, що початкова точка променю – джерело світла.
При зворотному трасуванні променів відслідковуються тільки промені, що попадають в око спостерігача. Це виконується в такий спосіб. З ока спостерігача через кожен піксель екранної площини в синтезовану сцену пропускається промінь, і потім він відслідковується в зворотному напрямку. Коли промінь наштовхується на поверхню, інтенсивність відповідного пик села визначається освітленістю найближчої крапки перетинання променя з поверхнею. Як що на шляху променя не виникає ніякого об'єкта, варто брати освітленість навколишнього простору (неба чи землі спеціально спроектованої однорідної моделі поверхні)(рисунок 1).
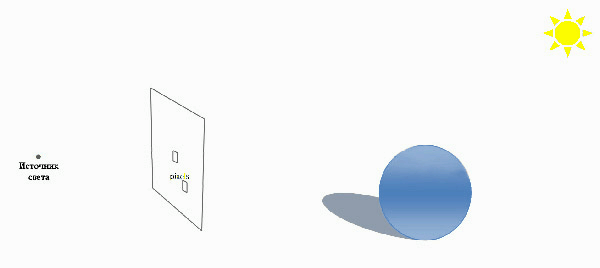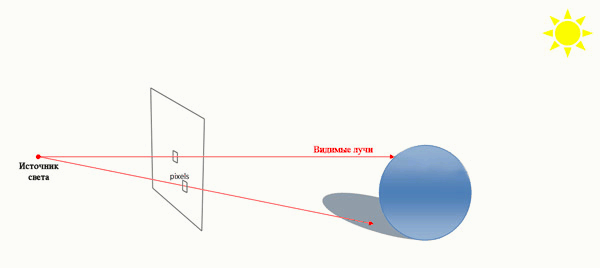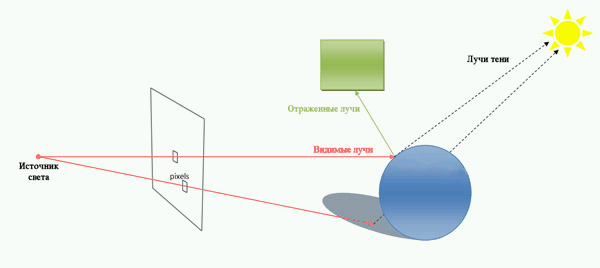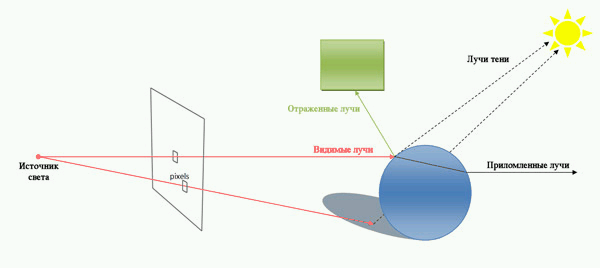
Рисунок 1 - Алгоритм трасировки променів (анімація, 7 кадрів, 79КБ)
В алгоритмі використовуються нескладні математичні співвідношення. При цьому обчислення на етапах геометричних перетворень, розрахунку параметрів освітленості і растрування виконуються одночасно, однак, це вимагає значних витрат часу, що до недавнього часу не дозволяло використовувати його як метод синтезуючих ГСРЧ.
Розробка алгоритмів міжпікселної інтерполяції для прискорення алгоритму трасування променів.
Для оптимізації алгоритму трасування променів можливо:
- прискорити аналіз перетинання лучачи/об'єкта;
- розпаралелити частину завдань.
Тому що для більшості задач швидкість рендеру набагато важливіше, ніж коректність відображення картинки, для прискорення роботи алгоритму Ray-Tracing у його структуру вносилися ряд різні модифікації.
Звичайно, збільшення частоти генерації кадрів досягалося за рахунок зниження якості картинки при русі камери й об'єктів.
Очевидно, що суміжні пікселі трасуємого зображення мають приблизно той самий колір. На практиці, сцена середньої завантаженості, має близько 70% піксельних сегментів (області пікселей, які розрізняються по кольорі менш чим на 1 % (Рисунок 2) і приблизно тільки 8% крайніх областей (області пікселей, які розрізняються по кольорі більш ніж на 25 %). Ці дані наведені для того, щоб показати - більша частина часу витрачена на обробку пікселей із приблизно однаковим кольором (рисунок 2). Ідея й полягати в зміні цієї ситуації.
![]()
Рисунок 2 - Рядкова піксельна інтерполяція
Хоча довжина сегмента на практиці може мінятися, найчастіше, вона становить 4-6 пікселей, тому застосування складних методів інтерполяції не доцільно й у цій роботі обчислення кольору внутрішніх пікселей буде виконуватися по формулі 1:
Pinner = (Pleft + Pright )/2 (1)
Основна перевага даного підходу складається в простоті й високій ефективності. Але тепер встає питання - як визначити місцезнаходження сегментів. Класичний алгоритм трасування променів простежує кожний піксель площини незалежно, отже, якщо немає попередньої інформації, те не можна гарантовано точно виділити однорідні сегменти пікселей.
Таким чином, основна ідея модифікації алгоритму трасування полягає в наступному:
- трасувати менше пікселей, чим їхня загальна кількість, що визначається дозволом зображення;
- для одержання значення непростежених пікселей застосовується механізм інтерполяції;
- для одержання бажаної якості рендерингу, використовується крок трасування й коефіцієнт максимального розходження в кольорі крайніх пікселей;
- при неефективності трасування коректується її крок.
Інтерполяція — в обчислювальній математиці спосіб знаходження проміжних значень величини за наявним дискретному наборі відомих значень.
Блокова міжпіксельна інтерполяція
Уведемо угоди за структурою апаратного забезпечення:
- кожному пікселю зображення призначають свій процесорний елемент (PE) (можливо віртуальний);
- два суміжних PE обчислюють крайні пікселі одного сегмента;
- у кожного PE є ідентифікатор, що змінюється в межах від 0 до Nmax;
- всі процесорні елементи мають ідентичну структуру.
Розглянемо зображення 1024 на 1024 пікселей, і припустимо, що кожному пікселю призначався свій процесорний елемент. Виходить величезне число процесорів (1 058 576). Що зовсім не прийнятно. Таким чином, застосування вищезгаданого методу, взявши блоки 4х4 повністю обґрунтовано.
Саме оптимальне рішення є інтерполювати не рядка, а блоки розміром 4 на 4 пікселя (рисунок 3).
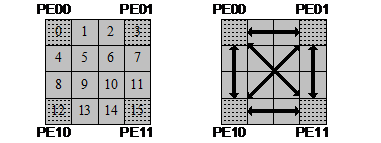
Рисунок 3 - Блокова піксельна інтерполяція 4 на 4 пікселя
То есть, трассировка выполняется только для 4 пикселей, которые находятся в углах блока. Значение других пикселей получаем с помощью интерполяции по формуле 1.
Тобто, трасування виконується тільки для 4 пікселей, що перебувають у кутах блоку. Значення інших пікселей одержуємо за допомогою інтерполяції по формулі 1.
Таким чином, підвищується продуктивність у порівнянні з простим алгоритмом трасування променів.
Практична цінність
Збільшення продуктивності системи відбуватися за рахунок апаратних витрат.
Загальна кількість процесорів для блокової інтерполяції може бути розраховане як:
PE_блокова_інтерполяція = (int [( n-1) / (k+1)] +1) ^ 2
Для картинки 1024 на 1024 пікселя, трасуємої блоками 4х4 пікселя:
PE_блокова_інтерполяція = ([( 1024-1) / (2+1)]+1 ) 2 = 116 964
Зменшення кількості процесорів склало близько 7 разів. Так само варто помітити, що інтерполяції в кожному блоці піддавалися тільки по два внутрішніх пікселя, на підставі чого можна сказати, що практично вся інтерполяція була успішною.
Сьогодні технологія трасування променів застосовується через трудомісткість тільки корпораціями, підрозділами, що спеціалізуються на створенні спец ефектів для кінофільмів, на створенні мультиплікаційних фільмів. Так само ця технологія досить поширена в сфері роботи із тривимірною графікою, де потрібно тільки синтезувати один кадр, технологія використовується для одержання високоякісних зображень у програмнім забезпеченні, такому як Maya, 3D Max, Autodesk.
В останні роки дуже далеко вперед ступнули графічні процесори виробництва nvidia і AMD. Сьогодні навіть бюджетні графічні рішення цих двох гігантів мають від 100 графічних незалежних блоків, які дозволяють швидко(паралельно) обробляти дані. Ці графічні процесори в багато разів швидше справляються із завданнями, пов'язаними з обчисленнями й форматом чисел QFLOAT (4х точні числа)(рисунок 4).
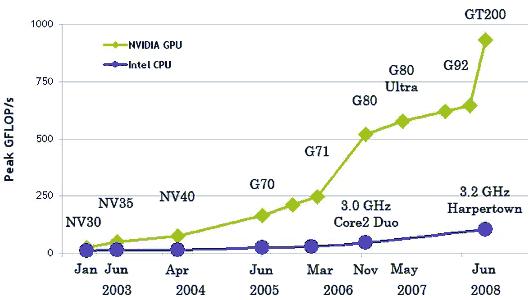
Рисунок 4 - Порівняння швідкостей GPU CPU
Сьогодні nvidia і AMD вже показали API власних движків графічного рендеру, заснованого на методі трасування променів, так що в найближчому майбутньому варто очікувати появи комп'ютерних ігор, у яких за візуалізацію буде відповідати алгоритм трасування променів, що суттєво вплине в кращу сторону на якості 3D комп'ютерної графіки.
У рамках магістерської роботи була розроблена програмна модель (рисунок 5), яка реалізує алгоритм трасування променів, підтримує алгоритми тіней, часткового затінення, власного затінення, відбиттів, розсіювання, відблисків, згладжування.
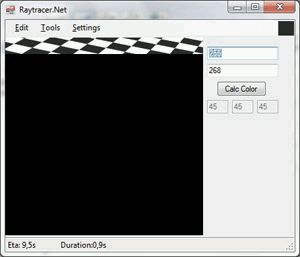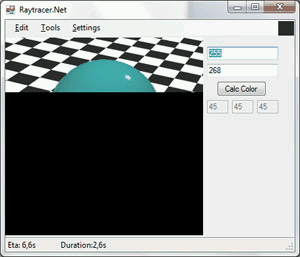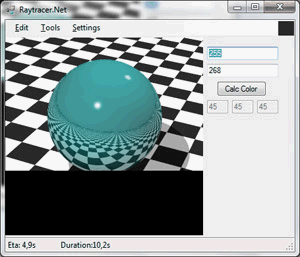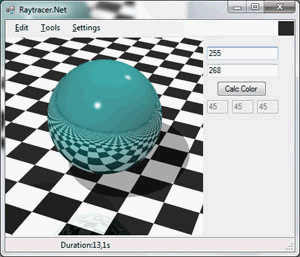
Рисунок 5 - Програмна реалізація методу трасування променів (анімація, 5 кадрів, 150КБ)
Огляд досліджень по темі в ДонНТУ
В ДонНТУ тему ускорения алгоритма трассировки лучей рассматривает Иванова Екатерина Владимировна. У ДонНТУ тему прискорення алгоритму трасування променів розглядаєІванова Катерина Володимирівна.
Огляд досліджень по темі в Україні
Нажаль, у Україні в жодному ВНЗ тема прискорення алгоритму трасування променів не розглядалася.
Огляд досліджень по темі у світі
Методами оптимізації й прискорення алгоритму трасування променів для одержання фото реалістичних зображень займаються світові відомі компанії, які спеціалізуються на розробці візуальних ефектів, створенню мультфільмів (PIXAR), компанії, які спеціалізуються на розробці апаратного забезпечення для ПК (INTEL, nVidia, AMD), компанії, які спеціалізуються на розробці спеціалізованого комп'ютерного встаткування (Caustic, Splutterfish).
Через те, що метод трасування променів дуже вимогливий до апаратної складової, навіть світовий лідер по створенню візуальних мультфільмів PIXAR використовує метод не всіх розробок, щоб не перевантажити існуючі обчислювальні потужності. Таку саму ситуацію іспитує компанія Lucas Arts..
INTEL передбачує використання інструкцій пакетної обробки даних SSE 1,2,3,4,5+ для прискорення роботи з набором(пакетом) інформації (векторів).
Трасування променів по своїй сутності винятково вдало підходить для паралельних обчислень. Для розрахунку окремих променів не використовуються загальні дані, тому промені можуть рендеритися в довільному порядку. Це означає, що алгоритм трасування променів теоретично може використовувати переваги сучасних процесорних технологій. При тому, що більшість додатків можуть лише частково виконуватися в паралельному режимі, трасування променів порівняно легко адаптується до таких технологій паралельної обробки даних, як SIMD, Hyper-Threading та багатоядерних процесорів.
Використання технології SIMD для методу трасування променів трохи проблематично. Алгоритм трасування променів стає залежним від пропускної здатності пам'яті, оскільки кожний промінь розраховується як минаючий через деяку просторову структуру й перевіряється на предмет перетинання з декількома примітивами для визначення найближчої крапки перетинання.
nVidia пішла своїм шляхом. Тому що корпорація спеціалізується на виконанні потужних відео чипів, побудованих на конвеєрній структурі із численною кількістю паралельно працюючих блоків (високопродуктивна серія чипів Geforce FX), які виконують операції над окремими пікселями й трикутниками, тобто фактично вхідними даними для цих блоків є набір векторів, а формат чисел – QFLOAT (128 біт), був створений движок OptiX Engine. Движок заснований на використанні технології CUDA, мови HLSL (мова так званих шейдерів, мікропрограм для обчислювальних блоків), яка дозволяє розпаралелювати обчислення на одному графічному чипі, ґрунтуючись на конвеєрній структурі з паралельно працюючими обчислювальними блоками. Для порівняння, якщо програмний метод рендеру сцени займає кілька хвилин, те апаратний (з використанням рішень nVidia / CUDA / OptiX) займає значно менший час.
Аналогічною розробкою може похвастатися й AMD. Їхня розробка називається AMD Cinema 2.0. Базовою платформою для цієї розробки є движок OTOY (продукт співробітництва AMD, Otoy, Lightscape). «Cinema 2.0» є засобом, що забезпечують розрахунок трасування променів у реальному часі на графічних процесорах Radeon (серії чипів v7x0, v8x0, старші моделі цих чипів мають обчислювальну потужність порядку 1 TFLOP при роботі із числами формату QFLOAT) і центральних процесорах AMD Phenom.
Корпорація Caustic надала готовий OpenGL і GLSL API, багатоплатформенний OpenRL SDK, який став стандартом для розробки комплексних рішень із використанням синтезу зображень за допомогою технології трасування променів. Також Coustic надала перше у світі, вузьконаправленне апаратне рішення CausticONE, яке дозволяє синтезувати зображення з використанням набору бібліотек Openrl до 20 раз швидше, чим сучасні GPU і CPU.
Splutterfish розробила свою систему рендеру зображення Brazil r/s (Brazil Rendering System). Brazil r/s основний продукт SplutterFish, реалізований як плагін до AutoDesk, 3ds Max, Rhinoceros, Autodesk Maya, і як окремий модуль standalone. На комерційній основі в цей час доступна тільки версія для 3ds Max, у той час як Rhino 3D версія доступна у відкритому бета тестування через McNeel and Associates. Brazil r/s— це рей-трейсерний рендер, у якому є присутнім кілька алгоритмів прорахунку глобального висвітлення Global Illumination: QMC і Photon Mapping. Цю систему використовувала компанія Lucas Arts при створенні ефектів до кінофільму «Зоряні війни 3».
ВИСНОВОК
Усі вищеописані продукти компаній nVidia, AMD, INTEL, Caustic, Splutterfish у синтезі фінальної графічної сцени використовують усі пікселі, не враховуючи того, що фон може бути однорідним, заливання може мати той самий колір, тобто використовують якусь частину ресурсів у холосту, для розрахунку того самого кольору, для розрахунку кольору, що відрізняється від поруч вартих на коефіцієнт SI, коефіцієнт погрішності кольору сприймання ока людини.
Що б прискорити трудомісткий алгоритм трасування променів, потрібно впровадити алгоритм блокової інтерполяції, втрати в кольорі в результуючім зображенні мінімальні, так само застосувавши фільтр при обчисленні кольору внутріблокових пікселей у випадку, коли верхні пікселі дуже сильно відрізняються від нижніх кольором, можна розв'язати проблему анті аліасінгу.
Як видне із прикладу розрахунку КПД алгоритму із застосуванням блокової інтерполяції, для зображення розміром 1024х1024 пікселей потрібно приблизно в сім раз менше апаратних блоків, прискорення рендеру сцени досягає значення 4-5 разів, що обумовлене не достатнім швидким доступом до пам'яті у виді того, що використовувані значення кольорів пікселей лежать у різних комірках пам'яті, потрібен перерахунок адреси пам'яті.
Отже, завдяки блоковій межпіксельній інтерполяції можна досягти великої економії на процесорних елементах при розробці графічної системи, базованої на алгоритмі трасировки променів.
Список использованной литературы
- Malcheva R.V. The problems of modeling and rendering of the realistic complex scenes / R.V. Malcheva, S. Kovalov, U. Korotin // Сборник трудов VII МНТК «Машиностроение и техносфера XXI века. – Донецк: ДонГТУ, 2000. - С.308-310.
- Malcheva R.V. The problems of modeling and rendering of the realistic complex scenes / R.V. Malcheva // Proceedings of ECCPM 2002. - Portoroz, 2002. - PP.537-538.
- Серёженко А.А. Оптимизация метода трассировки лучей / А.А. Серёженко // Збірка матеріалів п’ятої міжнародної науково-технічної конференції студентів, аспірантів та молодих науковців. – Донецк: ДонНТУ, Т2, 2009 - с. 71-74.
- Роджерс Д. Математические основы машинной графики. Пер. с англ. / Д. Роджерс, Дж. Адамс / Под ред. Ю.И.Топчеева.- М.: Машиностроение,1980 234 с.
- Эгрон Ж. Синтез изображений. Базовые алгоритмы. / Ж. Эгрон. - М.: Радио и связь. - 1993. - 216 с.
- Корреган Д. Компьютерная графика. Секреты и решения. / Д. Корреган - М., 1995 - 345 с.
- Шикин Е.В. Начала компьютерной графики. / Е.В.Шикин, А.В.Боресков, А.А.Зайцев. - М.: ДИАЛОГ-МИФИ. - 1993.- 138 с.
- SplutterFish: Brazil Rendering System for 3ds Max [электронный ресурс] - режим доступа - http://splutterfish.com
- Caustic Graphics - Reinventing realtime ray tracing with OpenRL SDK built on OpenGL and GLSL APIs [электронный ресурс] http://www.caustic.com/
- Cinema 2.0: The Next Chapter in the Ultimate Visual Experience - [электронный ресурс] - http://www.amd.com/us-en/Corporate/AboutAMD/0,,51_52_15438_15106,00.html?redir=cin01
- nVidia OptiX: Application Acceleration Engine - [электронный ресурс] - http://www.nvidia.com/object/optix.html Куликов А.И., Овчинникова Т.Э. Метод трассировки лучей / Интернет университет информационных технологий intuit.ru - [электронный ресурс] - http://www.intuit.ru/department/graphics/graphalg/6/5.html
- Codermind team A ray tracer in C++ - [электронный ресурс] - http://www.codermind.com/articles/Raytracer-in-C++-Introduction-What-is-ray-tracing.html
- Implementation Ray Tracing on GPU - [электронный ресурс] - http://www.clockworkcoders.com/oglsl/rt/gpurt1.htm