
Abstract
Содержание
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research, planned results
- 3. Synthesis of intonation component of speech signal using spline interpolation
- Conclusion
- References
Introduction
Modern systems are not only able to perform various operations on the calculation and information processing, but also to perform data recognition and recovery. In recent years, such systems are of great interest not only in scientific, but in practical areas of human activity.
One of the actual tasks of these systems is speech synthesis.
Speech synthesis is the process of reconstruction of the shape of the speech signal by its parameters.
During design and development of modern speech synthesizers is used frequently sound database [1]. Such a database contains either a single phoneme or a combination thereof, or a full record of words or phrases, depending on the approach to the synthesis. On the first stages of synthesizer creation the filling of database can be performed manually. But such an approach is fraught with time costs to find required segments, subjective human perception of sound, difficulty in reproducing the results of the filling.
Therefore there is a problem of automation of the filling process via usage of the methods of speech segmentation.
There are many methods of speech segmentation based on different mathematical apparatus such as discrete wavelet transform [2], dynamic programming [3], the logarithmic transformation of the spectrum [4]. They allow to receive reproducible results with different quality and segmentation speech accuracy. Specific requirements for methods of segmentation are a speaker independency, since this property allow to receive sound database for the various voices without changing the parameters of the method for individual speaker.
To modern systems of speech synthesis have requirements of legibility and naturalness of sound. Legibility means correct recognition by the person of all the words of the synthesized speech. Most modern speech synthesis systems demonstrate good legibility reaching the legibility of natural speech. The naturalness is evaluated by similarity measures between synthesized and naturally-spoken speech.
Under the speech with intonation we understand the reader's expression relationship to the content of this text and the audience. Usually, the style and meaning of the text dictate a choice of style of speech. In a speech with the intonation the individual words are underlined, certain sections of text are highlighted by pauses, etc.
1. Theme urgency
Speech synthesis can be used in communication engineering, in information systems, in military and space technology, in robotics. Also it can be used for delivery of the information about technological processes and for help. In perspective development of high-quality speech synthesis systems is a necessary step towards closer human communication with the computer. Speech synthesis may be required in all cases where the information receiver is a human.
Based on the above it can be concluded that the master's work is devoted to actual scientific task of speech synthesis.
2. Goal and tasks of the research, planned results
The goal of master's work is software development for the synthesis of words and phrases of Russian speech with modeling of intonational coloring.
To achieve this goal it is necessary to solve the following tasks:
- Segmentation of the speech signal for automatic filling of the synthesizer's database with different sound combinations.
- Analysis of the entered text.
- Building transcription of the text.
- Gluing sound combinations from the synthesizer's database without the clicks.
- Determination of intonational constructions of the text.
- Adduction of the speech signal to a given melodic contour.
Research object: speech as a sequence of sounds, which are implementations of specific phonemes.
Research subject: algorithms of modeling of melodic contour for synthesis of speech and software implementation.
For the experimental evaluation of received theoretical results the development of software implementation of a speech synthesizer is planned.
3. Synthesis of intonational component of speech signal using spline interpolation
In this approach [17] to the compilative synthesis if speech signal we need to obtain formal description of its phonetic and intonational properties. As part of the description proposed we need to specify intonational characteristics for all phonemes. These characteristics include the number of control points of parametric curves. The parameters of the neighboring phonemes should be smoothly coordinated.
Figure 1 shows the main stages of compilative synthesis of speech signal with the using of smooth parametric curves with a limited set of control points given.
To achieve the qualitative synthesis it is important to smoothly adjust the following parameters of speech signal:
- Contour of pitch frequency is the main component of intonational speech.
- The amplitude envelopes , the primary purpose of which is dynamically adjusts the signal amplitude. The joint increase in the amplitude and frequency of the signal leads to an increase of its volume.
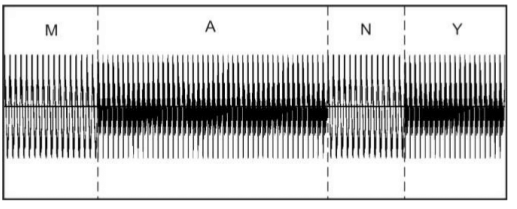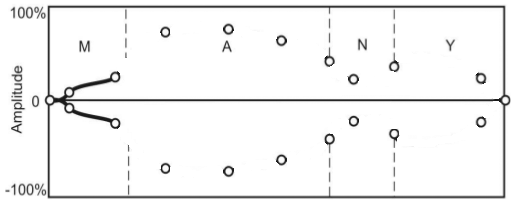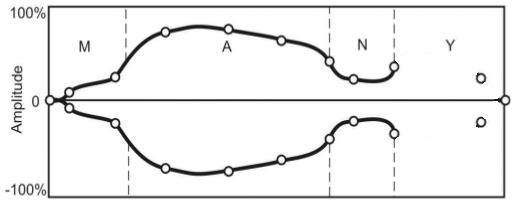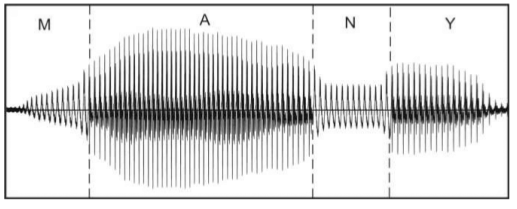
Figure 1 — Stages of imposing intonational construction on the of speech signal (animation: 8 frames, 5 cycles repeat, 145 kb)
In compilative synthesis [8] via various algorithmic manipulations on the audio signal the necessary form is achieved. The specified form of the speech signal depends on many factors: the language, the speaker's voice, text, required intonation, speed and volume of pronunciation, etc.
Prepared, normalized on duration of phonemes and the overall level of the amplitudes, smoothly connected from different fragments speech signal is input to the parameters control system. Depending on the required intonational characteristics pitch frequency contour is formed and superimposed over the original speech signal. Then the amplitude envelopes are superimposed over the signal.
A limited number of control points is to define curve allocated. So the original function of control parameter is approximated in a best way. Extremums of the approximating function are selected as initial reference point.
Conclusion
Speech synthesis is an actual task. The following results were obtained during work on this essay:
- an algorithm for speech signal segmentation is developed for automatic filling of the synthesizer's sounds database;
- intonational constructions of the Russian language were examined;
- existing approaches to the creation of intonational coloring were review.
Further research is aiming on the following aspects:
- definition of intonational constructions of the text;
- adduction of the speech signal to a given melodic contour.
While writing this essay master's work had not been completed yet. Final completion term is December 2012. The full text of the work and materials on the subject could be obtained from the author or his supervisor after that date.
References
- Сорокин В.К. Синтез речи / Сорокин В.К. — М. : Наука, 1992. — 392 с.
- Вишнякова О.А. Автоматическая сегментация речевого сигнала на базе дискретного вейвлет-преобразования / О.А. Вишнякова, Д.Н. Лавров // Математические структуры и моделирование — 2011, — Выпуск 23. С. 43–48.
- Давыдов А.Г. Использование периодичности речевого сигнала при фонемной сегментации речи / А.Г. Давыдов, Б.М. Лобанов // Доклады Белорусского государственного университета информатики и радиоэлектроники, № 2, 2006. — С. 69–74.
- Колоков А.С. Предварительная обработка и сегментация речевого сигнала в частотной области для распознавания речи / Колоков А.С. // Автоматика и телемеханика, № 6, 2003. — С. 152–162.
- Д. Фланаган Анализ, синтез и восприятие речи / Д. Фланаган — М. : Связь, 1968. — 395 с.
- Фант Г. Анализ и синтез речи / Фант Г. — Новосибирск : Наука, 1970 — 167 с.
- Фант Г. Акустическая теория речеобразования / Фант Г. — М : Наука, 1964. — 329 с.
- Лобанов Б.М. Компьютерный синтез и клонирование речи / Б.М. Лобанов, Л.И. Цирульник — Минск : Белорусская наука, 2008. — 316 с.
- Буланин Л.Л. Фонетика современного русского языка / Буланин Л.Л. — М. : Высшая школа, 1970. — 208 с.
- Бондарко Л.Б. Звуковой строй современного русского языка. / Бондарко Л.Б. — М. : Просвещение, 1977. — 175 с.
- Бондарко Л.В. Фонетическое описание языка и фонологическое описание речи / Бондарко Л.В. — Л. : ЛГУ, 1981. — 199 с.
- Брызгунова Е. А. Интонация. Русская грамматика / Брызгунова Е. А. — М. : Наука, 1980. — 378 с.
- Пешковский А.М. Интонация и грамматика. / Пешковский А.М. — М. : Избр. Труды, 1959. — 247 с.
- Цеплитис Л.К. Анализ речевой интонации / Цеплитис Л.К. — Рига : Зинтарис, 1974. — 270 с.
- Людовик Т.В. Автоматический синтез нейтральной и выразительной речи / Людовик Т.В. // Искусственный интеллект, № 1, 2010. — С. 9-02.
- Lyudovyk T. Unit Selection Speech Synthesis Using Phonetic-Prosodic Description of Speech Databases / Lyudovyk T., Sazhok M. // Proceedings of the International Conference
Speech and Computer
(SPECOM'2004). — St.-Petersburg (Russia), 2004. — Р. 594-599. - Калимолдаев М.Н. Синтез интонационной составляющей речевого сигнала с применением сплайновой интерполяции / М.Н. Калимолдаев, Е.Н. Амиргаливев, Р.Р Мусабаев [Электронный ресурс]. — Режим доступа : http://conf.nsc.ru/files/conferences/MIT-2011/fulltext/58039/58041/Калимолдаев_Статья.pdf
- Ермоленко Т.В. Алгоритмы сегментации с применением быстрого вейвлет-преобразования [Электронный ресурс]. — Режим доступа : http://www.dialog-21.ru/Archive/2003/Ermolenko.htm
- Ермоленко Т.В. Классификация фреймов речевого сигнала в задачах дикторонезависимого распознавания речи / Т.В. Ермоленко, А.В. Жук // Искусственный интеллект. — 2011. — № 3 — C. 152–161.
- Сорокин В.Н. Сегментация и распознавание гласных / В.Н. Сорокин, А.И. Цыплихин // Информационные процессы. — 2004. — Т. 4, № 2. — С. 20-04.
- Сергиенко А. Б. Цифровая обработка сигналов / Сергиенко А. Б. — СПб : Питер, 2006. — 751 с.
- Р. Лайонс Цифровая обработка сигналов / Р Лайонс — М : Бином-Пресс, 2011. — 654 с.
- Э. Айфичер Цифровая обработка сигналов. Практический подход / Э. Айфичер, Б. Джервис — М : Вильямс, 2004. — 992 с.
- Умняшкин С.В. Теоретические основы цифровой обработки и представления сигналов / Умняшкин С.В. — М : Форум, 2007. — 304 с.
- Дремин И.М. Вейвлеты и их использование / И.М. Дремин, О.В. Иванов, В.А. Нечитайло // Успехи физических наук. — 2001. — Т. 171, № 5. — С. 465-500.
- Taylor P. Text to Speech Synthesis / University of Cambridge, — 2007. 597 pp.
- Hunt A. Unit selection in a concatenative speech synthesis system using a large speech database / Hunt A., Black A. // Proceedings of the International Conf. on Acoustics, Speech, and Signal Processing. — Atlanta (USA), 1996. — Vol. 1. — P. 373-376.
- Perspective on the Next Challenges for TTS Research / [Schroeter J., Conkie A., Syrdal A. и др.] // Proceedings of the IEEE Workshop on Speech Synthesis. — 2002. — P. 211-214.