ВЕЙВЛЕТ МЕТОД СЕГМЕНТАЦИИ РЕЧИ
Перевел с английского: Костенко А.В.
Источник: Официальный сайт факультета компьютерных наук Университета Йорка Хеслингтона
http://www-users.cs.york.ac.uk/~suresh/papers/WMOSS.pdf
В этой статье предлагается новый метод сегментации речи. Он основан на мощности колебаний вейвлет спектра речевого сигнала. В большинстве подходов по распознаванию речи, речевые сигналы сегментируются с использованием статически-временной сегментации. Статической сегментации необходимо использовать окна, чтобы уменьшить искажение границ. Более естественным подходом сегментации является сегментация речевого сигнала на основе частотно-временного анализа. Границы задаются в местах, где некоторое количество энергии полосы частот быстро меняется. Большинство методов не статической сегментации нуждаются в обучении для конкретных данных и реализуются как часть моделирования. В данной работе мы применяем дискретное вейвлет преобразование (ДВП) для анализа речевых сигналов, результирующий энергетический спектр и его производные. Эта информация позволяет найти границы фонем. Это первый этап в процессе распознавания речи. Кроме того, мы представляем оценку эффективности нашего метода путем сравнения его с ручным сегментированием. Сегментационный метод оказывается наиболее эффективным для поиска границ фонем. Результаты оказались более полезными для распознавания речи, чем алгоритмы статической сегментации.
Информационные технологии оказывают все большее и большее влияние на все сферы деятельности в нашей повседневной жизни, проблема коммуникации между человеком и устройствами обработки информации становится все более значимой. До сих пор такая коммуникация почти полностью достигалась посредством клавиатуры и экрана, но речь, безусловно, наиболее широко используемое, природное и быстрое средство связи между людьми. К сожалению, машинные возможности для интерпретации речи по-прежнему бедны в сравнении с тем, чего может достичь человек.
В подавляющем большинстве подходов в распознавании речи, речевые сигналы должны быть разделены на сегменты перед тем как можно будет приступить к распознаванию. Свойства сигнала, содержащиеся в каждом сегменте, считаются постоянными, или другими словами, характерны для одной части речи.
Наиболее часто используется текущий метод, который заключается в использовании статически заданном делении, например, на 25 блоков мс [12]. Этот метод извлекает выгоду из простоты выполнения и легкости сравнения блоков той же длины. Однако, различная длина фонем - естественное явление, которое не может быть проигнорировано. Кроме того, граничные эффекты обеспечивают дополнительное искажение (которое, как правило, уменьшается посредством применения окна Хэмминга). Создавая больше граничных меток при сегментации фонем. Поэтому при статической сегментации есть риск потери информации о фонемах за счет слияния различных звуков в одном блоке, теряется информация о длине фонемы и происходит потеря отдельных фонем.
Более удовлетворительным подходом, является попытка найти границы фонем от изменяющихся во времени свойств речевого сигнала. Ряд подходов были заранее предложены для этой задачи [6, 11, 13] но они используют особенности, полученные от акустического знания фонем. Такие методы должны быть оптимизированы к специфическим данным фонемы и не могут быть реализованы отдельно от распознавания фонемы. Нейронные сети [9], также были проверены, но они требуют времени обучения. Сегментацию могут применить сегментные модели (СM) вместо скрытых Марковских моделей (СММ) [7]. Это рамки групп решения в последовательностях рамок, с помощью моделирования. Такое решение подразумевает сегментацию и распознавание проводящихся одновременно, и существует множество возможных длин наблюдения. В общем, СМ распространение продолжительности дает вероятность сегментной длины, так, фактически, это описывает вероятность специфической сегментации высказывания. СM для данного ярлыка также характеризует семейство выходных плотностей. Это дает информацию о наблюдении последовательности различных длин. Эти особенности СM решения позволяют определять местонахождение границ только на нескольких фиксированных положениях в зависимости от оснащения (на умноженной длине одного промежутка).
Спектральный анализ является очень эффективным методом для извлечения информации из речевых сигналов. Дискретное вейвлет преобразование (ДВП) успешно используется во многих приложениях по обработке речи [3, 4, 5, 8, 10] для спектрального анализа сигналов. В случае распознавания речи, он в основном используется для повышения точности параметризации. Экспериментальные результаты показывают превосходство методов ДВП над более классическими как мел-частотные кепстральные коэффициенты (МЧКК) [3, 4, 5]. Анализ энергии в различных подзонах частоты дает прекрасную возможность различить начало и конец фонем. Для многих границ, нет никакого заметного падения общей энергии, а на некоторых частотах, энергия, в целом постоянна на протяжении всей фонемы. Тем не менее, многие фонемы резко изменяются в частотном диапазоне, что позволяет определять их начальные и конечные точки. Наш метод отличается от большинства других тем, что он анализирует сам сигнал в частотной области. Это означает, что мы не используем информацию, основанную на моделировании или распознанные фонемы. Сегментационный шаг может проводится независимо и заканчиваться перед шагом распознавания. Здесь не нужно никакое обучение или адаптация к пользователю.
Схема работы выглядит следующим образом: в разделе 2, описано ДВП разложение, как основной инструмент нашего метода. В разделе 3 мы представляем метод сегментирования и фильтрацию, чтобы получить скорость изменения информации. Сегментация - процесс сравнения сглаженной области и его скорости от изменения функций описаны как некоторые другие общие правила сегментации и методов. В разделе 4 мы опишем реализованный алгоритм. В разделе 5 информацию о наших экспериментах в том числе сравнение применения различных небольших волн и статической сегментации (кадрирование). Описан новый общий метод оценки для сегментации фонем, и представлены результаты в базе данных польских слов.
Человеческое ухо использует частоту обработки на первом этапе звукового анализа [2]. Это побуждает нас использовать ДВП в искусственном методе анализа речи, как восприятия мотивированного решения.
Исходный сигнал и его вейвлет-спектр обрабатывается с 16-ти битной точностью. Вейвлет принадлежит к группе частот преобразования. В результате, легко найти параметры речи, которые являются важными для человеческой системы прослушивания [10]. Для того чтобы получить ДВП, коэффициенты ряда
 (1)
(1)
необходимо вычислить, где  , это i-я функция вейвлета в (m +1) уровне разрешения.
, это i-я функция вейвлета в (m +1) уровне разрешения.
Коэффициенты нижнего уровня рассчитываются путем применения известных формул [2, 8]
 (2)
(2)
 (3)
(3)
где h и g являются постоянными коэффициентами, которые зависят от предполагаемой пары: масштаб функции  и вейвлета
и вейвлета  . Формулы (2) и (3) используются для разложения сигналов цифровой фильтрации вейвлет-коэффициентов. Если заданы вейвлет-коэффициентов
. Формулы (2) и (3) используются для разложения сигналов цифровой фильтрации вейвлет-коэффициентов. Если заданы вейвлет-коэффициентов 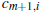 , в (m + 1)-м разрешенном уровне, мы можем применить (2) и (3) для вычисления коэффициентов m-го уровня разрешения. Элементы для ДВП определенного уровня могут быть собраны в вектор, например,
, в (m + 1)-м разрешенном уровне, мы можем применить (2) и (3) для вычисления коэффициентов m-го уровня разрешения. Элементы для ДВП определенного уровня могут быть собраны в вектор, например,  . Коэффициенты других разрешенных уровней вычисляются рекуррентно по формулам (2) и (3). Кратномасштабный анализ естественным образом приводит к иерархической и быстрой схеме для расчета вейвлет коэффициентов для данного речевого сигнала s . В этом случае значения
. Коэффициенты других разрешенных уровней вычисляются рекуррентно по формулам (2) и (3). Кратномасштабный анализ естественным образом приводит к иерархической и быстрой схеме для расчета вейвлет коэффициентов для данного речевого сигнала s . В этом случае значения
 (4)
(4)
ДВП для M+1 уровней получены. Вейвлет-спектр производится с помощью фильтра банка (каскадные таблицы фильтрации и понижение операций). Вейвлет-преобразование можно рассматривать как дерево. Корень дерева состоит из коэффициентов ряда всплесков (1) исходного речевого сигнала. На следующем уровне дерева результатом является один шаг ДВП. Последующие уровни в дереве строятся рекурсивно применяя шаг вейвлет разложения сигнала в низких (приближенных) и высокой (подробных) частей. Предпринятые эксперименты показали, что речевой сигнал должны быть разложен на шесть уровней, которые охватывают диапазон частот человеческого голоса (см. Таблицу 1). Энергия речи сигнала выше 5,5 кГц и ниже 86 Гц, что очень низко.

Рис.1. Дискретный вейвлет Мейера
Полезность шести вейвлет функций была проверена. Полученные результаты для разных всплесков (см. таблицу 2) показывает, небольшие различия в их эффективности. Кажется, что дискретный Мейер вейвлет (рис. 1) [1] или symlets должны быть выбраны в качестве основы для ДВП из за их симметрии во временной области и компактной поддержке в частотной области.
Ясно, что мы ожидаем абсолютную величину скорости изменения энергии, которая велика в начале и в конце фонем. Тем не менее, это не однозначно определяет начальные и конечные точки, по двум причинам. Во-первых, энергия может повыситься в течение значительного периода времени в начале фонемы, что приводит к неоднозначности время запуска. Во-вторых, может также быть быстрым изменения энергии в середине сегмента. Лучший метод определения границ фонем опирается на энергетические переходы между ДВП участками.
Правильно выбранный метод сегментации должен увеличивать эффективность распознавания речи. Наш подход основан на шести уровнях ДВП анализа (например, М = 6) речевого сигнала (Рис. 2).
Количество  образцов вейвлет спектров n-уровня (где n = 1, ..., М) зависит от длины N речевого сигнала во временной области, предполагая, что N является степенью 2. В таблице 1 представлены их количество на каждом уровне по отношению к низкому уровню разрешения. Для каждого n-уровня разложения энергия сигнала
образцов вейвлет спектров n-уровня (где n = 1, ..., М) зависит от длины N речевого сигнала во временной области, предполагая, что N является степенью 2. В таблице 1 представлены их количество на каждом уровне по отношению к низкому уровню разрешения. Для каждого n-уровня разложения энергия сигнала
 где i=0,...,
где i=0,..., N-1, (5)
N-1, (5)
рассчитывается по-другому, чтобы получить равное количество образцов.
Энергия ДВП участка показывает быстрые изменения (см. Рис.2). Несмотря на сглаживание (5) изменение энергетических форм волны быстрое. Первые порядковые отличия в энергии неизбежно шумны, и так мы вычисляем порог  , для энергетических колебаний в каждой подгруппе, выбирая самые высокие значения
, для энергетических колебаний в каждой подгруппе, выбирая самые высокие значения  в окне данного размера
в окне данного размера  , чтобы получить энергетический порог (Fig.3 и Таблица 1). Дополнительно мы используем сглаженный оператор, разность которого вычисление энергетического участка сворачивается с маской [1,2, -2, -1] для получения сглаженной информации об изменении
, чтобы получить энергетический порог (Fig.3 и Таблица 1). Дополнительно мы используем сглаженный оператор, разность которого вычисление энергетического участка сворачивается с маской [1,2, -2, -1] для получения сглаженной информации об изменении  .
.
Таблица 1: Характеристика дискретного вейвлет преобразования уровней
|
|||

Рис.2. Энергия ДВП участков имени "Andrzej". Пунктирные линии - границы ручной сегментации
Таблица 2: Сравнение постоянной сегментации и предложенного метода с использованием различных вейвлетов
 |
 |
||
Const92.8 ms Meyer db2 db6 db20 sym6 haar |
0.0796 0.1602 0.2325 0.1927 0.1716 0.1816 0.2663 |
5.2479 3.2325 2.8531 3.0752 3.2724 3.0581 2.8783 |
5.6459 4.0334 4.0157 4.0385 4.1305 3.9660 4.2099 |
Начало фонем должны быть обозначены изначально небольшим, но быстро растущим уровнем энергии в одном или нескольких ДВП уровнях. Другими словами, мы должны ожидать, что энергия малой и производная должны быть большим. Мы можем обнаружить границу фонемы поиском i-й точки, для которых неравенство
 (6)
(6)
справедливо и для границы фонемы, где постоянная р – значение порога, который дает отчет о масштабе времени и чувствительности контрольно-пропускных пунктов. По скорости изменения функции  умножается на коэффициент масштабирования
умножается на коэффициент масштабирования  равный 1. На практике мы ищем индексы, для которых сглаженная энергия и скорости изменения функции подхода близки друг к другу и не обязательно пересекающихся. Мы обнаружили, что порог р – расстояние между энергией и сглаженной скоростью изменения функции изменяется как 0,02 для достижения наилучших результатов. Другим условием повышения точности превышения минимального порога
равный 1. На практике мы ищем индексы, для которых сглаженная энергия и скорости изменения функции подхода близки друг к другу и не обязательно пересекающихся. Мы обнаружили, что порог р – расстояние между энергией и сглаженной скоростью изменения функции изменяется как 0,02 для достижения наилучших результатов. Другим условием повышения точности превышения минимального порога  из участка ДВП энергии, которая была выбрана экспериментально 0.003. Она защищает нас от анализа шума, а не речевого сигнала.
из участка ДВП энергии, которая была выбрана экспериментально 0.003. Она защищает нас от анализа шума, а не речевого сигнала.
Представленный выше метод без дополнительных разъяснений не будет точно определять границы фонем по ряду причин. Во-первых, точное положение границы может незначительно отличаться между уровнями. Для некоторых фонем, только одна полоса частот может показать значительные изменения в силе, для других несколько. Во втором случае, каждый участок анализа обнаруживает отдельные границы. Они могут незначительно отличаться. Во-вторых, несмотря на сглаживание производной, вблизи порога может быть число переходов, которые представляют ту же границу. Эти проблемы преодолевают группировкой вместе всех точек перехода через все группы, если они меньше чем время  , за исключением, где представляется минимальная длина фонемы. Мы помещаем 5 как его значение в дискретной области, которая представляет 29 мс. Соседние значения дала худшие результаты в оценке теста. Пограничная позиция – центр этих группируемых пунктов перемещения. Удивительно мы нашли предварительный акцент, фильтрующий как шаг, плохое качество, поэтому мы не использовали это в конечной версии алгоритма.
, за исключением, где представляется минимальная длина фонемы. Мы помещаем 5 как его значение в дискретной области, которая представляет 29 мс. Соседние значения дала худшие результаты в оценке теста. Пограничная позиция – центр этих группируемых пунктов перемещения. Удивительно мы нашли предварительный акцент, фильтрующий как шаг, плохое качество, поэтому мы не использовали это в конечной версии алгоритма.
Алгоритм состоит из следующих шагов:
1. Нормализация речевого сигнала путем деления максимального значения.
2. Разложение сигнала на шесть уровней по ДВП.
3. Вычислить сумму энергии образцов во всех частотных подгруппах в соответствии с таблицей 1, чтобы получить (5), энергетическое представления (i) n-й подгруппы.
4. Рассчитать порог , для энергетических колебаний в каждой подгруппе, выбирая самые высокие значения в окне заданного размера (Рис. 3 и Таблица 1).
5. Расчет скорости изменения функции путем фильтрации (i) с маской [1, 2, -2, -1].
6. Учитывая порог р расстояние между и (i) и порог минимального (i), найти индексы для которых 
 , где = 1. Написать такие индексы в один вектор (отмечены звездочками на рис. 3).
, где = 1. Написать такие индексы в один вектор (отмечены звездочками на рис. 3).
7. Найти и сгрупперировать индексы, где нет пространства между соседними точками больше чем атрибут .
8. Рассчитать среднее значение индекса (с округлением до ближайшего целого числа) для каждой группы находящихся в предыдущем шаге, как представитель группы. Они индексируют фонемные границы в порядке индексации DWT 1-го уровня.
В нашей реализации мы предполагали, частота дискретизации  = 11025 Гц. Это дает период выборки
= 11025 Гц. Это дает период выборки  = 90,7 мс. Для того чтобы оценить качество наших результатов, мы должны вручную отсегментировать 50 польских слов для сравнения. Ручная сегментация само по себе не совсем точный процесс, потому что человеческое ухо ошибается. Кроме того фонемы обычно перекрывают друг с друга. Причиной этого является то, что выражение звуков производится за счет модуляции воздушного потока из легких путем вибрации голосовых связок. Эта модуляция реагирует на изменения вибраций в голосовом тоне с опозданием. Возможно есть степень неопределенности именно там, где фонемы начинаются и заканчиваются, с точностью до нескольких образцов.
= 90,7 мс. Для того чтобы оценить качество наших результатов, мы должны вручную отсегментировать 50 польских слов для сравнения. Ручная сегментация само по себе не совсем точный процесс, потому что человеческое ухо ошибается. Кроме того фонемы обычно перекрывают друг с друга. Причиной этого является то, что выражение звуков производится за счет модуляции воздушного потока из легких путем вибрации голосовых связок. Эта модуляция реагирует на изменения вибраций в голосовом тоне с опозданием. Возможно есть степень неопределенности именно там, где фонемы начинаются и заканчиваются, с точностью до нескольких образцов.
Слова делятся на сегменты не только, используя нашу автоматическую технику. Метод постоянный сегментации, где речь разбивается на сегменты фиксированной длины также был оценен как базовый уровень. Качество сегментации может быть оценено по двум критериям. Во-первых, нужное количество сегментов нужно найти - количество сегментов должно соответствовать числу фонем, присутствующих в речи. Ошибка в Количество сегментов для слова w определяется как
 (7)
(7)
где  и
и  -число сегментов в автоматическом и ручном сегментировании соответственно.
-число сегментов в автоматическом и ручном сегментировании соответственно.
Вторым критерием является точность позиции сегментации. Это основано на близости границы с ручным сегментированием границы. Так как мы не знаем которая граница соответствует определенной границе в сегментации стороны, мы берем ближайшую границу как правильную. Ошибка в размещении для слова w есть
 (8)
(8)
где  является позицией i-й границы в автоматическом сегментировании и
является позицией i-й границы в автоматическом сегментировании и  является j-й позицией в границе ручной сегментации. Наконец, мы построим общую ошибку из
является j-й позицией в границе ручной сегментации. Наконец, мы построим общую ошибку из
 (9)
(9)
где  является количеством слов в оценке набора (50 в нашем примере), и равно 5, которая представляет 29 мс. Ошибка в числе сегментов (w) имеет большее влияние на дальнейшее распознавание, чем смещение границы представленное (w). Мы решили масштабировать (w) от на минимальную длину фонемы, потому что граница смещения, как правило, меньше, чем отсутствующей границы вообще. Такой критерий описывает возможные неточности сегментации. Она учитывает все важные вопросы, однако решение не лишено недостатков. Он считает небольшие различия между ручной сегментацией и автоматической сегментации как ошибки, в то время как такие изменения не должны обязательно рассматриваться именно таким образом. Как уже было сказано, пока не трудно показать статистику правильной сегментации, потому что мы не можем сравнить их с идеалом. Ручная сегментация не является достаточно совершенной, чтобы быть полностью убедительным шаблоном.
является количеством слов в оценке набора (50 в нашем примере), и равно 5, которая представляет 29 мс. Ошибка в числе сегментов (w) имеет большее влияние на дальнейшее распознавание, чем смещение границы представленное (w). Мы решили масштабировать (w) от на минимальную длину фонемы, потому что граница смещения, как правило, меньше, чем отсутствующей границы вообще. Такой критерий описывает возможные неточности сегментации. Она учитывает все важные вопросы, однако решение не лишено недостатков. Он считает небольшие различия между ручной сегментацией и автоматической сегментации как ошибки, в то время как такие изменения не должны обязательно рассматриваться именно таким образом. Как уже было сказано, пока не трудно показать статистику правильной сегментации, потому что мы не можем сравнить их с идеалом. Ручная сегментация не является достаточно совершенной, чтобы быть полностью убедительным шаблоном.
Таблица 3: Сравнение обнаруженных границ фонемы с ручной сегментацией слова "Andrzej"
Ручное |
0 |
4 |
27 |
52 |
66 |
86 |
105 |
118 |
||
Таблица 4: Влияние введеного белого шума на обнаруженные границы фонемы (с использованием вейвлет sym6) по ошибке . В столбцах отмеченных ± мы представили максимальное значение шума.
|
|
|
|||
0.5 1 1.5 |
3.0780 3.2340 3.2881 |
3 4 5 |
3.4931 3.7579 3.8002 |
7 8 9 |
4.0035 4.0326 4.2065 |
Метод оценки можно было бы улучшить, если бы несколько человек сделали ручную сегментацию. В таком случае шаблон не был бы средним значением над различными наблюдателями, а скорее короткий диапазон возможных правильных ответов для каждой границы. Ошибка была бы пересчитана, если автоматическая сегментация вышла бы за пределы диапазона и ее значение было бы расстоянием к более близкому концу диапазона. Это защитило бы, как минимум частично, метод оценки от ошибки оператора ограниченной точности человеческого уха. Общая ошибка для нашего набора данных приводится в таблице 2. Наибольшая ошибка при статической сегментации 23,2 мс что гораздо меньше 92,8 мс, вызвано это тем, что длина фонем, как правило, в среднем около 100 мс.
Рис. 3 показывает пример сегментации процесса. Наряду с автоматическим и ручным сегментированием границы, показаны шесть полос сглаженного вейвлета. Для этого слова, пограничные позиции показываются в Таблице 3. Метод находит почти все границы точно, с точностью до 2 образцов, но потеря одной границы слишком далеко до конца одной фонемы и фонема была разделена два раза по отдельным элементам.
Мы провели дополнительный эксперимент для дальнейшей оценки. Мы представили белый шум автоматически найденным границам фонемы. Мы увеличили энергию шума добавлением или вычитанием больших случайных значений для каждой границы в последовательных сравнениях. Мы обнаружили, что средняя ошибка в размещении растет, как представлено в (табл. 4). Это показывает, что результаты оценки ухудшаются путем введения белого шума.
Мы потеряли некоторую информацию о значении слова используя статическую сегментацию. Эффективный и быстрый алгоритм разговорной сегментации позволяет нам вводить возможность лучшего автоматического распознавания речи.
Предлагаемый метод основан на анализе ДВП. Это эффективно, потому что некоторые фонемы имеют энергетические вариации только в узкой группе. Это гораздо легче обнаружить, анализируя ДВП подсигналы, чем энергию всего сигнала. Пороги энергии ДВП подсигнала должны быть рассчитаны для более легкого и более быстрого анализа энергетических вариаций. Легко обнаружить изолированные фонемы, используя наш алгоритм. Дополнительно представлен простой метод оценки сегментации основанный на сравнении с ручной сегментацией.

Рис.3. Пример сегментации слова "Andrzej". Пунктирные линии границы ручной сегментации; пунктирные линии границы сегментации в автоматическом режиме, жирные линии и тонкие линии сглажены в зависимости от скорости изменения функций. Звездочки являются значениями на границах, для которых и (i) близки друг к другу или равны (ср. с 6-й шаг алгоритма).
1. P. Abry. Ondelettes et turbulence. Diderot ed., 1997.
2. I. Daubechies. Ten lectures on Wavelets. Society for Industrial and Applied Mathematics, 1992.
3. M. Deviren and K. Daoudi. Frequency and wavelet filtering for robust speech recognition. Joint International Conference on Artificial Neural Networks (ICANN)/International on Neural Information Processing (ICONIP), Istanbul, 2002.
4. O. Farooq and S. Datta. Wavelet based robust subband features for phoneme recognition. IEE Proceedings: Vision, Image and Signal Processing, 151(3):187–193, 2004.
5. J.N. Gowdy and Z. Tufekci. Mel-scaled discrete wavelet coefficients for speech recognition. Proc. of ICASSP, Istanbul, 2000.
6. D. B. Grayden and M. S. Scordilis. Phonemic segmentation of fluent speech. Proc. of ICASSP, pages 73–76, 1994.
7. M. Ostendorf, V.V. Digalakis, and O.A. Kimball. From hmm’s to segment models: A unified view of stochastic modeling for speech recognition. IEEE Trans. on Speech and Audio Processing, 4:360–378, 1996.
8. O. Rioul and M. Vetterli. Wavelets and signal processing. IEEE Signal Processing Magazine, 8:11–38, 1991.
9. Y. Suh and Y. Lee. Phoneme segmentation of continuous speech using multi-layer perceptron. In ICSLP 96, 1996.
10. D. Wang and S. Narayanan. Piecewise linear stylization of pitch via wavelet analysis. Proc. of Interspeech, 2005.
11. C. J. Weinstein, S. S. McCandless, L. F. Mondshein, and V. W. Zue. A system for acoustic-phonetic analysis of contimuous speech. IEEE Trans. on Acoustics, Speech and Signal Processing, 23:54–67, 1975.
12. S. Young. Large vocabulary continuous speech recognition: a review. IEEE Signal Processing Magazine, 13(5):45–57, 1996.
13. V. W. Zue. The use of speech knowledge in automatic speech recognition. Proc. of the IEEE, 73:1602–1615, 1985.