
| Резюме Біографія Реферат |
|
Тема: Методи та алгоритми оптимізації доступу до просторових даних в СУБД HBase Содержание:
Типові завдання інтелектуального аналізу просторових даних включають кластеризацію, класифікацію та визначення трендів. Основна відмінність між отриманням знань в звичайних базах даних і в просторових – це те, що атрибути сусідів певного просторового об’єкта мають вплив на сам цей об’єкт. Тому алгоритми вилучення знань з просторових даних сильно залежать від ефективності процесу визначення ставлення сусідства для будь-якого просторового об’єкта. Операція визначення ставлення сусідства між просторовими об’єктами вимагає багато обчислювального часу. Простий алгоритм пошуку сусідніх об’єктів має обчислювальну складність, так як необхідно переглядати всі пари об’єктів. Таким чином, метою роботи є аналіз проблеми актуальності даних генеруються в ГІС, а також виявлення методів і алгоритмів, за допомогою яких можна ефективно індексувати просторові дані [1]. Останнім часом з’являється велика кількість інформаційних систем генеруючих просторові дані. Такі системи зазвичай називають геоінформаційними системами (ГІС). Це такі системи як сенсорні мережі, системи дистанційного зондування Землі, супутниковий моніторинг транспорту. Все це говорить про те, що кількість та обсяги просторових баз даних будуть продовжувати швидко рости. Інтелектуальний аналіз цих даних може дати багато корисної інформації про реальний фізичний світ і допомогти у вирішенні своїх завдань експертам таких предметних областей як екологія, землеустрій, муніципальне управління, транспорт, економіка і багатьох інших. Наукова новизна полягає у використанні кодів Мортона і деревоподібної структури даних такий, як дерево квадрантів, які дозволять індексувати просторові об’єкти для їх подальшої обробки. Такий підхід повинен забезпечити високу продуктивність в розподілених системах використовують СУБД HBase. Заплановані практичні результати За допомогою даної роботи передбачається отримати рішення проблеми індексації просторових даних одержуваних з геоінформаційних систем.
Істотною відмінністю ГІС від інших інформаційних систем з просторовою локалізацією даних є включення в опис просторових об'єктів топологічних характеристик і класифікація на цій основі просторових об’єктів на: точкові, лінійні і майданні (ареальні). Тимчасової аспект, як правило, включає три фактори довготривалий, середньо тимчасовий і оперативний. З цим аспектом пов’язана характеристика якості інформації – актуальність і процедура актуалізації даних.
За тимчасової характеристики інформація, що зберігається і ДПС, звичайно підрозділяється на:
Системи розподіленого зберігання і обробки даних Для роботи з великими обсягами даних останнім часом все активніше використовується розподілене зберігання і обробка. Причому спостерігається перехід від використання високопродуктивних мейнфреймів до кластерним системам, що складається з великого числа недорогих серверів з архітектурою x86-64 [2]. Після опублікування фірмою Google статей розкриває принципи зберігання та обробки даних, реалізовані їй для своїх сервісів [3, 4], з’явилися відкриті проекти, які реалізують ці принципи. Найбільш успішним з них на сьогоднішній день є проект Hadoop. Hadoop є вільним Java фреймворком, що підтримує виконання розподілених додатків, що працюють на великих кластерах, що об’єднують звичайні сервера під управлінням відкритої операційної системи Linux. Для розподіленого зберігання даних використовується файлова система Hadoop Distributed File System (HDFS), яка є відкритим аналогом Google File System (GFS). Поверх цієї файлової системи працює СУБД HBase, яка є аналогом СУБД BigTable від Google [3]. В Hadoop реалізована обчислювальна парадигма, відома як MapReduce [4]. Згідно цій парадигмі додаток поділяється на велику кількість невеликих завдань, кожне з яких може бути виконано на будь-якому з вузлів кластера. Всі ці технології дозволяють досягти дуже високої агрегованої пропускної здатності кластера. Ця система дозволяє додаткам легко масштабуватися до рівня тисяч вузлів і петабайт даних. Тому розробку просторових індексів ми будемо виконувати для СУБД HBase. Математичні методи розв’язання задачі Для побудови просторового індексу пропонується використовувати структуру даних дерево квадрантів (quadtree). Дерево квадрантів – це деревовидна структура даних, в якій кореневої і кожен внутрішній вузол має чотири дочірніх вузла [4]. Ця структура даних була розроблена спеціально для розбивки двовимірного простору за допомогою рекурсивного поділу його на чотири квадранта (рис. 1).

Рисунок 1 – Принцип використання дерева квадрантів 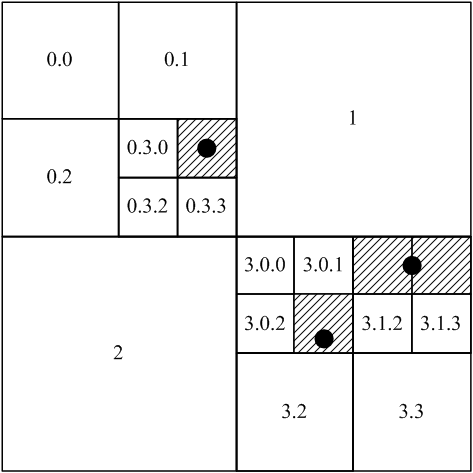
Рисунок 2 – Індексація просторових об’єктів, розбивка на блоки Корінь дерева ділить область на 4 квадранта СВ, СЗ, Пд, Пд (відповідно до карти). Кожен рівень дерева квадрантів вимагає два біти коду Мортона. Для кодування географічних координат ми пропонуємо використовувати код довжиною 64 біта. Так як географічні координати Землі варіюються від -90° до 90° по широті і від -180° до 180° по довготі 64-х бітний код Мортона дозволить ставити координати з точністю аж до сьомого знака після коми в десятковому поданні градусів. Коди Мортона були обрані завдяки простоті розрахунку номера осередку по геометричних координатах. Просторові бази даних оперують такими двовимірними геометричними об’єктами як точка, ламана лінія і багатокутник. Точка в двовимірному просторі представляється двома географічними координатами: довготою і широтою. Розглянемо алгоритм визначення коду Мортона для координат точки в двовимірному просторі: Для того, щоб отримати код Мортона для вузла містить точку, досить перевести індекси x і y в бінарне подання, після чого побудувати нове число, по черзі беручи по одному розряду з двійкового подання кожного числа [5, 6]. Розглянемо тепер більш складний випадок, коли індексується просторовий об’єкт, представлений ламаної або багатокутником. Будь двовимірний об’єкт може бути замінений описаним прямокутником (bounding box) [7, 8] з деякою втратою точності. Це дозволяє спростити розрахунки і значно збільшити швидкість обробки просторових запитів. Використання цього підходу є звичайною практикою при побудові індексів просторових даних. Таким чином, довільний двовимірний об’єкт при індексації представляється у вигляді описаного прямокутника. Дерево квадрантів має властивість адаптивності. Це означає. Що просторові об’єкти можуть індексуватися вузлами різного рівня. Все залежить від площі індексуємого об’єкта. Якщо індексується точка, то використовується вузол нижнього рівня (рис. 2, рис. 3). Якщо ж індексується об’єкт представлений прямокутником, то посилання на нього записується у вузол, розмір якого мінімально перевищує розмір цього прямокутника [1]. 
Рисунок 3 – Індексація просторових об’єктів, деревоподібна структура
Взаємний вплив між просторовими об’єктами визначається топологічним ставленням, відстанню та напрямком між об’єктами.
Для визначення топологічних відносин між двома просторовими об’єктами A і B зазвичай використовуються такі предикати [9, 10]:
В результаті роботи був проведений аналіз геоінформаційних систем, виявлено основні їх недоліки у плані індексування та вилучення просторових даних. Для вирішення даної проблеми був розроблений метод індексації просторовий даних в СУБД HBase.
|
