
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Наукова новизна
- 4. Огляд досліджень і розробок
- 4.1 Нейронні мережі
- 4.1.1 Розробка методу з використанням нейронних мереж та ГА
- 4.2 Генетичні алгоритми
- 4.2.1 Розробка методу з використанням ГА
- Висновки
- Перелік посилань
Вступ
Ефективність роботи будь-якої галузі значною мірою визначається рівнем інформаційних технологій та широтою їх вживання. У медицині особливого значення набуває напрям, пов’язаний з розробкою систем підтримки прийняття рішень, розвитком телемедицини, оскільки всі ці удосконалення і визначають нові діагностичні і лікувальні можливості. Системи інтелектуальної підтримки прийняття лікарського рішення (діагностичного або лікувального) інформують лікаря про критичні ситуації в стані пацієнта, пов’язаних з виходом окремих показників стану організму за допустимі значення. Добре відомо, що людина не в змозі стежити за поведінкою більше семи яких-небудь об’єктів (параметрів) одночасно. Тому із зростанням кількості, що повідомляються такими системами фактів критичної зміни показників стану пацієнта аналіз ситуації і прийняття лікаркою діагностичних і лікувальних рішень стає усе більш скрутним. Легко собі уявити, що позамежна кількість інформації, що поступає до лікаря, здатна стати перешкодою для ухвалення обгрунтованих лікарських рішень. Таким чином, система надання інтелектуальної підтримки вирішенням лікаря, повинна узяти на себе функцію попереднього стиснення і узагальнення інформації, виділення істотних елементів і відсіювання непотрібної інформації, що заважає.
1. Актуальність теми
Щорічно в світі при пологах і в післяпологовому періоді помирає 350–370 жінок. Найчастіша причина смертності &ndash акушерське кровотеча. Акушерські кровотечі є одним з найнебезпечніших ускладнень, які можуть статися під час пологів, частота їх появи 2–3% з усіх випадків. Можливість прогнозування патологічної акушерської крововтрати напередодні пологів дозволить своєчасно створити запаси кровозамінників, плазми, препаратів крові, можливо і аутокрові, а також надати адекватну терапію із залученням висококваліфікованих реаніматологів, акушерів-гінекологів та судинних хірургів для проведення органозберігаючих операцій (перев’язка судинних пучків і подчревних артерій) у випадку розвитку післяпологового кровотечі.
2. Мета і задачі дослідження та заплановані результати
Метою дослідження є вибір напрямку власних досліджень в області прогнозування розвитку патологій в акушерстві та гінекології, розробка СКС прогнозування розвитку втрати крові при пологах за допомогою ГА.
Основні задачі дослідження:
- Аналіз поставленої проблеми прогнозування розвитку патологій в акушерстві та гінекології
- Розгляд існуючих методів прогнозування розвитку патологій в акушерстві та гінекології.
- Розробка алгоритму прогнозування розвитку патологій в акушерстві та гінекології.
- Розробка програмного забезпечення СКС прогнозування розвитку патологій в акушерстві та гінекології.
Об’єкт дослідження: процес проектування і розробки методів отримання знань медичних систем підтримки прийняття рішень
Предмет дослідження: методи розробки отримання знань для систем підтримки прийняття рішень в акушерстві та гінекології
Методи дослідження базуються на методах штучного інтелекту, основних положеннях теорії ймовірностей та математичної статистики. Передбачається застосувати метод групового обліку аргументів, генетичний алгоритм.
3. Наукова новизна
Наукова новизна полягає в кодуванні хромосоми і застосуванні генетичного алгоритму для побудови регресійної моделі та відбору чинників ризику одночасно.
Нейронні мережі можна розглядати як сучасні обчислювальні системи, які перетворюють інформацію по образу процесів, що відбуваються в мозку людини. Оброблювана інформація має чисельний характер, що дозволяє використовувати нейронну мережу, наприклад, в якості моделі об’єкта з абсолютно невідомими характеристиками. Інші типові програми нейронних мереж охоплюють задачі розпізнавання, класифікації, аналізу і стиснення образів.
У самому спрощеному вигляді нейронну мережу можна розглядати як спосіб моделювання в технічних системах принципів організації та механізмів функціонування головного мозку людини. Згідно сучасним уявленням, кора головного мозку людини є безліч взаємопов’язаних найпростіших осередків &ndash нейронів, кількість яких оцінюється числом близько 10 10 . Технічні системи, в яких робиться спроба відтворити, нехай і в обмежених масштабах, подібну структуру (апаратно або програмно), отримали найменування нейронні мережі.
Даний метод складно реалізуємо так як практично важко відстежити правильність роботи даного методу на етапі налагодження. А так же неможливість інтерпретації проміжних даних і складність роз’яснення результатів роботи мережі робить даний метод вкрай незручним для застосування у даному випадку.
Відбір інформативних параметрів виконується за допомогою нейронних мереж (НС) [4, 5] та генетичних алгоритмів (ГА) [2, 3]. Такий підхід (спільне використання НС та ГА) дозволить не просто виконати відбір факторів ризику, а вибрати інформативний набір даних, зберігши взаємопов’язані змінні.
Перекласти з такої мови: російськаДля реалізації такого підходу спочатку необхідно розробити НС для визначення ризику розвитку акушерських кровотеч. Для практики найважливішим є визначення ризику втрати крові при пологах більш ніж 0,5% від маси тіла, з метою вжиття відповідних заходів. В цьому випадку, по суті, виконується класифікація на два класи: патологічне кровотеча і допустиме. Для реалізації поставленого завдання в такій формі доцільно використовувати багатошарову НС прямого поширення. Такий тип НС показує гарні результати при навчанні з учителем, а так як у нас є навчальна вибірка з реальними медичними даними, то виберемо багатошарову НС для класифікації на патологічну і звичайну втрату крові при пологах. Таким чином, на першому етапі необхідно вибрати архітектуру нейронної мережі та навчити її. Враховуючи те, що в подальшому (при відборі факторів ризику) на кожному кроці виконання ГА відбуватиметься навчання НС, доцільно вибирати архітектуру мережі з мінімальною складністю, що дозволить зменшити час виконання програми. Під складністю мережі будемо припускати обчислювальну складність алгоритму навчання НС. Під обчислювальної складністю алгоритму навчання будемо розуміти кількість операцій за один крок навчання. Відомо, що для алгоритму зворотного поширення кількість операцій пов’язано лінійною залежністю з синаптичними вагами (включаючи пороги) [1]. Тобто обчислювальну складність визначає число прихованих шарів і число нейронів на кожному з них. В результаті проведених експериментів обрана архітектура НС, представлена на рис.1. Кількість входів обумовлено максимальною кількістю чинників ризику (після кодування їх отримали 99). Вибрані активаційні функції – гіперболічний тангенс і лінійна функція.
Після того як визначена і успішно навчена НС, виконується ГА, який подає різні комбінації чинників ризику на входи НС і потім виконується спроба навчити мережу при такій комбінації відібраних факторів ризику. Принцип реалізації кодування хромосоми представлений на рис. 2. Кожна хромосома являє собою послідовність певної кількості бітів (визначається максимальною кількістю чинників ризику). Значення кожного біта дорівнює 1, якщо фактор з відповідним номером присутній в даному наборі, і нулю, якщо цей фактор відсутній. Передбачені різні варіанти параметрів ГА в Як метод селекції можна вибирати колесо рулетки або турнір (із зазначенням кількості особин у турі), як метод редукції передбачена елітарна стратегія, повна заміна, часткова заміна популяції (із зазначенням відсотка замінних особин), можна задавати ймовірність операції мутації і схрещування (передбачений одноточковий і двоточковим оператор схрещування). В якості критерію зупину можна використовувати певну кількість ітерацій або вказати кількість повторень результату.
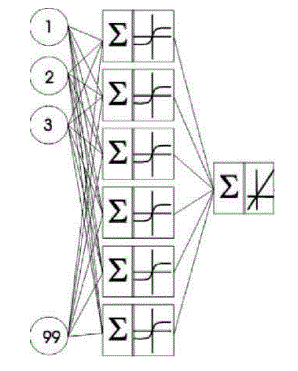
Рисунок 1 – Архітектура нейронної мережі
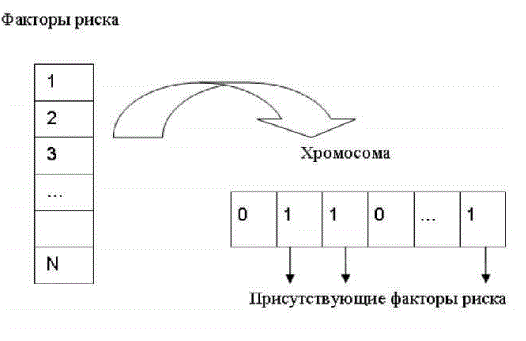
Рисунок 2 – Кодування хромосоми
У пропонованому підході для виділення ознак використаний генетичний алгоритм, який має модифіковану схему реалізації стосовно до завданню багатокритеріальної оптимізації. У той час як більшість подібних методів, використовуваних для рішення таких задач, використовує єдиний, складовою оптимізуються критерій [4]. Рішенням задачі в даному випадку є кілька недомініруемих підмножин ознак. Розроблено фітнес-функція (1), яка передбачає пошук рішення, що є оптимальним згідно двома критеріями – враховується точність класифікації та кількість факторів ризику. До того ж дана фітнес-функція дозволяє задавати бажане співвідношення точності класифікації та кількості факторів ризику.
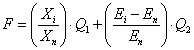 |
(1) |
де Xi – кількість присутніх факторів ризику в i-й хромосомі, Xn – максимальна кількість факторів ризику, Ei – помилка навчання НС для i-ої хромосоми, En – помилка навчання НС під час використання максимальної кількості факторів, Q1 і Q2 – коефіцієнти, за допомогою яких регулюється співвідношення між точністю класифікації і числом факторів ризику. Рекомендується вибирати діапазон значень (2), і дотримуватися умови (3).
| (2) |
| (3) |
Після етапу підготовки даних отримали навчальний масив розміром 99 х 100, де 99 вхідних параметрів та 100 навчальних прикладів. Дана вибірка розділена на дві – по 50 прикладів в кожній. За першою вибіркою проводилося навчання нейронної мережі та відбір ознак за допомогою генетичних алгоритмів. В результаті кількість факторів зменшилася практично у два рази. Потім, на другий виборці успішно протестована нейронна мережа, з використанням тільки виділених факторів. Таким чином, результат можна вважати позитивним і переходити до етапу побудови і навчання аналітичної системи прогнозування втрати крові при пологах.
Генетичний алгоритм являє собою метод, який відбиває природну еволюцію методів вирішення проблем, і в першу чергу завдань оптимізації. Генетичні алгоритми – це процедури пошуку, засновані на механізмах природного відбору і спадковості. У них використовується еволюційний принцип виживання найбільш пристосованих особин. Вони відрізняються від традиційних методів оптимізації декількома базовими елементами. Зокрема, генетичні алгоритми:
- обробляють не значення параметрів самого завдання, а їх закодовану форму;
- здійснюють пошук рішення виходячи не з єдиної точки, а з їх деякої популяції;
- використовують тільки цільову функцію, а не її похідні або іншу додаткову інформацію;
- застосовують імовірнісні, а не детерміновані правила вибору.
Пошук (суб) оптимального рішення задачі виконується в процесі еволюції популяції – послідовного перетворення одного кінцевого безлічі рішень в інше за допомогою генетичних операторів репродукції, кроссинговера і мутації. Наявність у генетичних алгоритмів цілої “популяції” рішень спільно з імовірнісним механізмом мутації, дозволяють припускати меншу ймовірність знаходження локального оптимуму й більшу.
Генетичні алгоритми призначені для вирішення завдань оптимізації. Прикладом такого завдання може служити навчання нейромережі, тобто підбору таких значень ваг, при яких досягається мінімальна помилка. При цьому в основі генетичного алгоритму лежить метод випадкового пошуку. основним недоліком випадкового пошуку є те, що нам невідомо скільки знадобиться часу для виконання завдання. Для того, щоб уникнути таких витрат часу при вирішенні завдання, застосовуються методи, що проявилися в біології. При цьому використовуються методи відкриті при вивченні еволюції і походження видів. Як відомо, в процесі еволюції виживають найбільш пристосовані особини. Це призводить до того, що пристосованість популяції зростає, дозволяючи їй краще виживати в умовах, що змінюються.
Вперше подібний алгоритм був запропонований в 1975 році Джоном Холландом (John Holland) в Мічиганському університеті. Він отримав назву “репродуктивний планї Холланда” та ліг в основу практично всіх варіантів генетичних алгоритмів. Однак, перед тим як ми його розглянемо докладніше, необхідно зупиниться на тому, яким чином об’єкти реального світу можуть бути закодовані для використання в генетичних алгоритмах [6].
Подання об’єктів
З біології ми знаємо, що будь-який організм може бути представлений своїм фенотипом, який фактично визначає, чим є об’єкт в реальному світі, і генотипом, який містить всю інформацію про об’єкт на рівні хромосомного набору. При цьому кожен ген, тобто елемент інформації генотипу, має своє відображення у фенотипі. Таким чином, для вирішення завдань нам необхідно представити кожну ознаку об’єкта у формі, що підходить для використання в генетичному алгоритмі. Все подальше функціонування механізмів генетичного алгоритму проводиться на рівні генотипу, дозволяючи обійтися без інформації про внутрішню структуру об’єкта, що й обумовлює його широке застосування в самих різних завданнях.
У найбільш часто зустрічається різновиди генетичного алгоритму для подання генотипу об’єкту застосовуються бітові рядки. При цьому кожному атрибуту об’єкта у фенотипі відповідає один ген в генотипі об’єкта. Ген являє собою бітовий рядок, найчастіше фіксованої довжини, яка являє собою значення цієї ознаки.
Кодування ознак, представлених цілими числами
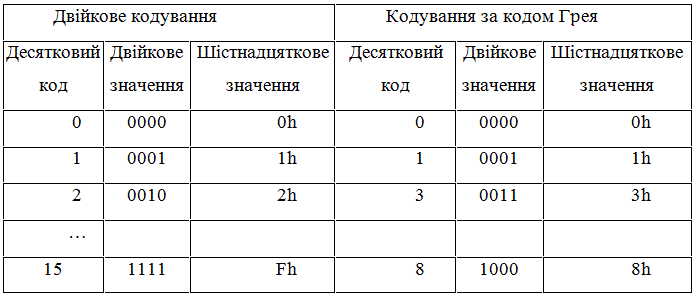
Для кодування таких ознак можна використовувати найпростіший варіант – бітове значення цієї ознаки. Тоді нам буде дуже просто використовувати ген певної довжини, достатньої для подання всіх можливих значень такої ознаки. Але, на жаль, таке кодування не позбавлене недоліків. основний недолік полягає в тому, що сусідні числа відрізняються в значеннях кількох бітів, так наприклад числа 7 і 8 у бітовому поданні відрізняються в 4-х позиціях, що ускладнює функціонування генетичного алгоритму і збільшує час, необхідний для його збіжності. Для того, щоб уникнути цю проблему краще використовувати кодування, при якому сусідні числа відрізняються меншою кількістю позицій, в ідеалі значенням одного біта. Таким кодом є код Грея, який доцільно використовувати в реалізації генетичного алгоритму. Значення кодів Грея розглянуті в таблиці нижче:
Таблиця 1 – Відповідність десяткових кодів і кодів Грея
Таким чином, при кодуванні цілочисельної ознаки ми розбиваємо його на тетради і кожну тетраду перетворюємо за кодом Грея.
В практичних реалізаціях генетичних алгоритмів зазвичай не виникає необхідності перетворювати значення ознаки в значення гена. На практиці має місце зворотна задача, коли за значенням гена необхідно визначити значення відповідного йому ознаки.
Таким чином, задача декодування значення генів, яким відповідають цілочисельні ознаки, тривіальна.
Схема функціонування генетичного алгоритму
Тепер, знаючи як інтерпретувати значення генів, перейдемо до опису функціонування генетичного алгоритму. Розглянемо схему функціонування генетичного алгоритму в його класичному варіанті.
- Ініціювати початковий момент часу t=0. Випадковим чином сформувати початкову популяцію, що складається з k особин:
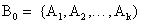
- Обчислити пристосованість кожної особини
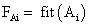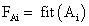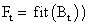 , i=1…k і популяції в цілому
, i=1…k і популяції в цілому 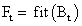 (також іноді звану терміном фіттнес). Значення цієї функції визначає наскільки добре підходить особина, описана даної хромосомою, для вирішення завдання.
(також іноді звану терміном фіттнес). Значення цієї функції визначає наскільки добре підходить особина, описана даної хромосомою, для вирішення завдання.
- Вибрати особину
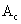 з популяції
з популяції 
- З певною вірогідністю (ймовірністю кросовера) вибрати другу особину з популяції
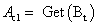 і провести оператор кросовера
і провести оператор кросовера 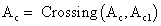 .
.
- З певною вірогідністю (ймовірністю мутації) виконати оператор мутації .
- З певною вірогідністю (ймовірністю інверсії) виконати оператор інверсії
 .
.
- Помістити отриману хромосому в нову популяцію
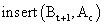 .
.
- Виконати операції, починаючи з пункту 3, k раз.
- Збільшити номер поточної епохи t=t+1.
- Якщо виповнилося умова зупину, то завершити роботу, інакше перехід на крок 2.
Тепер розглянемо детальніше окремі етапи алгоритму.
Найбільшу роль в успішному функціонуванні алгоритму грає етап відбору батьківських хромосом на кроках 3 та 4. При цьому можливі різні варіанти.
Найбільш часто використовується метод відбору, званий рулеткою. При використанні такого методу ймовірність вибору хромосоми визначається її пристосованістю,
тобто ![]() . Використання цього методу призводить до того, що ймовірність передачі ознак більш
пристосованими особинами нащадкам зростає. Інший часто використовуваний метод – турнірний відбір. Він полягає в тому, що випадково вибирається кілька особин
з популяції (зазвичай 2) і переможцем вибирається особина з найбільшою пристосованістю. Крім того, в деяких реалізаціях алгоритму застосовується так
звана стратегія елітизму, яка полягає в тому, що особини з найбільшою пристосованістю гарантовано переходять в нову популяцію. Використання
елітизму зазвичай дозволяє прискорити збіжність генетичного алгоритму. Недолік використання стратегії елітизму в тому, що підвищується ймовірність попадання
алгоритму в локальний мінімум.
. Використання цього методу призводить до того, що ймовірність передачі ознак більш
пристосованими особинами нащадкам зростає. Інший часто використовуваний метод – турнірний відбір. Він полягає в тому, що випадково вибирається кілька особин
з популяції (зазвичай 2) і переможцем вибирається особина з найбільшою пристосованістю. Крім того, в деяких реалізаціях алгоритму застосовується так
звана стратегія елітизму, яка полягає в тому, що особини з найбільшою пристосованістю гарантовано переходять в нову популяцію. Використання
елітизму зазвичай дозволяє прискорити збіжність генетичного алгоритму. Недолік використання стратегії елітизму в тому, що підвищується ймовірність попадання
алгоритму в локальний мінімум.
Інший важливий момент – визначення критеріїв зупину. Звичайно як них застосовуються або обмеження на максимальне число епох функціонування алгоритму, або визначення його збіжності, зазвичай шляхом порівнювання пристосованості популяції на декількох епохах і зупинки при стабілізації цього параметра.
При побудові математичної функції класифікації або регресії основна задача зводиться до вибору найкращої функції з усієї безлічі варіантів. Справа в тому, що може існувати безліч функцій, однаково класифікуючих одну і ту ж навчальну вибірку (рис. 3).
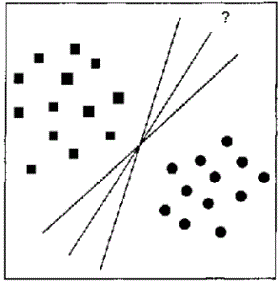
Рисунок 3 – Варіанти лінійного поділу навчальної вибірки
Для побудови регресійної моделі необхідно виконати відбір необхідних факторів і потім розрахувати коефіцієнти рівняння. Природно вибираючи той чи інший набір параметрів можна отримувати різні регресійні моделі, причому багато з них будуть показувати хороші результати. Таким чином, для побудови оптимальної моделі необхідно вирішити два завдання: вибрати фактори ризику, які будуть змінними множинної регресії, і розрахувати коефіцієнти рівняння. Відбір факторів ризику є непростою задачею [4], яку можна вирішувати за допомогою ГА [5]. Пропонується вирішувати ці дві задачі одночасно.
Разробка методу
Стандартний ГА [3, 2] передбачає наступну послідовність, (рис.4).
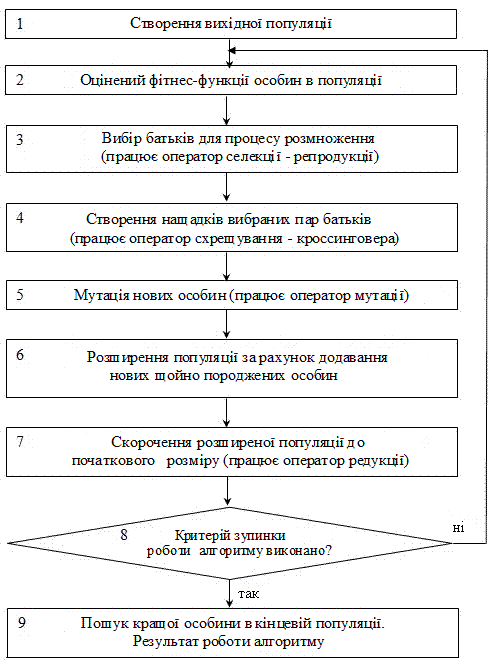
Рисунок 4 – Простий генетичний алгоритм
- На першому етапі виконується генерація початкової популяції, де випадковим чином генерується певна кількість особин. Важливим етапом є
розробка способу кодування хромосоми, так як кожна особина це можливе рішення задачі (рівняння множинної регресії). Ми пропонуємо наступну
структуру хромосоми (рис. 5). Кожна особина представляється послідовністю певної кількості бітів (визначається максимально можливою кількістю
факторів ризику). Значення кожного біта може дорівнювати “1”, якщо фактор з відповідним номером присутній в даному рівнянні регресії, і “0”, якщо цей
фактор відсутній. Таким чином, кожній хромосомі відповідає регресійна модель, побудована методом найменших квадратів (МНК), з відповідним її
структурі набором факторів ризику.

Рисунок 5 – Кодування хромосоми
(анімація: 7 кадрів, 6 циклів повторення, 55,9 кілобайт) - Другий етап передбачає розрахунок фітнес-функції. В якості фітнес-функції виступає помилка регресійної моделі, яка може розраховуватися по
формулою (4):
де N – кількість прикладів у навчанні, y – отриманий результат регресійної моделі, yy – дійсний результат.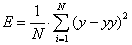
(4)
Розрахована помилка зіставляється кожній хромосомі. Краща особина буде мати мінімальну помилку, тобто мінімальну фітнес-функцію.
Третій етап є реалізацією генетичного алгоритму. Генетичні оператори виконуються стандартні. - Найбільш поширений метод реалізації оператора репродукції (ОР) – побудова колеса рулетки, в якому кожній хромосомі відповідає сектор, пропорційний її значенням фітнес-функції, що забезпечує більшу ймовірність вибору кращих особин для оператора кросинговеру.
- Застосовується простий оператор кроссинговера (ОК), який виконується в 3 етапи:
1) вибираються дві хромосоми (батьки) з поточної популяції;
2) випадково вибирається точка схрещування – число k з диапазону [1,2…n-1], де n – довжина хромосоми;
3) дві нових хромосоми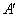 ,
, 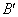 (потомки) (нащадки) формуються з A і B шляхом обміну підрядків після точки схрещування, (рис. 6).
(потомки) (нащадки) формуються з A і B шляхом обміну підрядків після точки схрещування, (рис. 6).
ОК виконується з заданою вірогідністю (відібрані два батьки не обов’язково проводять нащадків).).
Рисунок 6 Формування хромосом оператором кроссинговера
- Оператор мутації (ОМ) грає вторинну роль і його ймовірність зазвичай мала. Оператор мутації виконується в 2 етапи:
1) в хромосомі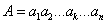 випадково вибирається k-ая позиція (біт)
мутації(1 <= k <= n);
випадково вибирається k-ая позиція (біт)
мутації(1 <= k <= n);
2) проводиться інверсія значення гена в k-й позиції, формула (5).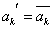
(5) - Наступний етап алгоритму припускає розширення популяції за рахунок додавання нових, щойно створених особин.
- Потім отриману популяцію скорочуємо до вихідних розмірів (працює оператор редукції), шляхом відбору найкращих особин.
- Критеріїв зупинки роботи алгоритму буде два: максимально задану кількість кроків, незначна зміна значення фітнес-функції.
- Після виконання критерію зупину виконується пошук кращої особини в кінцевій популяції, що є результатом роботи алгоритму (рівняння множинної регресії). У випадку, не виконання критерію зупину, переходимо на пункт 2.
Висновки
Процес проектування і розробки методів отримання знань медичних систем підтримки прийняття рішень є одним з важливих методів діагностики. У сфері сучасних технологій недостатня увага приділяється розробці СКС прогнозування розвитку патологій в акушерстві та гінекології, що дає можливість удосконалити і визначити нові діагностичні та лікувальні можливості. Для підвищення достовірності визначення патологій при вагітності на ранніх стадіях можна впровадити розроблені методи і раніше почати застосування профілактичних заходів, спрямованих на зниження загрози ризику здоров’я майбутньої мами.
Магістерська робота присвячена актуальній науковій завданню підвищення достовірності визначення патологій при вагітності на ранніх стадіях, впровадження розроблених методів для застосування профілактичних заходів, спрямованих на зниження загрози ризику здоров'я майбутньої мами. У рамках проведених досліджень виконано:
- Проналізіровано поставлена ??проблема прогнозування розвитку патологій в акушерстві та гінекології.
- Розглянуто існуючі методи прогнозування розвитку патологій в акушерстві та гінекології.
- Розроблено алгоритм прогнозування розвитку патологій в акушерстві та гінекології.
- Підготовка розглянутого математичного апарату для розробки програмного забезпечення СКС прогнозування розвитку патологій в акушерстві та гінекології.
Розглянуто актуальне завдання вибору кращої регресійної моделі, для прогнозування втрати крові при пологах. Надалі планується реалізувати розглянутий математичний апарат і провести експерименти на реальних медичних даних, наданими співробітниками центру материнства і дитинства. Планується розробка та впровадження системи підтримки прийняття рішень (СППР) прогнозування акушерських кровотеч.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2012 року. Повний текст роботи і матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- Саймон Хайкин Нейронные сети: полный курс, 2-е издание. : Пер. с англ. / Саймон Хайкин // Издательский дом «Вильямс». – М.: 2006. – 1104 c.
- Д. Рутковская Нейронные сети, генетические алгоритмы и нечеткие системы / Д. Рутковская М. Пилиньский, Л. Рутковский. – М.: 2004. – 452 c.
- Ю.О. Скобцов Основи еволюційних обчислень / Ю.О. Скобцов. – Донецьк: ДонНТУ, 2009. – 316 с.
- Т.А. Васяева Анализ методов отбора факторов риска развития патологий в акушерстве и гинекологии / Т.А. Васяева, Д.Е. Иванов, И.В. Соков, А.С. Сокова // Збірка матеріалів ІІ Всеукраїнської науково-технічної конференції студентів, аспірантів та молодих вчених.ІУС КМ-2011 11–13 квітня 2011р., Донецьк: ДонНТУ, 2011. – № 1. – С. 209–212.
- Т.А. Васяева Отбор факторов риска потери крови при родах / Т.А. Васяева, Д.Е. Иванов, И.В. Соков. // Інтелектуальні системи прийняття рішень і проблеми обчислювального інтелекту: Матеріали міжнародної наукової конференції. – Херсон: ХНТУ, 2011. – № 1. – 472 с.
- Г.К. Вороновский Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности / Г.К. Вороновский, К.В. Махотило, С.Н. Петрашев, С.А. Сергеев // заказное. – Х.: ОСНОВА, 1997. – 112 с.
- М.В. Медведев Дифференциальная ультразвуковая диагностика в гинекологии. // М.В. Медведев, Б.И. Зыкин, В.Л. Хохолин, Н.Ю. Стручкова. – М.: Видар, 1997.
- Генетические алгоритмы [Электронный ресурс]. – Режим доступа: http://www.gotai.net/documents/doc-ga-002.aspx.
- Популярно про генетичні алгоритми [Электронный ресурс]. – Режим доступа: http://www.victoria.lviv.ua/html/oio/html/theme10.htm.
- Genetic Algorithms [Электронный ресурс]. – Режим доступа: http://www.doc.ic.ac.uk/~nd/surprise_96/journal/vol4/tcw2/report.html.