
| CV Biografy Abstract |
|
Subject: Methods and algorithms for optimizing access to spatial data in the database HBase Contents:
Typical tasks of spatial data mining include clustering, classification and identification of trends. The main difference between the extraction of knowledge in conventional databases and in the space – this is what the neighbors determine the spatial attributes of the objects have an impact on this very subject. Therefore, algorithms for extracting knowledge from spatial data are highly dependent on the efficiency of the process of determining the relationship to the neighborhood of a spatial object. The operation of determining the ratio between the spatial objects of the neighborhood needs a lot of computing time. A simple algorithm to search for nearby objects has the computational complexity, since it is necessary to view all the pairs of objects. Thus, the purpose is to analyze the problem of the relevance of data generated in a GIS, as well as the identification of methods and algorithms that can be used effectively to index spatial data [1]. Recently there have been a large number of information systems generating spatial data. Such systems are commonly referred to as geographic information systems (GIS). This is a system such as sensor networks, remote sensing, satellite monitoring of transport, etc. All of this suggests that the number and amounts of spatial databases will continue to grow rapidly. Intelligent analysis of these data may provide useful information about the real physical world and help in solving their problems to experts such domains as ecology, land management, municipal management, transportation, economics, and many others. scientific innovation is the use of codes of Morton and tree data structures such as a quadtree, which will index the spatial objects for further processing. This approach should provide high performance in distributed database systems using HBase. With this work assumes a solution to the problem of indexing spatial data obtained from geographic information systems. Review of Geographic Information Systems
The significant difference of GIS from other information systems with the spatial localization of the data is included in the description of spatial objects and topological characteristics of the classification on this basis of spatial objects: point, line and area (areal). Temporal aspect, as a rule, consists of three long-term factor, average time and operational. From this aspect is related characteristics of the quality of information – the relevance and the procedure for updating the data.
By the time characteristics of the stored information and the SOT, usually divided into:
Distributed data storage and processing To work with large volumes of data in recent years increasingly used a distributed storage and processing. Moreover, there is a shift from the use of high-performance mainframe to the cluster systems consisting of a large number of low-cost servers with x86-64 [2]. Following the publication of articles by Google disclosing the principles of data storage and processing, implemented it for their services [3, 4], there were open source projects that implement these principles. The most successful of them so far is the project of Hadoop. Hadoop is a free Java framework that supports the execution of distributed applications running on large clusters, combining conventional server running open source operating system Linux. For distributed data storage uses a file system Hadoop Distributed File System (HDFS), which is analogous to open Google File System (GFS). On top of that file system databases running HBase, which is analogous to BigTable database of Google [3]. Hadoop is implemented in the computational paradigm, known as MapReduce [4]. According to this paradigm, the application is divided into many small tasks, each of which can be performed on any node in the cluster. All these technologies make it possible to achieve very high aggregate bandwidth of the cluster. This system allows applications to easily scale to thousands of nodes and petabytes of data. Therefore, the development of spatial indices, we will perform for database HBase. Mathematical Methods for solving the problem to build a spatial index is proposed to use a data structure quadtree (quadtree). Quadtree – a tree data structure in which the root and each internal node has four child nodes [4]. This data structure has been designed specifically for the breakdown of two-dimensional space by recursively dividing it into four quadrants (Fig. 1).

Figure 1 – Principle of the quadrants of the tree 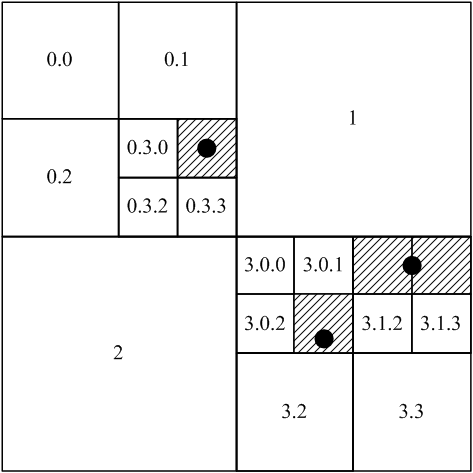
Figure 2 – Indexing spatial objects, blocking The root of the tree divides the region into four quadrants NE, SE, SW, SE (in accordance with the card). Each level of the tree quadrants requires two bits of code Morton. To encode geographic coordinates, we propose to use the code length of 64 bits. Since the geographic coordinates of the Earth range from -90° to 90° in latitude and from -180° to 180° of longitude 64-bit code will allow Morton to set the coordinates to an accuracy up to seven decimal places in decimal degrees. Morton codes were chosen due to ease of calculation of the cell numbers in the geometric coordinates. Spatial databases operate on two-dimensional geometric objects such as point, polyline and polygon. The point in the two-dimensional space is represented by two geographical coordinates: longitude and latitude. Consider the algorithm for determining the Morton code for the coordinates of the two-dimensional space: In order to get the code for the node containing Morton's point, it is enough to translate the indices x and y in the binary representation, and then build a new number, in turn, taking on one category of the binary representation of each number [5, 6]. Let us now consider a more complicated case, when indexed by a spatial object represented by a broken line or a polygon. Any two-dimensional object can be replaced by the described rectangle (bounding box) [7, 8], with some loss of accuracy. This allows us to simplify calculations and to significantly increase the processing speed of spatial queries. This approach is common practice in the construction of the indices of spatial data. Thus, an arbitrary two-dimensional object when indexing is described as a rectangle. Quadtree has the property of adaptability. It means. That spatial objects can be indexed nodes at different levels. It all depends on the area of the indexed object. If the point is indexed, the site uses the lower level (Fig. 2, Fig. 3). If the object is represented by a rectangle is indexed, the reference to it is written in a knot the size of which exceeds the minimum size of the rectangle [1]. 
Figure 3 – Indexing of spatial objects, the tree structure
Mutual influence between spatial objects defined by topological relation, distance and direction between the objects.
To determine the topological relations between two spatial objects A and B are commonly used following predicates [9, 10]:
As a result of an analysis of geographic information systems, they identified the major deficiencies in terms of indexing and retrieval of spatial data. To solve this problem, we developed a method of indexing spatial data in the database HBase.
|
