
Improved data distribution systems in high-loaded networks
Introduction
Each year the performance of workstations and increasing capacity of modern hardware processing provides an opportunity for a fresh look at the essence of the implementation of modern management systems and data processing. However, in industrial networks where the number of sensors and processing machinery is so great that it allows only simple elements (eg, microcontrollers) for processing the results, given the characteristics of the medium in which the system operates. There are different solution to the problem of building such networks. But for data processing, when a processing point can not handle the load, the solution lies with the model of distributed object technology. Example of realisation of data distribution is shown on figure 1. Choice of model of distributed information system largely determines the properties of the projected information system.[1]
is widely known that such a system with distributed object technology consists of a combination of hardware and software components that interact with each other. Each of these components is a hardware module that performs a specific task within a single process. In this implementation may use an object-oriented approach when building large information systems. Consequently, the components of such systems are considered at different levels of abstraction, where each object has a certain line of conduct.[2] Communication facilities, in most cases, carried out by means of some medium of interaction, which aims at messaging between objects, synchronization, synthesis of the results.[6]
Most problems are solved using distributed software systems, as well as the constraints that are used constantly facing could be understood when considering the process of evolutionary development of methods of distributed information processing. Should be aware that, despite the fact that the technology of programmers and users of their programs has changed, the problems remain the same as those that were in the past. Distributed system - a collection of independent computers (hardware nodes) representing their users a single unified system. From the end users are hidden differences between the computers and methods of communication between them. Users and applications consistently working in distributed systems, regardless of where and when is their interaction.[7] Computer system, consisting of many different computing nodes that operate very different software can be called a distributed system only if its users, it looks and behaves like a classical processor time-sharing system. To support the presentation of different computers and computer networks in a single system, the organization of distributed systems often include an additional layer of software. This level is called the level of system support (middleware). The main task of distributed software systems - to facilitate their users access to remote resources, and control the sharing of these resources.[3] Resources may be virtual, but they can be traditional - computers, printers, storage files, files and data.[8]
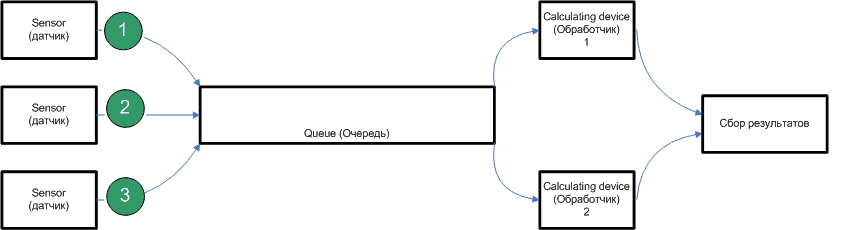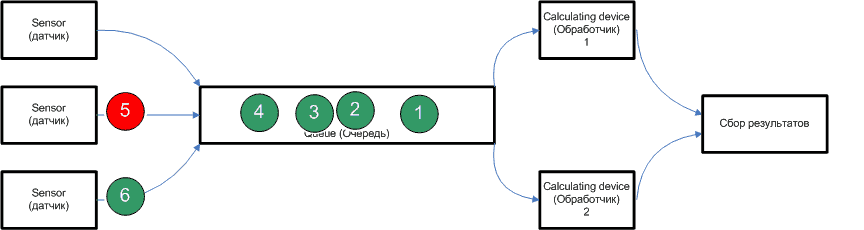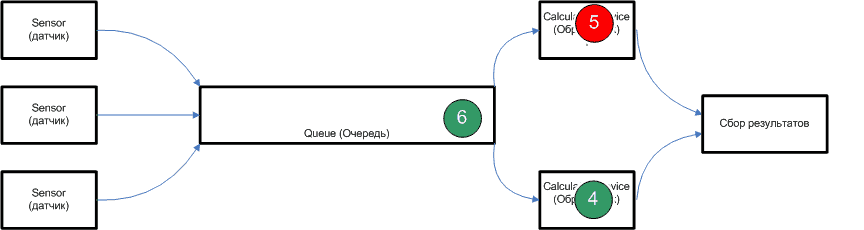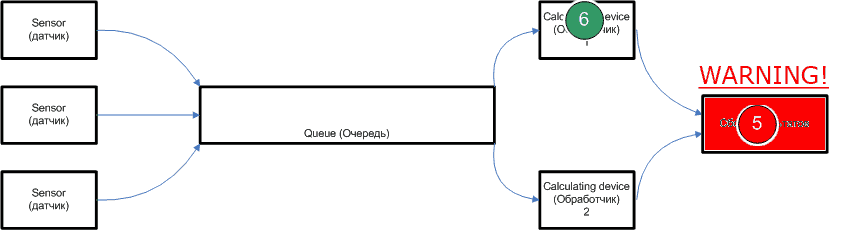
Figure 1 - Example of realisation of data distribution (animation, 14 frames, 34KB)
Aims
The purpose of this master's thesis is to increase the productivity of industrial heavy-network by improving the system of processing and distribution of data. To achieve this goal, we need to solve the following tasks:- Examine existing protocols, their features industry standards offered by developers for the design of industrial networks, as well as a review of ready solutions
- familiarize with existing algorithms for data distribution in networks, including the methods used in the DDB
- Define a set of parameters that are required to determine the effectiveness of the system as a whole
- Investigate existing algorithms that are applicable to specific industrial network
- Update optimization algorithm for data distribution, and investigate the effect of changes on system performance
Relevance select a theme
essence of the work is to build a distributed industrial network that can handle large volumes of information from various sensors and devices via distributed computing. Examples of such systems can serve as a control system of the plant, where the response time of emergency system should be minimal. For a quick response to the danger of a monitoring system should provide as much as possible faster and more efficient processing of data obtained from tracking the progress of the plant. The introduction of data distribution in highly stressed networks will reduce the reaction time. Similar systems are widely used at all stages of production, so this theme is relevant today. Alleged practical value lies in the fact that the resulting system will reduce the response time of the signal system at risk. And the shops with an increased risk for employees of the plant timely response of emergency systems (fire suppression, ventilation system, emergency stop conveyors, etc.) can save lives and health of workers.[10]
Expected own results
As a result of the work of master planned design a model of industrial networks, and accelerate the information processing system that will reduce the time the results of data processing. This system can be applied in cases where the amount of information coming to the input of the processing system, many times exceeds the capacity of a single compute node. The system will distribute the load among computing stations, thus avoiding the overflow queue for processing signals.
Conclusion
In this paper we consider the problem of data distribution in industrial networks, conducted a superficial review of existing solutions. The problem lies in the processing of large data sets obtained from different devices, sensors. The main purpose of research - to minimize the response time of the possible danger. The solution is to improve the distribution system of data between processors. As a result of the work efficiency of this method should be confirmed experimentally by constructing a model of industrial networks.
Literature
- Цегелик Г.Г. Системы распределенных баз данных. - Львов: Свит, 1990. – 168 с.
- I. Ahmad Evolutionary Algorithms for Allocating Data in Distributed Database Systems [Электронный ресурс]. Режим доступа: http://ranger.uta.edu/~iahmad/journal-papers/[J39]...
- Date C.J. What is distributed database?. - InfoDB, 1987.
- Сайты разработчиков спецификаций промышленных сетей. ARCNET Resource Center [Электронный ресурс]. Режим доступа: http://www.arcnet.com/
- Володькин И.Н. Основы проектирования промышленных сетей. - М.: Москва, 2004.
- IEC 61804-1 Function blocks (FB) for process control. - BSI, 2004
- ISA/ANSI. Standards and practices Department Procedure [Электронный ресурс]. Режим доступа: http://ieeexplore.ieee.org.
- Архипов А.С., Нагруженные сети: модели, разработка, реализация. - СПб.: Питер, 1998.
- Колесников Д.Г., Оптимизация распределения информационных файлов в сетях ЭВМ с параллельной обработкой .- Ростов-на-Дону,1999.
- Петров В.Н., Информационные системы: учебное пособие .- СПб.: Питер, 2002.