Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми і перспективи розробки систем розпізнавання мови
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд механізму мовотворення
- 3.1 Формування звуку
- 3.2 Класифікація звуків
- 3.3 Класифікація фонем
- 4. Запис мовного сигналу
- 5. Деякі алгоритми сегментації
- 5.1 Алгоритм пошуку кордонів шиплячих і глухих приголосних звуків
- 5.2 Алгоритм поділу шиплячих і глухих приголосних
- 5.3 Алгоритм пошуку кордонів голосних і дзвінких приголосних звуків
- 5.4 «В-Н» - обробка числового масиву
- 5.5 Виділення глухих приголосних
- 5.6 Розпізнавання в парі класів «шипляча-пауза»
- 5.7 Сегментація чисто мовного сигналу
- 5.8 Сегментація за наявності шиплячих і пауз
- 6. Визначення кінця слова. Виявлення і виділення глухого вибухового звуку в кінці слова
- Висновки
- Перелік посилань
Вступ
Комп'ютери знаходять усе більш широке вживання у всіх областях людської діяльності. В даний час стримуючим чинником до збільшення кількості комп'ютерів в світі є неприйняття їх непідготовленим користувачем, його страх перед комп'ютерами. Певною мірою це неприйняття пов'язане з традиційними для обчислювальної техніки засобами введення інформації, в першу чергу, введення з клавіатури.
До недавнього часу процес мовного спілкування людини і комп'ютера був неодмінним атрибутом науково-фантастичних романів, і ніким не сприймався серйозно. Кілька років тому ситуація кардинально змінилася. Сьогодні використання мовних технологій в прикладних програмах як альтернативний засіб взаємодії в системі «людина-комп'ютер», набуває все більшого розмаху. Такий процес носить сповна обгрунтований і об'єктивний характер через низку обставин. По-перше, розвиток мовних засобів взаємодії з персональним комп'ютером (ПК) лежить в рамках світової тенденції «олюднення» ПК, тобто дозволяє створювати інтерфейси, максимально дружні користувачеві. По-друге, мініатюризація сучасних засобів управління і зв'язку вимагає принципово нових підходів до здійснення взаємодії користувача з такого типа пристроями. Для сучасних технологій не представляє великої праці створення, наприклад, мобільного телефону розміром з авторучку, проте механічний набір номера на такому телефоні буде пов'язаний з певними труднощами. Голосовий набір номера і авторизація в цьому випадку є очевидним і найбільш відповідним виходом. По-третє, для великого кола користувачів мовний спосіб спілкування з ПК є єдино можливим через обмеженість їх фізичних можливостей (люди з порушеннями опорно-рухового апарату, іншими фізичними недоліками, сліпі і так далі) або специфіки професії.
Велике значення придбали також завдання, пов'язані з швидким пошуком і здобуттям від великих інформаційно-обчислювальних систем («інформаційних банків») потрібних відомостей у вигляді звичайних мовних повідомлень, передаваних по телефонних мережах [1]. Все це зробило проблему автоматичного розпізнавання мови різносторонньою і актуальною.
В даний час у всьому світі ведуться роботи із створення природніших для людини засобів спілкування з комп'ютером, серед яких перше місце займає мовне введення інформації в комп'ютер. Проблема мовного введення інформації ускладнюється рядом чинників: відмінністю мов, специфікою вимови, шумами, акцентами, наголосами і тому подібне. Дана робота присвячена розробці прийомів і алгоритмів розпізнавання мови, зокрема глухих вибухових в кінці слова російської мови.
У будь-якій мові існує якийсь набір звуків, який бере участь при формуванні звукової подоби слів. Як правило, звук поза мовою не має значення, він набуває його лише як складова частина слова, допомагаючи відрізнити одне слово від іншого. Елементи цього набору звуків називаються фонемами.
1. Актуальність теми і перспективи розробки систем розпізнавання мови
На даний час мовне розпізнавання знаходить все нові і нові сфери застосування, починаючи від додатків, що здійснюють перетворення мовної інформації в текст і закінчуючи бортовими пристроями управління автомобілем. Все різноманіття існуючих систем розпізнавання мови [2] можна умовно розділити на наступні групи:
1. Програмні ядра для апаратних реалізацій систем розпізнавання мови;
2. Набори бібліотек, утиліт для розробки програм, що використовують мовне розпізнавання;
3. Незалежні призначені для користувача програми, що здійснюють мовне управління і перетворення мови в текст;
4. Спеціалізовані програми, що використовують розпізнавання мови;
5. Пристрої, що виконують розпізнавання на апаратному рівні;
6. Теоретичні дослідження і розробки.
Технології мовного розпізнавання знайшли своє вживання в різних областях. Проте в даній області безліч проблем все ще залишаються не вирішеними, багато ідей вимагають подальшого розвитку. Так, програми, що працюють з ізольованими словами, досягли високої точності в командних системах – в найбільш поширених сучасних застосуваннях точність розпізнавання складає в середньому 95-99% і залежить в основному від рівня шуму. В той же час завдання розпізнавання злитої мови достатньою мірою не вирішена, хоча в разі обмеженого словника системи такого типа існують (Voxreports на ядрі Viavoice, Verbmobil) і показують високі результати по точності. В даний час безліч робіт присвячена проблемі розпізнавання злитої мови (ІПУ РАН, «Істра-софтвер», IBM), оскільки саме такий тип мовної взаємодії вважається найбільш перспективним [3].
Найважливішим етапом обробки мови в процесі розпізнавання, є виділення інформативних ознак, що однозначно характеризують мовний сигнал. Існує деяке число математичних методів, що аналізують мовний спектр. Тут найбільш широко використовуваним є перетворення Фур'є, відоме з теорії цифрової обробки сигналів. Даний математичний апарат добре себе зарекомендував в даній області, є безліч методик обробки сигналів, що використовують в своїй основі перетворення Фур'є.
Не дивлячись на це, постійно ведуться роботи по пошуку інших доріг параметризації мови. Одним з таких нових напрямів, є вейвлет аналіз, який став застосовуватися для дослідження мовних сигналів порівняно недавно. Теорія даного методу зараз розвивається вченими всього світу, і багато дослідників покладають великі надії на використання інструменту вейвлет аналізу для розпізнавання мови. Якщо розглянути мовні розпізнавачі з позиції класифікації за механізмом функціонування, то переважна їх частина відноситься до систем з імовірнісно-мережевими методами ухвалення рішення про відповідність вхідного сигналу еталонному – це метод прихованого Марківського моделювання, метод динамічного програмування і нейромережевий метод. Наприклад, нейронні мережі можуть бути використані для класифікації характеристик мовного сигналу і ухвалення рішення про приналежність до тієї або іншої групи еталонів.
Нейромережа володіє здатністю до статистичного усереднювання, тобто вирішується проблема з варіативністю мови. Багато нейромережевих алгоритмів здійснюють паралельну обробку інформації, тобто одночасно працюють всі нейрони. Тим самим вирішується проблема із швидкістю розпізнавання – звичайний час роботи нейромережі складає декілька ітерацій. Зараз багато розробників використовують апарат нейронних мереж для побудови розпізнавачів [4]. Проте, якщо порівняти показники сучасних систем розпізнавання з показниками систем часів початку зародження цієї галузі науки, то можна сказати, що за минулі десятки років дослідники недалеко просунулися. Це заставляє деяких фахівців сумніватися відносно можливості реалізації мовного інтерфейсу в найближчому майбутньому [5]. Інші вважають, що завдання вже практично вирішене. Більшість експертів погоджуються на думці, що для розвитку розпізнавання мови буде потрібним деякий час. В рамках свого проекту «Super Human Speech Recognition» IBM сподівається розробити комерційні системи, що перетворюють мову в друкарський текст точніше, ніж людина [6].
2. Мета і задачі дослідження, заплановані результати
Метою дослідження даної області є розробка нових підходів щодо застосування існуючих алгоритмів з обробки мовного сигналу і їх вдосконалення по відношенню до проблем пов'язаних з розпізнаванням в кінці мовного сигналу.
Основні задачі дослідження:
- Аналіз існуючих методів розпізнавання мови, покладених в їх основу схем аналізу мови, з точки зору використання виділених властивостей.
- Ознайомлення з безліччю технологій, методологією обробки мови.
- Визначити важливі для розпізнавання властивості мови і мовлення.
- Аналіз існуючих проблем та шляхи їх вирішення.
- Вивчення основних принципів запису мовного сигналу і його сегментації.
- Визначення загального напрямку подальшого вивчення матеріалу з заданої теми.
Об'єкт дослідження: існуючі системи запису і розпізнавання мови, а також існуючих методів і алгоритмів спрямованих на обробку мовного сигналу і подальшого його розпізнавання.
Предмет дослідження: підвищення ефективності алгоритмів сегментації з розпізнавання звуків, що знаходяться в кінці мовного сигналу.
У рамках магістерської роботи планується отримання актуальнихнаукових результатів за наступними напрямками:
- Разработка нового підходу до проблем розпізнавання звуків, що знаходяться в кінці мовного сигналу.
- Визначення областей застосування даного розпізнавання.
- Модіфікація відомих методів обробки мовного сигналу і оцінювання ефективності їх застосування в практичних випробуваннях.
Для експериментальної оцінки отриманих теоретичних результатів і формування фундаменту наступних досліджень, в якості практичних результатів планується розробка комп'ютерної програми, що попередньо буде мати такі властивості:
- Запис мовного сигналу.
- Збереження, завантаження та видалення записаного сигналу.
- Фільтрація мовного сигналу і його сегментація на окремі фонеми.
- Виведення результату розпізнавання та його відтворення.
3. Огляд механізму мовотворення
Мова у фізичному розумінні – це акустичний сигнал, що генерується органами артикуляцій людини, передається через фізичне середовище, сприймане вухом людини.
3.1 Формування звуку
При природній або штучній генерації мови в акустичному сигналі змінюються фізичні параметри [7]. Ці зміни впливають на мембрану вуха, створюють траєкторії звукових образів, що розуміються людиною як відповідні звуки даної мови. Механізм утворення звуку приведений на рисунку 1.
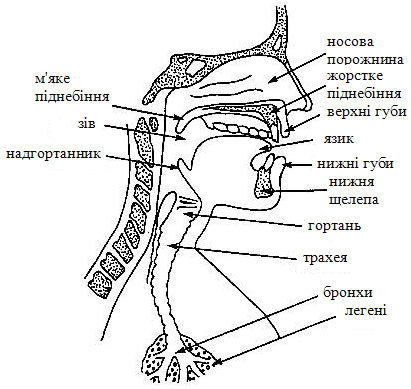
Рис. 1. Звуковий тракт людини
При розмові грудна клітка розширюється і стискується, прокачавши потік повітря з легенів по трахеї через голосову щілину (рис. 3.1). Якщо голосові в’язки напружені, як при утворенні дзвінких звуків типу голосних, то вони вібрують подібно до релаксаційного генератора і модулюють потік повітря, перетворюючи його на короткі імпульси.
Якщо голосові в’язки розслаблені, повітря вільно проходить через голосову щілину, не піддававшись модуляції. Повітряний потік проходить через глоткову порожнину мимо основи язика і в залежності від положення м'якого піднебіння – через ротову і носову порожнини.
Потік повітря виходить назовні через рот або ніс (або обома дорогами) і сприймається як мова [8]. В разі глухих звуків, таких, як [з] або [п], голосові в’язки розслаблені. При цьому можливі два режими: або утворюється турбулентний потік, коли повітря проходить через звуження в голосовому тракті, або виникає короткий вибуховий процес, викликаний підвищеним тиском повітря за точкою перекриття голосового тракту.
При зміні положення артикуляторів (губ, язика, щелепи, м'якого піднебіння) під час виголошування безперервної промови форма окремих порожнин голосового тракту істотно змінюється.
У дорослої людини акустична трубка має довжину близько 17 см і частота її першого (чверть-хвильового) резонансу дорівнює 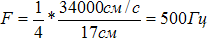 . Площа поперечного перетину акустичної трубки неоднакова і залежить від положення артикуляторів, змінюючись від 0 до 20 см2.
. Площа поперечного перетину акустичної трубки неоднакова і залежить від положення артикуляторів, змінюючись від 0 до 20 см2.
Голосовий тракт має деякі стійкі види резонансних коливань, звані формантами, які істотно залежать від розташування артикуляторів.
3.2 Класифікація звуків
Звуки, що беруть участь у формуванні мови, мають дві основні класифікації: по ознаках артикуляцій і по акустичних ознаках.
Класифікація звуків за ознаками артикуляцій є украй важливої при використанні методів генерації і розпізнавання мови за допомогою моделювання носоглотки, але для вирішення завдань ділення на фонеми цікавіший розгляд акустичних відмінностей звуків [9]. По акустичних ознаках звуки підрозділяються на: тональні, сонарні і галасливі.
Тональні звуки – утворюються голосом при повній відсутності шумів, що забезпечує хорошу чутність звуку. До них відносяться голосні: а, э, и, о, у, ы.
Сонарні (звучні) – чия якість визначається характером звучання голосу, який грає головну роль в їх утворенні, а шум бере участь в мінімальній мірі. До них відносяться приголосні: [м], [м’], [н], [н’], [л], [л’], [р], [р’], [j]. Символ [’] означає м'якість звуку.
Галасливі – їх якість визначається характером шуму – акустичного ефекту від тертя повітря при тих, що зближують, або вибуху при зімкнутих органах мови:
- дзвінкі галасливі тривалі: [в], [в’], [з], [з’], [ж];
- дзвінкі галасливі миттєві: [б], [б’], [д], [д’], [г], [г’];
- глухі галасливі тривалі: [ф], [ф’], [з], [з’], [ш], [х], [х’];
- глухі галасливі миттєві: [п], [п’], [т], [т’], [к], [к’].
По вироблюваним звуками акустичному враженню виділяють наступні групи звуків:
- свистячі: [з], [з’], [з], [з’], [ц];
- шиплячі: [ш], [ж], [ч], [щ];
- тверді: [п], [в], [ш], [ж], [ц] і ін.;
- м'які: [п’], [в’], [ч], [щ] і ін.
Для подальшого аналізу проведемо інформаційні образи звуків різних груп.
Різниця образів і звуків різних видів велика, що значно полегшила б завдання розділення звуків, коли б не присутність декількох чинників, що утрудняють роботу.
По-перше, перехід між різними звуками, як правило, здійснюється украй плавно навіть між звуками різних груп (виняток становлять деякі вибухові приголосні). Якщо ж говорити про звуки однієї групи, то стає проблематичним розділяти перехідні процеси від вимовляння того або іншого звуку, наприклад, в послідовності, що сприймається людиною як «иау», звук [а] фактично повністю втрачає свій звичайний образ в переході від [и] до [у]. Під впливом [и] і [у] дещо зменшилася частота в [а], та і сама форма звуку дещо трансформувалася.
По-друге, скрутно назвати які-небудь постійні критерії для успішного ділення на звуки у зв'язку із складністю процесу їх утворення.
Повернемося до відображень звуків і проаналізуємо загальний вигляд голосних і сонарних звуків. Легко виявити якусь загальну закономірність, яка обумовлена походженням звуків – звуки цих видів віддалено нагадують реакцію деякої системи на послідовність рівновіддалених імпульсів. Дійсно, імпульсами голосних і сонарних звуків є коливання дійсних, і звукових в’язок. Остаточного вигляду звукові хвилі набувають після проходження через носоглотку, яка за своєю суттю є системою фільтрів. Необхідно відзначити, що зміни в напрузі дійсних голосових в’язок і артикуляції відбуваються значно повільніше, ніж коливання голосових в’язок.
3.3 Класифікація фонем
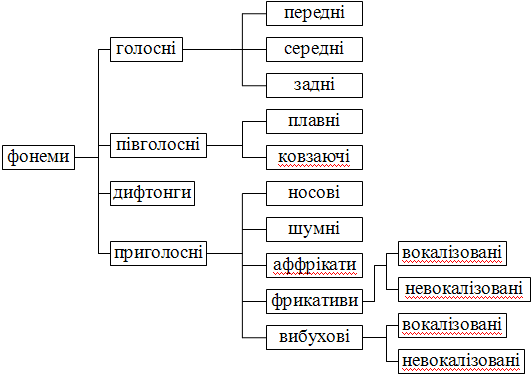
Рис. 2. Класифікація фонем
На рисунку 2 приведена загальна класифікація мовних фонем.
Голосні утворюються при квазіперіодичному збудженні голосового тракту незмінної форми імпульсами повітря, що виникають унаслідок коливання голосових в’язок. Голосні діляться на три підгрупи по положенню язика у момент вимовляння визначеної голосної: передні, середні і задні.
Півголосними називаються звуки, акустичні характеристики яких зміняються залежно від вимовного тексту.
Приголосні носові звуки утворюються при голосовому збудженні, при цьому рот закритий і служить резонансною плоскістю, а сам звук виходить разом з повітрям через ніс.
Приголосні фрикативні невокалізовані звуки утворюються шляхом збудження голосового тракту турбулентним повітряним потоком.
Приголосні фрикативні вокалізовані звуки утворюються як і невокалізовані звуки шляхом збудження голосового тракту, а також у цей момент коливаються голосові в’язки.
Вибухові вокалізовані приголосні звуки утворюються при зімкненні голосового тракту в якійсь області порожнини рота. За змичкою повітря стискується, а потім раптово вивільняється.
Вибухові невокалізовані приголосні звуки мають дуже важливі відмінності від вокалізованих. В період повного зімкнення голосового тракту голосові в’язки не коливаються. Після цього періоду, коли повітря за змичкою вивільняється, протягом короткого проміжку часу втрати на тертя зростають із-за раптової турбуленції потоку повітря. Далі шумовий повітряний потік з голосової щілини збуджує голосовий тракт і після цього виникає голосове збудження.
Аффрікати є сумішшю вибухового звуку і фрикативного приголосного.
Шумові приголосні утворюються шляхом збудження голосового тракту турбулентним повітряним потоком, тобто без участі голосових в’язок.
4 Запис мовного сигналу
За основу береться 8-бітове оцифровування звукового сигналу з частотою дискретизації 22050 Гц, так, що його значення мають 28 = 256 градацій: від 0 до 255. Передбачається використання системи в лабораторних умовах, за відсутності істотного зовнішнього шуму.
Записаний сигнал, що містить мову, розбивається на відрізки по 256 відліків. Для кожного з них обчислюється відношення
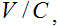 (1)
(1)
де
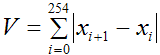 (2)
(2)
- чисельний аналог повної варіації C- число точок постійності, тобто моментів часу, для яких в наступний момент величина сигналу залишається незмінною. Створюється список значень величини (1), відповідних послідовності згаданих відрізків. При виділенні елементу списку курсор у вікні візуалізації сигналу повинен ставати в початок відповідного відрізку. Далі «очима» визначаються елементи списку, відповідні мовчанню і визначається максимальний з них. Це число збільшується на 0,1 і заноситься у файл під ім'ям Startporog, а результат, збільшений в 2 рази – під ім'ям Endporog. Все це можна також зробити автоматично, записавши перед налаштуванням, наприклад, 30 тисяч відліків тиші.
Після початку запису, виголошується слово і натискується кнопка зупинки запису. Після цього комп'ютер починає обчислювати для послідовних відрізків по 256 відліків величину (1). Визначаються моменти, коли ця величина перевищує Startporog і стає менше, ніж Endporog і у відповідних місцях сигналу проставляються мітки або (і) частина сигналу між ними виділяється. Таким чином ми отримуємо записане слово.
5 Деякі алгоритми сегментації
5.1 Алгоритм пошуку кордонів шиплячих і глухих приголосних звуків
На кожному етапі роботи системи відбувається аналіз транскрипції мовного сигналу для з'ясування його фонетичного складу. За наявності в транскрипції шиплячих (до яких в даній роботі відносяться [ш], [с], [ф], [х], [ц], [ч], [щ]), глухих вибухових приголосних [п], [к], [т], [t], які асоціюються з паузою в сигналі (тут t означає м'яке [т]), або фонем [ж], [з] ділянка, яка повинна містити одну з вказаних і сусідню з нею фонему, обробляється фільтром низьких частот з частотою зрізу 500 Гц. Це зменшує енергію ділянки, відповідної кожній з перерахованих фонем. Далі відбувається розділення сигналу на частини з високою і низькою амплітудою (енергією) [10,11].
Для цього обчислюється середня амплітуда всієї відфільтрованої ділянки: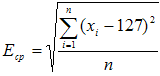 де, xi – значення i - го відліку ділянки;
n – кількість відліків (довжина ділянки).
Далі відфільтрована ділянка розбивається на відрізки по 256 відліків і обчислюється амплітуда на кожному відрізку. В результаті отримуємо масив значень амплітуди Ei. Щоб визначити кордони між високоамплітудною і низькоамплітудною частинами сигналу, послідовно порівнюємо кожне значення Ei з пороговим значенням T. Для шиплячих і пауз вважаємо T = 0.3 від Eср, для [ж] і [з] вважаємо T=Eср. Якщо Ei-1>T і Ei<T, то, можливо, значення 256 помножене на i – це кордон між високоамплітудною і низькоамплітудною частинами ділянки.
Щоб уникнути появи зайвих кордонів, додатково перевіряється відстань до попереднього кордону. Якщо воно не перевищує 512 відліків, то значення 256 помножене на i пропускаємо, інакше вважаємо значення 256 помножене на i черговим кордоном і запам'ятовуємо його разом з попереднім кордоном в списку сегментів Segment_array.
Ділянку з цими кордонами вважаємо високоамплітудною і відповідною черговому голосовому звуку в транскрипції (або декільком голосовим звукам).
де, xi – значення i - го відліку ділянки;
n – кількість відліків (довжина ділянки).
Далі відфільтрована ділянка розбивається на відрізки по 256 відліків і обчислюється амплітуда на кожному відрізку. В результаті отримуємо масив значень амплітуди Ei. Щоб визначити кордони між високоамплітудною і низькоамплітудною частинами сигналу, послідовно порівнюємо кожне значення Ei з пороговим значенням T. Для шиплячих і пауз вважаємо T = 0.3 від Eср, для [ж] і [з] вважаємо T=Eср. Якщо Ei-1>T і Ei<T, то, можливо, значення 256 помножене на i – це кордон між високоамплітудною і низькоамплітудною частинами ділянки.
Щоб уникнути появи зайвих кордонів, додатково перевіряється відстань до попереднього кордону. Якщо воно не перевищує 512 відліків, то значення 256 помножене на i пропускаємо, інакше вважаємо значення 256 помножене на i черговим кордоном і запам'ятовуємо його разом з попереднім кордоном в списку сегментів Segment_array.
Ділянку з цими кордонами вважаємо високоамплітудною і відповідною черговому голосовому звуку в транскрипції (або декільком голосовим звукам).
Якщо Ei-1<T і Ei>T, то, можливо, 256 помножене на i – кордон між високоамплітудною і низькоамплітудною частинами ділянки (при цьому виконується така ж перевірка, що і у попередньому випадку). Ділянка з відповідними кордонами вважається низько амплітудним, що відповідає черговому шиплячому звуку, паузі або [ж], [з] в транскрипції (або поєднанню «шиплячий – пауза»).
При роботі алгоритму наявність транскрипції слова дає можливість контролювати правильність чергування високоамплітудних і низькоамплітудних ділянок (тобто якщо в транскрипції за шиплячою слідує голосовий звук, то алгоритм шукатиме лише перехід від низької амплітуди до високої і навпаки). Це дозволяє уникнути появи зайвих міток і підвищує точність сегментації.
5.2 Алгоритм розділення шиплячих і глухих приголосних
Якщо в результаті роботи попереднього алгоритму в списку сегментів присутні ділянки з низькою енергією, відповідні поєднанню шиплячих і глухих приголосних звуків [п], [к], [т], [t], то для того, щоб визначити кордон між ними, використовується наступний алгоритм. Відповідна ділянка вихідного сигналу обробляється фільтром високих частот з частотою зрізу 1500 Гц і на ньому будується масив значень амплітуди Ei (від лівого кордону до правого). Щоб визначити кордон між шиплячою і паузою, послідовно порівнюємо кожне значення Ei з пороговою величиною, рівною Eср. Якщо Ei-1>Eср і Ei<Eср, то, можливо, значення 256 помножене на i – це шуканий кордон. Щоб уникнути появи зайвих кордонів, додатково перевіряється відстань від лівого кордону всієї ділянки до знайденого кордону. Якщо воно не перевищує 512 відліків, то значення 256 помножене на i пропускаємо, інакше рахуємо значення 256 помножене на i черговим кордоном і запам'ятовуємо це значення разом з лівим кордоном ділянки в списку сегментів Segment_array. Ділянка з цими кордонами вважається високоамплітудною і відповідною шиплячій, а наступна за ним низькоамплітудна ділянка – паузі. У список сегментів додаються дві нові ділянки.
5.3 Алгоритм пошуку кордонів голосних і дзвінких приголосних звуків
Якщо після роботи попередніх алгоритмів в списку сегментів присутні ділянки з високою амплітудою, відповідні поєднанням підряд голосних, що йдуть, і дзвінких приголосних звуків, для їх розділення застосовується фільтрація відповідних ділянок сигналу фільтром високих частот. Така фільтрація сильно знижує енергію ділянок, відповідних дзвінким приголосним звукам, тоді як енергія голосних зменшується трохи.
Якщо ділянка містить звук [и], то вона обробляється фільтром високих частот (ФВЧ) з частотою зрізу 3500 Гц (за винятком пар «ил» і «lі»). Для поєднань «вы», «ил», «lі», «лу», «ду», «ву», «бу», «гу» використовується ФВЧ з частотою зрізу 250 Гц, для поєднання «му» – частота зрізу 750 Гц. В разі останніх поєднань ділянка обробляється фільтром високих частот з частотою зрізу 500 Гц. Далі будується масив значень амплітуди Ei на даній ділянці сигналу (від лівого кордону до правого). Щоб визначити кордони між високоамплітудними і низькоамплітудними ділянками сигналу, послідовно порівнюємо кожне значення Ei з пороговою величиною T. Якщо приголосна є одна з фонем [б], [д], [г], то T дорівнює половині Eср, інакше T=Eср . Якщо Ei-1>Т і Ei<Т, то, можливо, значення 256 помножене на i – це кордон між високоамплітудними і низькоамплітудними ділянками сигналу. Щоб уникнути появи зайвих кордонів, додатково перевіряється відстань до попереднього кордону. Якщо вона не перевищує 600 відліків, то пропускаємо значення 256 помножене на i, інакше вважаємо значення 256 помножене на i черговим кордоном і запам'ятовуємо його разом з попереднім кордоном в списку сегментів Segment_array. Ділянка з цими кордонами вважається високоамплітудною і відповідною черговому явному звуку в транскрипції (або декільком явним звукам). До голосних відносяться: [а], [о], [у], [е], [ы], [и], [э], [ю], [я].
Якщо Ei-1<Т і Ei>Т, то, можливо, 256 помножене на i – кордон між низькоамплітудною і високоамплітудною ділянками сигналу (при цьому виконується така ж перевірка, як і у попередньому випадку). В разі позитивного результату перша ділянка вважається низькоамплітудною і відповідає черговому дзвінкому приголосному звуку в транскрипції ([б], [в], [г], [д], [л], [l], [м], [н]) (тут l позначає м'яке «л»). Робота алгоритму завершиться, коли будуть проглянуті всі значення Ei.
5.4 «В-Н» - обробка числового масиву
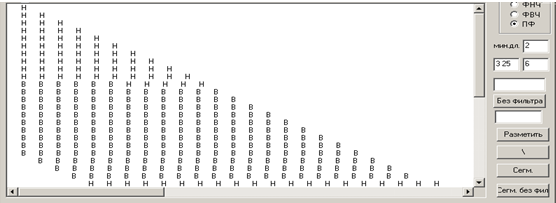
Хай є одновимірний числовий масив і заданий деякий поріг р. Побудуємо символьну послідовність S, поставивши у відповідність членам масиву, які більше р, символ «В» (вище за поріг), останнім – символ «Н» (нижче за поріг). Для того, щоб усунути випадкові одиничні включення, для кожного проміжного i-го елементу отриманої символьної послідовності S виконуються дві додаткові обробки. Обробка «трійками», якщо s[i-1]=s[i+1] і s[i]≠s[i-1], то вважається s[i]=s[i-1]. Обробка четвірками, якщо s[i]=s[i+3] і s[i+1]≠s[i], s[i+2]≠s[i], то вважається s[i+1]=s[i] і s[i+2]=s[i].
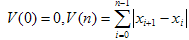 (3)
(3)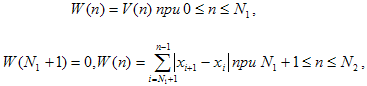 (4)
(4)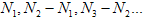 (5)
(5)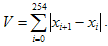 (6)
(6)