
Abstract
Содержание
Introduction
Every year in the world during childbirth and postpartum 350–370 women die. The most common reason of death is obstetric hemorrhage. Obstetric haemorrhage is one of the most dangerous complications that can occur during childbirth, the frequency of occurrence is 2–3% in all cases.
Ability to predict pathological obstetric hemorrhage before birth will promptly create a stock of blood substitutes, plasma, blood products, autologous blood, and perhaps provides adequate therapy with highly trained intensive care, obstetricians and vascular surgeons for sparing operations (ligation of vascular bundles and hypogastric arteries) in the case of postpartum hemorrhage.
1. Formulation of the problem
The main goal in constructing a mathematical function of classification or regression is to choose the best one from the set of possible variants. The problem is that there may be various functions that classify the same training data sets with the same accuracy (fig. 1).
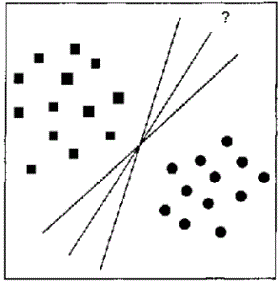
Figure 1 – Variants of linear division of teaching selection
To build a regression model the necessary factors have to be selected, and the coefficients of the equation have to be calculated. It is natural that choosing a particular set of parameters we can obtain different regression models and many of them will give good results. Therefore, to construct an optimal in some way model we have to solve two problems: to select a risk factors wich will be variables of multiple regression, and to calculate the coefficients of the equation. Selection of risk factors is a challenging task [1], which can be solved using the GA [2]. It is proposed to solve these two problems simultaneously.
2. Development of method
Standard GA [3, 4] supposes a next sequence, (fig. 2).
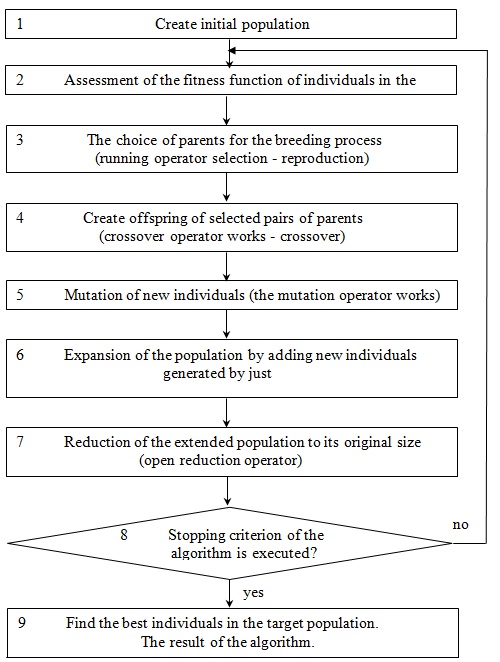
Figure 2 – Simple genetic algorithm
- On the first stage the generation of initial populyacii is executed, where casual appearance is generate the several of individuals. The important stage
is development of method of encoding of chromosome, because every individual it is a possible decision of task (equalization of multiple regression).
We offer the next structure of chromosome (fig. 3). Every individual appears the sequence of certain amount of bits (determined the maximally possible amount
of risk factors). The value of every bit can be equal "1", if a factor with the proper number is in this equalization of regression, and "0", if this factor
absents. Thus, a regressive model, built a least-squares method (LSM), corresponds every chromosome, with the proper its structure by the set of risk factors.

Figure 3 – Encoding of chromosome
(animation: 7 frames, 6 cycles of repetition, 63,8 Kb) - The second stage is implied by the calculation of fitnes-function. The error of regressive model which can settle accounts on a formula comes forward
as a fitnes-function (1):
where N – is an amount of examples in teaching, y – is the got result of regressive model, yy – is an actual result.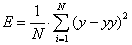
(1)
The expected error is compared every chromosome. The best individual will have a minimum error, that minimum fitnes-function.
The third stage is realization of genetic algorithm. Genetic operators are executed standard. - The most widespread method of realization of operator of reproduction (OR) is a construction of wheel of roulette, in which a sector, proportional its value of fitness-function, corresponds every chromosome, that provides large probability of choice of the best individuals for the operator of crossing-over.
- The simple is used operator of crossing-over (OC) which is executed in 3 stages:
1) two chromosomes (parents) get out from current populyacii;
2) by chance the point of crossing gets out is a number k to from a range [1,2...n–1], where n – is length of chromosome;
3) two new chromosomes ,
, 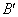 (descendants) formed from An and B by the exchange of sublines after the point of crossing, (fig. 4).
(descendants) formed from An and B by the exchange of sublines after the point of crossing, (fig. 4).
OC – is executed with the set probability (the selected two parents produce descendants not necessarily).
Figure 4. Forming of chromosomes the operator of crossing-over
- The operator of mutation (OM) plays the second role and his probability usually small. The operator of mutation is executed in 2 stages:
1) in a chromosome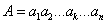 k position (bit) of mutation gets out by chance (1 <= k <= n);
k position (bit) of mutation gets out by chance (1 <= k <= n);
2) the inversion of value of gene is produced in k position, formula (2).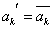
(2) - The next stage of algorithm is supposed by expansion of populyacii due to addition of new, just created individuals.
- Abbreviate then got populyaciyu to the initial sizes (the operator of reduction works), by the selection of the best individuals.
- Criteria of stop of work of algorithm it will be two: maximally set amount of steps; insignificant change of value a fitnes-function.
- After implementation of criterion of stop the search of the best individual is executed in eventual populyacii, that is a job of algorithm performance (equalization of multiple regression). In case, not implementations of criterion of stop, passed to the point 2.
Conclusion
In this article the actual problem of selecting the best regression model for predicting blood loss during delivery was discussed. In the future we're planning to realise this mathematical theory and test it on real medical data provided by the staff of the center of motherhood and childhood. We'we planning to develop and implement the prediction of obstetric hemorrhage decision support systems (DSS).
References
- Т.А. Васяева Анализ методов отбора факторов риска развития патологий в акушерстве и гинекологии / Т.А. Васяева, Д.Е. Иванов, И.В. Соков, А.С. Сокова // Збірка матеріалів ІІ Всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених.ІУС КМ-2011 11–13 квітня 2011р., Донецьк: ДонНТУ, 2011. – № 1. – С. 209–212.
- Т.А. Васяева Отбор факторов риска потери крови при родах / Т.А. Васяева, Д.Е. Иванов, И.В. Соков. // Інтелектуальні системи прийняття рішень і проблеми обчислювального інтелекту: Матеріали міжнародної наукової конференції. – Херсон: ХНТУ, 2011. – № 1. – 472 с.
- Ю.О. Скобцов Основи еволюційних обчислень / Ю.О. Скобцов. – Донецьк: ДонНТУ, 2009. – 316 с.
- Д. Рутковская Нейронные сети, генетические алгоритмы и нечеткие системы / Д. Рутковская М. Пилиньский, Л. Рутковский. – М.: 2004. – 452 c.
- Г.К. Вороновский Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности / Г.К. Вороновский, К.В. Махотило, С.Н. Петрашев, С.А. Сергеев // заказное. – Х.: ОСНОВА, 1997. – 112 с.
- М.В. Медведев Дифференциальная ультразвуковая диагностика в гинекологии. // М.В. Медведев, Б.И. Зыкин, В.Л. Хохолин, Н.Ю. Стручкова. – М.: Видар, 1997.
- Генетические алгоритмы [Электронный ресурс]. – Режим доступа: http://www.gotai.net/documents/doc-ga-002.aspx.
- Популярно про генетичні алгоритми [Электронный ресурс]. – Режим доступа: http://www.victoria.lviv.ua/html/oio/html/theme10.htm.
- Genetic Algorithms [Электронный ресурс]. – Режим доступа: http://www.doc.ic.ac.uk/~nd/surprise_96/journal/vol4/tcw2/report.html.
- Генетические алгоритмы [Электронный ресурс]. – Режим доступа: http://www.neuroproject.ru/genealg.htm.