

Реферат по теме выпускной работы
Содержание
- Введение
- 1. Анализ математических моделей представления и методов моделирования цифровых устройств
- 1.1 Модели цифровых устройств
- 1.1.1 Функциональные модели
- 1.1.2 Структурные модели
- 1.2 Логическое моделирование неисправных цифровых устройств
- 2. Постановка задачи построения тестов
- 3. Методы построения проверяющих тестов
- 3.1 Основные положения построения тестов
- 3.2 Структурные методы построения тестов, не ориентированные на конкретную неисправность
- 3.3 Структурные методы построения тестов для заданной неисправности
- 3.4 Генетические алгоритмы в построении тестов
- 3.4.1 Классический генетический алгоритм
- 3.4.2 Применение генетических алгоритмов в построении тестов
- 3.5 Роль стратегии наблюдения выходных реакций в построении тестов ЦУ с памятью
- Заключение
- Список источников
Введение
Широкое распространение компьютерных технологий и цифровой техники во всех областях деятельности современного общества повышает требования к качеству и надежности используемых устройств. Совершенствование элементной базы и архитектуры, увеличение степени интеграции и надежности цифровых устройств (ЦУ) не возможны без эффективных систем автоматизированного проектирования и диагностики цифровых систем. Важную роль в системах автоматизированной диагностики играют подсистемы тестовой диагностики и моделирования. Эффективность таких систем, основанных на подаче на испытуемый объект специально организуемых (тестовых) воздействий, в значительной мере зависит от применяемых методов и алгоритмов построения проверяющих тестов и моделирования. Применение подобных систем позволяет повысить качество и надежность, уменьшить время проектирования и диагностики ЦУ.
Исследованиям проблем диагностики и проектирования отказоустойчивых цифровых устройств посвящены проводящиеся регулярно международные симпозиумы, конференции и школы-семинары: IEEE VLSI Test Symposium (IEEE VTS), IEEE Euro Test Symposium (IEEE ETS), International Conference “Design, Automation & Test in Europe” (DATE), IEEE East-West Design&Test Symposium (IEEE EWDTS, симпозиум, проводимый по инициативе Харьковского национального университета радиоэлектроники), IEEE Latin American Test Workshop и т.п. Существует международный совет по технологиям тестирования – Test Technology Technical Council (IEEE TTTC), объединяющий ученых и инженеров, работающих в области проблем надежности и тестирования ЦУ, и спонсируемый международным научно-техническим обществом IEEE Computer Society. Все это красноречиво говорит о чрезвычайной актуальности исследования проблем надежности и диагностики цифровых схем.
В настоящее время разработано ряд эффективных методов генерации проверяющих тестов для цифровых схем. Значительный вклад в развитие тестирования цифровых систем внесли зарубежные исследователи Roth J.P., Zorian Y., Agrawal V.D, Abramovici M., Fujivara H., Ivanov A., Prinetto P., Pomeranz I., Reddy S.M., Rudnick E.M., Patel J.H. и отечественные ученые Пархоменко П.П., Каравай М.Ф., Убар Р.Р., Тоценко В.Г., Сперанский Д.В., Твердохлебов В.А., Романкевич А.М., Дербунович Л.В., Кривуля Г.Ф., Скобцов Ю.А., Хаханов В.И., Харченко В.С., Зинченко Ю.Е. и другие. Однако, существующие методы не всегда позволяют строить тесты высокой полноты за приемлемое время. В первую очередь это относится к цифровым схемам с памятью.
Таким образом, построение проверяющих тестов для цифровых схем с памятью является актуальной научно-технической проблемой, решение которой существенно влияет на надежность и качество цифровых систем. В данной работе будут рассматриваться и исследоваться структурный, аналитический и эволюционный подход к генерации проверяющих тестовых цифровых схем с памятью.
1. Анализ математических моделей представления и методов моделирования цифровых устройств
1.1 Модели цифровых устройств
В процессе автоматизации проектирования и диагностирования цифровых систем (ЦС) широкое применение находят системы верификации, моделирования и генерации проверяющих тестов, в которых используются соответствующие математические модели. Объектом данного исследования являются цифровые устройства (ЦУ), под которыми, как правило, подразумеваются устройства, перерабатывающие двоичную (цифровую) информацию. Они в свою очередь делятся на два класса [1–3]: комбинационные схемы – устройства без памяти (без обратных связей) и последовательностные схемы – устройства с памятью (с обратными связями). При построении моделей ЦУ используется как функциональный, так и структурный подход.
1.1.1 Функциональные модели
Суть функционального подхода заключается в абстрагировании от внутренней организации устройства и рассмотрении только его логики функционирования.
Модели комбинационных схем. В качестве функциональной модели комбинационных устройств, чаще всего, используют систему булевых функций:
z1 = f1(x1, ..., xn)
...
zm = fm(x1, ..., xn),
где X = (x1, ..., xn) – входные, Z = (z1, ..., zn) – выходные переменные, принимающие двоичные значения B2 = {0,1}. Данная система булевых функций описывает комбинационное ЦУ, которое имеет n входов, m выходов и представлено на рис. 1.1.
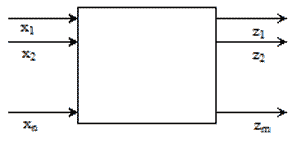
Рисунок 1.1 – Комбинационное ЦУ
Здесь каждая булева функция fi(x1, ..., xn) - это отображение B2n —> B2. Простейшим способом представления булевой функции является таблица истинности.
1.1.2 Структурные модели
Информация о логике функционирования ЦУ, которую дают описанные выше функциональные модели, является недостаточной для решения проблем построения тестов и моделирования. При разработке алгоритмов построения тестов и моделирования чаще используется структурная модель цифрового устройства, отражающая, кроме логики функционирования ЦУ, связи между его компонентами и внешней средой. В качестве структурной модели ЦУ, как правило, используется правильная логическая сеть или логическая схема. Логическая сеть или схема – это ориентированный граф, вершинами которого являются логические элементы, входы, выходы и узлы разветвления. Направленные дуги графа отображают соединения сети. Правильная логическая сеть – это сеть, у которой выходы никаких двух элементов не соединены вместе и каждая из функций, реализуемых на выходах ЦУ, может быть представлена как булева функция выхода комбинационного устройства или конечного автомата в случае ЦУ с памятью. Основу сети составляют логические элементы двух типов:
- элементы, функционирование которых описывается булевыми функциями;
- элементы памяти, функционирование которых описывается моделью конечного автомата.
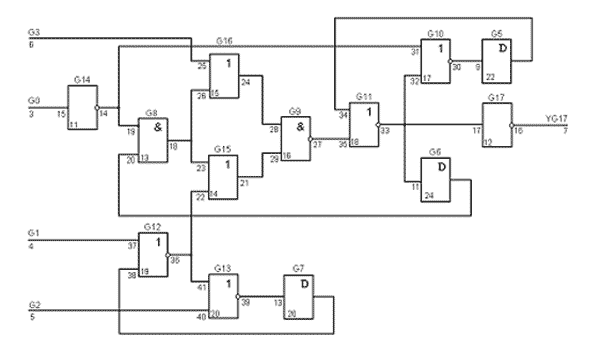
Рисунок 1.2 – Графическое описание схемы S27
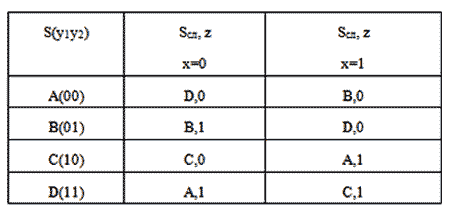
На рис. 1.2 представлена комбинационная логическая схема s27 из каталога ISCAS-89. На рис. 1.7 представлена последовательностная схема, заданная конечным автоматом Мили, представленным в таблице 1.3.
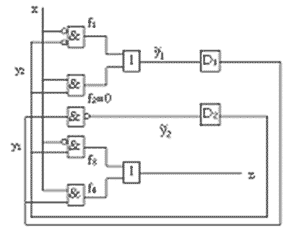
Рисунок 1.3 – Пример последовательностной схемы
Таблица 1. Конечный автомат, задающий ЦУ с памятью
1.2 Логическое моделирование неисправных цифровых устройств
Моделирование ЦУ с неисправностями является одним из важнейших разделов логического моделирования и используется в системах автоматизированного проектирования (САПР) и диагностики компьютерных систем при решении следующих задач [2]:
- определение эффективности тестовой последовательности – её полноты и диагностических свойств;
- построение диагностических словарей для поиска неисправностей в логических схемах;
- генерация проверяющих тестов (в качестве инструмента определения эффективности генерируемых наборов);
- анализ поведения схемы и ее свойств с неисправностью.
Для решения этих задач программам моделирования неисправных схем требуется следующая информация:
- описание логической схемы;
- описание тестовой входной последовательности;
- модели и список обрабатываемых неисправностей.
Функциональная структура системы моделирования неисправных цифровых схем представлен на рис.1.4.
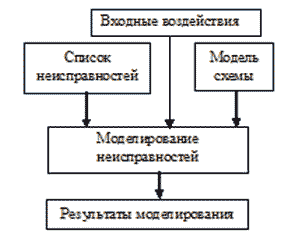
Рисунок 1.4 – Моделирование неисправностей
2. Постановка задачи построения тестов
Суть задачи построения тестов заключается в поиске двоичной входной последовательности, которая для каждой неисправности из заданного множества дает различные выходные значения сигналов в исправной и неисправной схемах. Как правило, рассматриваются одиночные константные неисправности. Полагаем, что одиночная константная неисправность (single stack-at fault ) действует только на соединение между вентилями [1–3]. Каждая линия схемы может иметь два типа этих неисправностей: константа 0 и константа 1 (s-a-0, s-a-1). Итак, константная неисправность фиксирует на линии постоянное значение сигнала 0 или 1 (s-a-0, s-a-1), независимо от значения подаваемого на нее сигнала.
Под тестом понимают последовательность входных воздействий, анализ выходных реакций на которые позволяет либо проверить исправность исследуемого устройства, либо определить место расположения неисправностей, содержащихся в устройстве [1, 2]. Соответственно в первом случае говорится о проверяющих тестах, во втором - о диагностических тестах. В дальнейшем речь будет идти только о проверяющих тестах.
Далее мы будем рассматривать исключительно тестовое диагностирование.
3. Методы построения проверяющих тестов
3.1 Основные положения построения тестов
Целью автоматизированной системы генерации тестов является построение проверяющего теста для данной схемы. При этом в идеале желательно, чтобы [2]:
- полнота проверяющего теста была максимальна;
- время генерации тестов было минимальна;
- построенный тест имел минимальную длину.
Эти условия вытекают из экономических и технологических требований. Очевидно, что полнота теста непосредственно влияет на качество производимой продукции. Длина теста влияет на стоимость тестирования ЦУ и определяет характеристики необходимых тестеров (в частности, необходимый объем памяти) и время тестирования. Следует отметить, что полноту теста необходимо определять относительно проверяемых (неизбыточных) неисправностей. Так, например, для схемы, имеющей 5% избыточных несправностей, очевидно полнота теста 96% является явно недостижимой. Потому порой различают полноту и эффективность теста, которые определяются следующим образом [2].
Полнота – P = O / N, где N – общее число неисправностей и O – число проверяемых на данном тесте неисправностей.
Эффективность – P = O / (N – R), где R – число избыточных неисправностей.
Количественные значения полноты и эффективности теста, также существенно зависит от того, как формировалось множество неисправностей. Современные системы обычно используют методы сокращения списков неисправностей, основанные на отношениях эквивалентности и доминирования [2].
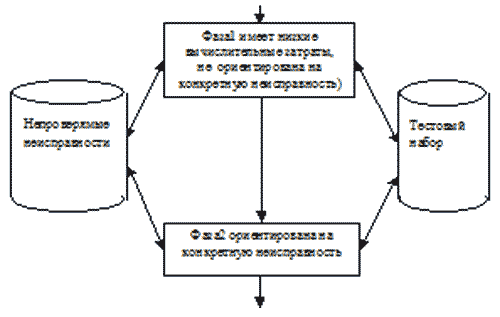
Рисунок 3.1 – Структура системы генерации тестов
3.2 Структурные методы построения тестов, не ориентированные на конкретную неисправность
На начальном этапе генерации проверяющих тестов (I фаза) используются быстродействующие и простые в реализации методы, которые позволяют с малыми затратами времени получить тест для большей части неисправностей. Одним из таких методов является псевдослучайный метод генерации тестов, достаточно подробно описанный в литературе [1-3]. Этот метод не ориентирован на конкретную неисправность и строит тест для всей схемы. Он относительно прост в реализации, обладает высоким быстродействием и для некоторых классов схем позволяет получить тесты с удовлетворительной полнотой (особенно это касается комбинационных схем). Этим обусловлено широкое применение этого метода в системах автоматизированного построения тестов [20, 21]. Важнейшей компонентой этого метода является программа моделирования неисправных схем, которая позволяет отбирать тестовые воздействия из множества случайно генерируемых двоичных наборов. При реализации этого метода используются программные генераторы псевдослучайных двоичных чисел. В простейшем случае псевдослучайный двоичный набор обрабатывается следующим образом. Для текущего случайного двоичного вектора Xi с помощью программы моделирования с неисправностями определяется величина n(Xi), которая характеризует число неисправностей, проверяемых на наборе Xi без учета тех неисправностей, которые проверяются ранее построенной тестовой последовательностью X1, X2,…, Xi-1. Далее если n(Xi)>=Т (пороговое значение), то набор Xi включается в тестовую последовательность и генерируется следующий псевдослучайный набор. Если n(Xi) < Т, то этот входной набор бракуется и не включается в тест. Упрощенная блок-схема алгоритма псевдослучайной генерации тестов представлена на рис. 3.2 [2].
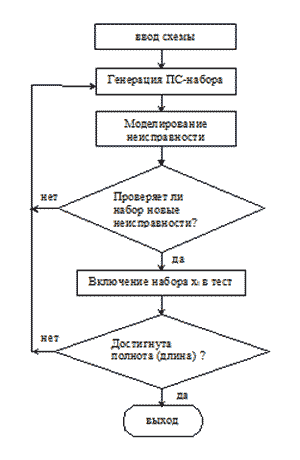
Рисунок 3.2 – Псевдослучайная генерация тестов
3.3 Структурные методы построения тестов для заданной неисправности
В настоящее время разработано достаточно много структурных методов, которые применяются для решения задачи генерации теста для заданной неисправности. Их объединяет то, что они в большей или меньшей степени основаны на активизации путей с помощью многозначных алфавитов.
Первым регулярным методом, для которого теоретически доказано, что он гарантирует построение теста для неизбыточной неисправности в комбинационной схеме, является D-алгоритм [24]. Данный метод и его последующие модификации получили чрезвычайно широкое распространение в 70-х годах. В базовом D-алгоритме использовалась многомерная активизация и 6-значный алфавит T6={0,1,D,D’,u,∅}, где {0,1} обозначают обычные (булевы) значения, {D,D’} представляют рассогласование сигналов в исправной и неисправной схемах, u – неопределенное значение и ∅ обозначает конфликт (противоречие) в процессе генерации теста. Однако, несмотря на популярность данного метода, его эксплуатация показала, что существует класс схем, содержащих большое число сходящихся разветвлений, для которых в процессе генерации тестовой последовательности возникает слишком большое число конфликтных ситуаций. Для таких схем был предложен метод PODEM [25,26], в котором также используется 6-значный алфавит, но применяются совершенно иные стратегии поиска и обработки конфликтных ситуаций в процессе генерации тестов. Этот метод оказался существенно проще в программной реализации, чем D-алгоритм, и более эффективным для больших комбинационных схем объемом до нескольких десятков тысяч вентилей [27]. Идеи, заложенные в PODEM получили успешное развитие в [28], где разработан метод FAN (fan-out-oriented test generation algorithm). В этом методе на этапе препроцессорной обработки проводится дополнительный анализ схемы, в результате которого ЦУ разбивается на древовидные подсхемы, что позволило разработать сделать более эффективными процедуры продвижения
3.4 Генетические алгоритмы в построении тестов
Применение эволюционных алгоритмов для построения проверяющих тестов показало их высокую эффективность по сравнению с псевдослучайными и детерминированными методами генерации тестов, в особенности, для последовательностных схем. Эволюционные вычисления используют различные модели эволюционного процесса [43-49]. Среди них можно выделить следующие основные парадигмы:
- генетические алгоритмы;
- эволюционные стратегии;
- эволюционное программирование;
- генетическое программирование.
Отличаются они, в основном, способом представления искомых решений и различным набором используемых в процессе моделирования эволюции операторов
3.4.1 Классический генетический алгоритм
Генетические алгоритмы (ГА) [43-45,49] являются одной из парадигм эволюционных вычислений и представляют собой алгоритмы поиска, построенные на принципах, сходных с принципами естественного отбора. ГА используют случайный направленный поиск для построения (суб)оптимального решения некоторой проблемы. В ГА из всего пространства поиска для текущего анализа выделяется некоторое множество точек этого пространства (потенциальных решений), которое в терминах натуральной селекции и генетики называется популяцией. Здесь каждая особь популяции соответствует потенциальному решению задачи, которое представляется хромосомой – структурой элементов – генов. Произвольный ген хромосомы принимает значение – аллель, из некоторого конечного алфавита, который задает кодовое представление точек пространства поиска решений. В простейшем случае (классическом ГА) особь представляется двоичной строкой (например, 0011101). Это делает ГА очень привлекательным для решения задач построения проверяющих тестов цифровых схем, где решение задачи представляется в виде двоичных наборов или их последовательностей [50-57]. ГА использует кодированные структуры безотносительно их смысловой интерпретации. Сам код и его структура описываются понятием генотип, а его интерпретация, с точки зрения решаемой задачи, понятием фенотип. На популяции особей (потенциальных решений) определяется целевая (fitness) функция (ЦФ), которая позволяет оценить близость каждой особи к оптимальному решению – способность к выживанию. Генетический алгоритм поиска решения основан на моделировании эволюции подобной искусственной популяции. Популяция особей развивается (эволюционирует) от одного поколения к другому. Генерация новых особей в процессе работы алгоритма выполняется на основе моделирования процесса размножения. При этом особи-решения, участвующие в процессе воспроизводства называют родителями, а получившиеся в результате новые особи – потомками. В каждом поколении множество особей – потомков производится, используя части особей-родителей и добавляя новые части с «хорошими свойствами». Многочисленные эксперименты показывают, что ГА эффективно используют информацию, накопленную в процессе эволюции, что проявляется в постепенном от поколения к поколению улучшении качества особей.
Формально генетический алгоритм можно описать следующим образом [49]:
ГА=(P, N, l, r, k, m, f, pk, pm),
Классический ГА использует три основных оператора: репродукция, кроссинговер, мутация. При репродукции хромосомы копируются согласно значениям их целевых функций (ЦФ). Копирование лучших хромосом с большими значениями ЦФ определяет большую вероятность их попадания в следующее поколение. Оператор репродукции реализует принцип “выживания сильнейших” по Дарвину. Самый простой (и популярный) метод реализации ОР – построение асимметричного колеса рулетки, в которой каждая хромосома имеет сектор, пропорциональный ее значению ЦФ (рис. 3.3, рис. 3.4).
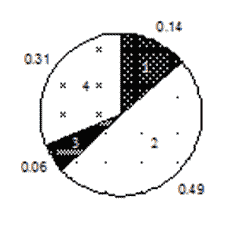
Рисунок 3.3 – Модель ОР в виде асимметричного взвешенного колеса рулетки
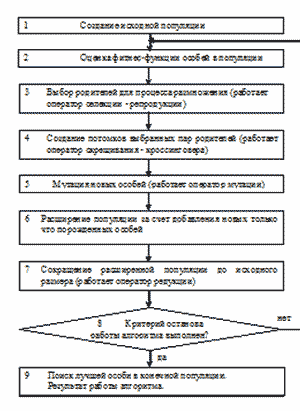
Рисунок 3.4 – Классический генетический алгоритм
3.4.2 Применение генетических алгоритмов в построении тестов
В ранних работах ГА применялись для генерации тестов комбинационных ЦУ [50,51]. Поскольку значения на выходных линиях комбинационной ЦУ зависят только от значений на внешних входах и не зависят от внутреннего состояния схемы, в качестве особи здесь выступает одиночный тестовый набор X=(x1, x2,…, xn,) –двоичная строка длины n (количество входов ЦУ).
В этом случае группа потенциальных тестовых наборов образует популяцию. К выбранным таким образом особям применимы стандартные операции ГА, описанные выше. Исследования показывают, что наиболее эффективной является мощность (число особей) популяции, пропорциональная числу входов схемы n (например, 3n) и использование одноточечного и двухточечного операторов кроссинговера. Укрупненный алгоритм генерации теста на основе описанного подхода в виде псевдокода можно представить следующим образом.
Генерация теста(схема,неисправность)
{
Инициализация схемы;
Генерация начальной популяции наборов;
While(не выполнено условие останова)
{
Моделирование неисправностей;
Оценка фитнесс-функции;
Включение лучшего набора в тест;
Выполнение генетических операторов:
репродукции,
кроссинговера,
мутации;
Генерация новой популяции;
}
Вывод построенного теста;
Отметим, что в рассмотренном подходе в отличие от классического ГА, представленного блок-схемой рис. 3.4. данный тип ГА применяется на каждом шаге для решения локальной задачи выбора следующего входного набора для включения его в тест. Как мы увидим дальше, в следующем разделе для схем с памятью ГА применяется глобально, где особь представляет потенциальное решение всей (глобальной) проблемы – тестовой последовательности.
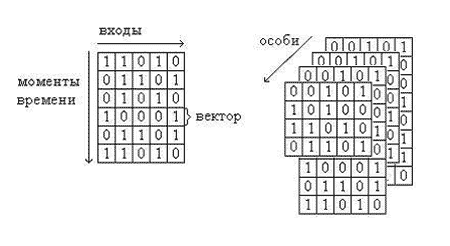
Рисунок 3.5 – Кодирование особей и популяций в ГА для ЦУ с памятью: (а) особь; (б) популяция
Для последовательностных схем значения сигналов внешних выходов при функционировании зависят не только от значений сигналов на его внешних входах, а и от значений состояний (триггеров). Поэтому здесь при генерации тестов с применением ГА в качестве особи используется тестовая последовательность, которая представляется двоичной таблицей (рис. 3.5 а). Число столбцов таблицы определяется числом входов схемы, а число строк – длиной тестовой последовательности. Популяция состоит из фиксированного числа тестовых последовательностей, возможно, различной длины (рис. 3.5 б). Для выбранного таким образом представления особей и популяций применяются генетические операторы скрещивания и мутации [2, 49].
3.5 Роль стратегии наблюдения выходных реакций в построении тестов ЦУ с памятью
Постановка задачи построения проверяющих тестов и моделирования неисправностей для ЦУ с памятью существенно зависит от применяемой стратегии наблюдения выходных сигналов [2, 58, 59]. Как правило, большинство применяемых на практике структурных методов для последовательностных схем учитывают не все выходные сигналы и неявно предполагают наличие цепей установки элементов памяти. Более полное использование выходных сигналов для всех моментов времени и всех выходов позволяет существенно повысить полноту тестов для схем с памятью [2, 58, 59].
Существуют две стратегии наблюдения выходных реакций ЦУ с памятью: одиночная стратегия наблюдения, применяемая в большинстве структурных методах построения тестов для ЦУ с памятью, и кратная стратегия наблюдения, основывающаяся на принципах теории экспериментов конечных автоматов [2, 58, 59]. Принципиальное отличие между этими стратегиями состоит в следующем. Согласно одиночной стратегии неисправность обнаружима и, следовательно, для нее можно построить тестовую последовательность) если найдется один момент времени t, такой что независимо от начального состояния исправной и неисправной схем значения выходных сигналов различны для исправной и неисправной схем. То есть все пары состояний исправной и неисправной схемы выдают различные выходные сигналы в один и тот же момент времени. Согласно кратной стратегии для каждой пары состояний исправной и неисправной схемы существует свой момент времени, в котором они выдают различные выходные сигналы. Т.е. разные пары состояний исправного и неисправного ЦУ могут различаться в разные моменты времени. Такое, казалось бы, небольшое отличие приводит к тому, что неисправность, являющаяся нетестируемой при условии применения первой традиционной стратегии, на самом деле имеет проверяющий тест в случае использования кратной стратегии.
Заключение
Таким образом, на текущий момент перспективными исследованиями в области построения тестов являются исследование возможности применения кратной стратегии наблюдения и наработок теории экспериментов с конечными автоматами в процессе построения и оценки эффективности тестов для ЦУ с памятью на структурном уровне. При этом важным является изучение методов возможной реализации данного подхода:
- применение символьного моделирования;
- применение многозначных логик;
- применение эволюционных алгоритмов, в частности, ГА.
В связи с этим для повышения эффективности систем автоматизированной генерации проверяющих тестов для ЦУ с памятью необходимо решить следующие задачи:
- Исследование влияния различных стратегий наблюдения выходных сигналов на эффективность генерации тестов для последовательностных цифровых схем.
- Исследование и разработка структурного и структурно-аналитического методов построения проверяющих тестовых последовательностей для схем с памятью на основе кратной стратегии наблюдения выходных сигналов.
- Исследование методов многозначного и смивольного логического моделирования для повышения эффективности генерации тестов для последовательностных схем на основе кратной стратегии наблюдения выходных сигналов.
- Разработка метода генерации проверяющих тестов для схем с памятью с использованием генетических алгоритмов и характеристических последовательностей.
Разработка соответствующего программного обеспечения генерации проверяющих тестовых для ЦУ с памятью.
Список источников
- Барашко А.С., Скобцов Ю.А., Сперанский Д.В. Моделирование и тестирование дискретных устройств. – Киев: Наукова думка, 1992. – 288с.
- Ю.А.Скобцов, В.Ю.Скобцов. Логическое моделирование и тестирование цифровых устройств. – Донецк: ИПММ НАНУ, ДонНТУ, 2005. – 436 с.
- Abramovici M. Digital System Testing and Testable Design. – New York: Computer Science Press, 1990. – 652 p.
- Thompson E.W., Szygenda S.A. Digital logic simulation in a timed-based, table-driven environment. Part 2. Parallel Fault Simulation // Computer, IEEE Comp. Society. – 1975. – N 3. – P.38-49.
- Levendell Y.H., Menon P.R. Comparison of fault simulation methods – treatment of unknown values // Journal digital system. – 1980. – N 4. – P.443-459.
- Armstrong D.A Deductive method for simulating faults in logic circuits//IEEE Transactions on Computers.-1972.-N 5.-P.38-49.
- Биргер А.Г. Многозначное дедуктивное моделирование цифровых устройств // Автоматика и вычислительная техника. – 1982. – №4. – С.77-82.
- Ulrich T.G., Baker T. Concurrent simulation of nearly identical digital networks//Computers.-1974.-N4.-P.39-44.
- Yu.A.Skobtsov, V.Yu.Skobtsov, D.E.Ivanov Evolutionary distributed test generation methods for digital circuits // Proc. of 8th International Workshop on Boolean Problems, Freiberg, Germany, September 2008. – P.213-218.
- T. Marcas, M. Royals and N. Kanopoulos, “On distributed fault simulation”, IEEE Computer, vol. 7, Jan. 1990.- P. 40-52.
- S. Patil, P. Banerjee and J. Patel, “Parallel test generation for sequential circuits on general purpose multiprocessors”, in Proceedings of the 28th ACM/IEEE Design Automation Conference, (San Francisco, CA), June 1991.
- S. Ghost, “NODIFS: a novel, distributed circuit partitioning based algorithm for fault simulation of combinational an sequential digital design on loosely coupled parallel processors”, tech. rep., LEMS, Division of Engineering, Brown University, Providence, RI, 1991.
- Corno F., Prinetto P., Rebauden M., Sonza Reorda M., Veiluva E. A PVM tool for automatic test generation on parallel and distributed systems // Proc. Int. Conf. on high-performance computing and networking. – Milan, 1995. – P.39-44.
- Muth P. A nine-valued circuit model for test generation // IEEE Trans.Comput. – 1976. – N6. – P.630-636.
- Cha C.W., Donath W.E., Ozguner F. 9-v algorithm for test pattern generation of combinational digital circuits // IEEE Transactions on Computers. - 1978. - №3 - P.193-200.
- Sziray J. Test calculation for logic networks by composite justification // Digital Process. – 1979. – № 5. - P.3–15.
- Cheng W.T. Split circuit model for test generation // 25th Design automation conference proceedings. – 1988. - P.96–101.
- R.Krieger, B.Becker, M.Keim. Symbolic fault simulation for sequential circuits and the multiple observation strategy// Proc. design automation conf.– 1995.– P.339–344.
- B.Becker,M.Keim. Hybrid fault simulation for synchronous sequential circuits//Journal of electronics:Theory and applications.-1999.-15.-P.219-238.
- M.Keim, N.Drechsler, R.. Drechsler, B.Becker. Combining Gas and symbolic methods for high quality tests of sequential circuits// Journal of electronics:Theory and applications.– 2001. – 17. – P. 37-51.
- Скобцов В.Ю. Символьное моделирование неисправностей последовательностных цифровых устройств // Автоматика и вычислительная техника. - 1997. - №5. - С.40-50.
- Скобцов В.Ю., Скобцов Ю.А. Генерация проверяющих тестов для последовательностных цифровых устройств на основе символьного моделирования // Автоматика и вычислительная техника. – 1999. – №4. – С.73–84.