
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Научная новизна о области применения
- 4. Общая постановка проблемы
- 4.1 Сегментация с помощью методов кластеризации
- 4.2 Сегментация с помощью роевых алгоритмов
- 4.3 Быстродействие
- Выводы
- Список источников
Введение
Задача анализа изображений, видео и других данных является очень актуальной в настоящее время, особенно в медицине. Пространственная сегментация – важная составляющая медицинских приложений по диагностике и анализу анатомических данных. Вместе со стремительным развитием вычислительной техники остро встает вопрос о разработке методов и подходов к обработке медицинских изображений. Зачастую постановка правильного диагноза болезни основывается на информации, полученной посредством магнитно-резонансного исследования, позитронно-эмисcионного исследования, рентгена и прочих. В связи с этим возникает необходимость в разработке эффективных алгоритмов сегментации и, в частности, пространственной сегментации. Ручная обработка трехмерных изображений требует больших усилий и часто чревата ошибками. Интерпретация же трехмерного медицинского изображения требует от врачей перестройки способа мышления и может приводить к большим разночтениям. Алгоритмы, автоматизирующие этот процесс, могут помочь медикам справиться с большим объемом данных, обеспечив им при этом надежную поддержку для диагностирования и лечения.
1. Актуальность темы
В связи с ростом технических возможностей современных вычислительных систем появляется все больше и больше возможностей по обработке данных. Технический прогресс не обошел стороной медицину. В клиниках и больницах используется большое количество сложных приборов и аппаратно-программных комплексов. Однако, несмотря на все разнообразие технических средств, доступных медикам, все еще остается открытым ряд проблем. Одной из таких проблем является обработка медицинских изображений. Сложность анализа и объемы данных бывают очень большими. Это влечет за собой сложность обработки и высокую вероятность ошибки при отсутствии каких-либо средств автоматизации. В связи с этим проблема автоматизации процесса анализа медицинских изображений и сегментации, в частности, является актуальной.
2. Цель и задачи исследования, планируемые результаты
Целью исследования является повышение эффективности сегментации трехмерных медицинских изображений, полученных с помощью компьютерной томографии.
Основные задачи исследования:
3. Научная новизна в области применения
Сегментация трехмерных медицинских изображений создает широкий спектр возможностей по исследованию анатомических структур без непосредственного контакта с пациентом. Так, например, данные, полученные посредством МРТ или КТ, дают возможность создавать виртуальные карты кровеносных сосудов, кишечного тракта, исследовать области интереса (ткани, органы, опухоли, другие участки). На сегодняшний день существует большое разнообразие алгоритмов сегментации трехмерных изображений, дающих оптимальные результаты. Однако не сущесвует одного универсального алгоритма, подходящего для любого класса данных. Кроме того, различные алгоритмы ведут себя по-разному при обработке достаточно больших объемов данных. В связи с этим целесообразно разработать алгоритм, который мог бы одновременно решать вычислительно трудные задачи за приемлемое время и был бы устойчив к шумам и артефактам.
4. Общая постановка проблемы
Пространственным изображением будем называть геометрическое описание трехмерного тела, полученного в результате измерения реального физического объекта, например, при помощи трехмерного сканера или КТ. Под сегментацией будем понимать разбиение изображения на непохожие области по некоторым признакам. В качестве таких признаков можно брать яркостные характеристики, текстуру и пр. Сегментация, как правило, считается очень трудной задачей. Эта трудность возникает из-за большого количества данных, сложности и изменчивости исследуемых областей. Ситуация усугубляется недостатками изображения, такими, как наличие артефактов и шума, которые могут привести к тому, что границы анатомических структур становятся нечеткими. Таким образом, основная задача алгоритмов сегментации – точное извлечение границы органов или областей интересов и отделение их от остальных данных. На сегодняшний день существует очень много подходов к сегментации изображений. Они различаются в зависимости от области приложения, модальности изображения (КТ, МРТ и т.д.) и других факторов. Например, сегментация легких имеет особенности, которые не характерны для тонкого кишечника. Алгоритм, который дает хорошие результаты для одной области, может не работать для другой. Эта изменчивость делает сегментацию очень сложной задачей. В настоящее время не существует метода сегментации, который обеспечивает приемлемые результаты для любого типа медицинских данных. Существуют обобщенные методы, которые могут быть применены к большому количеству разнообразных данных. Но методы, которые предназначены для частных случаев, всегда дают лучшие результаты. Авторы [1] классифицируют все многообразие алгоритмов сегментации следующим образом:
Данные алгоритмы относятся к алгоритмам поиска оптимальных решений. Следует отметить, что, хотя данные методы в той или иной мере решают поставленную перед собой задачу, они не лишены недостатков. К основным недостаткам можно отнести:
4.1 Сегментация с помощью методов кластеризации
Один из вариантов преодоления части из изложенных проблем – использование алгоритмов, дающих субоптимальные решения, а именно – эволюционных алгоритмов. Заметим, что в постановке задачи сегментации, прослеживается аналогия с задачей кластеризации. Для того, чтобы свести задачу сегментации к задаче кластеризации, необходимо задать отображение точек изображения в некоторое пространство признаков и ввести метрику (меру близости) на этом пространстве признаков. В качестве признаков точки изображения можно использовать представление ее цвета в некотором цветовом пространстве. Примером метрики может быть евклидово расстояние между векторами в пространстве признаков. Тогда результатом кластеризации будет квантование цвета для изображения. Задав отображение в пространство признаков, можно воспользоваться любыми методами кластерного анализа. Наиболее популярные методы кластеризации, используемые для сегментации изображений, – метод K-средних, FCM и другие алгоритмы [2]. Основным недостатком методов кластерного анализа является то, что они чувствительны к шумам.
Другой подход к решению задачи сегментации заключается в комбинировании генетического алгоритма и алгоритма К-средних. Рассмотрим эволюционный вариант алгоритма K-средних. Пусть дано множество A = {x1, x2, ..., xn} – множество векторов длины d, при этом элемент xij – это i-е свойство j-го элемента множества А. Введем следующую матричную величину  . Матрица W обладает следующим важным свойством:
. Матрица W обладает следующим важным свойством:
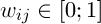 ,
, 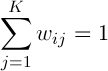 (1)
(1)
Обозначим центры кластеров следующим образом 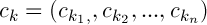 , тогда
, тогда
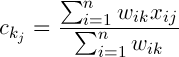 (2)
(2)
Таким образом, кластерное отклонение может быть определено по формуле:
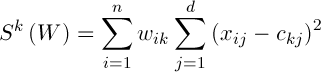 (3)
(3)
Требуется найти такую матрицу 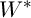 , что
, что 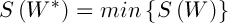 . Так как пространство поиска представляет собой множество всех существующих двоичных матриц W, удовлетворяющих условию (2), то можно представить хромосому в виде строки длины n, при этом каждый аллель может принимать значения из множества {1, 2,..., K}. Инициализация популяции может быть осуществлена одним из классических способов.
. Так как пространство поиска представляет собой множество всех существующих двоичных матриц W, удовлетворяющих условию (2), то можно представить хромосому в виде строки длины n, при этом каждый аллель может принимать значения из множества {1, 2,..., K}. Инициализация популяции может быть осуществлена одним из классических способов.
Селекция предполагает выбор случайной хромосомы из популяции с помощью метода рулетки, либо какого-либо другого метода. Решение в текущей популяции может задавать некоторый вес, который влияет на выживание в следующем поколении. Это означает, что каждой особи задается некоторое число, либо вычисляется значение специальной фитнесс-функции. Существует много способов вычисления этой фитнесс-функции [3]. Авторы [2] предлагают следующий вариант решения. Пусть 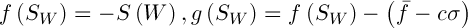 , где
, где 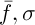 – среднее значение и стандартное отклонение функции
– среднее значение и стандартное отклонение функции 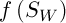 соответственно,
соответственно, 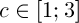 – некоторая константа. Тогда значение фитнесс-функции определим следующим образом:
– некоторая константа. Тогда значение фитнесс-функции определим следующим образом:
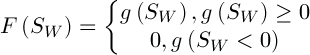 (4)
(4)
Оператор мутации меняет значение аллеля в зависимости от расстояния от данной точки до центра кластера. Зададим его следующим образом: аллель заменяется значениями, которые выбираются случайно, согласно следующему распределению вероятностей:
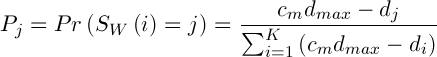 ,(5)
,(5)
где 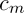 – некоторая константа,
– некоторая константа, 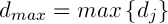 .
.
Алгоритм, с представленным выше оператором селекции, может сходиться достаточно долго. Кроме того, вероятность мутации должна быть достаточно мала, так как большие значения ведут к колебаниям решений. Чтобы исключить такие ситуации, вводится новый оператор, называемый K-means operator (KMO) [2]. Выполнение данного оператора состоит из следующих двух шагов:
Имея технику построения начальной популяции и генетические операторы, можно построить генетический алгоритм, блок-схема которого представлена на рис 1.
")
Рис 1. Общая схема работы генетического алгоритма
4.2 Сегментация с помощью роевых алгоритмов
Задача сегментации изображений также может быть сведена к задаче оптимизации на графах [1]. Такая специфика задачи позволяет использовать алгоритм муравьиных колоний для ее решения. Идея муравьиного алгоритма состоит в следующем. Происходит моделирование поведения муравьев, связанного с их способностью быстро находить кратчайший путь от муравейника к источнику пищи и адаптироваться к изменяющимся условиям, находя новый кратчайший путь. При своём движении муравей оставляет на своем пути феромон, и эта информация используется другими муравьями для выбора пути. Это элементарное правило поведения и определяет способность муравьёв находить новый путь, если старый оказывается недоступным. Происходит так же моделирование обогащения пути феромоном и его испарения. Данные шаги алгоритма позволяют искать все возможные оптимальные пути в пространстве поиска, а не какой-то один конкретный путь. Независимо от модификации общая идея работы муравьиного алгоритма может быть продемонстрирована блок-схемой, приведенной на рис 2.
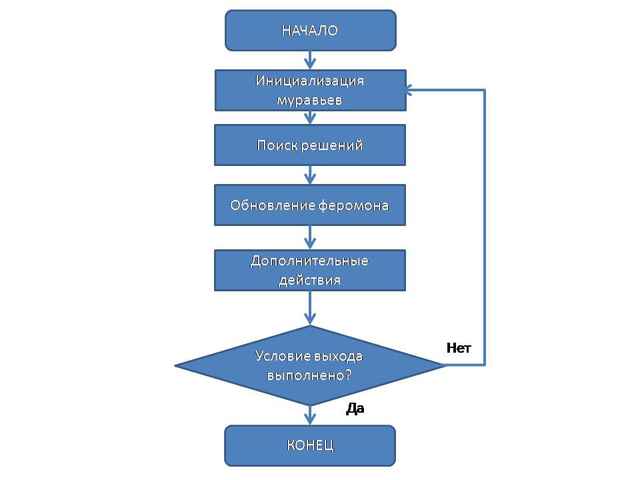
Рис 2. Общая схема работы муравьиного алгоритма
Инициализация муравьёв – стартовая точка, куда помещается муравей, зависит от ограничений, накладываемых условиями задачи, потому что для каждой задачи способ размещения муравьёв является определяющим. Либо все они помещаются в одну точку, либо в разные с повторениями, либо без повторений. На этом же этапе задаётся начальный уровень феромона. Он инициализируется небольшим положительным числом для того, чтобы на начальном шаге вероятности перехода в следующую вершину не были нулевыми. Вероятность перехода из вершины i в вершину j определяется по следующей формуле:
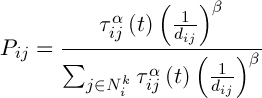 ,(6)
,(6)
где 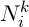 представляет множество возможных вершин, связанных с вершиной i для муравья k,
представляет множество возможных вершин, связанных с вершиной i для муравья k, 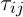 – уровень феромона,
– уровень феромона, 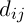 – эврестическое расстояние,
– эврестическое расстояние, 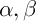 – некоторые константы.
– некоторые константы.
Обновление феромона происходит по следующей формуле:
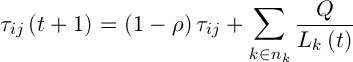 ,(7)
,(7)
где 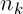 – количество муравьев,
– количество муравьев, 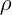 – интенсивность испарения,
– интенсивность испарения, 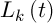 – длина пути, построенного k-м муравьем в момент времени t, Q – параметр значимости.
– длина пути, построенного k-м муравьем в момент времени t, Q – параметр значимости.
Рассмотрим способ применения алгоритма муравьиных колоний к сегментации изображений. В этом алгоритме муравьи представляются простыми агентами, которые случайным образом перемещаются по дискретному массиву. Пиксели, которые рассеяны в элементах массива, могут быть перемещены из одного элемента массива в другой, формируя кластеры. Перемещение пикселов косвенным образом определяется поведением муравьев. Каждый муравей может присоединять или исключать пиксель согласно функции, которая вычисляет сходство пикселя с другими пикселями в кластере. Таким образом, муравьи динамически кластеризируют изображение на независимые кластеры, которые включают только сходные между собой пиксели. Кроме этого, агент представляет новые вероятностные правила для присоединения или исключения пикселов, а так же стратегию локального перемещения для ускорения сходимости алгоритма. Предположим, размерность массива равна N. Каждый элемент этого массива связан с гнездом муравьев в определенном порядке, что позволяет муравьям легко переходить от одного элемента к другому. В процессе работы алгоритма муравьи могут изменять, строить или убирать существующие кластеры пикселов. Кластер представляется соединением двух или более пикселов и пространственно расположен в отдельной ячейке массива, что упрощает его идентификацию. Инициализируем N пикселов {Р1,…,Рn} для кластеризации, расположенные в массиве таким образом, что каждый элемент массива связан только с одним пикселем. Каждый муравей аi из колонии с К муравьями {a1,…,аk} присоединяет случайно выбранный пиксель из элементов массива и возвращается в гнездо. После начального этапа инициализации происходит этап кластеризации. Выбор муравья производится случайным образом. Он перемещается от своего гнезда к элементам массива и определяет с помощью вероятностного правила присоединять ли этот пиксель к кластеру. Каждый муравей знает список расположения пикселов, которые не были присоединены другими муравьями. Случайным образом муравей определяет следующий пиксель из списка свободных. Этот алгоритм повторяется для каждого муравья. Завершение алгоритма происходит при выполнении заданного критерия останова.
4.3 Быстродействие
Следует обратить внимание на тот факт, что эволюционные алгоритмы достаточно медленные. Поэтому, помимо основной задачи разработки эволюционного алгоритма сегментации, должна быть решена проблема производительности. Последнего можно добиться за счет комбинирования ресурсов CPU и GPU. Также следует обратить внимание на тот факт, что эволюционные алгоритмы представляют собой ряд независимых или слабозависимых задач. Это дает высокие потенциальные возможности для распараллеливания. Таким образом, объединяя способность эволюционных алгоритмов решать вычислительно трудные задачи и возможности современных вычислительных систем, теоретически можно добиться высокого быстродействия от медленных методов.
Рис 3. Основные принципы построения алгоритма
Выводы
Основная преследуемая цель состоит в том, чтобы построить хорошо распараллеливаемый эволюционный алгоритм, который способен решить свою поставленную задачу за приемлемое время, обрабатывая при этом достаточно большие массивы данных, а так же комбинируя при необходимости ресурсы CPU и GPU. Легко заметить, что наличие множества простых, практически независимых друг от друга агентов, дает хорошие потенциальные возможности для распараллеливания алгоритма. На основании вышеизложенного можно сделать вывод, что применение эволюционных и роевых вычислений может помочь устранить некоторые недостатки известных методов при обработке трехмерных изображений. Показано, что одним из подходов может быть применение метода кластеризации в совокупности с генетическим алгоритмом. В качестве альтернативы предлагается использовать алгоритм муравьиных колоний для решения задачи кластеризации, сведенной к задаче оптимизации на графах. Анализ предлагаемых решений показал, что генетические алгоритмы и алгоритмы муравьиных колоний основаны на ряде независимых подзадач, что позволяет значительно повысить скорость их работы, выполнив распараллеливание с применением вычислений на CPU, а также GPGPU. Таким образом, направлением дальнейшей работы является разработка и реализация параллельных вычислительных схем для эволюционного варианта алгоритма K-средних и муравьиного алгоритма кластеризации изображений, а также их проверка на задачах кластеризации и классификации КТ и МРТ изображений.
Важное замечание
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение – декабрь 2012 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Sarang Lakare, Arie E. Kaufman. 3D Segmentation Techniques for Medical Volumes // Center for Visual Computing, Department of Computer Science, State University of New York at Stony Brook. [Электронный ресурс]. – Режим доступа: http://www.cs.sunysb.edu.
- Александр Вежневец, Ольга Баринова. Методы сегментации изображений: автоматическая сегментация // Компютерная графика и мультимедаи сетевой журнал. [Электронный ресурс]. – Режим доступа: http://www.cgm.computergraphics.ru.
- K. Krishna, M. Narasimha Murty. Genetic K-Means Algorithm // IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS-PART B: CYBERNETICS, VOL. 29, NO. 3, JUNE 1999. [Электронный ресурс]. – Режим доступа: http://eprints.iisc.ernet.in.
- Р.В. Дрындик, М.В. Привалов. Применение эволюционных вычисления для сегментации трехмерных медицинских изображений/ Сборник материалов к III Всеукраинской научно-технической конференции студентов, аспирантов и молодых ученых. – Донецк, ДонНТУ – 2012, с. 480 – 484.
- D. Goldberg. Genetic Algorithms in Search, Optimization and Machine Learning. Reading, MA: Addison-Wesley, 1989.
- C. von der Malsburg. The correlation theory of brain function. Technical report, Max-Planck-Institute Biophysical Chemestry, 1981.
- G.P. Babu and M.N. Murty. "Simulated annealing for selecting initial seeds in the K-means algorithm" Ind. J. Pure Appl. Math., vol. 25, pp. 85–94, 1994.
- J.N. Bhuyan, V.V. Raghavan, and V.K. Elayavalli. "Genetic algorithm for clustering with an ordered representation" in Proc. 4th Int. Conf. Genetic Algorithms. San Mateo, CA: Morgan Kaufman, 1991.
- D.R. Jones and M.A. Beltramo "Solving partitioning problems with genetic algorithms" in Proc. 4th Int. Conf. Genetic Algorithms. San Mateo, CA: Morgan Kaufman, 1991.
- G.P. Babu and M.N. Murty. "A near-optimal initial seed selection in K-means algorithm using a genetic algorithm" Pattern Recognit. Lett., vol. 14, pp. 763–769, 1993.
- G.P. Babu. "Connectionist and evolutionary approaches for pattern clustering" Ph.D. dissertation, Dept. Comput. Sci. Automat., Indian Inst. Sci., Bangalore, Apr. 1994.
- G. Rudolph. "Convergence analysis of canonical genetic algorithms" IEEE Trans. Neural Networks, vol. 5, no. 1, pp. 96 – 101, 1994.
- L. Davis, Ed., Handbook of Genetic Algorithms. New York: Van Nostrand Reinhold, 1991.
- H. Spath, Clustering Analysis Algorithms. New York: Wiley, 1980.
- Y.T. Chien. Interactive Pattern Recognition. New York: Marcel-Dekker, 1978.