Целью исследования является изучение параллельных методов распознавания речи и разработка программной системы распознавания устной речи, функционирующей в реальном времени. Для достижения цели необходимо решить следующие задачи:
- проанализировать существующие параллельные методы распознавания речи
- проанализировать существующие технологии распараллеливания компьютерных приложений
- разработать алгоритм распознавания и выполнить его распараллеливание для SIMD-архитектуры
- разработать приложение для распознавания речи в реальном времени
Технологии распознавания речи все плотнее входят в нашу жизнь, предоставляя удобное средство управления самыми разнообразными электронными устройствами — управление голосом. К сожалению, распознавание речи — задача очень ресурсоемкая и требует высоких вычислительных мощностей, доступ к которым зачастую ограничен (например, в мобильных устройствах). Кроме того, процесс распознавания является длительным по времени, в то время, как конечные пользователи устройств ожидают быстрой реакции системы на команды.
Для ускорения вычислений можно использовать распараллеливание алгоритмов
Из всего вышесказанного следует, что исследование параллельных методов распознавания устной речи является актуальной научной проблемой.
В данной магистерской работе будут рассмотрены методы автоматического распознавания устной речи средствами технологий OpenMP и CUDA. Технология CUDA является молодой технологией и ее потенциал пока еще слабо изучен. Кроме того, исследования распараллеливания нейронных сетей на графических картах тоже являются молодыми.
В результате данной работы планируется создание программной системы, способной осуществлять распознавание речи в реальном времени. Кроме того, будет осуществлено создание библиотеки, облегчающей моделирование искусственных нейронных сетей и реализацию нейросетевых вычислений.
Исследованием методов распознавания устной речи и их реализацией на параллельных архитектурах занимаются сострудники Microsoft Research: Frank Seide, Gang Li и Dong Yu [7].
Также исследования по распознаванию речи ведут корпорации Google и Apple.
Лидер в области речевых технологий в Украине - отдел распознавания звуковых образов Международного научно-учебного центра информационных технологий и систем. С конца 1960х годов в отделе (тогда при Институте Кибернетики) под руководством Винцюка Т.К. ведутся работы по распознаванию речи [6].
В Донецке распознаванием речи занимаются в отделе распознавания языковых образов Государственного института искусственного интеллекта и в Донецком национальном техническом университете.
В ДонНТУ исследования в данной области проводят ассистент кафедры Прикладной математики и информатики Бондаренко И.Ю. и доцент кафедры Прикладной математики и информатики, кандидат технических наук Федяев О.И. [8]
Современные системы распознавания речи общего назначения в основном основаны на скрытых марковских моделях. Это статистические модели, которые выводят последовательность символов. СММ используются в распознавании речи, поскольку речевой сигнал можно рассматривать как кусочно-стационарный сигнал. На коротких временных интервалах (например, 10 миллисекунд) речь может быть аппроксимирована как стационарный процесс. Еще одна причина, во которой СММ пользуются популярностью, заключается в том, что они могут быть обучены автоматически и их использование является простым.
Подход динамической деформации времени раньше использовался повсеместно, но сейчас его вытеснили скрытые марковские модели. Динамическая деформация времени является алгоритмом для измерения сходства между двумя последовательностями, которые могут изменяться во времени или скорости. Например, сходство в движениях при ходьбе будет обнаружено даже если в одном видео человек шел медленно, а в другом быстрее, и даже если будут ускорения и замедления в ходе одного наблюдения. DTW может быть применена к видео, аудио и графике. На самом деле, любые данные, которые могут быть превращены в линейное представление могут быть проанализированы с помощью DTW. [10]
Искусственные нейронные сети (ИНС) — математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети Маккалока и Питтса. Впоследствии, после разработки алгоритмов обучения, создаваемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др.
ИНС представляют собой систему соединённых и взаимодействующих между собой простых процессоров (искусственных нейронов). Такие процессоры обычно довольно просты, особенно в сравнении с процессорами, используемыми в персональных компьютерах. Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам. И тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, такие локально простые процессоры вместе способны выполнять довольно сложные задачи.
С точки зрения машинного обучения, нейронная сеть представляет собой частный случай методов распознавания образов, дискриминантного анализа, методов кластеризации и т. п. С математической точки зрения, обучение нейронных сетей — это многопараметрическая задача нелинейной оптимизации. С точки зрения кибернетики, нейронная сеть используется в задачах адаптивного управления и как основа алгоритмов для робототехники. С точки зрения вычислительной техники и программирования, нейронная сеть — способ эффективного распараллеливания задач. А с точки зрения искусственного интеллекта, ИНС является основой философского течения коннективизма и основным направлением в структурном подходе по изучению возможности построения (моделирования) естественного интеллекта с помощью компьютерных алгоритмов.
Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения — одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. Технически обучение заключается в нахождении коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными данными и выходными, а также выполнять обобщение. Это значит, что в случае успешного обучения сеть сможет вернуть верный результат на основании данных, которые отсутствовали в обучающей выборке, а также неполных и/или «зашумленных», частично искаженных данных [5].
Какие средства необходимы программисту для создания параллельной программы? Вообще говоря, ответ зависит от того, на какой класс параллельных вычислительных систем рассчитана будущая программа. Для систем с общей памятью классическим является подход, основанный на использовании потоков. Для кластеров, где каждый вычислительный узел работает под управлением собственной операционной системы, параллельной программе, представляющей собой набор процессов, требуются механизмы передачи данных через сеть. Для систем, имеющих мощные графические чипы, идеальным вариантом будет GPGPU. Гибридные системы – кластеры с SMP-узлами и графическими картами – заставляют искать компромисс между относительной простотой создания параллельной программы только на основе процессов (приносим в жертву скорость обмена данными между ними), или использованием и процессов, и потоков, и GPGPU сразу (выигрываем в производительности на каждом узле, но тратим существенно больше усилий на этапе разработки).
В каждом из рассмотренных выше случаев разработчику не обойтись без поддержки со стороны операционной системы, которая должна предоставить необходимый API для работы с потоками, примитивы синхронизации, механизмы для обмена данными между процессами, исполняющимися как на одном вычислительном узле, так и на разных, как на процессорах, так и на видеочипах. Тем не менее, несмотря на то, что такая поддержка существует – наиболее распространенные операционные системы (в частности семейств Windows и Linux) имеют вполне достаточный уровень реализации всех необходимых механизмов – разработка параллельной программы только с их помощью – занятие, сравнимое по сложности с написанием последовательной программы на ассемблере. Следствием описанных обстоятельств стало появление как отдельных инструментов, поддерживающих процесс создания параллельных программ, начиная от отладчиков и сборщиков трасс выполнения и заканчивая предсказателями ожидаемой эффективности, так и специальных технологий разработки, предлагающих поддержку либо в виде библиотек функций (подход MPI), либо на уровне компилятора (подход OpenMP), либо на уровне драйверов (CUDA, OpenCL, GLSL).
При всем богатстве выбора существующих и создающихся вновь средств разработки параллельных программ, начиная от языков программирования и заканчивая библиотеками, предлагающими готовые реализации типовых вычислительных задач, реальных альтернатив на сегодняшний момент довольно немного, и каждой из них присущи свои ограничения.
Наиболее общим способом создания параллельных программ для систем с общей памятью является использование потоков. При этом функциональный параллелизм легко обеспечивается написанием разных потоковых функций, а параллелизм по данным реализуется благодаря общему виртуальному адресному пространству процесса, к которому все потоки имеют доступ. Работать с потоками программист может, как используя API операционной системы, так и создав собственную библиотеку потоков. Последний подход в ряде случаев может обеспечить большее быстродействие программы за счет меньших накладных расходов, но значительно более трудоемок. Разработка параллельной программы на основе потоков, в особенности в случае параллелизма по данным, предполагает решение задачи синхронизации и преодоление ряда возможных проблем: взаимной блокировки, тупиков, гонок данных и т.д. Целью при этом является получение корректных результатов выполняемых вычислений, например, недопущение чтения из оперативной памяти порции данных одним потоком в тот момент, когда другой поток осуществляет запись этих данных.
Операционные системы предоставляют необходимые средства для решения всех задач, возникающих в многопоточном программировании: критические секции, признаки блокировки, семафоры, мьютексы, события и т.д. Однако грамотное использование этих механизмов требует существенных усилий, поскольку отсутствие необходимой синхронизации доступа к данным влечет за собой, как минимум, неверные результаты, а в худшем случае приводит к аварийному завершению программы. В то же время, чрезмерная синхронизация ведет к снижению эффективности и масштабируемости параллельной программы.
Задачи, которые должен решить программист, разрабатывающий параллельную программу для системы с общей памятью, во многих случаях идентичны, а значит, их реализацию можно переложить на компилятор, что и предлагает стандарт OpenMP, специфицирующий набор директив компилятора (для языков C, C++ и Fortran), функций библиотеки (для тех же языков) и переменных окружения. OpenMP можно рассматривать как высокоуровневую надстройку над POSIX или Windows Threads (или аналогичными библиотеками потоков).
В настоящий момент существуют реализации стандарта OpenMP в компиляторах от многих производителей.
Преимуществами OpenMP являются:
- Простота использования – разработчик не создает новую параллельную программу, а добавляет в текст последовательной программы необходимые директивы и, возможно, вызовы библиотечных функций, указывающие компилятору способы распределения вычислений и данных между потоками, а также доступа к ним. Главной идеей OpenMP является распараллеливание циклов, обычно несущих основную вычислительную нагрузку.
- Гибкость – OpenMP предоставляет разработчику достаточно большие возможности контроля над поведением параллельной программы.
- Повторное использование – OpenMP-программа во многих случаях может быть использована как обычная последовательная, если необходимо обеспечить ее выполнение на однопроцессорной платформе. При этом, чтобы избавиться от реализации OpenMP в исполняемом модуле, достаточно пересобрать его последовательным компилятором. Директивы OpenMP будут проигнорированы, а вызовы функций библиотеки могут быть заменены на заглушки, текст которых приведен в спецификациях стандарта.
Создание параллельных программ с использованием стандарта OpenMP и соответствующих компиляторов во многих случаях дает не меньшую эффективность, чем программирование в потоках, и требует существенно меньше усилий от разработчика, однако OpenMP работает только в SMP-системах.
Параллельное программирование для систем с распределенной памятью (кластеров) не имеет в достаточной степени высокоуровневой (наподобие потоков) поддержки в операционных системах. Прямую работу с сокетами для реализации обмена данными между процессами параллельной программы не отнесешь к удобным подходам.
Стандарт MPI предоставляет механизм построения параллельных программ в модели обмена сообщениями, характерной для разработки программ, ориентированных на кластерные системы. Стандарт специфицирует набор функций и вводит определенный уровень абстракций на основе сообщений, типов, групп и коммуникаторов, виртуальных топологий. Существуют стандартные “привязки” MPI к языкам С, С++, Fortran. Реализации стандарта MPI имеются практически для всех суперкомпьютерных платформ, а также кластеров на основе рабочих станций UNIX\Linux и Windows. В настоящее время MPI – наиболее широко используемый и динамично развивающийся интерфейс из своего класса.
К положительным моментам MPI можно отнести:
- Переносимость – MPI позволяет в значительной степени снизить остроту проблемы переносимости параллельных программ между разными компьютерными системами – параллельная программа, разработанная на алгоритмическом языке C или Fortran с использованием библиотеки MPI, как правило, будет работать на любых вычислительных платформах, для которых имеется реализация стандарта.
- Повышение эффективности – MPI содействует повышению эффективности параллельных вычислений, поскольку в настоящее время практически для каждого типа вычислительных систем существуют реализации стандарта, в максимальной степени учитывающие возможности используемого компьютерного оборудования.
Основным подходом к построению MPI-программ является явное распределение данных и вычислений между процессами, а также обмен сообщениями для передачи данных, в силу чего MPI-программа часто существенно отличается от программы последовательной, а в некоторых случаях даже не может выполняться в однопроцессном варианте. И конечно, создание и отладка MPI-программ требует значительно больших усилий, чем создание последовательной программы, решающей ту же задачу.
Вычисления на GPU или GPGPU (General-purpose computing on graphics processing units, графические вычисления общего назначения) заключаются в использовании GPU (графического процессора) для универсальных вычислений в области науки и проектирования.
GPU вычисления представлены совместным использованием CPU и GPU в гетерогенной модели вычислений. Стандартная часть приложения выполняется на CPU, а более требовательная к вычислениям часть обрабатывается с GPU ускорением. С точки зрения пользователя приложение работает быстрее, потому что оно использует высокую производительность GPU для повышения производительности.
История графических чипов началась с графических конвейеров с фиксированной функциональностью. Постепенно их программируемость все возрастала, и, в конце концов, nVidia представила первый GPU, или графический процессор. В 1999-2000 годах специалисты в компьютерной области и научные работники в таких сферах, как получение медицинских изображений и электромагнетизм, перешли на GPU для вычислительных приложений общего назначения. Они обнаружили, что высокая производительность вычислений с плавающей точкой графических процессоров значительно ускоряла работу научных приложений. Это стало началом мощного движения, называющегося GPGPU или вычисления общего назначения на GPU.
В настоящее время, самыми распространенными технологиями GPGPU являются шейдерный язык GLSL и технологии CUDA и OpenCL.
GLSL (OpenGL Shading Language, шейдерный язык OpenGL), также известный как GLslang, является высокоуровневым шейдерным языком, основанном на языке программирования Си. Он был создан OpenGL ARB, чтобы дать разработчикам более прямой контроль видеокарты без использования ассемблера или аппаратно-зависимых языков.
Шейдеры на GLSL, суть - просто куски С-подобного кода, компилируемого драйвером на этапе выполнения в байткод и передаваемые на GPU для выполнения. Важный момент: GLSL допускает использование процедур и понимает циклы (особенно в развернутом виде), но отрицает рекурсию (сказывается отсутствие стека).
Достоинства GLSL:
- кроссплатформенная совместимость на нескольких операционных системах, включая GNU/Linux, Windows, MacOS.
- шейдерные программы могут быть использованы на любой карте, поддерживающей GLSL.
- каждый поставщик оборудования включает поддержку этого языка в драйвера своих устройств, что позволяет создавать код, оптимизированный под любую архитектуру.
В 2006-2007 компания NVIDIA произвела революцию в GPGPU и ускорила вычисления благодаря новой архитектуре массивно параллельных вычислений CUDA. Архитектура CUDA состоит из сотен процессорных ядер, которые работают в связке, чтобы разом справится с набором данных в приложении.
CUDA (Compute Unified Device Architecture) — программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU. Архитектура CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения — G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, Quadro и Tesla.
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах NVIDIA и включать специальные функции в текст программы на Cи. CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью, организовывать на нём сложные параллельные вычисления.
Первоначальная версия CUDA SDK была представлена 15 февраля 2007 года. В основе CUDA API лежит язык Си с некоторыми ограничениями. Для успешной трансляции кода на этом языке, в состав CUDA SDK входит собственный Си-компилятор командной строки nvcc компании Nvidia. Компилятор nvcc создан на основе открытого компилятора Open64 и предназначен для трансляции host-кода (главного, управляющего кода) и device-кода (аппаратного кода) (файлов с расширением .cu) в объектные файлы, пригодные в процессе сборки конечной программы или библиотеки в любой среде программирования, например в NetBeans.
Использует grid-модель памяти, кластерное моделирование потоков и SIMD инструкции. Применим в основном для высокопроизводительных графических вычислений и разработок NVIDIA-совместимого графического API. Включена возможность подключения к приложениям, использующим OpenGL и Microsoft Direct3D 9. Создан в версиях для Linux, Mac OS X, Windows.
Преимущества
По сравнению с традиционным подходом к организации вычислений общего назначения посредством возможностей графических API, у архитектуры CUDA отмечают следующие преимущества в этой области:
- Интерфейс программирования приложений основан на стандартном языке программирования Си с некоторыми ограничениями. По мнению разработчиков, это должно упростить и сгладить процесс изучения архитектуры CUDA.
- Разделяемая между потоками память (shared memory) размером в 16 Кб может быть использована под организованный пользователем кэш с более широкой полосой пропускания, чем при выборке из обычных текстур
- Более эффективные транзакции между памятью центрального процессора и видеопамятью
- Полная аппаратная поддержка целочисленных и побитовых операций
Ограничения
- Все функции, выполнимые на устройстве, не поддерживают рекурсии (в версии CUDA Toolkit 3.1 поддерживает указатели и рекурсию) и имеют некоторые другие ограничения
- Архитектуру CUDA поддерживает и развивает только производитель Nvidia
OpenCL (от англ. Open Computing Language — открытый язык вычислений) — фреймворк для написания компьютерных программ, связанных с параллельными вычислениями на различных графических (англ. GPU) и центральных процессорах (англ. CPU). В фреймворк OpenCL входят язык программирования, который базируется на стандарте C99, и интерфейс программирования приложений (англ. API). OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. OpenCL является полностью открытым стандартом, его использование не облагается лицензионными отчислениями.
Цель OpenCL состоит в том, чтобы дополнить OpenGL и OpenAL, которые являются открытыми отраслевыми стандартами для трёхмерной компьютерной графики и звука, пользуясь возможностями GPU. OpenCL разрабатывается и поддерживается некоммерческим консорциумом Khronos Group, в который входят много крупных компаний, включая Apple, AMD, Intel, NVidia, ARM, Sun Microsystems, Sony Computer Entertainment и другие.
Преимущества:
- Работает на любом оборудовании
Недостатки:
- Более низкая, по сравнению с CUDA, скорость вычисления
- Отсутствие поддержки указателей на функции, рекурсии, битовых полей, массивов переменной длины (VLA), стандартных заголовочных файлов
Распознавание речи в данной работе мы будем проводить с помощью искусственных нейронных сетей. Данный выбор обусловлен:
- хорошей способностью нейросетей к обучению и самообучению,
- их высоким естественным параллелизмом.
Распараллеливание будет производиться посредством технологий OpenMP и CUDA. Технология OpenMP была выбрана благодаря простоте ее использования, а также из-за широкой распространенности многоядерных процессоров. Технология CUDA выбрана из-за способности обеспечить высокую скорость вычислений.
Распознавание речи – это многоуровневая задача распознавания образов, в которой акустические сигналы анализируются и структурируются в иерархию структурных элементов (например, фонем), слов, фраз и предложений [4]. Каждый уровень иерархии может предусматривать некоторые временные константы, например, возможные последовательности слов или известные виды произношения, которые позволяют уменьшить количество ошибок распознавания на более низком уровне. Чем большим количеством априорной информации о входном сигнале мы располагаем, тем качественнее можем его обработать и распознать.
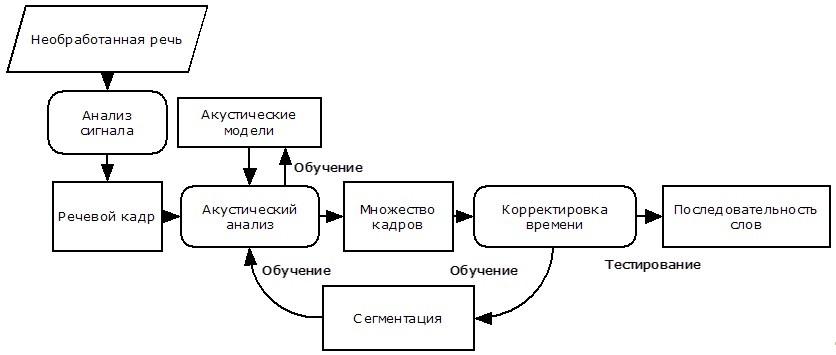
Рис. 1 – Структура системы распознавания речи
Структура стандартной системы распознавания речи показана на рисунке [3]. Рассмотрим основные элементы этой системы.
Необработанная речь. Обычно, поток звуковых данных, записанный с высокой дискретизацией (16 КГц при записи с микрофона либо 8 КГц при записи с телефонной линии).
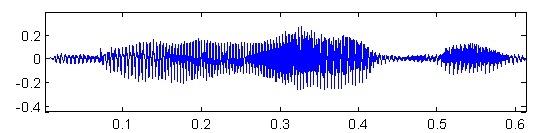
Рис. 2 – Необработанный речевой сигнал (ось X - время, ось Y - амплитуда сигнала)
Анализ сигнала. Поступающий сигнал должен быть трансформирован и сжат для облегчения последующей обработки. Есть различные методы для извлечения полезных параметров и сжатия исходных данных в десятки раз без потери полезной информации. Наиболее используемые методы: анализ Фурье; линейное предсказание речи; кепстральный анализ.
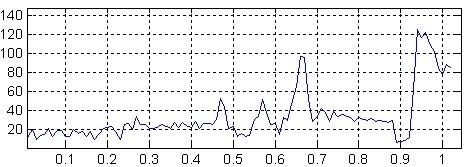
Рис. 3 – Результат спектрального анализа (ось X - частота, ось Y - мощность сигнала)
Речевые кадры. Результатом анализа сигнала является последовательность речевых кадров. Обычно, каждый речевой кадр – это результат анализа сигнала на небольшом отрезке времени (порядка 20-25 мс.), содержащий информацию об этом участке. Для улучшения качества распознавания, в кадры может быть добавлена информация о первой или второй производной значений их коэффициентов для описания динамики изменения речи.
Акустические модели. Для анализа состава речевых кадров требуется набор акустических моделей. Рассмотрим две наиболее распространенные из них. Шаблонная модель. В качестве акустической модели выступает каким-либо образом сохраненный пример распознаваемой структурной единицы (слова, команды). Вариативность распознавания такой моделью достигается путем сохранения различных вариантов произношения одного и того же элемента (множество дикторов много раз повторяют одну и ту же команду). Используется, в основном, для распознавания слов как единого целого (командные системы). Модель состояний. Каждое слово моделируется вероятностным автоматом, в котором каждое состояние представляет собой набор звуков. Этот подход используется в более масштабных системах.
Акустический анализ. Состоит в сопоставлении различных акустических моделей к каждому кадру речи. В результате образуется матрица сопоставления последовательности кадров и множества акустических моделей. Для шаблонной модели, эта матрица представляет собой набор Евклидовых расстояний между шаблонным и распознаваемым кадром (т.е. вычисляется, как сильно отличается полученный сигнал от записанного шаблона и находится шаблон, который больше всего подходит полученному сигналу). Для моделей состояний, матрица состоит из вероятностей того, что данное состояние может сгенерировать данный кадр.
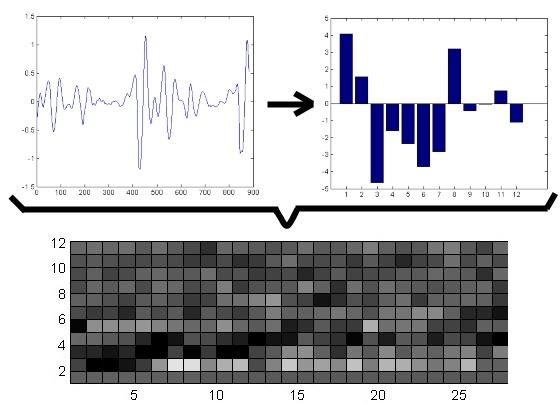
Рис. 4 – Акустический анализ (на графиках слева направо: 1) речевой кадр, ось X - время, ось Y - амплитуда; 2) акустическая модель, ось X - состояние, ось Y - амплитуда; 3) спектрально-временной образ, ось X - время, ось Y - частота, более светлые ячейки показывают большую интенсивность)
Корректировка времени. Используется для обработки временной вариативности, возникающей при произношении слов (например, “растягивание” или “съедание” звуков).
Как правило, полное описание речевого сигнал только его спектром невозможно. Наряду со спектральной информацией, необходима ещё и информация о динамике речи. Для её получения используются дельта-параметры, представляющие собой производные по времени от основных параметров.
Полученные таким образом параметры речевого сигнала считаются его первичными признаками и подаются на вход нейронной сети, на выходе которой будут соответствующие сигналу фонемы. Затем фонемы собираются в слова и предложения.
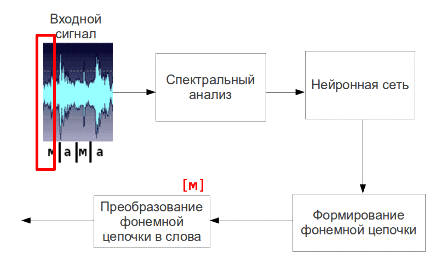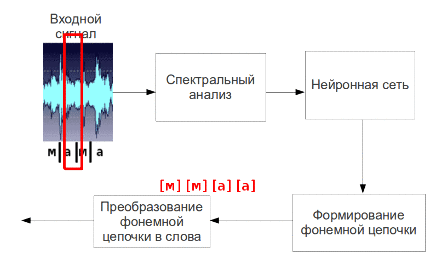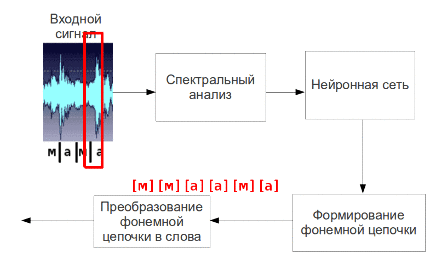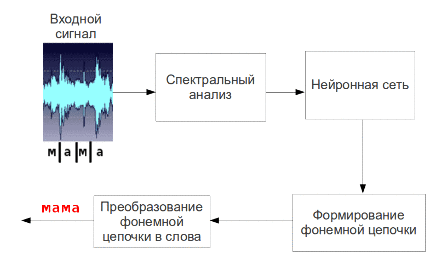
Рис. 5 – Процесс пофонемного распознавания речи (анимация: 9 кадров, 4.5 секунды, 7 повторов, объем 137.5 КБ)
В настоящий момент уже реализована библиотека для моделирования искусственных нейронных сетей, которая производит последовательные вычисления. Также выполнено ее частичное распараллеливание по технологии Nvidia CUDA [1] [9].
В работе были проанализированы существующие методы распознавания речи и технологии распараллеливания приложений. Были выбраны искусственные нейронные сети в качестве метода распознавания, а также технологии OpenMP и CUDA для увеличения быстродействия [2]. Планируется написание приложения, обеспечивающего распознавание речи в реальном времени.
- Шатохин Н. А., Реализация нейросетевых алгоритмов средствами видеокарты с помощью технологии Nvidia CUDA. // Информатика и компьютерные технологии / Материалы V международной научно-технической конференции студентов, аспирантов и молодых ученых — 24-26 ноября 2009 г., Донецк, ДонНТУ. - 2009. - 521 с.
Прочитать статью из моей библиотеки - PDF
- Шатохин Н.А., Бондаренко И.Ю. Сравнительный анализ эффективности распараллеливания нейроалгоритма распознавания речи на вычислительных архитектурах OPENMP и CUDA // Інформаційні управляючі системи та комп’ютерний моніторинг (ІУС КМ - 2011) / II Всеукраїнська науково-технічна конференція студентів, аспірантів та молодих вчених, 11-13 квітня 2011 р., м. Донецьк : зб. доп. у 3 т./ Донец. націонал. техн. ун-т; редкол.: Є.О. Башков (голова) та ін. – Донецьк: ДонНТУ, 2011. - Т.3. - 301 с.
Прочитать статью из моей библиотеки - HTML
- Фролов А., Фролов Г. Синтез и распознавание речи. Современные решения. [Электронный ресурс] — 2003. - Режим доступа: http://www.frolov-lib.ru/books/hi/index.html
- Алексеев В. Услышь меня, машина. / В. Алексеев // Компьютерра, - 1997. - №49.
- Уоссермен Ф. Нейрокомпьютерная техника: Теория и практика. - Изд. "Мир". - 1992. - 185 с.
- Винцюк Т.К. Анализ, распознавание и интерпретация речевых сигналов. - К.: Наукова Думка, - 1987. -262 с.
- Сейд Ф, Ли Г., Ю Д. Транскрипция разговорной речи с помощью контекстно-зависимой глубокой нейронной сети [электронный ресурс] — 2011. - Режим доступа: http://research.microsoft.com/pubs/153169/CD-DNN-HMM-SWB-Interspeech2011-Pub.pdf
- И. Ю. Бондаренко, О. И. Федяев, К. К. Титаренко. Нейросетевой распознаватель фонем русской речи на мультипроцессорной графической плате // Искусственный интеллект. - №3. - 2010. - 176 с.
- Д. В. Калитин. Использование технологии CUDA фирмы Nvidia для САПР нейронных сетей // Устойчивое инновационное развитие: проектирование и управление – №4. – 2009. – С. 16-19.
Прочитать статью из моей библиотеки - PDF
- Вригли С. Распознавание речи с помощью динамической деформации времени. [Электронный ресурс] – 1998. - Режим доступа: http://www.dcs.shef.ac.uk/~stu/com326/index.html.
Важное замечание
На момент написания данного реферата магистерская работа еще является не завершенной. Предполагаемая дата завершения: 1 декабря 2011 г., ввиду чего полный текст работы, а также материалы по теме могут быть получены у автора или его руководителя только после указанной даты.

