
Abstract
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research, expected results
- 3. Recognition of a couple of classes, «hissing-pause»
- 4. Determination of the end of the word. Detection and isolation of the deaf explosive sound to the end of word
- Conclusion
- References
Introduction
Nowdays all over the world people works to create a more natural means of a person computer communication, among which first place tooks speech input information into the computer. The problem of speech input complicated by a number of factors: the difference in language specific pronunciation, noise, accents, accents, etc. This masters work is devoted to an analysis of existing algorithms and the specifics of the development of new approaches to speech recognition, in particular to improve the recognition of Russian speech sounds are at the end of the speech signal [1].
1. Theme urgency
Currently, speech recognition is becoming more and more new applications, ranging from applications performing the conversion of speech information in the text and ending with on-board devices while driving. All the variety of existing speech recognition systems [2-6] can be divided into the following groups:
1. Software kernel for hardware implementations of speech recognition systems;
2. Sets of libraries, tools for developing applications used speech recognition;
3. Independent custom applications, performing voice control and/or conversion of speech into text;
4. Specialized applications used speech recognition;
5. Devices that perform pattern recognition at the hardware level;
6. Theoretical research and development.
This research also purports to supplement the existing algorithms for speech signal processing and segmentation, thereby to provide an opportunity to improve the efficiency of existing systems for speech recognition.
2. Goal and tasks of the research, expected results
The purpose of this field of research is to develop new approaches to the use of existing algorithms for processing the speech signal and their improvement with respect to the problems associated with recognition at the end of the speech signal.
The main objectives of the research:
- Analysis of existing methods for speech recognition that formed the basis of their patterns of speech analysis, in terms of selected properties.
- Exposure to multiple technologies, speech processing methodology.
- Identify important to recognize the properties of language and speech.
- Analysis of existing problems and ways to resolve them.
- Research the basic principles of recording of the speech signal and its segmentation.
- Isolation of the main areas for further research of the material on a given topic.
The object of research: the existing system of recording and speech recognition, as well as existing methods and algorithms to process the speech signal and its subsequent recognition.
Subject of research: increasing the efficiency of segmentation algorithms for the recognition of sounds are at the end of the speech signal.
As part of the master plan to get the actual scientific results in the following areas:
- Developing a new approach to recognition of sounds are at the end of the speech signal.
- Identify areas of application of this recognition.
- Modification of the known methods of speech signal processing and evaluation of their performance in practical tests.
For the experimental evaluation of the theoretical results and the formation of the foundation for further research, as the practical results will be the computer applications advance development with the following properties:
- Records of a speech signal.
- Saving, loading and removal of the recorded signal.
- Filtering the speech signal and its segmentation into individual phonemes.
- Output the result of recognition and reproduction.
3. Recognition of a couple of classes, «hissing-pause»
Consider an arbitrarily selected section of the speech signal is an analog of the numerical total variation «with a variable upper limit»:
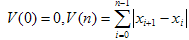 (3)
(3)Let N1 – the maximum number such that W (N1) ≤ 255. We believe
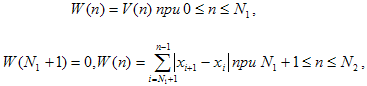 (4)
(4)where the N2 – the maximum number such that W (N2) ≤ 255 and so on. There is an array of numbers
 (5)
(5)On a hissing segment value (3) is growing rapidly, so that areas of increasing values of W (n) between 0 and 255 are relatively short, the number (5) are relatively small. In the segment of the value of a pause (3) grows slowly, and therefore the number of (5) are relatively large. To distinguish between pauses and hissing, we introduce a threshold p (for our equipment is 200). Take a selected segment of the voiceless consonants and construct a sequence of numbers (5). Those areas for which the number (5) is greater than p, refer to the amount of time pause (their union label the symbol P), the rest – a hissing (it will mark the symbol F). As a result, the computer will put the border marked hissing, and pauses.
4. Determination of the end of the word. Detection and isolation of the deaf explosive sound to the end of word
Let the spoken word «ЗАКОН» (law), ending with voiced consonant. Visualization of the signal is shown in Figure 7 with the segmentation according to the algorithm just described [7,8]. We construct a function W(n) (Fig. 4).

Fig. 4. Graph of the function W (n), corresponding to the signal in Figure 7

Fig. 5. Position the cursor that indicates the end of the intended signal
Figure 6 shows the result of the calculation of the array (5).
We developed the program supports the correspondence between the release of a string in the list in Figure 6 and the position of the cursor in Figure 5 (which shows the same graph as in Figure 4). Large numbers in the bottom of the list correspond to the site of silence at the end of the recorded signal. Moving from bottom to top on the list, passing strings, numbers, in which more than a threshold p1 (we take the threshold to 1000). Select the row for which the number of the previous line is less than p1. Leased line corresponds to the cursor position in Figure 5. It is anticipated the end of the speech signal.
We continue to move upwards through the list until the cursor to the left side of Figure 6 does not coincide with the mark P, or not be the first to the left of it. Sum up all the numbers in between the list and compare the calculated amount with the threshold Sum p2 (we take it equal to 3000). In this case it is less than p2. There fore, we believe the label end of the P signal and remove the label P. As a result of a marked visualization of the signal is as follows:
Now say the word «РОТ» (mouth). Here is his rendering of the final layout:
Here is the graph of W (n) with the cursor in the position of the alleged end of the signal:
Calculate the amount of Sum, in the same way as above. In this case it is greater than the threshold p2 (Figure 9, the cursor on the label is separated from P much further than in the previous example). There fore, the true end of the speech segment, we believe the position of the left edge of the cursor in Figure 9. Segment from P to label this new segment marks the end of the speech – a product of the deaf at the end of the explosive sound of the word. An example of the algorithm in the pronunciation of the word «ЗВОНОК» (Call) is shown in Figure 10.
Fig. 10. An example of the algorithm in the pronunciation of the word «ЗВОНОК» In this abstract I have presented some methods for digital processing of speech signals. Was considered the main classification of sounds. A review of the uses of speech recognition. There were also some results in this direction will more accurately identify unvoiced stops at the end of the signal, there by enabling them to select from a section of silence. All these methods are in good agreement with the current state of digital technology that allows us to simplify their implementation, testing and validation. These algorithms for segmentation of speech can help to solve the problem in improving the recognition of the end of the speech signal.
Further studies focused on the following aspects:
1. Studing of existing algorithms, the expansion and the addition of the results already obtained for the complex to accomplish the task.
2. Using of improved methods of segmentation.
3. To develop functional speech recognition system with the implementation of the algorithms, and perform the task to improve the written word segmentation accuracy.
This master's work is not completed yet. Final completion: December 2012. The full text of the work and materials on the topic can be obtained from the author or his head after this date.
1. Аграновский А.В. Автоматическая идентификация языка / А.В. Аграновский, О.Г. Можаев, Д.А. Леднов, М.Ю. Зулкарнеев // Искусственный интеллект. – 2002. – № 4. – С. 142-150.
2. Панов М.В. Современный русский язык. Фонетика / М.В. Панов – М.: Высшая школа, 1979. – 256 с.
3. Обжелян Н.К. Машины, которые говорят и слушают / Н.К. Обжелян, В.Н. Трунин-Донской. – К.: Штиинца, 1987. – 175 с.
4. Hosom J.P. Speech Recognition Using Neural Networks at the Center for Spoken Language Understanding / J.P. Hosom, R. Cole, M. Fanty // Center for Spoken Language Understanding, Oregon Graduate Institute of Science and Technology – July 1999.
5. Чекмарев А. Речевые технологии – проблемы и перспективы / А. Чекмарев // Компьютера. – 1997. – №49. – С. 26-43.
6. Speech recognition begins to makes itself heard [Електронний ресурс] / М. Broersma – Режим доступу до ресурсу: http://www.zdnet.co.uk/news/, October 2003.
7. В.Ю.Шелепов, А.В. Ниценко. К проблеме пофонемного распознавания // Искусственный интеллект. – 2005. – №4. – с.662-668.
8. Лекции о распознавании речи / Шелепов В.Ю. – Донецк: ІПЩІ «Наука і освіта», 2009. – 196 с.
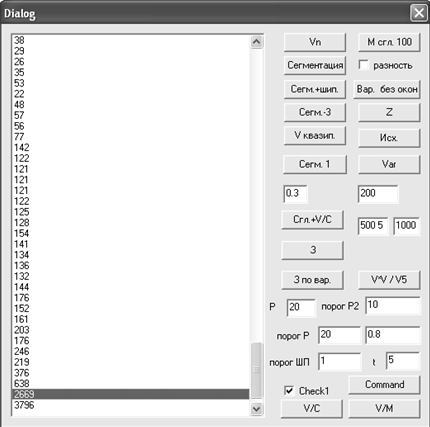
Fig. 6. The list on the left is an array (5)

Fig. 7. The final layout of the signal width marked the end of the signal

Fig. 8. Visualization of the signal for the word "mouth" with the final layout

Fig. 9. Graph of the function W (n) with the cursor in the position of the alleged end of the signal

(Animation: 6 frames, 10 cycles of repetition, 84.1 kilobytes)
Conclusion
References